

DevOps, Continuous Delivery & Database Lifecycle Management
Automated Deployment
The way we think about data and databases must adapt to fit with dynamic cloud infrastructure and Continuous Delivery. There are multiple factors driving significant changes to the way we design, build, and operate software systems: the need for rapid deployments and feedback from software changes, increasingly complex distributed systems, and powerful new tooling, for example. These changes require new ways of writing code, new team structures, and new ownership models for software systems, all of which in turn have implications for data and databases.
In a previous article (Common database deployment blockers and Continuous Delivery headaches), we looked at some of the technical reasons why databases often become undeployable over time, and how this becomes a blocker for Continuous Delivery. In this article, we’ll look at some of the factors driving the need for better deployability, and investigate the emerging pattern of microservices for building and deploying software.
Along the way, we’ll consider why and how we can apply some of the lessons from microservices to databases in order to improve deployability. In particular, we’ll see how the Eventual Consistency found in many microservices architectures could be applied to modern systems, avoiding the close coupling (and availability challenges) of Immediate Consistency. Finally, we’ll look at how Conway’s Law limits the shape of systems that teams can build, alongside some new (or rediscovered) ownership patterns, human factors, and team topologies that help to improve deployability in a Continuous Delivery context.
Factors Driving Deployability as a First-Class Concern
The ability to deploy new or changed functionality safely and rapidly to a Production environment – deployability – has become increasingly important since the emergence of commodity ‘cloud’ computing (virtualization combined with software-defined elastic infrastructure). There are plenty of common examples of where this is important – we might want to deploy a new application, a modified user journey, or a bug fix to a single feature. Regardless of the specific case, the crucial thing in late 2014 and beyond is that the change can be made independently and in an isolated way in order to avoid adversely affecting other applications and features, but without waiting for a large ‘regression test’ of all connected systems.
Speed, Feedback, and Security
This increased need for deployability is driven by several factors. First, startup businesses can now build a viable product, using new cloud technologies, to rival those of large incumbent players with staggering speed. Since it began to offer films over the internet using Amazon’s AWS cloud services, Netflix has grown to become a major competitor to both television companies and to the film industry. With software designed and built to work with the good and bad features of public cloud systems, companies like Netflix are able to innovate at speeds significantly higher than organisations relying on systems built for the pre-cloud age.
A second reason why deployability is now seen as hugely important is that if software systems are easier to deploy, deployments will happen more frequently and so more feedback will be available to development and operations teams. Faster feedback allows for more timely and rapid improvements, responding to sudden changes in the market or user base.
Faster feedback in turn provides an improved understanding of how the software really works for teams involved, a third driver for good deployability. Modern software systems – which are increasingly distributed, asynchronous, and complex – are often not possible to understand fully prior to deployment, and their behaviour is understood only by observation in Production.
Finally, an ability to deploy changes rapidly is essential to defend against serious security vulnerabilities such as Heartbleed and Shellshock in core libraries, or platform vulnerabilities such as SQL injection in Drupal 7. Waiting for a 2-week regression test cycle is simply not acceptable in these cases, but nor is manual patching of hundreds of servers: changes must be deployed using automation, driven from pre-tested scripts.
In short, organisations must value highly the need for change in modern software systems, and design systems that are amenable to rapid, regular, repeatable, and reliable change – an approach characterised as Continuous Delivery by Jez Humble and Dave Farley in their 2010 book of the same name.
What Are Microservices and Why Are They Becoming More Widespread?
The use of ‘microservices’ architectural pattern to compose modern software systems is one response to the need for software that can be easily changed. The microservices style separates a software application into a number of discrete services, each providing an API, and each with its own store or view of data that it needs. Centralised data stores of the traditional RDBMS form are typically replaced with local data stores, and either a central asynchronous publish-subscribe event store, or an eventually-consistent data store based on NoSQL ‘document’ or column databases (or both). These non-relational technologies and data update schemes decouple the different services both temporally and in terms of data schemas, while allowing them to be composed to make larger workflows.
Within an organisation, we would desperately avoid having to couple the deployment of our new application to the deployment of new applications from our suppliers and our customers. In a similar way, there is increasingly a benefit to being able to decouple the deployment of one business service from that of other, unrelated services within the same organisation.
In some respects, the microservices style looks somewhat like SOA and there is arguably an amount of ‘Emperor’s New Clothes’ about the term ‘microservices’. However, where microservices departs radically from SOA is in the ownership model for the services: with microservices, only a single team (or perhaps even a single developer) will develop and change the code for a given service. The team is encouraged to take a deep ownership of the services they develop, with this ownership extending to deployment and operation of the services. The choice of technologies to use for building and operating the services is often left up to the team (within certain agreed common cross-team parameters, such as log aggregation, monitoring, and error diagnosis).
The ownership of the service extends to decisions about when and what to deploy (in collaboration with the product or service owner), rather than orchestrating across multiple teams, which can be painful. This means that if a new feature or bugfix is ready to go into Production, the team will deploy the change immediately, using monitoring and analytics to track performance and behaviour closely, ready to roll back (or roll forward) if necessary. The possibility of ‘breaking’ things is acknowledged, but weighed against the value of getting changes deployed into Production frequently and rapidly, minimizing the ‘change set size’ and therefore risk of errors.
Microservices and Databases
Common questions from people familiar with the RDBMS-based software systems of the 1990s and 2000s relate to the consistency and governance of data for software built using a microservices approach, with data distributed into multiple data stores based on different technologies. Likewise, the more operationally-minded ask how database backups can be managed effectively in a world of ‘polyglot persistence’ with databases created by development teams. These are important questions, and not to be discounted: I hope to address them in more detail in a future article.
However, I think these questions can sometimes miss the point of microservices and increased deployability; when thinking about microservices we need to adopt a different sense of ‘scale’. Let me explain.
The Business is Already Decoupled
Consider a successful organisation with a typical web-based OLTP system for orders built around 2001 and evolved since then. Such a system likely has a large core database running on Oracle, DB2, or SQL Server, plus numerous secondary databases. The databases may serve several separate software applications. Database operations might be coordinated across these databases using distributed transactions or cross-database calls.

Fig.1 – Separate organisations are hugely resistant to close coupling and immediate consistency in their respective systems.
However, data needs to be sent to (or read from) remote systems – such as those of a supplier – and it is likely that distributed transactions will be used only sparingly. Asynchronous data reconciliation is much more common – it might take minutes / hours / days to process, and we deal with the small proportion of anomalies in back-office processing, refunds, etc. Proven techniques such as Master Data Management (MDM) are used to tie together identifiers from different databases within large organisations, allowing audit and queries for common data across the enterprise.
Fig. 2 – For the vast majority of activities, eventual consistency is the norm. This approach is also perfect for most services and systems within an organisation.
Between the databases of different organisations, eventual consistency, not immediate consistency, is the norm (consider the internet domain name system (DNS) as a great example of eventual consistency that has been proven to work well and robustly for decades).
Eventually Consistent Scales Better than Immediately Consistent
There is nothing particular special about the organisational boundary as point at which the default data update scheme switches to immediate consistency – it was merely convenient in the 1990s and 2000s. The boundary for immediate consistency has to be placed somewhere fairly close to the operation being performed; otherwise, if we insisted on immediate consistency across all supplier organisations and their suppliers (ad infinitum) we’d have to ‘stop the world’ briefly just to withdraw cash from an ATM! There are times when immediate consistency is needed, but eventual consistency should be seen as the norm or default.
When considering microservices and eventual consistency in particular, we need to take the kinds of rules that we’d naturally apply to larger systems (say bookkeeping for a single organisation, or orders for a single online ecommerce store) and apply these at a level or granularity an order of magnitude smaller: at the boundary of individual business services. In the same way that we have come to avoid distributed transactions across organisational boundaries, with a microservices architecture we avoid distributed transactions across separate business services, allowing event-driven asynchronous messaging to trigger workflows in related services.
So we can see that there are similar patterns of data updates at work between organisations and between business services in a microservices architecture: asynchronous data reconciliation with eventual consistency, typically driven by specific data ‘events’. In both cases, data workflows must be designed for this asynchronous, event-driven pattern, although the technologies used can appear on the surface to be very different.
Event Streams as a Well-Known Foundation
Another pattern that is shared between microservices and traditional RDBMS systems is the use of event streams for constructing a reliable ‘view of the world’. Every DBA is familiar with the transaction log used in relational databases and how it’s fundamental to the consistency of the data store, allowing replication and failure recovery by ‘replaying’ a serialised stream of events. The same premise is used as the basis for many microservices architectures, where the technique is known as ‘event sourcing’. An event-sourced microservices system could arguably be seen as a kind of application-level transaction log, with various service updates being ‘triggered’ from events in the ‘log’. If event streams are a solid foundation for relational databases, why not also for business applications built on microservices?
Changes that Make Microservices Easier
Application and network monitoring tools are significantly better in almost every respect compared to those of even a few year ago, particularly in terms of their programmability (configuration through scripts and APIs rather than arcane config files or GUIs). We have had to adopt a first-class approach to monitoring for modern web-connected systems because these systems are distributed, and will fail in ways we cannot predict.
Thankfully, the overhead in monitoring applications is proportionately smaller than in the past, with faster CPUs, networks, etc. combined with modern algorithms for dynamically reducing monitoring overhead. Enterprise-grade persistent storage (spinning disks, SSDs) is now also significantly cheaper per Terabyte than 10 years ago. Yes we have more data to store, but the size of operating systems, typical runtimes and support files has not grown so fast as to absorb the decrease in storage cost. Cheaper persistent storage means that denormalized data is less of a concern from a ‘data sprawl’ viewpoint, meaning that an increase in data caches or ‘duplication’ in event stores or document stores is acceptable.
Monitoring tools for databases have improved significantly in recent years too. Runtime monitoring tools such as Quest Foglight, SolarWinds Database Monitor, or Red Gate SQL Monitor all help operations teams to keep tabs on database performance (even Oracle Enterprise Manager has some reasonable dashboarding features in version 12). New tools such as DLM Dashboard from Red Gate simplify tracking changes to database schemas, reducing the burden on DBAs, and allow the automation of audit and change request activities that can be time-consuming to do manually.
DBA-as-a-Service
The increase in computing power that allows us to run much more sophisticated monitoring and metrics tooling against multiple discrete microservices can also be brought to bear on the challenge of monitoring the explosion of database instances and types which these microservices herald. Ultimately, this might resulting in what I call a ‘DBA-as-a-Service‘ model.
Rather than spending time deploying database schema changes manually to individual core relational databases, the next-generation DBA will likely be monitoring the Production estate for new database instances, checking conformance to some basic agreed standards and performance, and triggering a workflow to automatically backup new databases. Data audit will be another important part of the next generation DBA’s role, making sure that there is traceability across the various data sources and technologies, flagging any gaps.
Changes to cope with speed, complexity, and ‘cloud’
One of the advantages of microservices for the teams building and operating the software is that the microservices are easier to understand than larger, monolithic systems. Systems that are easier to comprehend and deploy (avoiding machine-level multi-tenancy) make teams much less fearful of change, and in turn allows them to feel more in control of the systems they deal with. For modern software systems whose behaviour cannot easily be predicted, the removal of fear and increase in confidence are crucial psychological factors in the long-term success of such systems.
Microservices architectures aim for ‘human-sized complexity’, decoupling behaviour from other systems by the use of asynchronous, lazy data loading, tuneable consistency, and queue-based event-sourced operations for background updates. The sense of ownership tends to keep the quality of code high, and avoids a large and unwieldy mass of tests accreting to the software.
Conway’s Law and the Implications for Continuous Delivery
The way in which teams communicate and interact is the single major determinant of the resulting software system architecture; this force (termed the ‘homomorphic force’ by software guru Allan Kelly) is captured by Conway’s Law:
“organizations which design systems … are constrained to produce designs which are copies of the communication structures of these organizations” – Mel Conway, 1968
Software architect Ruth Malan expands on this:
“if the architecture of the system and the architecture of the organization are at odds, the architecture of the organization wins” – Ruth Malan, 2008
In short, this means that we must design our organizations to match the software architecture that we know (or think) we need. If we value the microservices approach of multiple independent teams, each developing and operating their own set of discrete services, then we will need at least some database capability within each team. If we kept a centralised DBA team for these ideally-independent teams, Conway’s Law tells us that we would end up with an architecture that reflects that communication pattern (probably a central database, shared by all services, something we wanted to avoid!)
Team topologies for Effective Continuous Delivery
Since realising the significance of Conwy’s Law for software systems several years ago I have been increasingly interested in team ‘topologies’ within organizations and how these help or hinder the effective development and operation of the software systems required by the organization. When talking to clients I have often heard comments like this from overworked DBAs:
After you start looking at software systems through the ‘lens’ of Conway’s Law, you begin to see the team topologies reflected in the software, even if that results in an unplanned or undocumented software architecture. For organizations that have decided to adopt microservices in order to deploy features more rapidly and independently, there must be a change in the team structures if the new software architecture is to be effective.
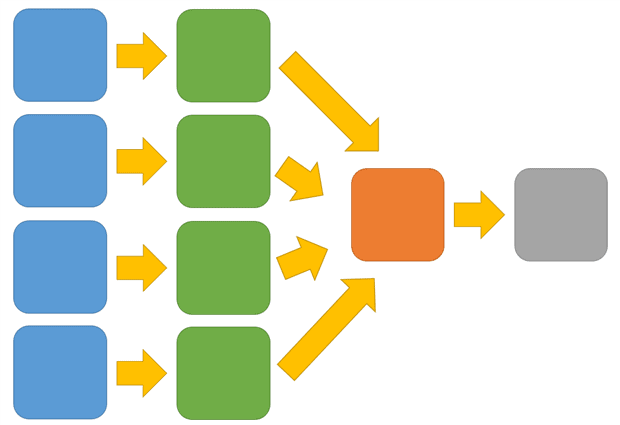
Fig. 3 – Seen through the lens of Conway’s Law, a workflow with central DBA and Ops teams, rotated 90 degrees clockwise, reveals the inevitable application architecture: Distributed front-end and application layers, and a single, monolithic data layer.
The vast majority of database changes must be handled within the team building and operating the microservices, implying a database capability inside the team. That does not necessarily mean that each microservices team gets its own DBA, because many microservices will have relatively simple and small databases with flexible schemas and logic in the application to handle schema changes (or to support multiple schemas simultaneously). Perhaps one DBA can assist several different microservices product teams, although you’d need some care not to introduce coupling at the data level due to the shared DBA.
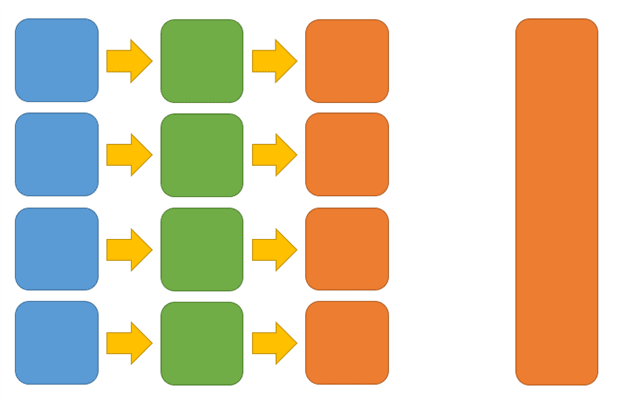
Fig. 4 – For a true microservices model, and the agility that implies, each service team needs to support its own data store, potentially with an overarching (or underlying) data team to provide a consistent environment and overview of the complete application.
In practice this might mean that every team has their own data expert or data owner, responsible for just their localised data experience and architecture (there are parallels between this and some of the potential DevOps team topologies I’ve discussed in the past). Other aspects of data management might be best handled by a separate team: the ‘DBA-as-a-Service mentioned above. This overarching team would provide a service that included:
- Database discovery (existence, characteristics, requirements),
- Taking and testing backups of a range of supported databases,
- Checking the DB recovery modes,
- Configuring the high-availability (HA) features of different databases based on ‘tuneable’ configuration set by the product team,
- Auditing data from multiple databases for business-level consistency (such as postal address formats).
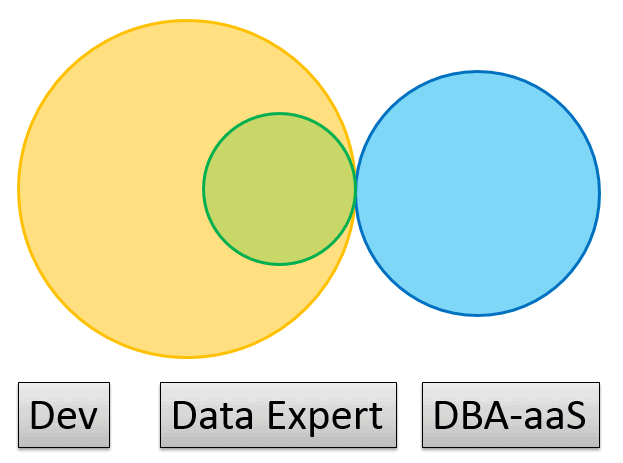
Fig 5. One potential topology for a Microservices / DBA-as-a-Service team structure
Of course, each autonomous ‘service team’ must also commit to not breaking functionality for other teams. In practice this means that software written by one team will work with multiple versions of calling systems, either through implicit compatibility in the API (‘being forgiving’) or through use of some kind of explicit versioning scheme (preferably semantic versioning). When combined with a ‘concertina’ approach – expanding the number of supported older clients, then contracting again as clients upgrade – this decouples each separate service from changes in related services, an essential aspect of enabling independent deployablity.
A good way to think about a DBA-as-a-Service team is to imagine it as something you’d pay for from AWS. Amazon don’t care about what’s in your application, but they will coordinate your data / backups / resilience / performance. It’s important to maintain a minimal interaction surface between each microservice and the DBA-as-a-Service team (perhaps just an API), so that they’re not being pulled into the design and maintenance of individual services.
There is no definitive ‘correct’ team topology for database management within a microservices approach, but a traditional centralised DBA function is likely to be too constraining if all database changes must be approved by the DBA team. Each team topology has implications for how the database can be changed and evolved. Choose a model based on an understanding of its strengths and limitations, and keep the boundaries clear; adhere to the social contracts, and seek collaboration at the right places.
Supporting Practices for Database Continuous Delivery
In addition to changes in technologies and teams, there are some essential good practices for effective Continuous Delivery with databases using microservices. Foremost is the need for a focus on the flow of business requirements with clear cross-programme prioritisation of multiple workstreams, so that teams are not ‘swamped’ with conflicting requests from different budget holders.
The second core practice is to use version control for all database changes: schema, users, triggers, stored procedures, reference data, and so on. The only database changes that should be made in Production are CRUD operations resulting from inbound or scheduled data updates; all other changes, including updates to indexes and performance tuning, should flow down from upstream environments, having been tested before being deployed (using automation) into Production.
Practices such as Consumer Driven Contracts and concertina versioning for databases help to clarify the relationship between different teams and to decouple database changes from application changes, both of which can help an organisation to gradually move towards a microservices architecture from one based on an older monolithic design.
It is also important to avoid technologies and tools that exist only in Production (I call these ‘Singleton Tools’). Special Production-only tools prevent product teams from owning their service, creating silos between development and the DBA function. Similarly, having database objects that exist only in Production (triggers, agent jobs, backup routines, procedures, indexes, etc.) can prevent a product team from taking ownership of the services they are building.
Summary
The microservices approach for building software systems is partly a response to the need for more rapid deployment of discrete software functionality. Microservices typically use a data model that relies on asynchronous data updates, often with eventual consistency rather than immediate consistency, and often using an event-driven pub-sub scheme. A single team ‘owns’ the group of services they develop and operate, and data is generally either kept local to a service (perhaps exposed via an API) or published to the event store, decoupling the service from other services.
Although at first the model looks very different from traditional RDBMS-based applications of the 1990s and 2000s, in fact the premises are familiar, but simply applied at a different scale. Just as most organisations kept database transactions within their organisation and using asynchronous data reconciliation and eventual consistency, so most microservices aim to keep database transactions within their service, relying on event-based messaging to coordinate workflows across multiple services. The event stream is then fundamental to both relational databases and to many microservices systems.
To support the microservices approach, new team structures are needed. Taking on board the implications of Conway’s Law, we should set up our teams so that the communication structures map onto the kind of software architecture we know we need: in this case, independent teams, ‘consuming’ certain database management activities as a service. The DBA role probably changes quite radically in terms of its responsibilities and involvement in product evolution, from being part of a central DBA function that reviews every change, to either being part of the product team on a daily basis, or to a ‘DBA-as-a-Service’ behind the scenes, essential to the cultivation and orchestration of a coherent data environment for the business.

DevOps, Continuous Delivery & Database Lifecycle Management
Go to the Simple Talk library to find more articles, or visit www.red-gate.com/solutions for more information on the benefits of extending DevOps practices to SQL Server databases.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments