

DevOps, Continuous Delivery & Database Lifecycle Management
Culture and Organization
Any database that is supporting an organization is unlikely to be self-sufficient, getting all its data only from the one or more applications that it serves. It will probably also be getting data from a variety of other sources and publishing its own data to other destinations.
In the past, databases were considered to be ‘silos’ of information, supporting a single application. In the past thirty years, they have developed to become participants in a rich ecosystem of data, publishing only the data for which they are the primary source, and subscribing to all other data. Because of the essential unreliability of networks, data tends to be pulled into the database, and pushed out in batches, and checked as part of the ‘pulling in’. This process is generally termed Extract-Transform-Load (ETL).
A lot of thought is put into understanding data within organizations, and there are established disciplines within Information technology, such as Master Data Management (MDM) and Data Lifecycle Management to understand the nature and source of data within organizations, and how and where it is processed and exchanged. This often leads to ‘Data Warehousing’ where the data is collected in a sort of self-service data compendium. To do this effectively requires a meticulous knowledge of the type of data, format, usage, ownership and confidentiality. As an alternative model of exchanging data, Microservices and SOA have been seen as ways of avoiding the curation of data, they actually put the onus of serving ‘owned’ data on the individual service.
This puts ETL at the heart of Database Lifecycle Management, since the three activities, Governance, Delivery and Operations, need to work closely together to make it happen effectively; not just in the active phase of development but throughout the life of the database. IT Governance has the task of maintaining a logical model of the data within an organization, the context within which individual applications exist, and ensuring that the handling of data is appropriate, and conforms to legal and regulatory frameworks and guidelines. Delivery and operations have to work together to create a system that works reliably, securely, and efficiently, is easy to maintain and monitor. All three groups need to ensure that there is a common vocabulary in discussion and documentation so that misunderstandings are avoided.
ETL without design
The introduction of DLM might seem an unnecessary and expensive overhead to a simple process that can be left safely to the delivery team without help or cooperation from other IT activities.
However, few organizations, when designing their Online Transaction Processing (OLTP) systems, give much thought to the continuing lifecycle of the data, outside of that system. They don’t consider how they are going to transform and aggregate data from the various sources around the organization into a central data source that, through data mining, can help support and drive their business decisions. Even in cases where many core processes around database development and testing are automated and managed, the ETL system remains in the “wild west”.
The result is chaotic ETL, featuring periods of intense and often frustrating effort around critical data loading periods. ETL processes will typically run long, and often fail completely. The business will complain that the data is incorrect or not available when required. The ETL team will respond by making ever greater efforts to ensure that the overnight batch completes in time. Eventually, however, the truth begins to dawn that the problem is due to the fundamental lack of design in the system.
If this situation sounds familiar, then this article will help you understand the specific challenges associated with ETL systems, and the database lifecycle management (DLM) patterns that work well when attempting to develop, manage and maintain them.
Tripping over terminology
I have direct experience of the confusions, and sometimes communication breakdown, between teams brought about largely by semantic misunderstandings. ETL is a classic case where the ETL team tend to use terms differently from other teams
With ETL systems we want to build a data set, not an application, so the challenges and the terminology are different. In ETL systems, people often refer to ‘production’ not as a live system serving traffic to end-users, but rather as the means to generate (‘produce’) the next batch of data. Likewise, in ETL systems, the ‘build’ phase comes at the end of the ETL process when we build the reporting data set, whereas in transactional systems, the first thing we typically do is to ‘build’ the software from version control.
In ETL, we typically ‘stage’ the new data in a ‘staging’ area before pushing the data to the reporting (‘live’) system; this means that in an ETL context, ‘Staging’ has a very specific meaning which may not align with the term ‘Staging’ used for transactional systems, where ‘Staging’ is often a synonym for ‘Pre-Production’.
Overview of ETL systems
Extract-Transform-Load or ETL refers to the process of transferring data in bulk from one system to another. ETL systems extract and transform large volumes of source data into a new dataset, and then load that data into a new data store, for subsequent querying. This process happens because we ingest data from a variety of sources (some internal, some external to the organization), and we need to reformat or regularize the data fields before we can do further processing downstream. Source data might include:
- Order placement data from an e-commerce web application
- Data from a customer engagement system such as a CRM like Salesforce
- Anonymized patient care data from hospitals across one country or region
- Customer financial data relating to credit-worthiness
It may come as data files from other applications, from open data sources on the internet, from services on the intranet or Cloud, or from a type of data warehouse.
ETL sounds like three distinct phases but in fact the phases overlap and it’s not necessarily a serial process. The ‘users’ of ETL systems are always other software systems or people involved in data analysis, rather than interactive customers or end-users.
Figure 1 offers a highly simplified depiction of an ETL system. Each black arrow represents an ETL task as data arrives from various sources, is transformed and loaded into a Data Warehouse. The ETL process often combines data from multiple different providers, and in many cases an ETL destination can also be a data source for another ETL process. For example, the SSAS cube may be a data source for an upstream OLTP database, providing aggregated and calculated values for key business metrics, as the raw data rows are archived.
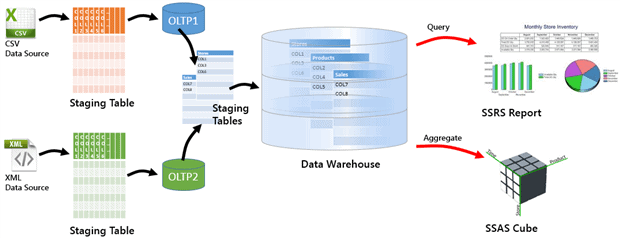
Figure 1
In Figure 1, we transport the data into staging tables in the staging area. At this point, we may well just “dump” the data into a staging table without any check constraints, using a fast, native bulk export method such as provided by Bulk Copy Program (BCP).
The recipient server has the responsibility of checking and, if necessary transforming the data, and can sometimes delegate this task to a separate server or to the ETL process itself. If the database is using a staging table, we transform and load data row-by-row into our target database, in this example a relational database. For this task, we will use an ETL tool, such as SQL Server Integration Services (SSIS). It will need to perform a range of transformation tasks, depending on the target, such as:
- Merging columns
- Splitting a column
- Pivoting data
- Data type conversion
We will also perform some data validation at this stage. For example, we must define constraints on each of the columns in our target database, to ensure the data confirms to our business rules. If a row fails the constraint conditions, it is written to Log table for inspection, and the process continues. We will also apply or maintain all appropriate indexes on the target tables.
ETL Workflows
Compared to transactional systems, ETL systems do not really have an ongoing ‘live’ state, but instead typically operate on a data load cycle that might be daily, weekly, or monthly, usually containing a ‘critical’ period where data must be loaded within a specific timeframe in order to meet internal or external deadlines. For instance, one ETL team may have to process data for an internal BI system, delivering once a week for finance meeting of the executive team, whilst another ETL may need to meet a monthly deadline imposed by a market regulator to report on the previous month’s transactions.
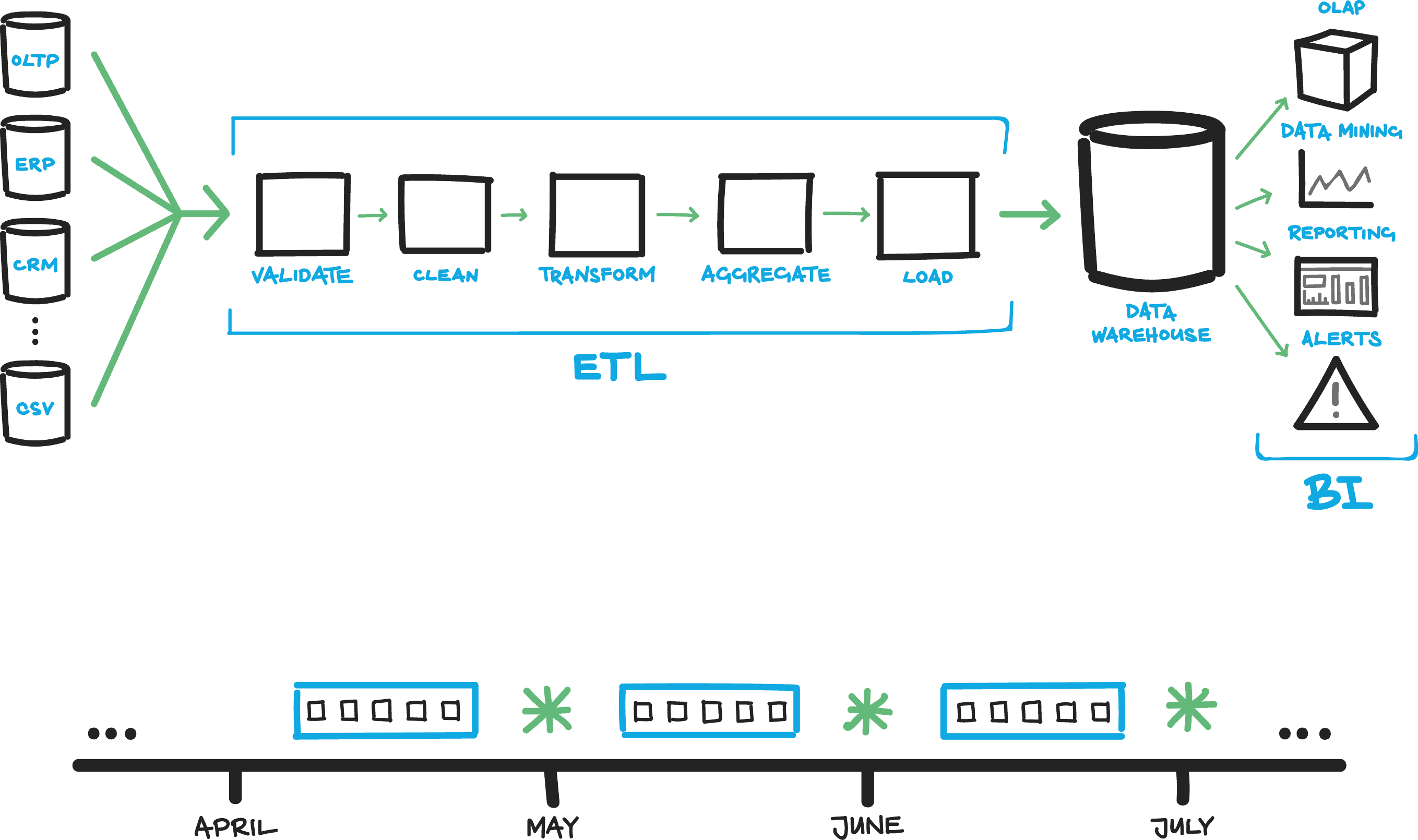
Figure 2
In the example shown in Figure 2, the ‘live’ environment is the reporting databases used by data mining, business intelligence, data alerting, and so on. To make sure that access to this live reporting data is not interrupted, ETL teams typically use a ‘staging’ area, where data quality tests are carried out before the data is loaded to the reporting environment. Data quality is assessed at extract, transform, and load phases before presenting to the reporting environment.
Typical problems with poorly managed ETL processes
When ETL processes are failing or running long, often the development team will take a long time to admit there is an issue. When the business complains that the data is unavailable or incorrect, the developers will tend to explain it away as an unusual event due to unexpected issues that caused the batch to overrun.
Production staff such as DBAs who are tasked with supporting the system will try to keep the system running and attempt to optimize the component ETL processes but due to the cyclic nature of ETL, it is easy for teams to get trapped within a reactive cycle. Fundamental improvements in the design of the ETL processing pipeline can be difficult to justify or prioritize because the bottlenecks are often heavily data-dependent; problems are blamed on ‘the data’ rather than the ETL process’s capability to deal with that data.
I call this the “JFDI” approach to ETL and the following sub-sections characterize the three most common problems associated with this approach, and the resulting ‘chaotic’ ETL processes.
Lack of knowledge of upstream and downstream systems
Typically, I’ve found that each team has little to no knowledge of the data processing and reporting requirements of the teams that work upstream and downstream in the “data pipeline”. This means that upstream changes to the data schema frequently break downstream ETL and reporting systems
The ETL processes will also tend to be fragile, and prone to failure as a result of any changes in the format of the source data, or due to “bad data” in the source. Often these problems don’t manifest until a large proportion of the source data has been processed. When it happens, the team have little choice but to make manual fixes to the data, or ETL processing stream, and then run the whole process again. Often, adjustments to the ETL process have a subsequent effect on the BI, reporting and alerting systems that rely on this data.
Long and unpredictable ETL processing times
When an ETL process exceeds its allotted time, rogue processes will be identified and an attempt made to optimize them but often these ignore the underlying problem that there is another process running at the same time that is interfering with it. I’ve seen cases where a modest, nightly batch load job took 4 hours to complete. This had never been questioned by the team; it was “just how long it took”. Deeper investigation revealed that the load process was running at the same time as a job that ran database integrity checks. Simply by tweaking the scheduling, we reduced the time for the batch load to 1 hour.
In the production system, as multiple processes attempt to insert data into, and read data from, the target database, there will tend to be blocking and deadlocking. As the number of data sources, and the volume of data, grows, so the ETL processes grow ever longer, until it is no longer possible to complete them in the allotted time-window, meaning that the data is not available in the target database when the business needs it, and downstream reporting processes fail and have to re-run.
Long ‘fail slow’ ETL test runs
Many ETL systems are not amenable to fine-grained testing. When testing the ETL process, the team might, for example, restore a backup of the full source data set, perform an “end-to-end” ETL run, and then run a few tests in the staging area in order to validate that their processing rules worked as expected. It often means that tests can run for a long time before eventually failing. This also leads to long cycle times for ETL improvements and fixes
Taming ETL Systems with DLM
Over the coming sections, we’ll review steps we can take to help tame and then systematically improve our ETL processes, and establish the “T-R-I-M” pillars of DLM:
- Traceability/Visibility – processes are visible to all teams, and to the broader business, from very early in the project.
- Repeatability – processes are automated, tested and therefore predictable and repeatable
- Incremental Improvement – processes connected by workflows that provide the necessary information to drive continuous short cycles of improvement
- Measurability – processes are instrumented and logged so that errors and deviation from predictable behavior are corrected quickly
Improving process visibility and measurability
One of the first steps is to explain the issues to the business and give them the means to judge how well you can fix it. Of course, visibility also includes the sense of instrumenting the systems to provide timings of the various jobs and any other metrics that can give a warning of impending problems.
Document existing knowledge
The first job is to collect and make visible to the business all existing knowledge about the system. The support staff will almost certainly have some statistics about what has been happening. Often they will have reports of long-running SQL statements from the overnight run which they have been looking to optimize. This is a good start but make sure that this is documented. Usually a few processes will be found to be causing major issues due to their long-running. Often these processes are not the underlying cause but are being blocked by others running at the same time. After a few iterations of optimization, the system can be improved. A note should be taken of problem tasks and how long they take to run which will be important information for a strategic solution.
Publish performance metrics
As soon as possible, start to introduce some basic monitoring to gather data about each major tasks and especially when the batch system starts and completes, and whether there are any errors. Each task needs to have a log of the start and end time. This should come from the scheduler – the SQL Server Agent maintains this in the history tables but this needs to be extracted into a log table for review.
Make this visible to the business, preferably with graphs, so that they can see when the system is available and can also start to see decreased batch processing times as progress is being made. It will also take some pressure off support staff and start to rebuild the relationship with the business
Instrument ETL processes
A key factor in the long-term success and continual improvement of our ETL processes is instrumentation.
For each task, we need to be able to “flick an on/off switch” to start collecting the performance and runtime metrics that will allow us to track the progress of tasks, troubleshoot failures quickly, and establish baselines by which to gauge recent performance compared to past performance.
If the duration of each ETL task is not monitored, then the team will inevitably fail to spot that an ETL job has suddenly, or gradually over time, increased in duration. Clearly, a variability in the data volume must be accounted for, but a measure such as ‘duration per 1000 records’ is something to watch over time to catch performance deterioration.
In addition, it’s important to track the delays between ETL steps, particularly if there are manual or manually-triggered processing steps in the ETL workflow. There is little point in performance-tuning an ETL transform step from 2 minutes down to 40 seconds if the following step is routinely not triggered until 3 or 4 hours have passed because the step is waiting for a member of the overworked team to inspect the output.
There are several possible ways to instrument ETL processes. In the Resources section, you will find articles describing to build instrumentation into SSIS packages, as well describing a tool called DTLoggedExec, a separate instrumentation tool for SSIS.
However, a general-purpose ETL instrumentation technique on the Windows platform may just require use of performance counters and PowerShell. This allows existing tools to monitor the progress and behavior of the ETL operation.
Improving Predictability
The foundations of predictable and stable ETL processes are:
- Proper planning for expected data volumes
- Understanding every ETL task that needs to run, and when it can run without blocking other tasks
- Parallelizing data extraction and digestion as far as possible
- Agreeing a data interface “contract” to prevent schema changes breaking ETL processes
Plan around data volume
One of the difficulties of many ETL processes is the volume of data that must be handled. The ETL team need to be able to estimate of the volume of data that the system needs to load now, and will need to load in a year from now, in order to plan for both current performance and scalability into the future. When ETL processes are chained, or run in parallel, a single process can, by running for an unexpectedly long time, affect other processes so that the total time period escalates.
Prevent excessive blocking/deadlocking between tasks
A fundamental challenge for ETL systems is that that they will often be running various tasks, with varying frequencies and durations. Some of these tasks need to run concurrently in order to complete the required processing in the allotted time window. Extraction tasks can run as frequently every 5 minutes depending on the reporting requirements. Likewise, transform- and load-related tasks will each need to run on a set schedule. Often, different tasks will compete for data in the same table. For example, at same time as importing today’s data into relational tables in the target database, another process may be reading data out of these same tables for export to an SSAS cube. In minimizing blocking as far as possible, timing and scheduling of the various tasks is crucial.
In his article, The ETL from Hell, Nigel Rivett describes a tactical approach to streamlining a chaotic ETL system, bases on establishing and documenting the following:
- Processing time windows – when does the data need to be available and when can processing start?
- A comprehensive task list, with dependencies
- External dependencies – e.g. on availability of external data source
- Internal dependencies – dependencies on other ETL tasks
- Grouping of tasks into “business threads” – for example, in Figure 1, one thread is the set of tasks required to extract data from the csv source, transform and load the data into the staging tables and transform and load the staging data into the data warehouse
- Measure “serial” processing time for each thread – establish size of problem
- Identify and tuning problem statements – add logging to a trace table for statements that may be an issue. Include number of rows affected, start and end time of a task, plus statement start and end times.
- Efficient batch scheduling/ parallelization – with automatic scheduling of each task, based on dependencies within fixed time windows, with build in logging and alerting
The most important task is to get as much baseline information as possible. How long is a process likely to take? What is unusual? It is a good idea to alter the schedule for a run so that a problem task runs on its own. This will give an idea of how long it needs and also whether or not it is affected by other tasks that are running on the system.
Parallelize data extraction
Some ETL systems have evolved to require that all data is ingested before the transformation phase begins. Sometimes this is necessary, but in situations where several independent data sets are being imported, this serialization can be unnecessarily costly if a problem is found in the extraction/ingestion phase.
In order to detect problems with inbound data as soon as possible, parallelize the extraction of data from independent data sources. When loading large volumes of data from a single source, it may also be possible to break down that source data file into multiple smaller files and process them in parallel.
Parallelizing data extraction as far as possible helps the team adopt a ‘fail fast’ capability. In the case of problems, they can choose to re-run just the failed data set, or even go ahead with the ETL processing for the rest of the data, rather than being forced to re-run the whole import.
Likewise, when querying (extracting) data in the staging tables, for loading data into the data warehouse, we should take advantage of database-level parallelization.
Prevent upstream data schema breaking downstream reporting systems
A very common problem with many ETL systems is a lack of predictability, and a resulting fragility that means frequent changes to the data scheme break the ETL process, so that the data is not available to upstream or downstream reporting processes when it is required.
Typically, the ETL team fits ‘between’ the source transactional or third-party data and the reporting teams, such as BI. ETL teams often have limited communication with teams that build or operate upstream systems on whose data the ETL processes rely. For external upstream systems, i.e. those belonging to other organizations, this is understandable if unfortunate, but in many organizations the ETL team has limited influence over changes to internal upstream systems too. For instance, a team developing a new user profile feature on a web-facing ecommerce system may have limited or no awareness of the needs of downstream systems such as ETL, and make a change to the OLTP data store that will break the ETL process on next run.
If a supplier of the data for ETL frequently changes the data format, it can be very difficult for the ETL team to distinguish real errors in the ETL processes from errors relating to the changing data, effectively leading to a continuously ‘moving target’ for the ETL team. This tends to be a particular problem when the data supplier is actually a paying client of the organization for which the ETL team works. The client will often supply the sales data, consumer credit data, purchasing data and so on in whatever form they like and expect the data processing organization to “just deal with it”, since they are paying for that service.
This is really a business problem that has a negative impact on the ETL team’s ability to improve the quality of the ETL processes. Without a schema or agreed data format, however loose, we cannot sensibly test the input data to an ETL system, and so we are beholden to apparently ‘random’ errors that are actually the result of the changing data format. This unrecognized data dependency between OLTP and ETL/BI systems can lead to conflict between not just teams but entire C-level budgets (CIO, COO, CTO and so on).
Insist on data format/schema standards for ETL
A key aspect of ‘fail fast’ for ETL is to have clear data format or schema standards against which incoming data can be tested. In essence, the consumer of the data, such as the BI team, agrees a ‘data contract’ with the supplier of the data, such as the ETL team, who in turn agree a data contract with the internal or external supplier of the data.
A lot of this work should be done during the early governance stages of a project. The governance activity will need to identify the downstream consumers of the data in the planning stage, and agree by discussion the full interface, based on the corporate data model.
The format specifications act as living documentation for the ETL system, detailing the nature of the data and also the areas of the inbound data likely to be problematic.
Agree data format changes by negotiation, not compulsion
Neither the ETL team nor the data supplier, especially if that supplier is also a client, should dictate changes to the data format, as this leads to avoidable wasted effort dealing with mismatching data. Instead, agree an approach where the impact of changes is understood and both sides work together to minimize the effects of new formats.
If a supplier cannot produce data to an agreed format, create an additional step in the ETL process to sanitize and check that data specifically, tracking that extra processing time carefully.
Use contract testing to avoid breaking downstream systems
A well-proven, although little-known, development pattern for groups of data producers and consumers is the Consumer-Driven Contracts pattern, which ” imbues providers with insight into their consumer obligations“, meaning that a team that provides a service or data gets ‘just enough’ of an insight into the needs of a team whose software consumes their service or data.
Consumer-Driven Contracts work like this: each team provides to the team immediately upstream a schema definition for incoming data, plus a test harness so they can test that any ETL changes don’t break the agreed data contract.
Consumer Driven Contracts
The use of ‘consumer-driven contracts’ to guide testing of explicit and implicit data contracts is based on ideas first articulated by Ian Robinson of ThoughtWorks in 2006, although used for many years prior to that by some teams. Martin Fowler discusses these ideas here: http://martinfowler.com/articles/consumerDrivenContracts.html
The ‘test harness’ might take many forms but, for example, the text-representation of most types of data, such as a postcode, or ISO-format currency value, can be tested by a regular expression (regex). A regex is, after all, merely a formalized language to describe text patterns. If the downstream consumer can tell the supplier of the data what the format is, then it reduces the likelihood of misunderstanding.
The provider of the data, such as the ETL team, will use a test harness supplied by the BI team, for example, to test any changes to the ETL process, getting early indication if their changes will break the downstream processes. When plugged into an automated deployment pipeline, the consumer-driven contract tests can act as a reliable ‘early-warning system’ to upstream providers: if the tests fail (go red in the CI system), then the team providing the data or service knows that they need to fix something because from the viewpoint of the consumer, something has broken.
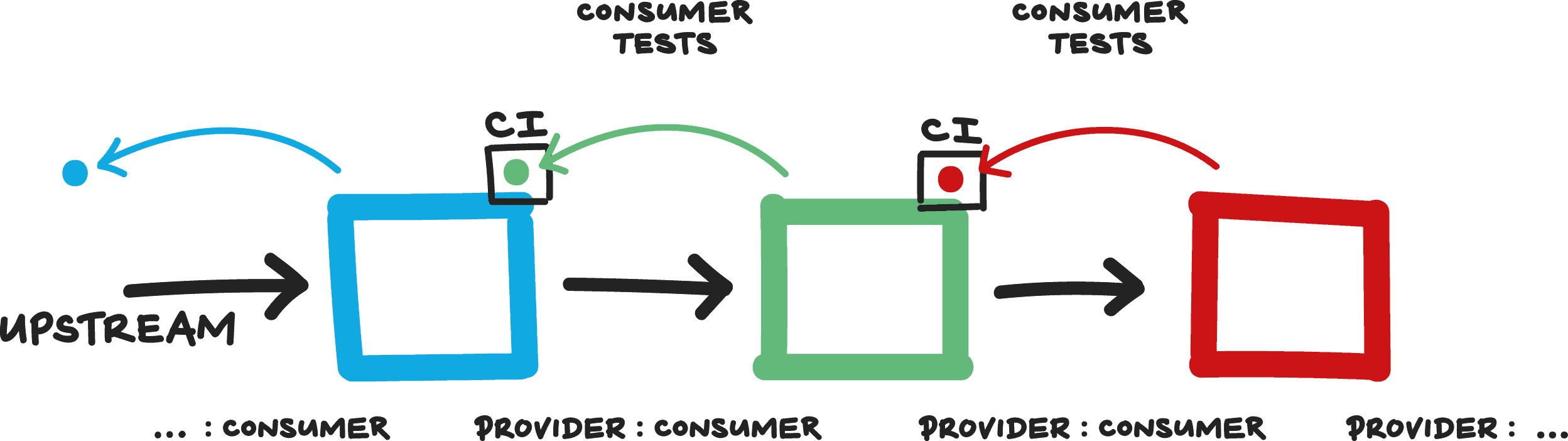
Figure 3
Similarly, the ETL team will act as a consumer of the data from upstream databases, providing a test harness to the development team responsible for the order processing application; the development team then uses the test harness from the ETL team in their deployment pipeline in order to check that any changes relating to the order application have not broken the downstream ETL processes.
Enforce validation checks during extract phase
Some ETL processes, like many fragile software systems, assume perfect, sanitized input data, and therefore may fail if unexpected data is ingested during the Extract or Transform phases. However, the failure may occur several minutes or hours, or even days, into the processing phase, necessitating the processing to be re-run after manual data fixes. This is a ‘fail-slow’ approach that can waste a significant amount of time.
For instance, if we know that data from one supplier is often ‘flaky’ for customer telephone number data, then we build an explicit check for that data field for that supplier’s data. By identifying faulty or problematic data early, we buy more time for fixing the problem, either within the ETL team or by pushing back to the supplier for improvements. If the incoming data contains errors detected by our schema or format standards, we can often shunt the data to a queue and carry on with other tasks until the data is fixed.
As discussed in the earlier section, Overview of ETL systems, one simple approach to data validation is to define constraints on the columns of the target tables and divert to a logging table any rows that fail to meet the constraint conditions.
Continuous Improvement of ETL Systems
Having tamed a misbehaving ETL system, we can begin during the various development cycles to introduce the DLM techniques that engender a culture of continuous improvement.
Implement fine-grained testing for each ETL task
Many ETL systems are not amenable to fine-grained testing at each stage, but require a full ‘end to end’ run in order to validate the processing rules. Of course, all ETL systems require full end-to-end testing; you’ll get many unpleasant surprises if you don’t check against the full expected load. However, if every test run is end-to-end then it leads to cycle times for improvements and fixes can be long. It also means that greater numbers of ETL programmers are needed than would be necessary with increased test coverage due to extensive rework of data loads.
We need to decompose the end-to-end ETL run into smaller, isolated sections, each of which can be run or re-run independently of the other stages. To help with this, we store the results from intermediate stages at least until the full ETL run has completed, and possibly a while longer, to help with defect fixing.
Alongside stage decomposition, we can use a standard, test-first approach to developing the transformation and processing code:
- Write a failing test that describes what the output should be but is not yet (as we have yet to write the code!)
- Write the simplest code that makes the failing test pass, using a small dataset targeted at that scenario
- Refactor the code to improve its modularity and focus
- Repeat from 1
With sufficiently small and focused data sets, it’s possible to evolve the ETL logic using a test-first approach without needing full end-to-end tests; one major benefit is that the tests capture clearly our expectations around what the resulting data should look like at each stage, helping us to reason about the processing required.
Consider using SQL ‘Unit Test’ frameworks for ETL code
Some ETL teams prefer to move processing logic out of the database and into application code, allowing them to use standard Unit Test frameworks such as JUnit, NUnit, and so on. For ETL teams that prefer to keep processing logic in some flavor of SQL, sensible use of a SQL unit test framework can help us to decompose our processing steps and retain confidence that all the steps are still working as expected, even when we make changes weeks or months later.
In conjunction with small, decoupled, focused tests, we can use a SQL ‘Unit Test’ framework for our ETL code (these frameworks are not really testing at the same ‘Unit’ level as application code is tested, but the Unit name has stuck).
The following table details some of the more common unit test frameworks and their availability by database vendor.
| DB2 | Oracle | PostgreSQL | SQL Server | ||
| tSQLt | http://tsqlt.org/ | Yes | |||
| SQL Test | http://www.red-gate.com/products/sql-development/sql-test/ | Yes | |||
| pgTAP | http://pgtap.org/ | Yes | |||
| SS-Unit | ttps://github.com/chrisoldwood/SS-Unit | Yes | |||
| SQL Unit | http://sqlunit.sourceforge.net/ | Via JDBC | Via JDBC | Via JDBC | Via JDBC |
| utpPL SQL | http://sourceforge.net/projects/utplsql/ | Yes | |||
| SQL Developer | http://docs.oracle.com/cd/E15846_01/doc.21/e15222/unit_testing.htm#RPTUG45000 | Yes | |||
| SQL Server Test | https://www.youtube.com/watch?v=MBB2dJKmQWU | Yes | |||
| TST | https://tst.codeplex.com/ | Yes | |||
| Quest Code Tester for Oracle | https://www.toadworld.com/products/code-tester | Yes | |||
| Ruby-plsql-spec | https://github.com/rsim/ruby-plsql-spec | Via Ruby | |||
| Db2unit | https://github.com/angoca/db2unit | Yes |
The essential premise with SQL Unit Test frameworks is that the stored procedure or function is the unit of testing, and that the parameters to the function or procedure act as the boundary.
Use small, focused data sets for testing specific conditions
A problem typical to many ETL systems is that teams either are not given the time or do not have the necessary experience to create specific datasets for testing purposes. There is often a sense that ‘the whole data set is needed’ in order to exercise the system sufficiently for meaningful pre-live testing.
Using a backup of the full dataset each time for testing tends to imbue the system with a kind of mythical aura that works against reason and decomposition, and hides details of how the system really behaves from both the ETL development team and the users (BI). This seems to be because when the team tries to use a smaller data set, certain problems are not caught during testing, and these omissions are then blamed on the lack of the full data set rather than the lack of specificity in the smaller data set. In other words, a series of smaller, more focused data sets can and should be used instead of the full data set for the majority of data use cases, and the full data set used only to identify new edge cases for upstream testing.
This is a general problem where an organization’s approach to testing is not advanced. It is not a problem that is specific to ETL alone, but becomes particularly problematic for ETL if the data volumes are large.
Fund ETL as enabling a key capability, avoiding time-limited ‘projects’
The ‘project’ funding model, with pre-allocated budget, a fixed scope, and a fixed deadline tends not to work well for the ongoing development and improvement of ETL systems (this holds for many kinds of software systems too, including BI). The reasons for this relate to the motivations of project managers and others involved in the initial project: because they are being measured on “time + scope + budget” rather than the effectiveness of the software system that results from the project, they have little incentive to improve the system, and every incentive to push through ‘workarounds’ in order to reach their deadlines.
Avoid ‘project’-based funding for ETL systems, and instead prefer a model that drives continuous evolution and improvement, with a funding ‘stream’ over 2 or 3 years. ETL provides an organizational capability around data-driven decision-making or data-rich applications, and should be funded as befits that capability.
Use Value Stream Mapping to highlight areas for improvement in ETL pipelines
Value Stream Mapping is a lean manufacturing technique popularized by Toyota and used to identify delays and bottlenecks in the flow of materials and execution of activities in the course of manufacturing a product. In the case of physical manufacturing, a Value Stream Map captures activities and delays from the raw materials, through the factory or assembly plant, to the transportation of the goods to the end customer.
Value Stream Maps help to target improvement efforts by highlighting the areas where time or materials are being wasted, allowing the organization to improve the areas that are actually bottlenecks, rather than guessing at where improvements should be made. It turns out that we can make use of Value Stream Mapping to help us identify waste and delays as we develop our software, a technique advocated by lean software experts Mary and Tom Poppendiek back in 2003 in their book Lean Software Development.
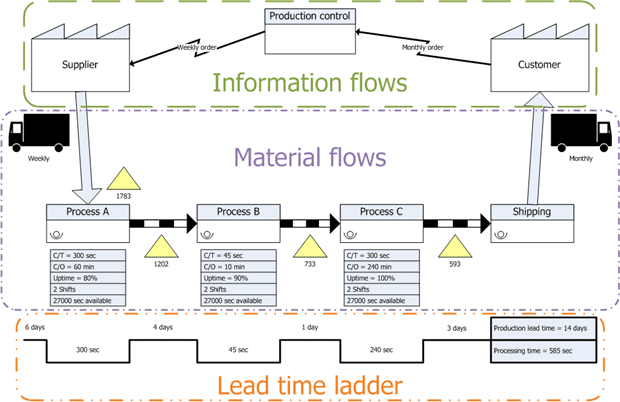
Figure 4 [Attribution: Daniel Penfield, CC https://creativecommons.org/licenses/by-sa/3.0/deed.en]
The sequential/pipeline nature of ETL lends itself very well to Value Stream analysis, highlighting delays and finding bottlenecks that can be related easily to business cost, in terms of rework, time-to-completion, or risk (such as missing a data processing deadline). For instance, if a team regularly waits for an ingestion task to complete, and that task blocks them from doing other work, then the task may be a candidate for parallelization. On the other hand, if an ETL team regularly has to wait two or three days for a new test server from the IT team, then that wait time can be identified as ‘waste’ and instead of automating a task, we would look at shortening the wait time for the test server.
Using a Value Stream Map fits well with the use of a deployment pipeline for ETL.
Summary
One of the advantages of putting a process such as ETL into the context of the lifecycle of the database is that the obvious is less likely to be missed. If our governance process is working well, we can design effective systems based on our knowledge of the appropriate source of data, its constraints, limitations, volume, rate of change, ownership and security requirements. We know the service requirements and the importance of resilience. With the help of operations, we can deliver ETL systems that are easily monitored, that alert appropriately when things go wrong, and are sufficiently economical with network, memory and CPU that they can expand to serve increasing workloads.
ETL systems can never be allowed to expand organically without stricture, like a coral reef. The result is almost inevitable chaos, usually at out-of-office hours when batch processes are generally scheduled. ETL is an aspect of the database where it is very easy to make a case for a collaborative approach based on Delivery, Governance and Operations to produce a system that is effective throughout its operational life.
Resources
- How to get ETL horribly wrong by Feodor Georgiev https://www.simple-talk.com/sql/ssis/how-to-get-etl-horribly-wrong/
- The ETL from Hell by Nigel Rivett https://www.simple-talk.com/sql/performance/the-etl-from-hell—diagnosing-batch-system-performance-issues/
- SSIS Design Patterns – ETL Instrumentation by Andy Leonard http://sqlblog.com/blogs/andy_leonard/archive/2007/12/26/ssis-design-pattern-etl-instrumentation-part-4.aspx
- DTLoggedExec tool for instrumenting SSIS by Davide Mauri http://dtloggedexec.codeplex.com/

DevOps, Continuous Delivery & Database Lifecycle Management
Go to the Simple Talk library to find more articles, or visit www.red-gate.com/solutions for more information on the benefits of extending DevOps practices to SQL Server databases.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments