
In first article in this series, Database Deployment Challenges, I described some of the challenges involved in database deployments. In the second article on the series, I described my solution to this problem, An Incremental Database Development and Deployment Framework. I defined the goals in developing such a framework, described its components parts and explained how they work together to automate database deployments. In the third article, Automating SQL Server Database Deployments: A Worked Example, I provided a simple practical example of a database deployment, using the framework, first creating an empty database and then upgrading it through three steps by writing T-SQL scripts, adjusting configuration files and the change log, before generating a full build script containing all schema objects.
Finally, here, I’ll wrap up coverage of my framework, and its use in database development and deployment, by delving deeper into the database scripting details that underpin its operation. I’ll describe how to:
- Script stored procedures such that we can update them without interrupting users
- Script object security and permissions in a manageable way
- Make use of configuration-driven scripts, and use them to handle situations such as deploying changes to multiple databases
- Use external tools with the framework to perform tasks such as bulk data loads
- Deal with problems such as version drift, arising from direct, unauthorized database alterations
Database Scripting within the Framework
When scripting out database for incremental development and deployment, we need to break the database into sub-projects. The second article in this series, An Incremental Database Development and Deployment Framework, described in detail the components and layout of a Database project, comprising:
- Database environment and structure – files, filegroups, partitioning objects
- Schema objects – tables, indexes, constraints
- Code objects used by client application – stored procedures, UDFs, triggers
- Static application data – such as list of provinces, for example
- Security configuration – roles, access rights for each of them and mapping of these roles to logins and users
Aside from the database projects, it’s possible to script, in separate projects, cross-database objects and configurations, such as replication objects. We won’t cover such projects in any detail here, focusing only on database projects. However, to give a flavor of how it would work, let’s say we have an OLTP database and a replica of it. We define both the original and replica in separate database projects. In a third project, a replication project with a different structure, we define the replication definition and maintenance. When time comes for deployment, we build the OLTP database and then the replica, from their separate projects, and then set up the replication from its project.
When we subsequently update the replicated environment, say to add a table to the OLTP database and/or replica, we define the new table and its replica in their respective database projects. We define in the replication project the new article/subscription definition, and so on, for the new table. To deploy the update, we remove replication from the target environment then upgrade both databases and set up the replication using the replication setup from the updated package.
Deeper into Database Scripting
In this section, we delve deeper into the details of scripting the database projects covering how to upgrade stored procedures without service interruption, security scripting, and how to write configuration-driven scripts. We’ll then consider how to define script and configuration files to:
- Deploy the same database with a different name
- Deploy simultaneous changes to multiple databases
- Use external tools during database deployment, for example to import static data
Scripting Stored Procedures
When scripting the creation of, and changes to, stored procedures, we should consider the following issues:
- We must use the same script for the stored procedure creation and update
- During live rollouts, the database may be in use, during the update
- Backward compatibility with the previous client application versions
Routine Script Template
The most common approach to the stored procedure (and UDF) scripting is “drop-if-exists-the-create-new”. With such an approach, there is always a short period between dropping and recreating the procedure. In addition, after recreating the object, we must also reapply the appropriate permissions so that users can access it. If the database is in use while we’re applying the update, there will always be a period where the object is unavailable. If the user manages to call the procedure during this period, SQL Server will report an error, breaking the user’s operation. The heavier the user workload, the more likely this interruption will affect users.
To avoid such interruption, we can update the procedure using the ALTER command, so that the user permissions remain unchanged. If a user happens to make a call during the update, SQL Server will simply delay the call until the procedure compiles, so it won’t result in a failure and error message.
Of course, if the procedure does not yet exist, an ALTER command will produce an error, but we can avoid that by starting the script with a stub creation routine that executes only if the procedure does not yet exist, and creates the object stub.
The code must skip the stub creation routine if the previous version of the routine exists. We cannot combine the CREATEPROCEDURE command with other commands in the batch, so we cannot put into an IF...BEGIN/END block. Instead, we can use EXECUTE() or GOTO or SET NOEXEC ON/OFF to put that stub command into its own batch. Listing 1 provides a template for a stored procedure creation/modification script, and adopts the latter approach.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
IF OBJECT_ID('ProcNameHere') IS NOT NULL SET NOEXEC ON GO -- if the routine exists this stub creation stem is skipped PRINT 'ProcNameHere: Creating routine stub...' GO CREATE PROCEDURE ProcNameHere AS PRINT 'ProcNameHere: Not implemented yet.' GO -- the following section will be always executed and the routine (or the stub) will be updated SET NOEXEC OFF GO PRINT 'ProcNameHere: Updating routine code...' GO ALTER PROCEDURE ProcNameHere -- here are all the parameters if needed AS BEGIN -- here is your code PRINT 'ProcNameHere ... running ...' END go PRINT 'ProcNameHere: Routine code updated.' go |
Listing 1: A template for creating or altering a stored procedure
Handling Client Backward Compatibility
The template in Listing 1 allows for a live database update, but the changes to the routine it still might affect the client application.
Consider a system with multiple application servers and a database server where we need to update the system while still serving the clients i.e. without stopping it completely. In most cases, this should be possible. First, update the database(s), then stop and upgrade the application servers one-by-one.
However, it’s possible that a new release contains both database and application changes but where the current application clients will not work with our updated stored procedure. To avoid that issue, follows these simple rules:
- If a stored procedure modification only fixes some bugs without changing the previously declared purpose, then the updated procedure will be compatible with both old and new releases.
- If a stored procedure gets new parameters or its behavior changes significantly then we must create a new version of it, in a separate script. We can rename the stored procedure to reflect the change, or just add a version suffix. Clients still running the current application version can use the original procedure, and updated clients can use the new one. In the next release, having updated all the application servers, we can remove the old stored procedure.
Scripting Security and Permissions
One may be tempted to script object (e.g. stored procedure) permissions in the same file as the object. However, a problem arises when someone needs to check on all the permissions in the system. This approach makes it quite hard to verify them by analyzing the source code. Sure, we can collect all the necessary information from the database once created, but then we must find who assigned permissions on what objects, and when, and why.
Another approach might be to encapsulate all security configuration steps for a database within a single T-SQL script, or stored procedure. In simple cases, this might work well but in cases where different target environments use different user names and logins, such a script becomes a burden, because we cannot test them properly. The reason is that they usually consist of code blocks that execute only on the specified server (i.e. test, or production), so they may work in the “lower” environments but fail unexpectedly in production.
A better approach is to provide the security settings separately from the code, in a cleaner logical form. This way, we can group together the appropriate permissions so the intent is obvious, even when presented for analysis to non-DBA people.
Therefore, my Incremental Deployment framework defines the security and permissions as a set of configuration files, and the deployment utility applies these settings appropriately. If we wish, we can define these security settings as a project separate from the Database project that describes the storage structures. However, I prefer to define security and permissions along with the rest of the database code.
Let’s examine why we need a set of configuration files rather than just a single file. In many projects, the security configuration is role-based. It is much easier, especially in terms of maintenance, to grant object permissions to database roles than it is to grant permission on a user-by-user basis. The same is true for the logins: it is much easier to operate with Windows groups than with individual logins.
The SQL Server security model, described simply, consists of two levels:
- Server-level access – defines the Windows accounts, SQL users, and their server-level privileges. The users/logins defined at this level may differ across the company. For example, test and production accounts should not be the same.
- Database-level access – defines the database-level permissions users for the server-level users. Also defines he database roles and permissions granted to them. The rules defined at this level should be the same in each database copy.
Therefore, it is a best practice for configuration files to reflect that separation with our security configuration consisting of two parts:
- Database role and permission configuration – lists all the roles for the database with all the permissions granted for each role
- Server login and database user configuration (plus the deployment tool) – lists all the logins and/or SQL users for that particular database environment along with the databases they can use and roles to which they are assigned within these databases
As discussed previously, the information in server-level login/user configuration file is environment-specific, meaning that each particular target environment (identified by the server\instance name), may use a different login or a Windows group for the same set of database roles.
How is that configuration data used? In the simplest possible case, we drop and then recreate all the database permissions and roles. The problem with this approach is that it could cause an outage for users who may not be able to use the database during the security update.
To avoid such an outage, a more realistic approach, and the one our deployment tool (DBCreator.vbe) uses, is to compare the desired configuration against the target environment and to synchronize them. This way all the applications are kept running, those that must be stopped are stopped and those that will be deployed upon the database update will have necessary permissions ready for them.
Configuration-Driven Scripts
Many components of the database project, like tables, are environment-independent and quite easy to script. Others, such as user logins and database file configuration, will differ from environment to environment and require more thought. The best approach is to use separate configuration files that define such components, for each environment. As an example, our deployment utility (DBCreator.vbe) then simply picks and uses the appropriate settings.
Certain less generic tasks can also benefit from the use of configuration files, such as a data extract or load process, or some automation process. In such cases, it’s rarely worth developing a dedicated application but a simple configuration-driven script, or set of scripts can help, since the user can simply modify the input files without touching the SQL code. In fact, all of the user-executed shell scripts (.cmd files) in our framework, used to perform particular operations on the database such as create a new database, update its structure, and so on, are configuration-driven scripts.
The introduction of scripting variables to SQLCMD made configuration-driven scripting in T-SQL much easier than ever it was with the OSQL utility. Let’s review a simple example. Its purpose is to print data from a table. This example will consist of three files
- The T-SQL script, incorporating SQLCMD variables used as needed
- An
.INIfile with database connection parameters defined in the form of “name=value” pairs - A batch file which reads the values from
.INIfile and executes the T-SQL script
For example, let’s say we have an imaginary T-SQL script named SampleSQLScript.sql in which three parameters are used: DatabaseName, SchemaName and TableName:
|
1 2 3 4 5 6 |
--:setvar DatabaseName "msdb" --:setvar SchemaName "dbo" --:setvar TableName "sysjobs" SELECT * FROM [$(DatabaseName)].[$(SchemaName)].[$(TableName)] AS t |
Listing 2: A configuration-driven SampleSQLScript
The three SQLCMD variable definitions (:setvar) are commented out since we will pass values for them from a batch file. The script.ini file provides values for these parameters, via the following two lines (each line starting from the first character):
|
1 2 3 4 |
ServerName=SERVER_23 DatabaseName=msdb SchemaName=dbo TableName=sysjobs |
Listing 3: The Script.ini file
Then the batch (.cmd) file would look something like this:
|
1 2 3 4 5 6 7 |
set CnfFileName=script.ini for /F "usebackq eol=;" %%s in ("%CnfFileName%") do set %%s sqlcmd -S %%ServerName%% -E ^ -i SampleSQLScript.sql ^ -v DatabaseName=%%DatabaseName%% ^ -v SchemaName=%%SchemaName%% ^ -v TableName=%%TableName%% |
Listing 4: The #SampleSQLScript.cmd file
For those unfamiliar with the command-line tools, this batch performs three simple steps:
- Assigns the name of the configuration file to an environment variable
CnfFileName - Traverses the content of the configuration file (with
FOR /Fcommand) and treats each line in that file as a definition of a new environment variable with given value - Calls a T-SQL script using SQLCMD utility using the variables defined in the previous step (note that the caret “
^” symbols simply indicate that the command continues on the next line).
These configuration-driven scripts are also useful in cases where we wish to execute same command multiple times with different parameters. Our .INI file could contain a tab- (or comma-, or semicolon-) delimited list of parameters. For example, let’s say we have a TablesToExport.ini file, with a list of tables and the file names to which to export their data.
|
1 2 |
Customers.dbo.ClientsArchive ClientsArchive2015.txt Products.dbo.ProductCatalog2014 ProductCatalog2014.txt |
Listing 5: The TablesToExport.ini file
In our batch file, instead of writing separate line to export the table data using BCP, we can use the same FOR command.
|
1 2 3 4 5 |
echo Getting list of tables to unload from " TablesToExport.ini" file. for /F "usebackq eol=" %%a in ("TablesToExport.ini") do ( echo Unloading table %%a into file %%b bcp %%a out %%b -S . -T ) |
Listing 6: The batch file for exporting data
We can even pass configuration scripts as parameters. For example, we can provide database connection parameters in one .INI file and the list of input parameters in another so that the user specifies just the appropriate file rather than the parameters themselves.
For a more complicated configuration structure, we need a more sophisticated tool, providing better error handling and so on, but for the most of such simple tasks, the mechanism in the examples above is more than enough.
Handling Database Name Mapping
In some environments, different teams or users share a single SQL Server instance, which may be used for several purposes such as for development and testing, or for different kinds of testing, such as for regression and user-acceptance testing. In such cases, we need to deploy the same database project under different the target database name.
All the configuration files in the framework, including the change log, specify the database name as an XML attribute, as shown in Figure 1.
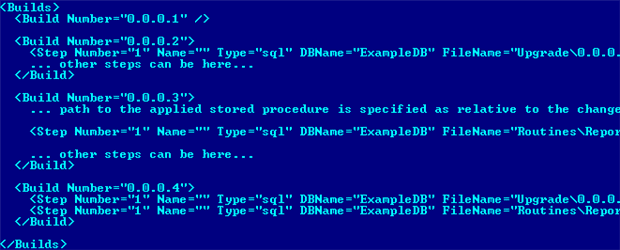
Figure 1: The DBName attribute, in the Change Log
Therefore, we have a “logical” database name, used in the project, and a “target” database name on the server. By default, the deployment utility will deploy a database with the “logical name”. However, using a dedicated configuration file, ExampleDB\Scripts\ExampleDB.DatabaseNameMappingUAT.config, we can instruct it to use a different one, as shown in Listing 7.
|
1 2 3 4 5 |
<LogicalEnvironment id="User" Acceptance Test Databases"> <Database NameInConfig="ExampleDB" NameOnServer="ExampleDBUAT" /> </LogicalEnvironment> |
Listing 7: Database name mapping in DatabaseNameMapping.config
The NameInConfig attribute specifies the logical name used throughout the project and NameOnServer specifies the name for the target database eon the target SQL Instance.
Developers must consider this mapping mechanism when coding the database scripts. In order to ensure this mapping works, T-SQL scripts should not explicitly switch to any particular user database (system ones like master or tempdb are OK). Furthermore, dynamic scripts should never hard code the database name, but rather accept the name as a parameter, or derive it from the current database name.
Another point to consider is that the physical files names for the new database must be unique, otherwise the system would report that the file exists already. For this reason, our DBName.FileLayout.config file uses placeholders, {{DBNAME}}, as shown in Listing 8. When the deployment utility, DBCreator.vbe,creates the database, it will substitute it with the target database name.
|
1 2 3 4 5 6 |
<Filegroup id="primary""> <File LogicalName="PrimaryDataFile_01" PhysicalName= "R:\SQL\DATA.2008\{{DBNAME}}_{{FGNAME}}_{{FILENAME}}.mdf" InitialSize="5MB" Growth="2MB" MaxSize="1024GB" /> </Filegroup> |
Listing 8: Use of placeholders to ensure unique database file names
In order to see this in action, we simply need to create a mapping file for each target database name. Let’s say it will be ExampleDB.DatabaseNameMappingProduction.config and ExampleDB.DatabaseNameMappingUAT.config. In the first one, we set the NameOnServer attribute to ExampleDBProd and, in the second, we set it to ExampleDBUAT. In both, update the logical environment name as appropriate (or use “Default” to deploy the new database to your default environment, as defined in ExampleDB.FileLayout.config). See Listing 7 for an example.
Before running any of the deployment utility commands, we must specify the correct one in the DBCreator.ini file, commenting others, as shown in Listing 9.
|
1 2 3 |
DbNameMappingFile=Scripts\ExampleDB.DatabaseNameMappingUAT.config #DbNameMappingFile=Scripts\ExampleDB.DatabaseNameMappingDev.config #DbNameMappingFile=Scripts\ExampleDB.DatabaseNameMappingProduction.config |
Listing 9: The DBCreator.ini file
Having done this, execute “#Create database(s).cmd“. Once complete, run “#Get build number.cmd” to confirm that the database build number (if you worked through to the end of the previous article in the series, the build number will be 0.0.0.4).
Deploying Changes to Multiple Databases
There are two distinct scenarios where we may want to use this framework to deploy changes to multiple databases, simultaneously. In the first, there are several databases within the project, which together we need to treat as a single unit. For example, there could be a project with a database for the OLTP transactions, and a separate database for reference data (client, validation lists, and so on). We develop them together, deploy them together, and they all have the same build number, and so on. This is an unwise decision that eventually runs into serious problems. Eventually, in the project lifetime, some of the databases will require a change that we must deploy immediately, before changes to the others are complete. At this point, we need to split the monolithic database project into smaller, independent ones. Therefore, while we can perform such changes through the framework it is not a recommended way of using it. It is better to develop each database as a separate project. For example, let’s say we have a system which uses ten databases, the application developers need six of them, the rest are reporting database that the application does not use directly.
How do we make it simple for a non-DBA to deploy such a multi-database project? We need a way to track the list of databases, their expected current version, location of the scripts to build/update the database and some mechanism to exclude some of them easily. In addition, we must be able to use the database backups for each of the six databases from the previous release, so we upgrade these databases to the current version, effectively rehearsing what we plan to happen in the next release deployment.
In other words, we need a mechanism to update these databases that works as follows:
- Traverse a list of the databases
- Find the location of the database project file
- For each database:
- Drop from the target server the existing database copy (if it exists)
- If the database is created in the prepared release:
- Create the database using the database creation script
- If the database is updated in the prepared release:
- Restore the database backup from the previous release
- Upgrade the database using the database upgrade script
- Check that the database version matches the desired version
- Report the execution status – if all databases have the desired build numbers, report success, otherwise, failure.
The simplest option is to use configuration-driven scripts, as described previously. The configuration for such a script would define:
- The target server
- A list of databases, with these characteristics:
- the location of the database project files (the scripts and configuration files for each database )
- The operation needed for a particular database (i.e. whether it must be created from scratch or restored from the previous release backup and then upgraded)
- The previous version backup file location for the existing databases
- The current database version for each database, so the script can report any inconsistency between the desired state and the actual state
It is the databases developer’s responsibility to maintain the configuration and associated files so that the database versions, location of the backup files and so on are all up-to-date.
Having done all this, the end user (i.e. application developer or tester) only has to know how to:
- Download a folder with the database projects from the source control system
- Start the tools described above
- Determine whether the process succeeded or failed
Using External tools with the Framework
Sometimes the database build/update process requires usage of external tools. For example, we may need to call an SSIS package as a part of the upgrade, or to load some data using BCP utility. The change log and other configuration files in the framework support use of a special step type, called “cmd“.
To demonstrate how this works, we’ll return to the ExampleDB database project from the previous article, Automating SQL Server Database Deployments: A Worked Example. We’ll create a new Countries table, and then load it with data from a text file.
In the “…\ ExampleDB \Scripts\Upgrade\0.0.0.5\” folder, we must add the scripts to create the table (01.Create Countries table.sql) and load the data (02.Load Country List.cmd). Listing 10 shows the latter. This CMD file contains a reference to the source data file as a relative path from the CMD file location (i.e. the text file is in “…\ ExampleDB \Scripts\ReferenceData\“.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# This is an example of the configuration-driven script # It expects the target server and database name as parameters set ServerName=%1 set DatabaseName=%2 set SourceFileName=..\..\ReferenceData\CountryListISO-3166-1.txt bcp dbo.Countries in ^ "%SourceFileName%" ^ -S %ServerName% -T ^ -d %DatabaseName% ^ -c -C1252 -t |
Listing 10: The CMD file to load the data
Note that older versions of bcp don’t support the -d parameter, in which case remove it and qualify the table name with the database name (i.e.bcp ExampleDB.dbo.Countries...).
In the change log, we must include the step to create reference both the SQL script to create the table, and the special cmd step type for the data load. Listing 10 is an extract from the change log and shows the “cmd” step.
|
1 2 3 4 5 6 7 |
<Build Number="0.0.0.5"> <Step Number="1" id="Type=""sql" DBName="ExampleDB" FileName="Upgrade\0.0.0.5\01.Create Countries table.sql" /> <Step Number="2" id="Type=""cmd" DBName="ExampleDB" FileName="Upgrade\0.0.0.5\02.Load Country List.cmd" CommandLineParameters="%srvname% %dbname%" /> </Build> |
Listing 11: The Change Log, containing the cmd step
In order to try this out, you’ll first need to create ExampleDB database. If you didn’t work through the previous article, then you can extract into a folder called ExampleDB the contents of the “05.New DB Creation with All Objects” folder in the coddle download bundle with this article (see the speech bubble to the right of the article header), and then follow the instructions in Step 5 of the previous article.
Having done this, copy over the contents of the existing ExampleDB folder the contents of the “06.Data Load” folder from the code download, a pre-prepared package that contains in the appropriate locations the new .sql and .cmd and .txt files, as well as the necessary additions to the change log.
Run the “#Update database(s) and security.cmd” file and you should see a new table dbo.Countries created in ExampleDB database containing 20 records.
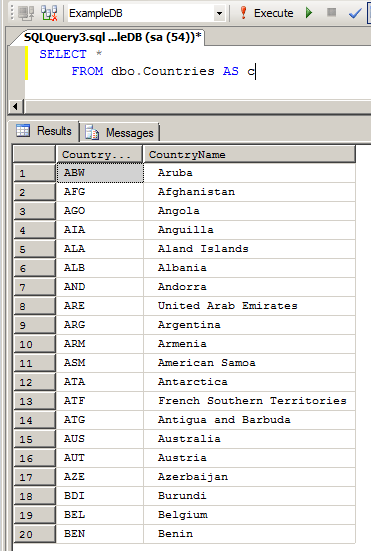
Figure 2: Verifying the data load for the Countries table
In this way, we can use any tool that we can call from the command line as part of the upgrade. We can test the CMD file separately and re-use it to run the same command set, later on. Inside of this batch file, we can execute SSIS packages, create folders, copy files, and so on.
The example above illustrates suggested usage of that functionality. Instead of making long T-SQL scripts inserting the initial (static) data into the system I created a simple package that loaded that data from an Excel file. It is possible for the business users, i.e. the business analysts, and configuration managers, to maintain those lists and relieve the DBA from the nightmarish task of updating multi-megabyte T-SQL scripts.
Another example of where we use an external tool as part of the deployment is in Step 5 of the previous article, where during full build code generation we use SQL Compare. The ExampleDB\Scripts\ExampleDB.SchemaScripting.config file points to a batch file calling SQL Compare with all the necessary parameters.
Framework Best Practices
We’ll finish up with some practical tips for getting the most out of the automated database deployment framework, with minimal issues.
Avoiding Version Drift
As we’ve discussed in previous articles, there must exist in the database some attribute that can show us, quickly and unambiguously, the database state. Such an attribute must be easy to retrieve and easy to understand, by any person in the team.
Other system parts (DLLs, program files, etc.) usually have their version number or build number embedded into them and we simply apply the same idea to the database. The basic premise is that if two database copies have the same build number, then they are identical, even to the point that they have identical filegroup and table structure, and identical set of routines, and the same system data. However, two database copies with the same version number can still have different characteristics, specific to the target deployment environment. There could, in other words, be differences in the operational data, in the security configuration (logins/users) or the physical file characteristics (file names, growth rate, and so on), but none of these are considered to be part of the database state (version). In our framework, we store this ‘state identification’ attribute in a database extended property (user-defined).
Successful use of this framework to transmission from one database version to another described relies on the fact that it we use it for all database deployments. It is important to ensure that the database we wish to update is at the appropriate version before the deployment and if someone modified the database directly, without using that deployment tool, then the build number is, in effect, corrupted.
Therefore, we must capture any unauthorized database modifications and, for this purpose, a database DDL trigger is our best option. This type of trigger catches all DDL commands and modifies the database build number if the command is not in the permitted list. We can add to the database extended property value the details of the operation, or we can add these details to a history audit trail. For legitimate changes, the deployment automation tool should simply update the version number attribute with a proper value, once it has completed successfully.
The trigger is included as part of the code download package (in …\ExampleDB\Scripts\Routines\Triggers). Here is how it works. If you ran the previous example in this article, you will have deployed an ExampleDB database, with database build number 0.0.0.5. We can confirm this by checking the Extended Properties value in SSMS, as shown in Figure 3.
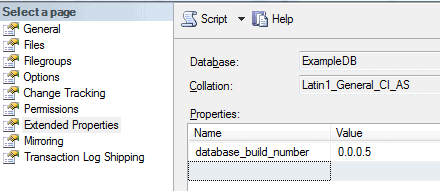
Figure 3: Confirm the value of database_build_number for ExampleDB
In Listing 12, we modify the Reports table directly, rather than through the framework.
|
1 2 |
ALTER TABLE [Reports].[ReportHeaders] ALTER COLUMN ReportType varchar(255) NULL |
Listing 12: Direct modification of the Reports table
Our DDL watchdog trigger modifies the database_build_number property, leaving the version number unchanged but adding text to describe the changes and who made them.
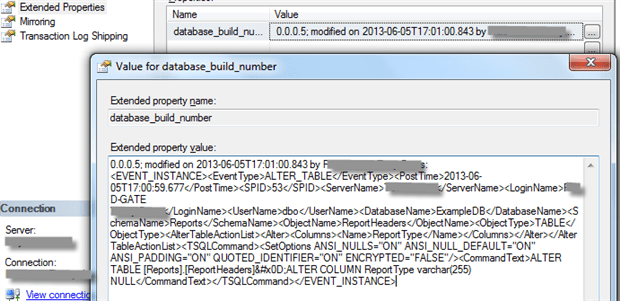
Figure 4: Detecting unauthorized database changes
The extended property value filed is limited in size to about 8K, so it cannot capture any subsequent changes, but at least we always capture the initial unauthorized change.
The deployment tool should, when run against such a database, fail to identify the correct database build number and exit with an error. Somebody then has to see what was changed, bring the database back to an appropriate state, and then set correct build number.
If a direct database modification is unavoidable, for some reason, then we must propagate the change back into the database project. The administrator, in that case, marks the database with some build number, and the change is included into the change log with that number. Of course, this has further implications, such as the need to re-test the project, refresh all of the environments refresh, and so on, but it still better then have an undetected change creeping into database.
Handling Deployment Rollbacks
Occasionally, despite our careful testing, a deployment may cause unforeseen problems that man we need to roll it back. At one point, we tried to provide, via the framework, an automated way to roll back to a previous version, for example 0.0.04 to 0.0.0.3. However, we have since removed this functionality simply because the added demand for complete functional testing of the database in its “post rollback” state proved too onerous in terms of the time and resources required for this testing.
Instead, we have two options, in response to a failed deployment:
- We backup the database just before each deployment, so we can simply restore that backup.
- Provide “hot fixes” through the regular update process.
Unit Testing
We perform unit testing of database code and objects, and then perform system unit testing. Many development teams perform regular unit testing of the application code, but rather neglect unit testing the database code and objects. One reason is the relative lack of dedicated tools for database unit testing. A database developer must write .NET unit tests or use any of the available database testing frameworks, such as t-SQL-t (http://tsqlt.org/). The tool I use, for database unit testing within our framework, is DbFit, originally developed by Gojko Adzic (https://github.com/dbfit/dbfit) and currently maintained by Jake Benilov (http://benilovj.github.io/dbfit/).
This tool simplifies database unit testing greatly. It requires no .NET coding; the tests themselves are simply tables of input and expected output parameters. No DBA skills are required to run them. We can organize test data also nicely, for re-use in multiple test cases. With DbFit one can test the code (stored procedures) as well as the table constraints, data types, and so on.
By incorporating unit tests for our database code and objects, we can automate the re-deployment of a database. In the test environment, the build process gets from source control system all the database project files, backups of the database from the previous releases, and then restores these databases, updates them to the latest version, and builds any new databases, if required.
The framework allows us to create an environment for such tests, because the database deployment results are repeatable; we get the same result regardless of the environment. Therefore, we can extend the unit-testing results to other environments.
Code Development Do’s and Don’ts
Finally, this section summarizes some of the more important coding rules to follow, for successfully database deployments via this framework.
DO…
- Create each stored procedure, function or trigger in a separate file (we can make an exception for code generated in bulk from a modeling tool where we have a large number of objects and don’t expect individual object modification).
- If you need to modify an object, previously bulk-generated, remove it from the generated code file, save in a separate one and maintain it separately from that point on.
- Register all stored procedures in the change log configuration file, so that the deployment tool will detect them, through the
Environmentconfiguration file, and deploy them. - For a full-build-from scratch (see step five in the previous article), remember to list any modified stored procedures, or other code objects, in the
CodeObjectsconfiguration file - Write the scripts to create or modify code objects (stored procedure, UDFs, etc.) in such a way that they execute without error however many times you do it. That is, the script should successfully create or update the routine regardless of whether or not it already exists. See the stored procedure-scripting template, earlier in this article.
- In scriptsto load or modify data, first check for the existence of the data
- Use print messages in the scripts to describe verbosely each step of its execution (existing version of procedure, detection and deletion, description of the data inserted, and so on). The framework logs all output, but it helps troubleshooting deployment issues.
DON’T…
- Switch context to a particular database (except for the system ones, like
masterortempdb) as it will invalidate database name mapping. The “logical” name of the database against which we wish to execute the script must be executed is specified in the configuration file referring to that script, so the deployment tool will automatically switch to the appropriate database. - Use hard-coded database names. Again, this would break the framework’s database name mapping functionality. In most cases, cross-database references hard-coded into stored procedures, or any other code, are a “code smell, indicating flaw in the system architecture.
- Assume any physical file name for the database data and log files. Design scripts to have these specified by parameters in the same way as database names. Use substitution placeholders for the database/filegroup/logical file name (see the Handling Database Name Mapping section, earlier in this article).
- Assume any particular database option set. If, for example, the procedure needs to have the
QUOTED_IDENTIFIERoption set toON, then the script should set it and not assume any settings. The script would provide consistent results regardless of the target server settings. - Set permissions in the code. There are dedicated configuration files responsible for the database security.
Summary
This article completes my coverage of the incremental database development and deployment framework. I hope it will help you make database deployments quick and repeatable, so you get the same result each time you run the same deployment, regardless of environment (production, test, development, and so on).
If you have any feedback, or feature requests, I’d love to hear it. Just leave a comment below, and I’ll respond.
Load comments