
The previous article in this series, Database Deployment Challenges, reviewed some of the common techniques for deploying new databases, and upgrading existing ones, including their various shortcomings. It emphasized the need for a simple, script-based approach to reliable, repeatable database deployments.
In this article, we’ll take a “big picture” look at the solution I offer, essentially comprising a set of scripts glued together with environment-aware configuration files. It relies on a combination of the techniques described in the previous article, in the sections “Database Creation from Multiple Scripts” and “Change Log-based Automated Upgrade“. As a whole, it offers a database development and deployment framework that supports an evolutionary (incremental) database development approach, and so fits well into an “agile” development methodology.
This article will provide a basic overview my framework and its main components, covering:
- Goals of an Automated, script based deployment solution – what we set out to achieve
- An overview of the structure of the framework and its major component parts:
- version control
- database modification scripts
- configuration files, including the change log
- the automated deployment utility (a
.vbsscript, in our example)
Included in the code download for this article (see code download bubble to the right of the article title) is a database project, including examples of all the scripts, utilities and configuration files referenced throughout. Feel free to download and start exploring it, as you read this article, and the next article will provide a full walkthrough of the process of creating a completely new, empty database, incrementally upgrading it through various sub-builds, and then generating a full build script.
Goals of an Automated Script-based Framework
My team needed a simple, automated, script-based way to smooth out the process of both building new databases from scratch, and to making incremental changes to existing databases. The following sections describe our most important aims.
Database Source Control
We wanted to store the database project in a source control system. Every official version of the database project must be in Source Control and in a manner that made it very easy to establish which scripts we required for which build, and in which order we needed to apply them. We wanted to banish forever the days when we’d need to search around in Source Control – or worse, on the developer’s machine – for the correct files.
Central to this mechanism is some form of Change Log (also stored in Source Control, and discussed in more detail later), which tracks all changes to the database structure and its static data.
We include in Source Control:
- The database DDL code and the database build script, including all database settings where there is one database to one application
- The application interface within the database (stored procedures and so on)
- Scripts for reference data, database configuration, users and scheduled tasks
- Build scripts for each major release, and migration scripts between releases
- All scripts used for testing and deployment
Easily Identifiable Database Build / Version Numbers
We needed a way to make the database state/version easily identifiable. Two databases carrying the same build number should be identical in their structure, code and static data. The idea is to have some value, such as a string or number, which could serve as an identifier. It is not, strictly, necessary to have an incrementing value because the Change Log, rather than the build number, defines the order of the builds. Nevertheless, it is worth assigning numbers or characters to the builds in some order so you can see quickly which is the later of two builds.
It must be possible for the build application, or script, to query the current version of a database so that it can apply the correct tested script to roll forward or roll back the database, whilst preserving the data within it. Most third-party deployment tools require a method for attaching a version to a database application.
Unfortunately, there is no single, established way to associate a database with a version number. We can store this version number as a value or structured document (e.g. XML or JSON) in an extended property of the database, as a table in the database itself. Bear in mind that we must store this number within the database, not in master or any other ‘central coordinating database’, so that the version number is carried with the database into backups, without losing the context.
The problem with storing the value in the database itself is that it’s not always possible; for some projects, it’s not possible to make any changes in database structure, without extensive modeling work to get it through the review boards and other processes. In this respect, it’s easier to justify to the client the existence of a database extended property than a new table.
Note that for a complex database, it is quite possible for the application interface (normally in a separate schema) to be maintained as a separate version to the database, since it needs to keep in step with one or more application. It is perfectly feasible in a large database for schema to be versioned separately. Also, note that if a production database contains extra objects, over what is in source control, (e.g. Replication objects), then it will not be completely comparable to the version in source control.
Change Control (avoid version drift)
We wanted to establish change control authority; in other words, for this solution to work there must be no other change in the database structure or code in the database(s) to be performed other than those determined by the deployment mechanism.
Version drift (or Version-creep) is the name given to the habit of ‘patching’ the production database to make any type of change, outside of the proper deployment mechanism. At the simplest level, when we detect version-drift, we are discovering that the version in production is not the version we think it is. The change could be as innocent as adding or changing an index to aid performance, but we can’t take that for granted. If we find changes in a production system that weren’t there when the deployed that version then we need to investigate this issue. See http://www.simple-talk.com/sql/database-administration/database-deployment-the-bits—database-version-drift/ for detailed discussion on this topic.
As a protection from such side hacks, we ought to create a DDL trigger in the database that modifies a build/version number whenever someone makes an ‘unofficial’ change, so that it would not match any build recorded in the Change Log. An example of such trigger is included with the current implementation of the framework. In the code download for this article, this trigger is created with the database (though we won’t discuss this further until a later article).
Repeatable Deployments
The deployments must also be repeatable; that is to say, the actions to bring a database from one state to another should be the same in any server environment. We use the same package to promote changes to all the environments, from development up to production.
In order to achieve this, we had to:
- Make it easy to configure any environment-specific parameters – such as the location of the database files, their size, growth rates and so on
- Remove all environment-specific statements from the code/scripts – so that any change of the configuration did not involve any code or script change
- Make the security configuration clear and easily maintainable – load security (logins, roles, database object permissions) from configuration files, not in T-SQL scripts
I know from bitter experience the pain that can ensue when no one executes, or tests, the branch of the code that involves the production server name, until it was time to create the production environment. It may sound like common sense to separate data and code, but in SQL Server development, it is not always that common.
One-Click Deployments
It should be a simple “one-click” process to deploy a database from scratch in any known state (build/version), to upgrade an existing database, or to roll back a database to the state in which it existed at a previous point in time, such as the release state in a previous build.
If we require a full database build, from scratch, then the deployment process must automatically create the database, the schema objects such as tables, code objects, such as stored procedures, assign relevant permissions, load the initial data and assign a new build/version number.
For an incremental build, the process must retrieve the current database build number from the target database, interrogate the Change Log for the required scripts (which includes both structure and stored procedure changes) and redefine permissions as per the configuration files (and then stamp the database with the build number).
Rolling Back Deployments
Ideally, the process to roll back a deployment would be simply a “reverse” of the deployment process. In other words, it would be a one-click process that reads the Change log from bottom to top and “undoes” each step.
In fact, our framework did support this functionality at one point, but we have since removed it for logistical reasons. In short, it is a big undertaking to implement complete system regression testing, to ensure the consistent state of the system post-rollback and we could not get agreement to implement such testing for the rare event of a rollback.
In the case of a “failed” deployment, we simply restore the database(s) from the previous backup, if possible. If the users have been working on the database for some time and cannot tolerate such a recovery, we prepare a “hot fix” upgrade, prepared and promoted within the same framework in the usual manner.
Remove Specialized Knowledge from the Deployment Process
Inherent in the desire for a simple, repeatable, automated deployment process was a desire to decrease the need for a high level of special knowledge in the deployment personnel. Ideally, the process of creating or updating the database/application environment should not require the attention of any developer. Any person who is interested in getting his database box up to date or building it from scratch should be able to do it. No DBA knowledge should be required from that person, no T-SQL skills, no database structure knowledge, nothing. All that should be required is the name of the target SQL Server and a login with sufficient rights. The rest should be preconfigured.
The Database Environment: Component Parts
Each database environment comprises a combination of objects, which at a high level we can categorize as follows:
- Database-level vs. Server instance-level
The objects pertinent to particular database scope may be located not in the database itself but defined at the server-level. Examples of server-level objects include logins, or Service Broker End Points. - Environment-aware ones vs. Environment-agnostic
Some object definitions will not vary between environments but others will. For example, if the same database exists in several environments, it will have the same filegroups in each environment, but the number and characteristics of the files within each filegroup may vary. - Recreated vs. Altered at the deployment
Certain objects, for example routines such as stored procedures, we can recreate from scratch for each build. Other objects, such as tables, which persist data, we must preserve and progressively alter.
Figure 1 depicts the major object types in each these categories.
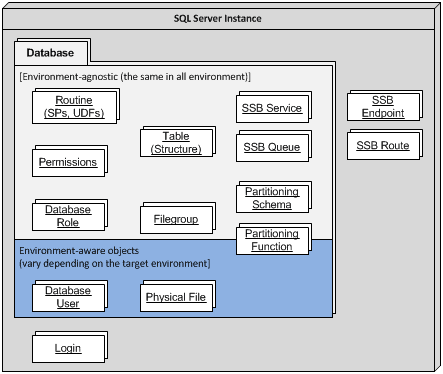
Figure 1: Components of a typical database environment
Each object type requires a different approach to its deployment and its scripting.
An Overview of the Incremental Database Deployment Framework
In our approach, every action is a “change” that we must script and track. We script each object type into a separate text file, stored in a version control system in order to track all changes to these files. We start with an empty database, and then iteratively upgrade it, adding new objects and amending existing ones until the database reaches the desired state, and we are ready to deploy.
Fowler and Sadalage on Evolutionary Database Design
You can find further details on the approach described in this article in Martin Fowler and Pramod Sadalage’s book on the evolutionary database design. It explains most of the reasons why database development and design must be incremental.
However, having all the change scripts is only half of the job in a deployment process. We must organize these scripts into some meaningful structure that allows simple, repeatable, reliable deployments, as described in our earlier goals. In this solution, we achieve this, essentially, by supplying the configuration files that describe how all of these scripts combine to create a new version of the database.
In addition, we have a deployment utility (in our example, written in Visual Basic Script), plus some associated utilities, which drives the database build, using the appropriate change scripts and configuration files.
Together, all of these files form the database build and upgrade package for a particular project. Figure 2 shows a typical database project organization, in the version control system.
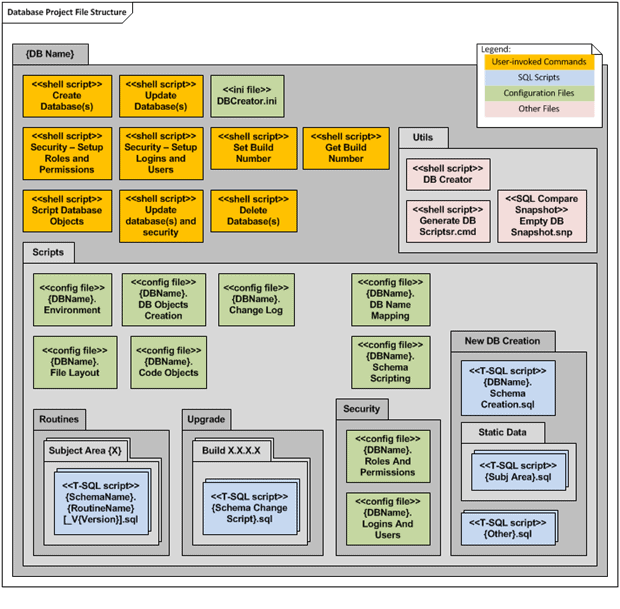
Figure 2: Typical Database Project File Structure
Note that it’s possible, in certain deployment scenarios, to have more than one database projects for the same database as well as other separate projects to define, for example, replication configuration, service broker objects, a project for data feeds/ETL processes for a given environment, and so on. For example, if we have an OLTP database and a replica of it, we might build and deploy the original database from one database project, its replica form a separate database projects, and then have a third ‘replication’ project, differently structured, which defines replication definition and maintenance in each environment. We’ll discuss this in more detail in a later article, but for now, we’ll consider only a single database project.
Each database project will contain all the change scripts, configuration files and utilities required to create and upgrade the database environment, on any SQL Server instance. This will of course include creating and upgrading the database (or set of databases) defined within that project, and their schema and code objects. However, it will also include database file structure, roles, permissions, users, database-level Service Broker objects, and static data.
At this stage, we won’t describe every aspect of our database project, but just enough so that, in the next article, we can walk through a simple, first example of creating, developing and deploying a new database, through the framework. Many intricacies we’ll leave to a later article, including:
- Database Mapping, which allows us to deploy a set of changes to a set of databases in a project and how to create/update database with a name different from the one used in the project
- Full details of how the role/permissions assignments works
- Various project parameters
For now, we’ll start with the Scripts folder, which occupies the bottom half of the figure. In here, there are some top-level configuration files and a separate sub-folder for security configuration, which we’ll get to shortly, and then three sub-folders containing database modification scripts.
Database Modification Scripts
Inside the Scripts folder of our database upgrade package, we have three sub-folders, Upgrade, Routines and New Database Creation, which contain the scripts that describe changes to our database code, objects and static/system data.
We describe the changes to the structure of our database code and objects using T-SQL scripts, but we’d also need to include any file (such as a batch file) that was necessary to support a of the incremental build process. For example, we may also have in the Scripts folder a batch (.cmd) file that executes an SSIS package to load or update some system data, or performs some other operation such as creating a WMI counter.
Figure 3 shows the creation of modification scripts for changes to a database routine, database structure or to an external operation.
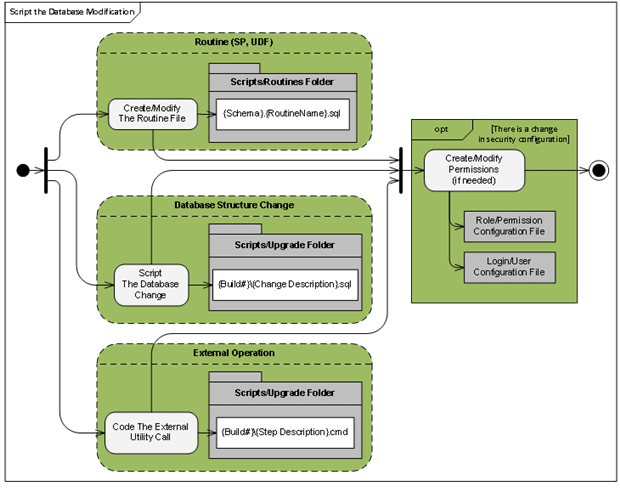
Figure 3: Steps of the Database Modification Scripting
Notice that every object script is associated with its own set of “security configuration” files. If the database change requires also modification of security, then we must also modify the appropriate permission files (discussed in more detail shortly).
Let’s briefly examine the contents of each of our three sub-folders for our database modification scripts, Upgrade, Routines and New Database Creation, in a little more detail.
Upgrade
This folder contains the T-SQL change scripts for all of the schema objects (tables, indexes, constraints and so on), for the current build. In other words, it contains the scripts to create any new scheme objects required for this build, or alter any existing objects that have changed since the previous build. For example, if in build 0.0.04 we add a new column to a table, then we’d create a folder called “…Upgrade\0.0.0.4” and within it store the script to alter the table.
Once created, we cannot simply drop and recreate a table for a subsequent build; we must persist the data. If we want a new table, index or constraint in the database, we script it as a T-SQL file and add it to the project as a database modification. The same is true for modifications of existing tables. In any case the developer must consider the volume and nature of the data already in the target object, existing and newly introduced constraints, whether or not such modification can (or will) be done on a live database and so on.
Routines
These T-SQL scripts describe our database routines, such as stored procedures, UDFs, triggers and so on. We do not have to preserve these objects from one build to the next; we can simply recreate them each time. However, this does not necessarily mean that we drop and recreate these objects each time. A better approach, for reasons we’ll discuss in the next article, is to create the object, if it does not exist, and alter the object to its final form, if it does.
New Database Creation (full build)
This folder contains a T-SQL script (DatabaseName.SchemaCreation.sql) that will set any required database settings, and then create all required schema objects for the latest full build.
At the end of a development cycle, we can roll up all schema object changes in order to build and deploy a database from scratch in one operation. In other words, instead of applying a series of incremental upgrades to a schema object, we simply create the object in its final state.
For example, let’s say that during a development cycle, we’ve produced four database builds (0.0.0.1 – 0.0.0.4), which we’ve been deploying to our test server. Now, at build 0.0.0.5 we’re ready to deploy to a new environment (e.g. Staging).
One way would be to deploy 0.0.0.1 to Staging and then incrementally upgrade it to 0.0.0.4. Another approach, and one we use, is to use a schema comparison tool (in our case, Red Gate SQL Compare) to compare the schemas for 0.0.0.1 (an empty database) with that for 0.0.0.5 and produce the required schema changes in a single script (we deal with code objects separately).
Also in this folder is the T-SQL script to reflect any necessary static data, which we must deploy with the database.
Configuration Files
At the top level of the Scripts folder, we have a set of configuration files including the Change Log and two some security configuration files (the latter stored in a separate sub-folder in our solution). Figure 4 shows the configuration files and their dependencies.
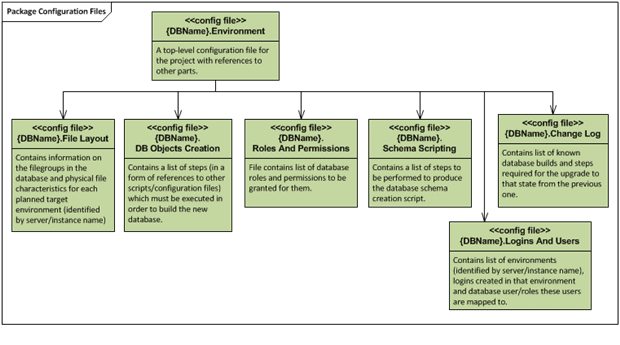
Figure 4: Package Configuration Files
The chosen configuration file format allows us to have a tree-like structure, where any configuration file can point to a file (a SQL script file or a .cmd file), or another configuration file. The exact file structure is flexible. We can use SQL Server Management studio to modify these files. They all are just XML documents so SSMS helps reveal any non-closed elements, missing quote marks, and so on. Alternatively, we can use a simple text-editing tool. These configuration files are vital to the operation of the framework and should be stored the source control along with the scripts.
Environment Configuration file
At the top of the tree, we have the Environment Configuration file. Our deployment utility simply references this file, DBName.Environment, to drive the whole deployment process. In this file is stored the current configuration build number, and the location and names of all other required configuration files, including the change log. All other files contain information that is specific to their associated operation, the latter executed by the deployment utility.
The configuration build number is updated only when we perform a full build (see the previous section, New Database Creation (Full Build)) and until we perform this full build the number stored here will reflect the very first build (0.0.0.1, say) rather than the current environment build number, stored in a database extended property.
Security Configuration
You may be tempted to script object (e.g. stored procedure) permissions in the same file as the object. However, a problem arises when someone needs to check on all the permissions in the system. The best approach is to provide the security settings separately, as a set of configuration files, which are then applied appropriately by the deployment utility.
For reasons that we’ll discuss in more detail in a later article, we chose a security configuration consisting of two parts: (1) database role and permission configuration and (2) server login and database user configuration. Hence, we have two Security configuration files, one for roles/permissions and one for logins/users.
The Change Log
We use the Change log used to track all the changes made to the database structure (schema and code objects) and static data. Here is an example of the Change Log file structure:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
<Builds> <Build Number="0.0.0.0" /> <Build Number="0.0.0.1" /> ... <Build Number="0.1.0.3"> <Step Number="1" id="dbo.UserActivity" table added to TrackingDB" Type="sql" DBName="TrackingDB" FileName="\0.1.0.3\dbo.UserActivity table added.sql" /> ... <Step Number="10" id="dbo.Events" table indexes added" Type="sql" DBName=" TrackingDB" FileName="\0.1.0.3\dbo.Events table indexes added.sql" /> ... </Build> <Build Number="0.1.4.0" /> </Builds> |
It is the responsibility of the developers or the build master to keep the change log updated.
In our current implementation, all the references to the files are relative to the configuration file location. In the Change Log example, database change scripts are stored in subfolders of the folder housing the Change Log. As discussed previously, each build script lives in a subfolder, named after the build number, of the Upgrade folder. However, thanks to the flexibility of the configuration files, you can modify the exact structure to accommodate the project needs.
Other Configuration Files
In our implementation, we have several configuration files relating to new database creation. In File Layout, we define the file and filegroup properties for each SQL Server instance, on each server. InDB Object Creation, we simply locate the require scripts and files to build all required database objects, and insert any static data. For example, it will reference the T-SQL script to build the required schema objects, and another for any static data. It also refers to another configuration file (Code Objects.config, not shown here) which defines all the stored procedures and other code objects.
The Schema Scripting configuration file contains the instructions for generation of the full build script for the schema objects. In our implementation, this file points to one of our utilities (#make db script.cmd, described later), supplying server and database details, so that we can execute a schema comparison tool (SQL Compare 10) to generate the change script.
Shell Scripts and Utilities
In the top half of our database project, in Figure 2, we have:
- Nine user-executed shell scripts (
.cmdfiles) to perform particular operations on the database: such as create a new database, update its structure, and so on. They can be treated as a replacement for a GUI, or as shortcuts for command-line instructions. - A DBCreator.ini file – this file simply supplies parameters that point the deployment utility to the relevant server and instance, and identify the correct
DBName.Environmentconfiguration file. - A set of deployment utilities (Utils) including:
- Most notably, the deployment utility (
DBCreator.vbs) - A shell script to create a SQL Compare snapshot of the empty database
- A
.cmdfile, make db script.cmd, to create a full build script for the database – we use SQL Compare to generate the change script by comparing the current build to the empty database snapshot. This script contains core schema objects only; we exclude code objects such as stored procedures, functions and triggers, as well as those related to security, and handle them separately.
- Most notably, the deployment utility (
For now, we’ll focus on the deployment utility, and the associated command files that call its defined operations. Eight shell scripts (.cmd files) correspond to distinct operations in the deployment utility (DBCreator.vbs). There is also a ninth shell script that is simply a wrapper script to update database and security together.
In each case, after dealing with any necessary parameter parsing and mapping, each shell script calls DBCreator.vbs, passing in a parameter to define the requested operation, along with parameters identifying the server and instance names and the appropriate Environment configuration file, DBName.Environment.
Let’s briefly review each the shell scripts (.cmd files), and their corresponding actions.
Create Database(s)
The Create Database(s) cmd file calls the DBCreator.vbs script with the “create” option, and the parameters required for that operation. This runs various routines in the DBCreator.vbs script, the next effect of which is to create and configure databases, schema and code objects, roles, permission, logins and users or that server environment, as defined by the Environment configuration file. It also sets the build number, as defined in this file.
Don’t forget that this environment configuration file simply points to all other required configuration files for the database. For example, it points to FileLayout configuration file for the details of the name, size and location of the various database files and filegroups. The DBCreator.vbs script simply follows those links to extract appropriate parameters and to identify the scripts it has to execute.
Update Database(s)
This cmd file calls DBCreator.vbs with the “updateStructure” option. This tells the DBCreator.vbs script to read from the change log a list of scripts needed to bring the environment to the latest build. It deploys the changes and then sets the build number for all databases in the environment (i.e. updates the value store in the database extended propert) from the latest build specified in the change log.
The result is that we upgrade any existing databases from any intermediate build to the latest and greatest, using the change log. Mind that the security settings and permissions were not affected (unless they were implicitly dropped by commands in the applied scripts).
Delete Database(s)
The Delete Database(s) cmd file calls DBCreator.vbs with the “delete” option. It forces the VBS script to delete the database environment and all databases included in the project. Be careful running this one!
Security Setup
Here we have two separate .cmd files with corresponding operations in the deployment utility:
Security - setup roles and permissions– creates database-level roles and grant these roles permissions on the database objects in server whose instance name we supply for database(s) listed in the environment configuration fileSecurity - setup logins and db users– create logins and map them to database users on the server whose instance name we supply, for database(s) listed in the environment configuration file. The VBS and configuration file support both Windows and SQL logins. Windows logins can specify the domain. If not, the machine name will be used as the domain. The operation checks the existence of all logins listed in the environment configuration file and creates them if needed. It revokes access for any logins to the databases in the target environment that are not listed in the configuration file. It then maps each login to a database user in each database for which the login is specified.
This separation of the roles and permissions from logins and users allows having a common set of database roles which are not environment-specific. Logins are environment-specific and their configuration is not burdened with individual object permissions.
Getting and Setting the Environment Build Number
As discussed earlier, there must exist in the database some attribute that can show us, quickly and unambiguously, the database state. Such an attribute, a version or build number, must be easy to retrieve and easy to understand, by any person in the team.
The basic premise is that if two database copies have the same build number, then they are identical in terms of table structure, routines, and system data, and even to the point that they have identical filegroup set (the filegroup set is environment-independent: the same set of filegroups is in all database copies.
However, two database copies with the same version number can still have characteristics specific to the target deployment environment (for example, the files within the filegroups are environment-specific). There could, in other words, be differences in the static data, in the security configuration (logins/users) or the physical file characteristics (file names, growth rate, and so on), but none of these are considered to be part of the database state (version).
We chose to store this state identification attribute in a database extended property. In fact it could be a table storing the history of changes, but we sacrificed that handy feature to be able to see and modify the value through the database properties in Management Studio. We have two .cmd files, one to get and one to set this value, and their corresponding operations in DBCreator.vbs, are reasonably straightforward.
- Get build number – gets the current build number from the environment. It is supposed to be used by DBA and developers, or whoever needs to detect the current database version
- Set build number – marks database environment with appropriate version (build) number. Checks script input parameters for the new Environment build number, either passed to the script or given by the user, and then forcefully sets build number for all databases in the environment. The developer or DBA setting the build number must ensure that the version number is correct
Script Database Objects
During incremental development of a database, we alter the various scripts and configuration files as appropriate, and then execute the Update Databases and Security cmd file to apply the changes to our database(s).
At some stage, for example at the end of a development cycle, we may wish to “wrap” into a single script all the schema changes required to advance the database(s) from the first to the final build in the cycle. We refer to this as a full build (or build from scratch) script. To generate this script we execute the Script Database Objects cmd file. It follows the FullBuildObjectCreation parameter in the Environment configuration file to identify a set of scripts that must be executed in order to a create a T-SQL file with all the database objects scripted at their current state.
In code example provided with this article, the FullBuildObjectCreation parameter simply points to the Schema Scripting configuration file (described earlier in the section Other Configuration Files), which is turn points to ourmake db script.cmd utility. This is simply a call to the command-line version of our schema comparison utility, SQL Compare. The resulting script (DatabaseName.SchemaCreation.sql) is used when we execute the Create Database(s) operation, described previously.
Summary
That completes our tour of the goals of the incremental database development and deployment framework, its component parts, and of how these parts fit together, to provide an automated way to build and deploy databases. In the next article, it’s time to put it into action!
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments