

Newly added in SQL Server 2025 is the answer to years of feature requests: Native Regex support. New functions have been added that provide ways to address common string-searching requests that are faster, easier, and more performant than previously-used methods.
This article dives into all of the new functionality with examples, details, and everything needed to make use of this new feature.
All demos and details have been constructed using SQL Server 2025 Community Technology Preview 1.4 and may change slightly between now and when its first RTM release occurs. If any of this content changes, it will be updated to be as accurate as possible after SQL Server 2025 becomes widely available for general usage.
Note that this functionality was also added to Azure SQL Database as a private preview in May, 2024, so its addition to SQL Server proper does not come as a huge surprise.
Background
String-searching in SQL Server has always been a mighty hassle. Balancing performance and horribly-complex queries is a compromise that no one enjoys.
Generally speaking, a relational database is not an ideal place to search large amounts of text. Even when leveraging features such as Full-Text Indexing, the ability for an application to leverage speedy text-searching decreases as data becomes larger. If a service optimized for text-search can be used, such as Elasticsearch or Azure AI Search, then it will be far easier to deliver accurate results quickly.
Despite that guidance, there are many reasons to search within text in SQL Server. Sometimes data is small and crunching a block of text can be done very quickly and at-scale without any latency. Other times, there is an immediate need to reduce the amount of data being returned to an application, and string-searching in the database will ultimately save time and resources. Alternatively, some analytic data systems can pre-crunch text data during data load processes, allowing the expensive text-search processes to have their results available to users when needed, without any waiting.
What Are Regular Expressions in SQL Server?
Regex (aka: regular expressions) provides a common syntax for search expressions that can be used when searching text. This may include words, letter sequences, patterns, or other combinations of text occurrences. For example, if I wanted to search this article for all places where the word “native” occurs as part of another word, then a Regex pattern similar to this would be used:
“native[a-zA-Z]” or “[a-zA-Z]native”
The first expression looks for the word “native” where it is immediately followed by another letter. The second expression checks for any letter first, followed by the word “native”. Regex has an extensive selection of metacharacters and patterns that can be used to describe text patterns, from simple and straightforward to those that get quite complex.
SQL Server has had limited support for Regex within LIKE operators for Perl Compatible Regular Expressions (PCRE) and .NET variants for quite a while, but this did not provide full support for the IEEE POSIX standard and functions that can make more efficient use of it.
In April, 2024, Microsoft added full Regex support to Azure SQL Database, which provided a sneak-peek at future functionality that would be available in a future full SQL Server version. SQL Server 2025 is the recipient of these features, which will now be described in detail.
Regex in SQL Server 2025
Without any further adieu, here is a comprehensive list of new Regex functions in SQL Server, along with their most common use-cases and examples of their usage. Note that some of these functions require compatibility level 170 (SQL Server 2025) to be enabled to use them. Therefore, that change will be made here immediately, before proceeding:
|
1 |
ALTER DATABASE WideWorldImportersDW SET COMPATIBILITY_LEVEL = 170; |
REGEXP_LIKE()
This function returns a 1 or 0 boolean value if a regex pattern is found within a string. A simple example would be one that checks if a string contains a specific word:
|
1 2 3 4 5 6 7 |
USE WideWorldImportersDW; SELECT FROM Dimension.Customer WHERE REGEXP_LIKE(Customer.Customer, ' NY[)]'); |
This example returns all rows from the Customer table where the Customer name includes the text “NY)”. The square brackets ensure that the parenthesis is read as a character literal and not as a regex modifier.
This next example is a bit more outlandish, but returns all rows where the Primary Contact starts with a capital A and ends in a lowercase a:
|
1 2 3 4 5 6 |
SELECT FROM Dimension.Customer WHERE REGEXP_LIKE(Customer.[Primary Contact], '^A.*a$'); |
The results include 17 customers with a primary contact starting with A and ending with a:

Note that Regex is case-sensitive, regardless of the database collation used. If a database has a collation that is case-insensitive, that will not affect the contents of regex expressions when they are used. Consider this slight adjustment to the above example:
|
1 2 3 4 5 6 |
SELECT FROM Dimension.Customer WHERE REGEXP_LIKE(Customer.[Primary Contact], '^A.*A$'); |
After that change is made to the query, the result set is now empty:

Because of this detail, it is important to ensure that any regex expressions have the correct case for any letters used.
One final example of this function returns any rows that have at least two consecutive letter “s” in a row:
|
1 2 3 4 5 6 |
SELECT FROM Dimension.Customer WHERE REGEXP_LIKE(Customer.Customer, '[sS]{2,}'); |
The results include nine rows where the customer name contains at least one sequence of multiple letter “s” in a row:

REGEXP_COUNT()
This function goes a step further and returns the number of times a regex expression appears in a string. For longer strings (or interesting questions), this allows a count to be calculated without the need for iteration, complex string manipulation, recursion, or some other messy method.
Consider the following query:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT [City Key], City, [State Province], REGEXP_COUNT(City.City, '[sS]{2,}') AS SequenceCount FROM Dimension.City WHERE REGEXP_COUNT(City.City, '[sS]{2,}') > 0 ORDER BY REGEXP_COUNT(City.City, '[sS]{2,}') DESC; |
This returns the number of times in a string that a sequence of at least two letter “s” appears in the city name. The query also filters out any rows where the count is zero and then orders by that count. The results are as follows:

Mississippi is high on the list of interesting city/state names (no surprise there!)
An additional parameter may be provided that gives the search a starting character, if there is a need to skip some of the string before beginning to count. For example, if there was a need to skip the first five characters of the city name, then the previous query could be modified like this:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT [City Key], City, [State Province], REGEXP_COUNT(City.City, '[sS]{2,}', 6) AS SequenceCount FROM Dimension.City WHERE REGEXP_COUNT(City.City, '[sS]{2,}', 6) > 0 ORDER BY REGEXP_COUNT(City.City, '[sS]{2,}', 6) DESC; |
The 3rd parameter is optional and tells the function to begin searching the string at the character position provided. In this example, the regex expression is searched for starting at character 6, which reduces the matches in the overall result set:

The rows returned are reduced from 1,752 to 590.
Another example shows how a list of cities can be retrieved that begin with the word “New” and include a space after that word:
|
1 2 3 4 5 |
SELECT FROM Dimension.City WHERE REGEXP_COUNT(City.City, '^New\s') > 0; |
The results show 1,002 cities that begin with the word “New”:

REGEXP_INSTR()
This function can return either the start or end position of a matched regular expression. This provides superior functionality to commonly used string-searching functions, such as PATINDEX or CHARINDEX, which only return the starting position for a given string pattern.
A simple example shows how the position of the word “New” can be found within a string:
|
1 2 3 4 5 6 7 8 |
SELECT City.City, City.[State Province], REGEXP_INSTR(City.City, 'New') AS StringLocation FROM Dimension.City WHERE REGEXP_INSTR(City.City, 'New') > 0 |
The results provide the starting location in the string, but only in strings where it is found:

The first optional parameter allows the starting position to search to be provided. This adjusted query also searches for the string “New”, but begins at character 2:
|
1 2 3 4 5 6 7 8 |
SELECT City.City, City.[State Province], REGEXP_INSTR(City.City, 'New', 2) AS StringLocation FROM Dimension.City WHERE REGEXP_INSTR(City.City, 'New', 2) > 0 |
The results show all cases where the word “New” is in the string, but not at the start:

The second optional parameter specifies which occurrence of the string pattern should be located. This updated example will return the position of the second occurrence of the word “New” within a city name:
|
1 2 3 4 5 6 7 8 |
SELECT City.City, City.[State Province], REGEXP_INSTR(City.City, 'New', 1, 2) AS StringLocation FROM Dimension.City WHERE REGEXP_INSTR(City.City, 'New', 1, 2) > 0 |
The results are a very short list of cities that happen to have the word “New” appear in them multiple times:

The third parameter specifies whether the function should return the starting position for the regex pattern (0) or the ending position (1). The previous query can be adjusted to return the end position of the second occurrence of the word “New” like this:
|
1 2 3 4 5 6 7 8 |
SELECT City.City, City.[State Province], REGEXP_INSTR(City.City, 'New', 1, 2, 1) AS StringLocation FROM Dimension.City WHERE REGEXP_INSTR(City.City, 'New', 1, 2, 1) > 0 |
The rows returned are the same, but the string location identified has shifted to the end:

More outlandish regular expressions can be applied, showing the flexibility available in these new functions:
|
1 2 3 4 5 6 7 8 |
SELECT City.City, City.[State Province], REGEXP_INSTR(City.City, ' N.*?w', 1, 1, 0, 'i') AS StringLocation FROM Dimension.City WHERE REGEXP_INSTR(City.City, ' N.*?w', 1, 1, 0, 'i') > 0 |
That work of art will return the start position in any city where the second (or later) word starts with “N” and is followed by a “W” later in the string. The “i” flag at the end makes the regular expression case-insensitive, which can be a handy flag for databases that use case-insensitive collations.
REGEXP_REPLACE()
This function takes the search capabilities introduced thus far and extends them to allow a matched string segment to be replaced by a new string. This mirrors how the classic REPLACE() function works, but using regex instead.
The simplest possible example will replace the string “New” with “Old”, whenever the search string is found:
|
1 2 3 4 5 6 7 8 |
SELECT City.City, City.[State Province], REGEXP_REPLACE(City.City, 'New', 'Old') AS OldCityName FROM Dimension.City WHERE REGEXP_COUNT(City.City, 'New') > 0; |
The slightly comical results are as follows:

The remaining parameters for this function are similar to REGEXP_INSTR(). The first provides a starting position from where to search. Consider the following example:
|
1 2 3 4 5 6 7 8 |
SELECT City.City, City.[State Province], REGEXP_REPLACE(City.City, 'New|Old', 'Mid', 5) AS MidCityName FROM Dimension.City WHERE REGEXP_COUNT(City.City, 'New|Old', 5) > 0; |
Starting at character 5, any occurrences of “New” or “Old are replaced with “Mid”. Note that this is case sensitive and lowercase versions of these words will not be replaced. Here is a sample of the results:

Similar to REGEXP_INSTR, the occurrence can be specified so that text is only replaced for the Nth occurrence of the regular expression. The following T-SQL replaces “New” or “Old” with “Mid”, but only for the second occurrence:
|
1 2 3 4 5 6 7 8 |
SELECT City.City, City.[State Province], REGEXP_REPLACE(City.City, 'New|Old', 'Mid', 1, 2, 'i') AS MidCityName FROM Dimension.City WHERE REGEXP_REPLACE(City.City, 'New|Old', 'Mid', 1, 2, 'i') <> City.City; |
The result set is small, but illustrates the effect of the script effectively:

In each case, the first occurrence of New/Old was left alone, and the second occurrence was modified.
REGEXP_SUBSTR()
The next regex function added to SQL Server, REGEXP_SUBSTR, finds a string pattern and returns the substring that matches it. This can be particularly useful for extracting portions of money, phone numbers, email addresses, websites, and other text that has consistent or important delimiters.
This example takes a customer name and extracts the contents of the parenthesis within that name:
|
1 2 3 4 5 6 |
SELECT Customer.[Customer Key], Customer.Customer, REGEXP_SUBSTR(Customer.Customer, '\ (([^)]+)\)') AS OfficeLocation FROM Dimension.Customer; |
The results include only the text between the parenthesis, excluding extra parentheses (if any were to exist):

If the substring is not found, then NULL is returned, as can be observed in the first row of the result set. In this next example, the letter code that prefixes some supplier codes is returned:
|
1 2 3 4 5 6 |
SELECT Supplier.[Supplier Key], Supplier.[Supplier Reference], REGEXP_SUBSTR(Supplier.[Supplier Reference], '[a-zA-Z]+') AS LetterCode FROM Dimension.Supplier; |
The results are either the letter code or an empty string, depending on whether a letter prefix exists:

The results show that any value with any number of letters as a prefix will return just that prefix. The plus sign instructs the regex to return one or more matching characters. If the string is not found, then NULL is returned. Note the slight difference in this query variant:
|
1 2 3 4 5 6 |
SELECT Supplier.[Supplier Key], Supplier.[Supplier Reference], REGEXP_SUBSTR(Supplier.[Supplier Reference], '[a-zA-Z]*') AS LetterCode FROM Dimension.Supplier; |
In this version, the plus is replaced with an asterisk, which indicates that the regex return zero or more matching characters. This results in an empty string being returned instead of NULL, which may be desirable for some applications.
REGEXP_MATCHES()
This function is ideal when detailed information is needing about regex string patterns and matching. The required parameters are a string expression and a regex pattern to match. The result set includes details about each match, its location, and which substrings were matched to the pattern.
This amount of information will sometimes be overkill, but will be especially helpful in scenarios such as these:
- Research/development using regular expressions
- Code that requires multiple detailed attributes of regex results
- Debugging regex code
- Visualizing results to better understand data or metadata
Consider the queries earlier that were searching for patterns within city names, and the following query that uses REGEXP_MATCHES() to search for the same expression:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT [City Key], City, [State Province], RegexMatchData.* FROM Dimension.City CROSS APPLY REGEXP_MATCHES(City.City, '[sS]{2,}') AS RegexMatchData WHERE REGEXP_COUNT(City.City, '[sS]{2,}') > 1 ORDER BY City.City ASC; |
The results provide a row per result found per city:

The results are a table that provides location information on the substring that matches the regular expression. This can be used to report on matches, make decisions about whether the results are valid or not, or assist with research. The match_id is an automatically generated integer identity that can be used to uniquely identify results within each string expression or set of expressions.
The final column, substring_matches, provides a JSON document for the details provided previously. This is convenient if there is a need to retrieve all of this information quickly, either for posterity or for analysis at a later time. For matching string expressions, this is the most comprehensive solution and allows a single query to return a wealth of information!
REGEXP_SPLIT_TO_TABLE()
The final new regex function available in SQL Server 2025 provides functionality that mimics STRING_SPLIT, but can split on a regex pattern. This can be very useful when text needs to be parsed or split, but the split expression is complex in nature.
Consider the example from earlier where any occurrence of two letter S in a row would be recognized as a regex expression. If this new function were used instead, then the resulting script would look like this:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT [City Key], City, [State Province], RegexMatchData.* FROM Dimension.City CROSS APPLY REGEXP_SPLIT_TO_TABLE(City.City, '[sS]{2,}') AS RegexSplitData WHERE REGEXP_COUNT(City.City, '[sS]{2,}') > 1 ORDER BY City.City ASC; |
The results are:

The results show that the REGEXP_SPLIT_TO_TABLE function will split a string based on whatever the regex expression is, thereby removing the match pattern from the result. Based on that, the word “Possession”, when split for [sS](2,}, returns three results: “Po”, “e”, and “ion”. The ordinal number provided is a integer key provided for each string that is split, allowing the results to be sorted or filtered based on the order of the results.
While quite useful, STRING_SPLIT only operates using a single static character separator, so there is no way to replicate the functionality of REGEXP_SPLIT_TO_TABLE using STRING_SPLIT.
Consider a string that needs to be split on more than one character, or a pattern of characters:
|
1 2 3 |
SELECT FROM STRING_SPLIT('"Taco", "Pizza", "Cheeseburger", "Salad", "Apple", "Carrot"', '", "'); |
This T-SQL is not valid and will result in an error:

Using the function REGEX_SPLIT_TO_TABLE(), this can be (almost) accomplished as follows:
|
1 2 3 |
SELECT FROM REGEXP_SPLIT_TO_TABLE('"Taco", "Pizza", "Cheeseburger", "Salad", "Apple", "Carrot"', '", "'); |
The results are ALMOST there:
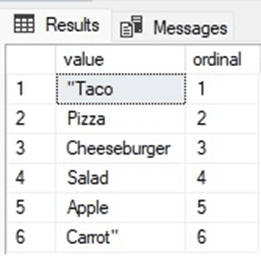
The split works as expected, but the leading and trailing quotes remain as they do not match the exact pattern provided. There are a variety of ways to solve this problem, including this code:
|
1 2 3 4 5 |
SELECT FROM REGEXP_SPLIT_TO_TABLE('"Taco", "Pizza", "Cheeseburger", "Salad", "Apple", "Carrot"', '", "|^"|"$') WHERE [value] <> ''; |
The results are what was intended at the start of this example:
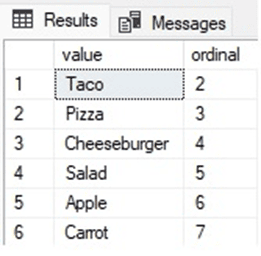
The ordinal is slightly off, and if that is an issue for the code that consumes this result set, then further adjustments can be made, such as simply trimming off the leading/trailing quotation marks in the result set, instead of opting for a more complex regex expression.
Flags
There are additional options available to these regex functions that adjusts their functionality in useful ways:
i: Case Insensitive
When the “i” flag is used, all string characters in the regular expression will be treated as case insensitive, allowing capital and lowercase letters to match patterns for each other. This is not a default setting.
c: Case Sensitive
This forces regex pattern matching to be case sensitive. This is the default setting and does not need to be explicitly used to ensure case sensitive regular expression matching.
m: Multi-Line Mode
When this flag is used, the carat (^) and dollar sign ($) will match the begin/end line characters in addition to begin/end text. This is not a default setting.
The following query will count the total number of begin/end lines in a text string:
|
1 2 3 4 |
SELECT REGEXP_COUNT('This is an example. Multiple lines are provided. Four in total ', '$', 1, 'm') AS NewLineCount; |
The results look like this:

Note that the last line counts in the total, even though there is no additional text on it. There is a total of 4 begin-line characters and 3 end-line characters, for a total of 7.
s: New Line Character Matching
This flag allows a period (.) to match a new line character (\n). This is not a default setting. Normally a period will match most characters, but not a new line. This example shows a before & after query using this flag:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT REGEXP_COUNT('This is an example. Multiple lines are provided. Four in total ', '.', 1) AS CharacterCount; SELECT REGEXP_COUNT('This is an example. Multiple lines are provided. Four in total ', '.', 1, 's') AS CharacterCount; |
The results of both queries is as follows:

The second version shows that there are 3 additional characters recognized in the string, which are accounted for by the three end-of-line characters.
Conclusion
Full Regex support in SQL Server will provide a huge boost to anyone writing or maintaining code that performs string-searching. Many of the old ways of parsing strings and searching for string patterns involved complex or ambiguous code that tended to be hard to read and maintain. In addition, unexpected inputs, such as NULL or empty string, were left to the developer to sort out on their own, for better or worse.
The new functions provide a great deal of utility while removing any ambiguity as to how they work. It is always exciting when new functions are added to SQL Server – and doubly so when they handle tasks that are so extraordinarily common! Let me know what your experiences are and what your thoughts are on these new tools.





Load comments