



One of the most hassle-prone changes that can be made in a SQL Server database is to widen an existing column. Depending on the column’s use and data type, this process may involve hundreds of schema changes, app downtime, and a mountain of risk-prone code to review and deploy.
This article dives into a fun (and interesting!) strategy for widening fixed-width columns in SQL Server, to reduce downtime, risk, and runtime at the time when a column’s data type needs to be changed.
If you have ever suffered through a lengthy INT to BIGINT release, then this guide is for you!
The Challenge of Altering Fixed-Width Columns
Changing the size of a column will always require a DDL change to the column’s definition, adjusting it from the old type/definition to the new one. If the column happens to be fixed-width, such as INT, DATETIME2, DECIMAL, or TIME, then the space for each value is allocated up-front for its storage.
Consider the four integer data types available in SQL Server:

In an uncompressed table, the maximum space needed for each value will be allocated when a new value is written. An INT will always write 4 bytes of data, even if the value is a small number that does not require 32 bits to represent it. This is completely intentional.
Data in SQL Server is stored on 8 kilobyte pages and rows are inserted into available space at runtime, before new pages are allocated to a given object. Imagine if every time a column value was updated from 8 to 8,000,000, SQL Server needed to move the row and/or allocate new space and move the row onto a new page? If this had to be executed for many rows at once, then UPDATE queries could become quite painful.
The remaining challenge comes when there is a need to adjust from a smaller range to a larger range. Altering a fixed-width column to a wider data type requires rewriting rows such that each newly written row has more space to store the values. For a large table, this can be a time-consuming, IO-intensive operation that creates extensive log-growth and blocks application users from accessing that table.
Note that this ONLY applies to fixed-width data types. VARCHAR, NVARCHAR, VARBINARY, and other variable-length columns allocate space as-needed at runtime and are ideal for strings where their length can vary greatly over time. Allocating 8000 bytes up-front for a description column that may contain 0, 5, 500, or 5,000 characters would be quite wasteful.
Consider the WideWorldImporters table Sales.OrderLines. Within this table is an integer column called PickedQuantity:
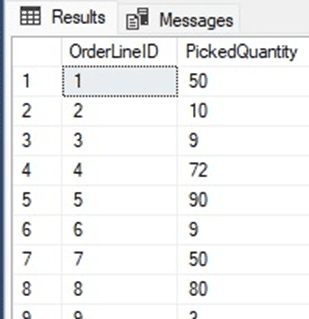
Nothing fancy here: It is a NOT NULL column containing an integer value representing quantities from an orders table.
Imagine that new products were being added and there was a need to represent quantities in larger values than an integer can hold. When the application developers implement the change, part of the work will be to alter the column from INT to BIGINT.
The script to make the change is simple enough:
|
1 |
ALTER TABLE Sales.OrderLines ALTER COLUMN PickedQuantity BIGINT NOT NULL; |
Before executing, IO statistics will be turned on so that the storage impact can be measured:
|
1 |
SET STATISTICS IO ON; |
Of course, when executed, the ALTER TABLE statement fails with a variety of errors, as reality reminds us that a change like this is never-so-simple:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Msg 5074, Level 16, State 1, Line 20 The index 'IX_Sales_OrderLines_AllocatedStockItems' is dependent on column 'PickedQuantity'. Msg 5074, Level 16, State 1, Line 20 The index 'IX_Sales_OrderLines_Perf_20160301_02' is dependent on column 'PickedQuantity'. Msg 5074, Level 16, State 1, Line 20 The index 'NCCX_Sales_OrderLines' is dependent on column 'PickedQuantity'. Msg 4922, Level 16, State 9, Line 20 ALTER TABLE ALTER COLUMN PickedQuantity failed because one or more objects access this column. |
To resolve this, any indexes or constraints that reference the column will be dropped prior to the change, and then re-added afterwards. This is a standard part of the task and a development team should validate for dependencies prior to committing code like this.
|
1 2 3 4 |
DROP INDEX IX_Sales_OrderLines_AllocatedStockItems ON Sales.OrderLines; DROP INDEX IX_Sales_OrderLines_Perf_20160301_02 ON Sales.OrderLines; DROP INDEX NCCX_Sales_OrderLines ON Sales.OrderLines; |
With those three indexes temporarily dropped, the ALTER TABLE statement from above succeeds, as we wanted it to. Here is the output from STATISTICS IO:
Table ‘OrderLines’. Scan count 1, logical reads 50687, physical reads 3, page server reads 0, read-ahead reads 4606, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Note that altering the column from INT to BIGINT required a total of 50,687 pages of reads, or about 396 megabytes in total of read activity. The query took about 5 seconds to complete. In addition, the impact on write activity to the transaction log can be validated with this query:
|
1 2 3 4 5 6 7 |
SELECT fn_dblog.allocunitname, SUM(fn_dblog.[log record length]) AS log_size_bytes FROM sys.fn_dblog (NULL, NULL) WHERE fn_dblog.allocunitname LIKE ('%Sales.OrderLines%') GROUP BY fn_dblog.allocunitname; |
The results are as follows:

The amount of log growth resulting from the column data type change was about 55 megabytes. Given that this table contains 231,412 rows, that comes out to about 1.75 kilobytes of read activity and 249 bytes of write activity per row. These amounts are non-trivial and are a direct result of the need to read the entire table and rewrite it with the new fixed-width column lengthened from 4 bytes to 8 bytes. As the table becomes larger and larger, lengthening a fixed-width column becomes more time-consuming and impactful.
Note that any indexes or constraints that are dropped prior to altering a column should be put back into place at a later time, when convenient, so the applications that rely on them can still do so. For this article, I chose to do so after the above demonstrations to avoid polluting any of the IO metrics.
The Real Problem: Application Uptime
Thus far, nothing discussed here is truly a problem. Users do not particularly care about the servers or databases that host the apps they use. As long as performance, security, and uptime are maintained, most users will happily go about their day without a second thought to any of these details.
Unfortunately, during the time when a column is being altered, any indexes impacted will become unavailable as changes are made. In other words, altering the size of a fixed-width column is a blocking change and will result in the table becoming unavailable. If the table is critical to an application’s function, then the true result is the dreaded D word: “Downtime”.
While some applications can tolerate downtime during maintenance periods, many cannot. Or if those apps do allow for maintenance windows, there is often a desire to minimize their length to reduce the impact of that disruption.
The challenge to tackle in this article therefore becomes: Adjust column length while minimizing downtime during a deployment.
Altering a column’s length as part of a software release against a table with millions or billions of rows could incur hours of downtime to complete if no optimizations or careful scripting considerations were made.
It is important to call-out that altering a column’s definition can still be quite complex in nature. This is especially true if the column is referenced by indexes, constraints, or code. Reducing downtime is the primary goal of this article, but doing so will not cause database complexity to go away.
Using Compression to Minimize IO
SQL Server includes a feature that can inadvertently help in reducing downtime, and it is data compression. Both ROW and PAGE compression include a single encoding algorithm that is quite impactful towards write operations: Bit packing. This algorithm stores fixed-width data types using only the space needed for each value. Therefore, if the value 5 were stored in an INT column, it would only consume the bits necessary to represent that number. The value 5,000 would require more space to store, but still far less than the 32 bits required to store a fixed-width integer value.
Essentially, the excess leading zeroes on smaller values are removed. The following chart shows an example of how different integer values would be stored when bit-packing is applied:
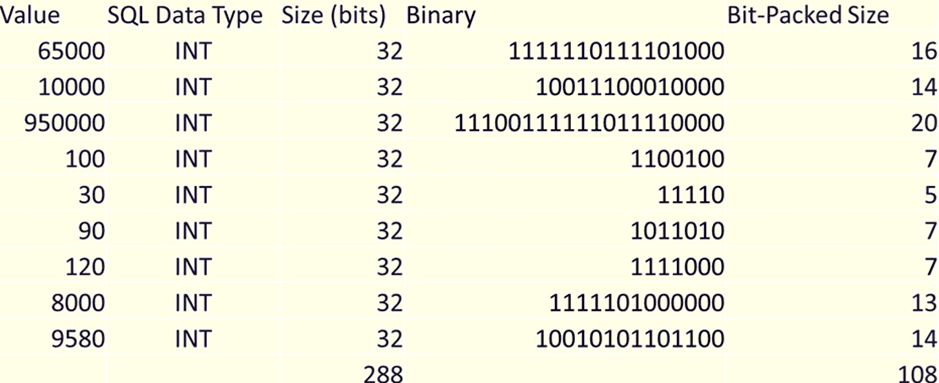
This convention is especially beneficial when the values in a column are far smaller than its data type’s maximum range. A key component of this feature is that fixed-width columns are no longer stored using the size of their maximum range.
This means that if a ROW or PAGE compressed fixed-width column were altered to a larger range, no additional writes should be needed. This sounds amazing, but is worth testing to prove it out. First, the column will be put back into its original state by:
- Dropping indexes
- Altering the column from BIGINT to INT
- Re-adding indexes
The following T-SQL will accomplish this task:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
DROP INDEX IX_Sales_OrderLines_AllocatedStockItems ON Sales.OrderLines; DROP INDEX IX_Sales_OrderLines_Perf_20160301_02 ON Sales.OrderLines; DROP INDEX NCCX_Sales_OrderLines ON Sales.OrderLines; ALTER TABLE Sales.OrderLines ALTER COLUMN PickedQuantity INT NOT NULL; CREATE NONCLUSTERED INDEX IX_Sales_OrderLines_AllocatedStockItems ON Sales.OrderLines (StockItemID ASC) ON USERDATA; EXEC sys.sp_addextendedproperty @name=N'Description', @value=N'Allows quick summation of stock item quantites already allocated to uninvoiced orders' , @level0type=N'SCHEMA',@level0name=N'Sales', @level1type=N'TABLE',@level1name=N'OrderLines', @level2type=N'INDEX',@level2name=N'IX_Sales_OrderLines_AllocatedStockItems'; CREATE NONCLUSTERED INDEX IX_Sales_OrderLines_Perf_20160301_02 ON Sales.OrderLines (StockItemID ASC, PickingCompletedWhen ASC) INCLUDE(OrderID,PickedQuantity) ON USERDATA; EXEC sys.sp_addextendedproperty @name=N'Description', @value=N'Improves performance of order picking and invoicing' , @level0type=N'SCHEMA',@level0name=N'Sales', @level1type=N'TABLE',@level1name=N'OrderLines', @level2type=N'INDEX',@level2name=N'IX_Sales_OrderLines_Perf_20160301_02'; CREATE NONCLUSTERED COLUMNSTORE INDEX NCCX_Sales_OrderLines ON Sales.OrderLines (OrderID, StockItemID, [Description], Quantity, UnitPrice, PickedQuantity) ON USERDATA; |
The test from earlier will be reproduced identically, except that the table’s clustered index will be rebuilt with ROW compression prior to repeating the experiment:
|
1 2 3 |
ALTER TABLE Sales.OrderLines REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); |
If online rebuilds are an available option in your edition of SQL Server, then definitely use ONLINE=ON as part of the T-SQL. This will further reduce downtime for the application that relies on this table.
The next steps are the same as earlier:
- Drop referencing indexes
- Alter the column to BIGINT
- Add indexes back to the table
- Measure the log activity using sys.fn_dblog
When ready, step 2 proceeds like it did earlier:
|
1 |
ALTER TABLE Sales.OrderLines ALTER COLUMN PickedQuantity BIGINT NOT NULL; |
The operation completed immediately and the STATISTICS IO output is completely empty:
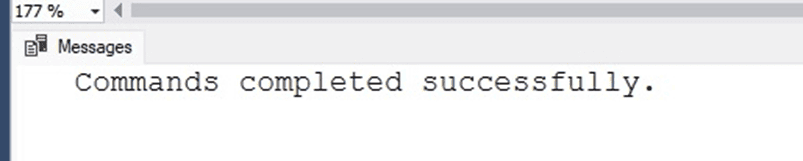
That is quite nice – zero pages is a far better IO cost than 50,687 pages!
The output of sys.fn_dblog is as follows:
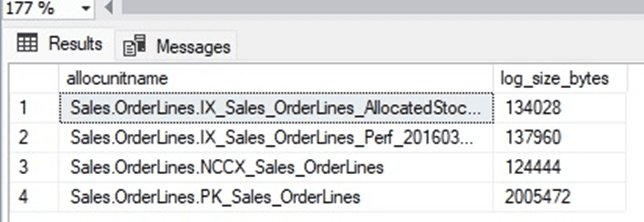
This may raise some eyebrows. Why did a transaction requiring no IO still incur log growth? Changing a column’s data type still requires metadata to be updated and those changes need to be committed to the log. In addition, adding referencing indexes back to the table was intentionally included this time prior to measuring the IO change. While these indexes were not expensive to create, the fact remains that building indexes is not free. As with the compression change, rebuilding indexes online will greatly reduce the potential disruption caused by this.
Step-by-Step: Altering Columns with Minimal Downtime
There are a wide variety of ways to alter a column’s definition. For example, a new table could be created with the new definition. A workflow for that change would look roughly like this:
- Create a new table with the new column definition. The table, constraints, triggers, and indexes will all require temporary names that are changed later.
- Copy all data into the new table.
- Drop all referencing indexes and constraints.
- Rename the old and new tables to essentially swap them.
- Rename indexes, constraints, triggers, etc…so that the new table has all of the valid names.
- Add back referencing indexes and constraints.
- Drop the legacy table when ready.
A process such as this is certainly complex, but could be effective in scenarios where the data size is small or write operations are not too frequent. If writes against the table are heavy, then keeping the old and new tables in sync during this process could be challenging. Triggers, views, and other trickery can be employed as needed, though not all developers or administrators will be comfortable building out a process with this level of complexity.
There are plenty of other examples of ways to alter column data types that have been documented in articles, presentations, and videos. While each has benefits and drawbacks, there is a key benefit to using compression: Uptime.
By taking the IO incurred by an ALTER COLUMN operation away and replacing it with the IO required to compress and decompress a table, the downtime experienced at the time of a software release is greatly reduced. Adjusting compression, dropping referencing indexes/constraints, and re-adding referencing indexes/constraints can be accomplished prior to and after the key software release changes. This breaks a large and disruptive release into a handful of smaller and far less risky sets of changes. It also moves the disruptive parts of the column-change to earlier and later times when convenient, instead of all-at-once during a critical release.
If online index rebuilds are available in the edition of SQL Server that is used (Enterprise or Developer), then the compression changes can be accomplished without downtime.
ROW Versus PAGE Compression
When using compression as a bridge to a smoother release of column data type changes, which variant is ideal? ROW and PAGE are both options, but there typically will be one clear answer to this question.
If a table is currently uncompressed, then it is due to one of two possibilities:
- The table is highly transactional in nature and compression would provide no benefit.
- Developers have never considered using compression.
If the table is the target of frequent small reads and writes as transactional applications will often be responsible for, then opt for the lightest-weight compression possible. ROW compression is the correct choice here as it is less aggressive and will have a smaller impact on writes and other transactional operations.
If the table is less transactional in nature and currently uncompressed, then there may be a benefit to applying ROW or PAGE compression permanently. This would mean that after the column width adjustment is complete, simply leave the column compressed and take no further action. Applications often have log, archive, reporting, or other tables that are optimal targets for compression and could benefit from being compressed as part of a column data type change and then left compressed afterwards as a permanent and beneficial change.
There is immense documentation on compression in SQL Server, including syntax, benefits, and how to estimate savings and effectiveness. Deciding whether on not to use compression requires research into how a table (and its indexes) are used and how they will be used in the future. For more information on this topic, check out Microsoft’s documents.
Conclusion
Altering the data type of a column can be a complex and risky change to design, test, and deploy. Data compression provides a convenient bridge between a pre-release data type and a post-release data type. Whether adjusting a primary key from INT to BIGINT, a DECIMAL column from two to four decimal places, or adding more precision to a DATETIME2 or TIME column, compression can reduce downtime and improve the performance of a release process significantly.
As a bonus, compression may be an ideal long-term decision for a table, in which case there is no need to change it back after-the-fact.
The steps outlined in this article allow a column data type change to be broken into smaller, less disruptive steps. These changes do not eliminate complexity or risk completely. Therefore, be sure to test release scripts and ensure that the expected behavior is what is experienced.
I hope you enjoyed this fun use of compression! If you have any comments or thoughts, let me know!



Load comments