
Imagine this: you have several directories full of SQL script files, and you need to know where a certain table is used. You’d rather like the context too, so you can check the whole SQL Expression and work out why it is running so slowly. Maybe, from that same daunting set of several directories, you need to search for a comment, either end of line, or block comment, perhaps structured. It could be that you just need to execute each query or statement in turn to check performance.
It’s not unusual to want to search just within strings. Although simple searches can be effective, you will at some point need a tool that is able to recognise and return a collection of strings representing the SQL code, divided up into the respective components of the SQL language.
For this article, we’ll use a PowerShell cmdlet, called Tokenize-SQLString, which is in my GitHub repository.
|
1 2 3 4 5 6 |
@' /* Select * from dbo.othertable */ drop view if exists dbo.Book_Purchases_By_Date; --drop the Book_Purchases_By_Date view Select 'create table dbo.YetAnothertable' '@|Tokenize-SQLString|Out-GridView |
This will provide the following stream of objects and finds the reference:
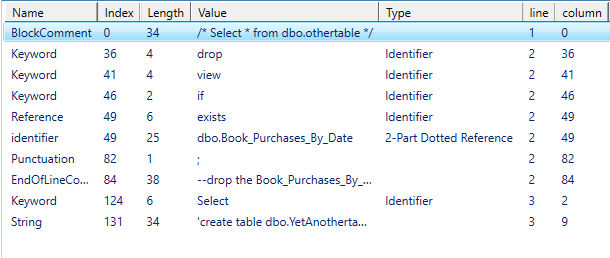
You’ll notice that it provides the location in the string (in the Index column of the output), and even the column and line in the query text. I’ve described elsewhere how to use the same technique to find external (3- and 4-part) references.
To achieve all this, you might think that nothing, but a parser will do. Sure, it would be nice if you have unlimited time, but really all you need is a tokenizer. The end-product of a tokenizer is generally the input to a parser. The tokenizer splits the input stream into individual language tokens such as strings, identifiers, keywords, and punctuation. It doesn’t need to be recursive, because, although elements of the SQL language are recursive, the input stream isn’t recursive. I use a tokenizer for some routine tasks such as for transferring comments associated with a table’s creation, and its columns, to the database metadata (assuming the RDBMS allows this).
Putting a tokenizer to work
As a playground, we can use for experiment a collection of SQL Expressions and DDL statements called the SQL Exerciser for Pubs (two flavours so far, SQL Server and PostgreSQL) It includes several different types of SQL Expression.
List different types of documentation
Here we list all the Javadoc documentation in the file (the fields can be formatted in Javadoc format or as YAML). JavaDocs remains a very good structured way of documenting any database objects. They are easily extracted by a tokenizer and then used to generate documentation and to apply ‘comments’ to the objects in whatever way is supported by the RDBMS. (in the following code, the multiline comment is a JavaDoc due to the preceding /** instead of the single asterisk character /*.
|
1 2 3 |
$TheFileName = '<MyPathTo>\PGPubsExerciser.sql' Tokenize-SQLString (Get-Content $TheFileName -raw)| where {$_.Name -ieq 'JavaDoc'} |
I’ll just show the first returned object:

We can just as easily get the block comments. Having got these, it is very easy to search for strings within them.
|
1 2 3 4 5 |
$TheFileName = '<MyPathTo>\PGPubsExerciser.sql' Tokenize-SQLString (Get-Content $TheFileName -raw)| where {$_.Name -in ('BlockComment','EndOfLineComment')}| foreach {[pscustomobject]@{‘line’=$_.line;’comment’=$_.Value }}| Out-GridView |
This outputs the following list in a new window.
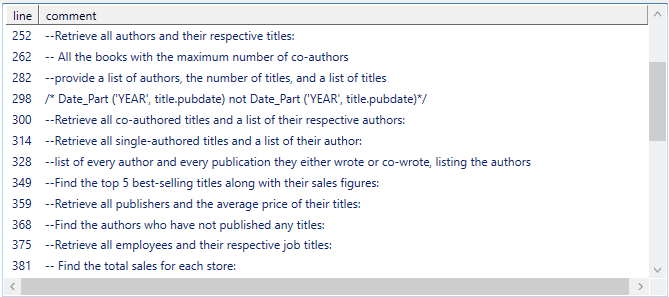
I’ve simply filtered for just those tokens that, in the first example, are Javadoc, and in the second example are either BlockComment or EndOfLineComment. Any of these token names can be used to filter with JavaDoc , BlockComment, EndOfLineComment, String, number, identifier, Operator and Punctuation.
Chopping up SQL expressions into an array of executable strings
For the next example, we’ll chop up a file (or variable) full of SQL expressions and batches into a string array that you can then execute, record or squirrel away however you wish.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# The path and filename of the sql file you want chopped up $TheFileName = '<MyPathTo>\PGPubsExerciser.sql' $Terminators =@('go',';') <# The list of terminators for SQL Expressions or batches in SQL Server, you may just want the batches, in which as it would be - $Terminators =@('go') #> #you'll need the contents in a variable $TheScriptContent = Get-Content $TheFileName -raw #This is the main pipeline that produces an array of SQL #Expressions in the original order $Expressions=$TheScriptContent|Tokenize-SQLString | where { $_.value -in $Terminators } | # because we know the position in the file from the #tokenizer, that's all we need to chop the file up foreach -begin { $StartIndex = 0 } { if ($_.value -eq 'GO') {$TerminatorLength=2} else {$TerminatorLength=0} $EndIndex = $_.Index; #We chop up the string occuring before the terminator "$($TheScriptContent.Substring( $StartIndex, $EndIndex - $StartIndex – $TerminatorLength+1 ).Trim())" # chopped up and trimmed $StartIndex = $EndIndex + $TerminatorLength+1; }|where { !([string]::IsNullOrWhiteSpace($_))} #no point in empty batches. |
You can then use the following code to make a prettier, textual listing”
|
1 2 |
1..$Expressions.count | foreach { [pscustomobject] @{'No.'=$_;'Expression'=$Expressions[$_-1]}} |
This will output the following listing:
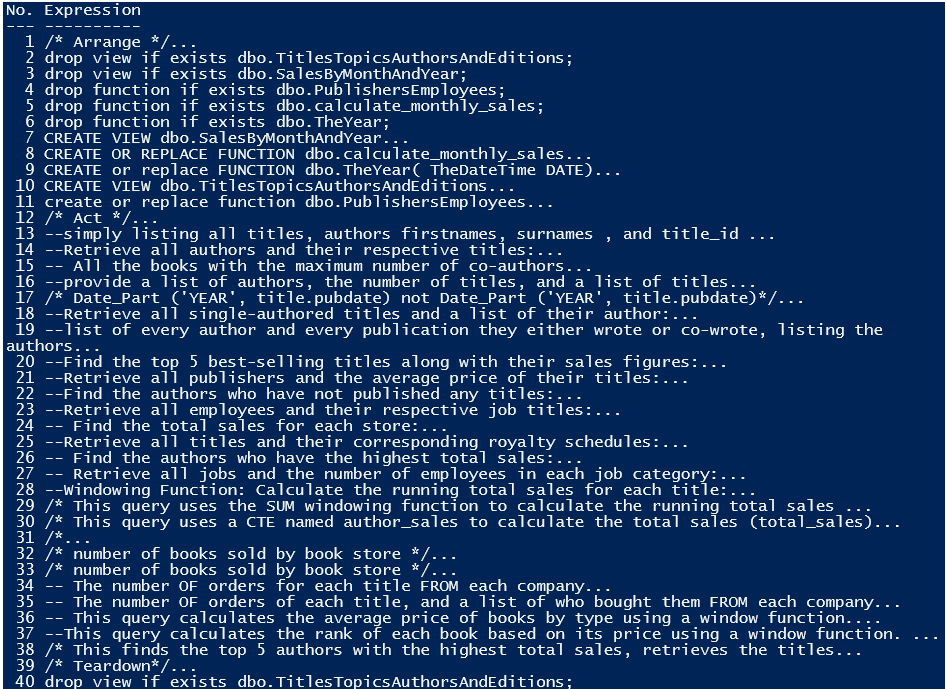
This will, obviously, store block comments and Javadocs in the same string. There will be times, in SQL Server, when you will want to use the client-side batch delimiter ‘GO’ to run entire batches rather than simple expressions, and so I’ve scripted this to allow for both types of statement terminators/batch separator, and any other batch separator you might be using. It removes ‘GO’ as it is client-side only but leaves the semicolon.
Return all table references.
Next, we’ll list all the permanent tables that are referenced in a file full of SQL Statements. It’s a bit more complicated, but manageable.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$TheFileName = '<MyPathTo>\PGPubsExerciser.sql' $Terminators =@('go',';') <# The list of terminators for SQL #Expressions or batches in SQL Server, you may just want the #batches, in which as it would be - $Terminators =@(‘go’) #> # The path and filename of the sql file you want chopped up # you'll need the contents in a variable $TheScriptContent = Get-Content $TheFileName -raw Get-Content $TheFileName -raw|Tokenize-SQLString|foreach { if (($_.Type -like '*Part Dotted Reference') ` -and ($_.Name -eq 'identifier')) { write-output $_.Value; } }| Sort-Object -Unique |
This will return a list that looks similar to the following:

It will include every table reference in the file, but not the local table references as you will get with CTEs.
Return table references separately for every SQL expression.
In a previous example, we separated each SQL Statement. For the next example, we want to get all the table references in every SQL Expression separately, including those in SQL Functions and views. This comes in handy where you cannot get dependencies from the live database, if you are using a database system that doesn’t provide them.
Note: To execute the following code you will need to install Powershell YAML that is located here: https://github.com/cloudbase/powershell-yaml using the following call::
|
1 |
Install-Module powershell-yaml |
Executing the following block of code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
$TheFileName = '<MyPathTo>\PGPubsExerciser.sql' $TheScriptContent = Get-Content $TheFileName -raw $Terminator = ';' $TableSources = Tokenize-SQLString $TheScriptContent | foreach -begin { $StartIndex = 0; $TableSource = @() } { if ($_.value -eq $Terminator) { $EndIndex = $_.Index + $_.Length; if ($TableSource.count -gt 0) { #If we found a tablesource being used @{ 'TableSources' = ($TableSource | ` Sort-Object -Unique); 'SQLExpression' = ` $TheScriptContent.Substring( $StartIndex, $EndIndex - $StartIndex); } } #move past the terminator $StartIndex = $EndIndex + $_.Length; $TableSource = @(); #Zero out the list of table sources } if (($_.Type -like '*Part Dotted Reference')) { $TableSource += $_.Value; } } $TableSources | foreach{ $_ | convertto-YAML } |
This results in the following partial output (Includes the final expression):
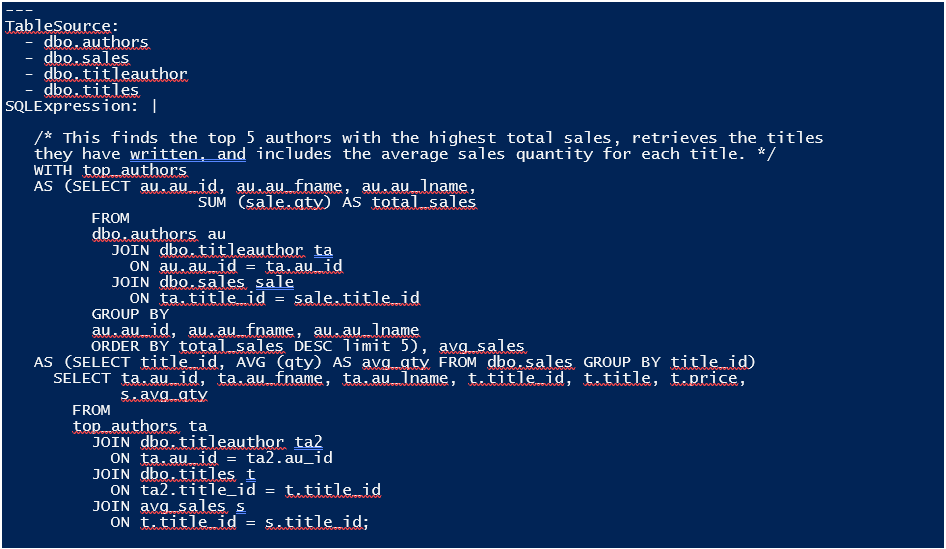
Colourising SQL Code
One can easily use the tokeniser to convert a SQL script into an HTML document (string) suitably colourised just like the IDE you use. This is useful for documentation and for quickly scanning code. At the moment, it is set for SSMS but this can be changed. It is easy to tweak it for the colourisation scheme that the developers are used to. The result can, of course, be viewed in a browser or browser-based IDE. The Title, the HTML header and the footer can be specified. This is a bit long to include with the article but the source is here as Convert-SQLtoHTML in Github.
It isn’t hard to use.
|
1 |
Convert-SQLtoHTML -SQLScript 'Select * from The_Table' |
If you look at the output, you can see that it has broken down each of the items, and then added font colour tags:
|
1 2 3 4 5 6 7 8 9 |
<!DOCTYPE html> <html> <head> <title>The SQL Code</title> </head> <body> <pre><font color="Blue">Select</font><font color="black"> *</font><font color="Blue"> from</font><font color="black"> The_Table</font></pre> </body> </html> |
You can feed it a file as well. We can try it out on our sample PostgreSQL code that we used in the previous examples:
|
1 2 3 4 |
$TheFileName = '<MyPathTo>\PGPubsExerciser.sql' $TheScriptContent = Get-Content $TheFileName -raw Convert-SQLtoHTML -SQLScript $TheScriptContent > ".\colorised.html" Start-Process -FilePath ".\colorised.html" |
Which (depending on your configuration,) will display in your browser like this …

I find this very handy for object-level scripts, where each object is converted into its HTML form. It makes a very simple documentation of the state of a database that is easy to navigate. I tend to save the tokeniser output to make it easier to do subsequent searches for specific strings such as table references.
Conclusions
I use the tokenizer mainly for test purposes, for exercising individual queries from a longer SQL file that I can edit in a SQL Editor, and getting timings from them. I also use it for working out what tables are, and are not, being used within views and functions. However, it is also handy for a range of tasks such as formatting SQL or syntax highlighting it. I use it for getting and preserving the comments around CREATE statements so that the live database objects and columns can have comments attached to them. I suspect that there are other uses. It is an open-ended tool for the database developer who is a PowerShell user .
Note: For an additional practical application of the tokenizer, check out the Redgate Product Learning article: Code Visibility: Browsing through Flyway Migration Files. It shows how to use the tokenizer to colorize a set of Flyway migration files (in HTML, such as for web documentation).
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments