
When you have code in a SQL Server database, the only guaranteed way to know whether the code will run is to actually run the code. Of course, there are certain checks when you deploy code to a SQL Server database: The server will check whether any columns exist on tables used by the code you are deploying exists but if a table does not exist it allows the code to be deployed and further those objects could be altered or subsequently dropped so that the code no longer works when you run it. There are other problems too: Checks on dependencies aren’t made, for example, during build if a procedure references a missing table.
References and Their Validation
SQL Server Data Tools (SSDT) attempts to help developers by validating that any code that references an object will run when it is called. This means that every time the project is built, any reference to an object is validated to ensure that the object exists, and that the way it is used is correct.
To show an example: If we have this table definition …
|
1 2 3 4 5 6 7 |
CREATE TABLE employees ( employee_id INT NOT NULL IDENTITY(1, 1), first_name VARCHAR(255) NULL, last_name VARCHAR(255) NOT NULL, CONSTRAINT [pk_employees] PRIMARY KEY ( employee_id ) ); GO |
… then the following code will produce an error because the INSERT operation is trying to insert into columns that do not exist.:
|
1 2 3 4 5 6 |
CREATE PROCEDURE add_employee (@first_name VARCHAR(255), @last_name VARCHAR(255) ) AS INSERT INTO employees ( [bert], [ernie], [100 airplanes flying] ) SELECT @first_name, @last_name, 1; GO |
It is possible to have this sort of problem in SQL Server simply by creating the procedure before the table (due to deferred name resolution)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE PROCEDURE add_employee (@first_name VARCHAR(255), @last_name VARCHAR(255) ) AS INSERT INTO employees ( [bert], [ernie], [100 airplanes flying] ) SELECT @first_name, @last_name, 1; GO CREATE TABLE employees ( employee_id INT NOT NULL IDENTITY(1, 1), first_name VARCHAR(255) NULL, last_name VARCHAR(255) NOT NULL, CONSTRAINT [pk_employees] PRIMARY KEY ( employee_id ) ); GO |
You can even work the same trick with functions or views as well by subsequently dropping the correct table and then creating a faulty table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
CREATE TABLE employees ( employee_id INT NOT NULL IDENTITY(1, 1), first_name VARCHAR(255) NULL, last_name VARCHAR(255) NOT NULL, CONSTRAINT [pk_employees] PRIMARY KEY ( employee_id ) ); GO create VIEW Employee as SELECT Employee_ID, coalesce(First_name,'')+ ' ' + last_name AS name FROM employees go drop table employees; go create table employees( employee_id int not null identity(1,1), [bert] varchar(255) null, [ernie] varchar(255) not null, [100 airplanes flying] bit not null, constraint [pk_employees] primary key (employee_id) ); |
No errors so far! Then if we ran this query
|
1 |
SELECT * FROM employee |
Which would give …
|
1 2 3 4 5 6 7 8 |
Msg 207, Level 16, State 1, Procedure Employee, Line 3 Invalid column name 'First_name'. Msg 207, Level 16, State 1, Procedure Employee, Line 3 Invalid column name 'First_name'. Msg 207, Level 16, State 1, Procedure Employee, Line 3 Invalid column name 'last_name'. Msg 4413, Level 16, State 1, Line 1 Could not use view or function 'employee' because of binding errors. |
In this case SQL Server would have happily created the table, the view and then the new version of the table. Both these errors would break a deployment despite there being no errors during the actual deployment process.
SSDT and the validation of references in other databases
What SSDT does in this case is see that the stored procedure or view has a reference to employees and it is using the three non-existent columns but because they do not exist, SSDT can create a warning that the code is not valid.
This is great when you have the code that you will call within your SSDT project; but what if it needs to validate something outside the SSDT project such as “select [whoopsie] from sys.sysprocesses” or “select wrong_column from otherdatabase.dbo.employees”. The code for the system DMVs or another database would not be in your project because your project only contains the code for your database. What would happen if you had a linked server pointing to an AS/400 where the files referenced could not be put in your project as they are in a whole different SQL dialect?
The answer for SSDT projects is database references. Database references allow SSDT to validate that the code that you call in your project is valid because even though the system DMVs or other databases do not exist in your project, there is a DACPAC (Data-tier Application Component Package) which contains a model of the relevant objects of those databases which is used to validate that the model in your database is correct.
What happens if you get a warning?
When I learnt to program, I did a lot of reading and one of those books, “Code Complete”, left me with a few habits that I still use today and one of those is to never ignore compiler warnings and turn them into errors. This is the same with C as it is with T-SQL. By default, a new SSDT project will just show a warning about invalid references but you should turn on “Treat Transact-SQL warnings as errors” which is on the “Build” page of the SSDT project properties:
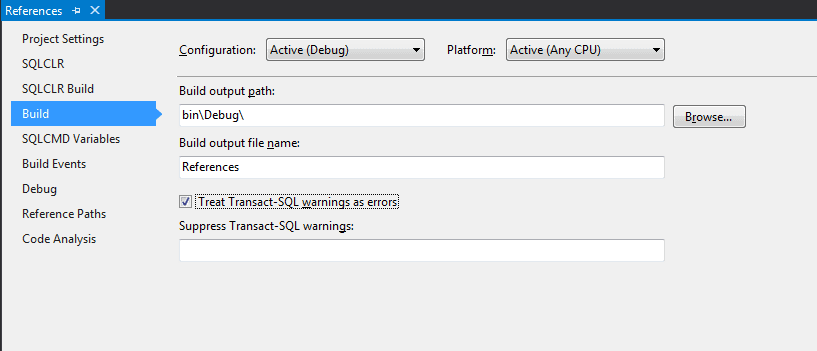
If you import a legacy database into SSDT you may find that you get a lot of these error so you could leave this disabled but aim to have it enabled at some point.
References are not just about validation
SSDT does more than just use the references to validate that code is correct. When you use references as well as validation you also get intellisense and if you are referencing a separate SSDT project rather than a DACPAC, when you refactor the target object any references to it will also be updated. For example if we have two projects, “Sales” and “HumanResources”, there is a stored procedure in the Sales database that references the employees table in the HumanResources database, if we use the rename refactoring to change the Id column on the employees table to employee_id, the reference to it in the HumanResources database will also be updated:
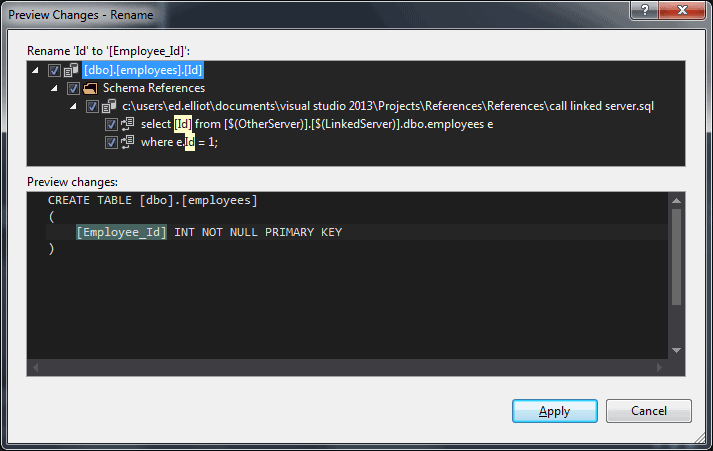
We can also quickly jump from the stored procedure that uses the table to the table definition by putting the cursor over the table name and pressing ctrl+b or right-clicking and choosing “Go to Declaration” so it makes developing fast, there is certainly no need to find the table in object explorer and script out the definition.
What can you reference?
You can reference:
- Other SSDT projects in the current Visual Studio solution
- Two of the system databases, master and msdb
- Any other database that has been built into a DACPAC, either as an SSDT project or extracted using SSMS, DACfx or sqlpackage.exe
Other SSDT projects in the same solution are the simplest form of database reference, you have your code in one project and you call it from another one.
The two system databases are simply extracts of the master or msdb databases put into DACPACs. To help support different versions of SQL Server, SSDT actually ships with a version of master.DACPAC and msdb.DACPAC for each version of SQL Server including Azure that SSDT supports.
The last type allows us to reference a pre-compiled SSDT project in the form of a DACPAC which is useful as you can manage dependencies really quite simply. For example in my SSDT projects I have a unit test project and that references tSQLt, I don’t have to deploy tSQLt for every new project I set up, I simply add my pre-built tSQLt.DACPAC as a reference in the unit test project and then I can start using the tSQLt procedures directly.
Unless we have a DACPAC when we use linked servers to reference other databases, we will have to disable the option of treating T-SQL warnings as errors: This is not good, since we are losing the major benefit of SSDT. If we are in this situation, it is often preferable to create a dummy DACPAC with the skeleton versions of objects we are calling in our project. There is a risk that the skeleton project is incorrect but that is unlikely and can be fixed fairly easily.
What types of references are there?
When writing T-SQL code, there are a number of ways to reference an object, the general semantics for referencing objects in SQL Server itself are:
|
Type |
Example |
Linked Server |
Cross Database |
Same Database |
|
Different Database, Different Server |
Server.Database.Schema.Object |
|
|
|
|
Different Database, Same Server |
Database.Schema.Object |
|
|
|
|
This Database |
Schema.Object |
|
||
|
This Database |
Object |
|

References to the system databases, master or msdb are automatically set to “Different Database, Same Server” but the objects are available to reference using Schema.Object as they are treated as special cases.
“This Database” – Deploying Composite Objects & Deleting Objects
There is an option (DropObjectsNotInSource) that you can use which deletes any objects which are in the target but which are not in the source. This is a really useful way to make sure that the objects that you remove from your code are actually dropped from the database. If you do not have the option enabled your database fills up with old unused objects and backup objects which shouldn’t really be there so it is best to have this option enabled.
When you deploy a DACPAC if you use “This Database” references to build up a database you need to deploy all of the DACPACs together which you can do by including the option IncludeCompositeObjects. This will silently merge all of the DACPACs together before comparing them all to the target database. If you do not use the IncludeCompositeObjects option then any objects in the referenced DACPACs will be dropped.
Reference aware statements
There is a complexity with references that is quite important. When you deploy code to SQL Server you need to supply the name of the linked server and or the database you will be calling:
|
1 2 3 4 5 |
CREATE PROCEDURE get_employee ( @empoyee_id INT ) AS SELECT * FROM another_database.hr.employees WHERE employee_id = @employee_id |
If another_database exists on the same server, then you will get to the table you want. SSDT has no way of knowing that the DACPAC for another_database is actually going to be deployed to a database with that name so, instead of supplying the database name, you need to replace the database name with a SqlCmd variable. The SqlCmd variable is created automatically for you when you create the reference:
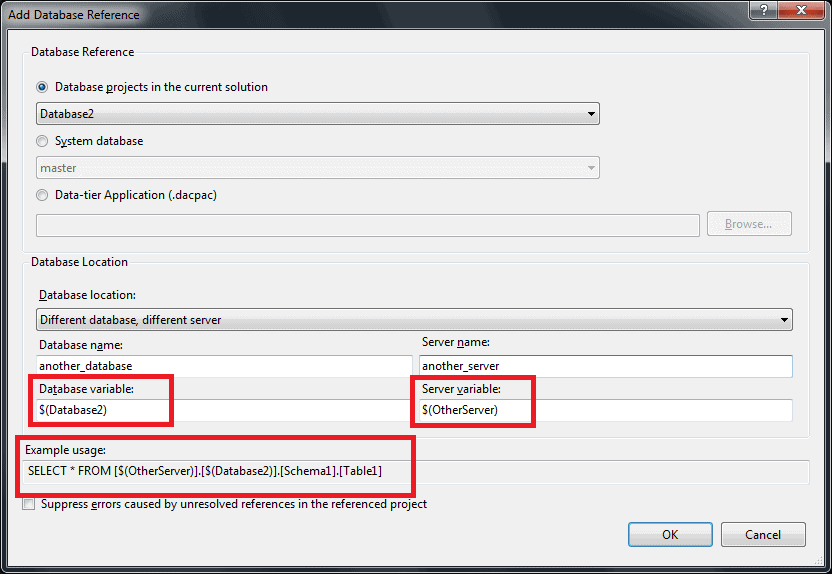
If you are adding a “Different Database, Different Server” reference SSDT will create a Server and a Database SqlCmd variable.
You will then need to manually modify your statements to use the SqlCmd variables so:
|
1 2 3 4 5 |
CREATE PROCEDURE get_employee ( @empoyee_id INT ) AS SELECT * FROM [$(another_database)].hr.employees WHERE employee_id = @employee_id |
If you do not do this then you will get an error for each reference. When the code is deployed, the value of the variables are replaced with the values that you want to use for that deployment: This means that you can easily deploy the same code to different environments without having to have the same linked server and database names.
How do you add references?
References are added in a similar way to standard references in Visual Studio: right click on the “References” node of your SSDT project and choose “Add Database Reference”, this will start the “Add Database Reference” dialog:
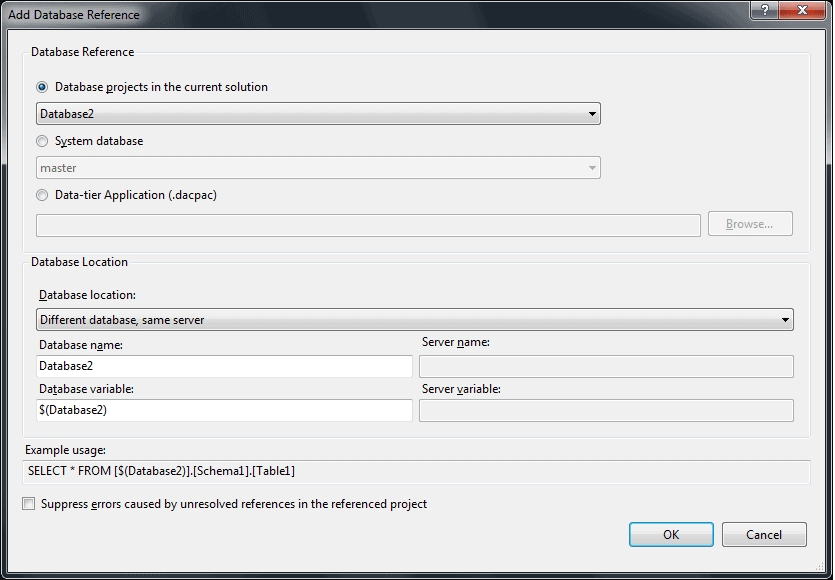
There are three targets for your reference, you can add a reference to any one of:
- SSDT project in your current solution
- System Database (master/msdb)
- Pre-Built DACPAC file
Once you have chosen your target, you can choose the type of reference and create the variables that you need for the reference-aware statements.
Circular References
There is one final complexity with references in SSDT. References use the msbuild project system which means you cannot have a circular reference. SQL Server however has no problem creating a set of circular references. SQL Server does, however, allow circular references because a database is not deployed as a whole but as a chain of individual statements.
If you have circular references, then you will need to identify the code that references the other projects but is not called by the other projects. These must then be moved into separate SSDT projects so you can then use “This References” to deploy them together.
For more details on circular references see “SSDT: How to Solve the Circular References Issue” by Luca Zavarella:
Conclusion
References in SSDT add an extra level of complexity to manage. In return, they provide a lot of benefits in terms of the resilience of your deployments. Once you have your code in SSDT and compiling, you should then find it easier to start refactoring out the cross-database calls where possible. Where it is not possible to remove them you will still be able to get the benefits of using SSDT.
Redgate is working on some tools to help with SSDT development. We’d love to know more about how you use SSDT and what problems you face. Please visit our page on the Redgate site to learn more, help us to learn more about your SSDT requirements, and sign up to help us with the beta.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments