

DevOps, Continuous Delivery & Database Lifecycle Management
Continuous Integration
I find testing to be a very tedious business: All developers do. Testing SQL databases is something you like doing if you find the process of testing applications too exciting. The answer for the rest of us is, of course, to mechanise as much of the test process as possible.
Here is a simple form of SQL DML test for SQL Select statements. I think of it as a type of integration test. Where you are doing Continuous Integration, it is a good way of ensuring that nothing serious is broken. By ‘serious’, I’d include poor performance as well as the wrong result.
The idea is that you just develop, in your favourite IDE such as SSMS or VS, a batch of SQL queries or execute statements. You check them as necessary to make sure they’re right. You then save the file in a directory. You do as many tests as you like, and use as many subdirectories as you like.
Here is an imaginary test. Don’t worry about the SQL Statements, they are just there to demonstrate
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
--the first query PRINT '(first)' PRINT '-SaveResult' SELECT p1.ProductModelID FROM Production.Product AS p1 GROUP BY p1.ProductModelID HAVING max(p1.ListPrice) >= ALL ( SELECT avg(p2.ListPrice) FROM Production.Product AS p2 WHERE p1.ProductModelID = p2.ProductModelID ); --the second query PRINT '(Second)' SELECT sum(s.TotalDue), count(*), right(convert(CHAR(11), s.OrderDate, 113), 8), TerritoryID FROM Sales.SalesOrderHeader AS s GROUP BY right(convert(CHAR(11), s.OrderDate, 113), 8), TerritoryID WITH ROLLUP ORDER BY min(s.OrderDate) --and the third query PRINT '(final)' PRINT '-noMoreResult' SELECT p.FirstName + ' ' + p.LastName AS customer, SalesOrderNumber AS CurrentOrder, first_value(SalesOrderNumber) OVER ( PARTITION BY s.CustomerID ORDER BY SalesOrderNumber ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS FirstOrder, last_value(SalesOrderNumber) OVER ( PARTITION BY s.CustomerID ORDER BY SalesOrderNumber ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING ) AS LastOrder, s.TotalDue, convert(CHAR(11), s.OrderDate, 113) AS DateOrdered FROM Sales.SalesOrderHeader s INNER JOIN Sales.Customer AS c ON s.CustomerID = c.CustomerID INNER JOIN Person.Person AS p ON c.PersonID = p.BusinessEntityID WHERE orderDate > dateadd(MONTH, -1, ( SELECT max (orderDate) FROM Sales.SalesOrderHeader )) ORDER BY OrderDate |
You’ll notice some print statements here. They’re only necessary if you want to do something different to the default behaviour. When you bang the button to run the test, every query in a batch will have its own timings, results, I/O information and execution plans, so when they’re saved to disk, they need a unique name.
That PRINT '(final)' not only gives it a name but also makes it easier to pick out the messages that belong to each query. The test harness saves the result to disk, using that name as filename and in the XML.
Sometimes, you’ll have a query that has an enormous result that you don’t want saved to disk. That PRINT '-noMoreResult' deals with that. As the name suggests from then on in the batch, unless you then do PRINT '-SaveResult'. Yes, there are ways of being more controlling if you need to be.
A lot of the time, you will want to make sure that the result that is returned is correct. This is why the result is automatically saved as an XML file. If you leave a file with the correct result in the directory, then the PowerShell script obligingly compares the result with that and produces a report that tells you what the differences are.
That’s it, basically.
Why do it?
Throughout development, you must continuously check that certain key queries produce the correct data, and do it quickly. Not only should they do it quickly on the test or QA server, but also under realistic loads. They must use effective execution plans.
This means testing a number of relevant SQL Expressions or batches against maybe several databases, normally replicas of the same database in the same version, but stocked with different amounts of data. I do it to see whether the result is what it should be, how long it took and what were the CPU or I/O resources used. If a problem crops up, I will want the query plan that was used. These SQL Queries could be simple or complex, and they are intended to check out the vital functions to make sure you never pass on a release that is severely broken. I do it on every build, so it has to be able to work unattended. The benefit is that if something breaks, I can be pretty sure of what did it: it is what I’ve done on the day before the test. Because you have the execution plans, you can email an expert for help as well.
There are plenty of test frameworks that will do this sort of test, but nothing I’ve come across that does it all, in a way that is unobtrusive and easy to use. Above all, I want it to be easy to change the SQL. (Actually, I like changing the PowerShell too, but that is another story)
What does it do?
With PowerShell you get some timing metrics for free with the Measure-Command cmdlet that gives you the end-to-end time. This helps give you the end-to-end time for a whole batch, but this isn’t sufficient. We also need to get a rough idea of the server CPU and timing, the query execution plan and maybe even a more accurate measure of the time taken to execute the command on the server. Basically, you don’t want to be bothered with the results of all this unless something goes wrong. You also will want to specify a number of server instances/databases to do the test run with.
For me, the most important thing is to be able to add a number of queries to a file and have them executed against a particular database and server.
How does it do it?
Here is a simple test harness to show the guts of the script. The actual script does rather more but this sample should work if you fill in the server, database credentials and the path to the test. Here, I leave out the distracting routine stuff of getting each database and each batch, and just show the important stuff. As you can see from the script, it is a simple task that executes the batch, and checking the results by monitoring the messages that come back for errors and special statements that switch on or off certain features. For comparisons of results, I use the .NET library for comparing XML files. You will need to fill in the details (look for 'These below need to be filled in! ‘) before it will work.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 |
#make sure no errors slip through set-psdebug -strict; $ErrorActionPreference = "stop" try { Add-Type -path "${env:ProgramFiles(x86)}\XmlDiffPatch\Bin\xmldiffpatch.dll" } #load xmldiffpatch to test results catch #oops, he hasn't installed it yet { write-warning @' This routine currently compares results to make sure that the results are what they should be. It uses XMLDiff, a NET tool. It can be downloaded from here. It only does so if you leave a file with the CorrectResult suffix in the filename. If you don't want this facility, remove it! '@; exit; } $xmlDiff = New-Object Microsoft.XmlDiffPatch.XmlDiff; # Create the XmlDiff object $xmlDiff = New-Object Microsoft.XmlDiffPatch.XmlDiff( [Microsoft.XmlDiffPatch.XmlDiffOptions]::IgnoreChildOrder); #poised to test results against what they should be #here is the SQL batch for testing. It a real routine this would be pulled off disk # but we need to keep this test simple $SQL =@" --the first query print '(first)' print '-SaveResult' SELECT p1.ProductModelID FROM Production.Product AS p1 GROUP BY p1.ProductModelID HAVING MAX(p1.ListPrice) >= ALL (SELECT AVG(p2.ListPrice) FROM Production.Product AS p2 WHERE p1.ProductModelID = p2.ProductModelID); --the second query print '(Second)' SELECT sum(s.TotalDue), count(*), right(convert(CHAR(11),s.OrderDate,113),8),TerritoryID FROM Sales.SalesOrderHeader AS s GROUP BY right(convert(CHAR(11),s.OrderDate,113),8), TerritoryID WITH ROLLUP ORDER BY min(s.OrderDate) --and the third query print '(final)' print '-noMoreResult' SELECT p.FirstName+ ' '+p.LastName AS customer, SalesOrderNumber AS CurrentOrder, FIRST_VALUE(SalesOrderNumber) OVER(PARTITION BY s.CustomerID ORDER BY SalesOrderNumber ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS FirstOrder, LAST_VALUE(SalesOrderNumber) OVER(PARTITION BY s.CustomerID ORDER BY SalesOrderNumber ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS LastOrder, s.TotalDue, convert(CHAR(11),s.OrderDate,113) AS DateOrdered FROM Sales.SalesOrderHeader s INNER JOIN Sales.Customer AS c ON s.CustomerID = c.CustomerID INNER JOIN Person.Person AS p ON c.PersonID = p.BusinessEntityID WHERE orderDate > DateAdd(MONTH,-1,(SELECT max(orderDate) FROM Sales.SalesOrderHeader)) ORDER BY OrderDate "@ $ErrorActionPreference = "Stop" # nothing can be retrieved #--------------------These below need to be filled in! ----------------------------- $pathToTest = "$env:USERPROFILE\MyPath\" $databasename = "AdventureWorks" #the database we want $serverName = 'MyServer' #the name of the server $credentials = 'integrated Security=true' # fill this in before you run it! # if SQL Server credentials, use 'user id="MyID;password=MyPassword"' #--------------------These above need to be filled in! ----------------------------- #now we declare our globals. $connectionString = "Server=$serverName;DataBase=$databasename;$credentials; pooling=False;multipleactiveresultsets=False;packet size=4096"; #connect to the server $message = [string]''; # for messages (e.g. print statements) $Name = ''; $LastMessage = ''; $SQLError = ''; $previousName = ''; $SavingResult = $true; $ThereWasASQLError = $false; try #to make the connection { $conn = new-Object System.Data.SqlClient.SqlConnection($connectionString) $conn.Open() } catch #can't make that connection { write-warning @" Sorry, but I can't reach $databasename on the server instance $serverName. Maybe it is spelled wrong, credentials are wrong or the VPN link is broken. I can't therefore run the test. "@; exit } # This is the beating heart of the routine. It is called on receipt of every # message or error $conn.add_InfoMessage({#this is called on every print statement or message param ($sender, #The source of the event $event) #the errors, message and source if ($event.Errors.count -gt 0) #there may be an error { $global:SQLError = "$($event.Errors)"; #remember the errors $global:ThereWasASQLError = ($global:SQLError -cmatch '(?im)\.SqlError: *\w') #you may think that if there is an error in the array... but no there are false alarms }; $global:LastMessage = $event.Message; #save the message $global:message = "$($message)`n $($global:LastMessage)";#just add it switch -regex ($global:LastMessage) #check print statements for a switch { '(?im)\((.{2,25})\)' #was it the name of the query? { $global:Name = $matches[1] -replace '[\n\\\/\:\.]', '-'; #get the name in the brackets $null > "$pathToTest$($name).io"; #and clear out the io record for the query break; } '(?im)-NoMoreResult' { $global:SavingResult = $false; break; } #prevent saving of result '(?im)-SaveResult' { $global:SavingResult = $true; break; } #switch on saving of result default { #if we have some other message, then record the messge to a file if ($name -ne '') { "$($event.Message)" >> "$pathToTest$($name).io"; } } } } ); $conn.FireInfoMessageEventOnUserErrors = $true; #collect even the errors as messages. #now we do the server settings to get IO and CPU from the server. # We do them as separate batches just to play nice @('Set statistics io on;Set statistics time on;', 'SET statistics XML ON;') | %{ $Result = (new-Object System.Data.SqlClient.SqlCommand($_, $conn)).ExecuteNonQuery(); } #and we execute everything at once, recording how long it all took try #executing the sql { $timeTaken = measure-command { #measure the end-to-end time $rdr = (new-Object System.Data.SqlClient.SqlCommand($SQL, $conn)).ExecuteReader(); } } catch { write-warning @" Sorry, but there was an error with executing the batch against $databasename on the server instance $serverName. I can't therefore run the test. "@; exit; } if ($ThereWasASQLError -eq $true) { write-warning @" Sorry, but there was an error '$SQLError' with executing the batch against $databasename on the server instance $serverName. I can't therefore run the test. "@; } if (-not(test-path "$pathToTest")) {new-item "$pathToTest" -type directory} #now we save each query, along with the query plans do #a loop { if ($name -eq $previousName) #if we have no name then generate one that's legal { $Name = ([System.IO.Path]::GetRandomFileName() -split '\.')[0] }#why would we want the file-type? #the first result will be the data so save it $datatable = new-object System.Data.DataTable $datatable.TableName = $name $datatable.Load($rdr)#pop it in a datatable if ($SavingResult) { $datatable.WriteXml("$pathToTest$($name).xml"); } #and write it out as XML so we can compare it easily else #if we aren't saving the result delete any previous tests { If (Test-Path "$pathToTest$($name).xml") { Remove-Item "$pathToTest$($name).xml" } } $datatable.close; #and close the datatable if ($rdr.GetName(0) -like '*showplan')#ah we have a showplan!! { while ($rdr.Read())#so read it all out quickly in one gulp { [system.io.file]::WriteAllText("$pathToTest$($name).sqlplan", $rdr.GetString(0)); } } $previousName = $name #and remember the name to avoid duplicates #now we wonder if the DBA has left an XML file with the correct result? if (test-path "$pathToTest$($name)CorrectResult.xml") { #there is a correct result to compare with! $CorrectResult = [xml][IO.File]::ReadAllText("$pathToTest$($name)CorrectResult.xml") $TestResult = [xml][IO.File]::ReadAllText("$pathToTest$($name).xml") if (-not $xmlDiff.Compare($CorrectResult, $TestResult))#if there were differences.... { #do the difference report $XmlWriter = New-Object System.XMl.XmlTextWriter("$pathToTest$($name).differences", $Null) $xmlDiff.Compare($CorrectResult, $TestResult, $XmlWriter) $xmlWriter.Close(); $message = "$message`nDifferences found to result of query '$name'" } else #remove any difference reports with the same name { If (Test-Path "$pathToTest$($name).differences") { Remove-Item "$pathToTest$($name).differences" } } } } while ($rdr.NextResult())# and get the next if there is one $rdr.Close() #now save all the messages for th batch including the errors. $message > "$($pathToTest)all.messages" #and add the end-to-end timing. "End-To-End time was $($timeTaken.Milliseconds) Ms" >> "$($pathToTest)all.messages" |
And an inspection of the directory shows that the files are there
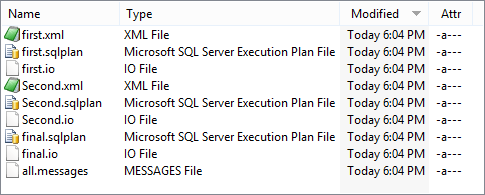
The execution plans can be clicked on and inspected if you have SQL Server Management Studio, or Visual Studio installed. If not you can drag the files and drop them on SQL Server Central’s SQL Tuneup page
The .io files and all.messages files are text files, but this is a script so you can call them whatever suits you.
That ‘final.io’ file has the following information:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Person'. Scan count 1, logical reads 106, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Customer'. Scan count 1, logical reads 123, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderHeader'. Scan count 2, logical reads 1372, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 266 ms, elapsed time = 263 ms. |
The all.Messages file has all the messages from all the individual SQL Select statements, but also the following
|
1 |
End-To-End time was 40 Ms |
If you want the PowerShell to detect differences in the result you just put in an XML file with the correct result (usually from a previous verified run). Here is a run with an error in it, showing the file with the correct result
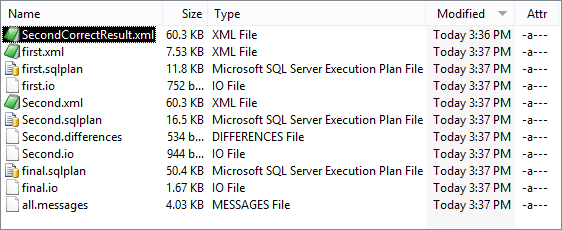
The XML files will need an XML editor to view them. If there is a difference between what there should be and what there is, there will be an XML difference report.(in this case in the file Second.differences
|
1 2 |
<?xml version="1.0"?><xd:xmldiff version="1.0" srcDocHash="17444750020386653172" options="IgnoreChildOrder " fragments="no" xmlns:xd="http://schemas.microsoft.com/xmltools/2002/xmldiff"><xd:node match="2"><xd:node match="6"><xd:node match="1"><xd:change match="1">154205.5859</xd:change></xd:node></xd:node><xd:node match="1"><xd:node match="1"><xd:change match="1">170471.7903</xd:change></xd:node></xd:node><xd:node match="4"><xd:node match="1"><xd:change match="1">189921.3994</xd:change></xd:node></xd:node></xd:node></xd:xmldiff> |
The Full Script
Here is the full script. (it is too big to embed in the article). Anyone who reads my PowerShell articles will know that I prefer to use either the registered server group of the central management servers, rather than specify connections. I set up a test group, usually with all supported levels of SQL Server.
I have the practical difficulty that I sometimes have the same physical server under two different names and so I correct for that just to get the unique physical servers, along with their connection strings. For good measure, I have a list of servers to avoid (the ones at a version level I’m not interested in supporting)
|
1 2 3 4 5 |
get-childitem 'SQLSERVER:\sqlregistration\' -recurse | where { $_.GetType() -notlike '*ServerGroup*' } | Select servername, connectionstring | where-object { $avoidList -NotContains $_.servername } | sort-object -property servername -unique | foreach-object { and so on ... |
For this version, I’ve set it to pull out all your registered servers, but I use a version that looks in a subgroup so I change the path to the list of test databases. You can use it either way because you have the $AvoidList to prevent servers getting into the list that you don’t want to test against.
For each server, I then run all the tests, serially. I get these from whatever files I can find, including subdirectories. I then filter out any files I don’t want.
|
1 2 3 4 5 6 |
Get-ChildItem $pathToTest -Recurse -directory Foreach ($folder in (Get-ChildItem $pathToTest -Recurse -Filter '*.sql'|Where-Object {$_.Extension -eq '.sql' })) { if (($ExcludeFiles -notin $Folder.Name) -and ($excludeDirectories -notContains $folder.Directory.name)) { And so on ... |
The result files are contained in subdirectories named after the name of the instance that ran the test, and the name of the result.
Because it is so easy to get the registered servers using the SQL Server PowerShell provider, I use that, so there is something else you’ll need to worry about before you run the code.
Wrapup
This routine doesn’t replace any of the standard tests, but it can catch errors that would otherwise cause problems to these tests, or maybe break the CI build. I find it handy because it takes almost no effort to run, doesn’t leave artifacts in my code, and gives me, saved on file, everything I need to see what the problem might be (including anythe SQL Error Message). I can even archive the data and spot trends. Naturally, I’ve given you just enough to customise a script to your particular requirements, and I hope that I’ve kickstarted someone to use PowerShell to the max for database development.

DevOps, Continuous Delivery & Database Lifecycle Management
Go to the Simple Talk library to find more articles, or visit www.red-gate.com/solutions for more information on the benefits of extending DevOps practices to SQL Server databases.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments