
A closure table is a design pattern for representing hierarchies in SQL databases using two tables: one for entities (nodes) and one for relationships (edges). Unlike self-referencing tables (parent_id), a closure table stores every ancestor-descendant path, making it straightforward to query subtrees, find ancestors, calculate depths, and track relationships that change over time.
This approach uses standard SQL JOINs and GROUP BY – no recursive CTEs or HIERARCHYID required. This article demonstrates converting the AdventureWorks Employee hierarchy from a self-referencing table to a closure table pattern.
Introduction
You’ll find self-referencing tables being used to represent hierarchies in SQL databases, and they seem like an elegant recursive way to do it: AdventureWorks2016 has three of them, including one to map the staff hierarchy. The problem is, of course, that such an approach mixes relationships and values. Before we get too conceptual about this difficulty, just imagine how you’d deal with a sudden request from your AdventureWorks bosses to be able to track the corporate hierarchy over time, or to work out when, and for how long, Tim was reporting to Alice. Yes, the information isn’t there, and you can’t deal with it in a self-referencing table even if you had the information. Relationships can have attributes as well as entities.
The Closure Table pattern
Real-life hierarchies need more than a parent-child relationship. Such hierarchies are often best modelled in SQL Server by having one table for the nodes and another for the ‘edges’, the relations between them. This ‘Closure Table’ pattern is much more suitable for real-life hierarchies that change over time or have conditions or other subtleties in the nature of the branches. You can add attributes of the relationship. In real life, for example, relationships tend have a beginning and an end, and this often needs to be recorded, so your database can tell you the state of the hierarchy at a certain point in time.
EDITOR’S NOTE: SQL Server 2017 has a new feature called Graph Databases which is similar to the techniques explained here. To learn more about this feature, take a look at the series by Robert Sheldon.
Closure tables are plain ordinary relational tables that are designed to work easily with relational operations. It is true that useful extensions are provided for SQL Server to deal with hierarchies. The HIERARCHYID data type and the common language runtime (CLR) SqlHierarchyId class are provided to support the Path Enumeration method of representing hierarchies and are intended to make tree structures represented by self-referencing tables more efficient, but they are likely to be appropriate for some but not all the practical real-life hierarchies or directories. As well as path enumerations, there are also the well-known design patterns of Nested Sets and Adjacency Lists. In this article, we’ll concentrate on closure tables.
A directed acyclic graph (DAG) is a more general version of a closure table. You can use a closure table for a tree structure where there is only one trunk, because a branch or leaf can only have one trunk. We just have a table that has the nodes (e.g. staff member or directory ‘folder’) and edges (the relationships). We are representing an acyclic (no loops allowed) connected graph where the edges must all be unique, and where there is reflexive closure. (each node has an edge pointing to itself).
Read also:
Subqueries for hierarchy traversal
Temporal tables for tracking hierarchy changes
An Example of a Closure Table
Vadim Tropashko, in his book SQL Design Patterns (Rampant Techpress, Kittrell, NC, USA, 2006.) gave a good explanation of the Closure pattern, and it has since been described in more detail in Bill Karwin’s SQL Antipatterns (The Pragmatic Bookshelf Dallas Texas).
We won’t go into the theory. We’ll just get stuck into demonstrating it with data from AdventureWorks2016 and so you can try things out.
Preparation
We are going to convert the AdventureWorks Employee table from a hierarchy path to a closure table. Then we will see if we can insert a department, delete a manager, insert someone and so on, just to see how hard it is.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
--create our temporary working staff hierarchy table DROP TABLE IF EXISTS #staff CREATE TABLE #Staff ( Employee_ID INT IDENTITY PRIMARY KEY,--we will use this as the key OrganizationNode HIERARCHYID, Ancestors AS (Coalesce(OrganizationNode.GetLevel(),0)) PERSISTED, --we will use this to get the number of elements in the employee NVARCHAR(80), FirstName NVARCHAR(50), LastName NVARCHAR(50) ); |
We fill this with the data from AdventureWorks
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
--steal the data from Adventureworks INSERT INTO #Staff (OrganizationNode, employee, FirstName, Lastname) SELECT Coalesce(Employee.OrganizationNode, Convert(HIERARCHYID,'/')), --we convert the null into a valid hierarchy root Coalesce(Person.Title+' ','')+ Person.FirstName+' ' +Coalesce(Person.MiddleName+' ','') + Person.LastName+Coalesce(' '+Person.Suffix,'')+ '. '+ Employee.JobTitle, --we have the full name Person.FirstName, Person.LastName FROM AdventureWorks2016.HumanResources.Employee Employee INNER JOIN AdventureWorks2016.Person.Person person ON Employee.BusinessEntityID = Person.BusinessEntityID GO |
We can now create and fill our new staff table and the StaffClosure Table
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
--clear out existing version if it exists IF Object_Id('StaffClosure', 'U') IS NOT null DROP TABLE StaffClosure; GO IF Object_Id('Staff', 'U') IS NOT null DROP TABLE Staff; GO --create our staff hierarchy table CREATE TABLE Staff --these represent the nodes with whatever attributes ( Employee_ID INT IDENTITY PRIMARY key,--for inserts etc. --a real table would have more attributes employee NVARCHAR(80), FirstName NVARCHAR(40), LastName NVARCHAR(40), ); SET IDENTITY_INSERT Staff ON --so we can put existing data in the table --now stock out nodes table with our mock data INSERT INTO Staff (Employee_ID, Employee, FirstName, LastName) SELECT Employee_ID, employee, FirstName, LastName FROM #staff -- so we can add people SET IDENTITY_INSERT Staff OFF |
The Closure table has a constraint to prevent duplicate edges and to ensure that all heads and tails reference the IDs of existing staff. We’ve added a Depth attribute that isn’t strictly necessary but it’s useful. As well as the direct parent/child references (edges) between nodes, there are ancestor/descendent references (edges). Also, nodes reference themselves (reflexive closure).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE TABLE StaffClosure --where we store our edges ( ancestor INT NOT NULL, descendant INT NOT NULL, Depth INT NOT NULL --this is handy to have but not essential PRIMARY KEY (ancestor, descendant),--enforce the rules FOREIGN KEY (ancestor) REFERENCES Staff (employee_ID), FOREIGN KEY (descendant) REFERENCES Staff (employee_ID) ); INSERT INTO StaffClosure(Ancestor, Descendant, depth) SELECT Employee_ID AS Ancestor,Employee_ID AS descendent, 0 FROM #staff --add reflexive closure UNION ALL --every edge as already defined within the path of the hierarchyid. SELECT parent.Employee_ID, child.Employee_ID AS child,f.depth FROM (VALUES (1),(2),(3),(4),(5),(6),(7),(8),(10),(11),(12))f(depth) --if you are likely to have a greater depth, then add numbers!! inner join #Staff AS child ON child.ancestors >= f.depth INNER JOIN #Staff AS parent ON parent.OrganizationNode = child.OrganizationNode.GetAncestor(depth) |
That’s it. All done now. We have a hierarchy represented by a closure table that we can play with now.
Listing the Tree
Let’s start by seeing who is there and the chain of reporting in the organisation. We’ll include the whole organisation by specifying that the CEO is in the chain. Obviously. You wouldn’t hard-code the name of the CEO in a working system, but use a function to return the reporting structure of the part of the organisation you’re interested in.
Non-recursive Listing
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT STUFF(( SELECT '->' + n.FirstName+ ' '+n.LastName from Staffclosure down INNER JOIN Staffclosure up on up.descendant = down.descendant INNER JOIN Staff n on n.employee_id = up.ancestor WHERE down.ancestor = d.ancestor and down.descendant <> down.ancestor AND down.descendant=d.descendant ORDER BY up.depth desc FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '') AS [path] FROM Staffclosure d WHERE d.ancestor = ( SELECT employee_id FROM staff WHERE employee LIKE 'Ken J Sánchez. Chief Executive Officer') AND d.descendant <> d.ancestor ORDER BY path |
And we can see everyone listed with their management chain.
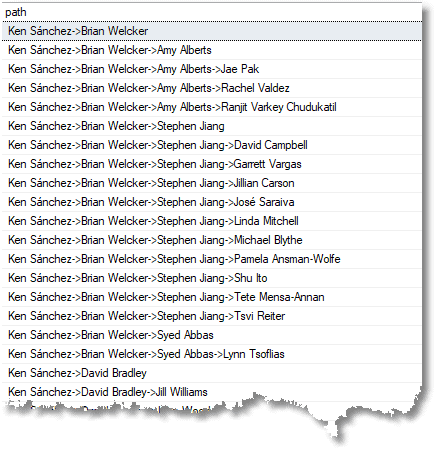
This method uses a simple aggregation to do this which relies on sorting the paths to get the order right. This was demonstrated by Bill Karwin in Rendering Trees with Closure Tables. To do this using SQL Server, we used the XML trick to emulate the group_concat() that MySQL has.
With SQL Server 2017, we now have String_agg() that is close to group_concat() but which doesn’t allow you to specify the order of concatenation of the expressions within the strings .
In this example, the ultimate boss (ancestor) was specified by hard-coding the name of the person. If this were a Table-valued function you could get the complete reporting line of any node and its descendants all the way up to the ultimate boss..
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
IF Object_Id('dbo.ReportingLine') IS NOT NULL DROP FUNCTION dbo.ReportingLine GO CREATE FUNCTION dbo.ReportingLine /** Summary: > List the reporting line for each employee ordered by the reporting path Author: Phil Factor Date: 03/04/2018 Database: PhilFactor Examples: - Select * from MyStaff cross apply dbo.Hierarchy(HeadOfDepartment) Returns: > A table indicating the reporting line as a string **/ (@employee_id INT) RETURNS TABLE --WITH ENCRYPTION|SCHEMABINDING, .. AS RETURN ( SELECT Stuff ( (SELECT '->' + n.FirstName + ' ' + n.LastName FROM dbo.StaffClosure AS down INNER JOIN dbo.StaffClosure AS up ON up.descendant = down.descendant INNER JOIN dbo.Staff AS n ON n.Employee_ID = up.ancestor WHERE down.ancestor = d.ancestor AND down.descendant <> down.ancestor AND down.descendant = d.descendant ORDER BY up.Depth DESC FOR XML PATH(''), TYPE ).value('.', 'NVARCHAR(MAX)'), 1,2,'') AS path FROM dbo.StaffClosure AS d WHERE d.ancestor = @employee_id AND d.descendant <> d.ancestor ); GO |
And here is an example of its use
|
1 2 3 4 5 6 7 |
DECLARE @Employee_ID INT = ( SELECT Staff.Employee_ID FROM dbo.Staff WHERE Staff.employee LIKE 'Mr. Brian S Welcker. Vice President of Sales' ) SELECT * FROM dbo.ReportingLine(@Employee_ID) ORDER BY ReportingLine.path |
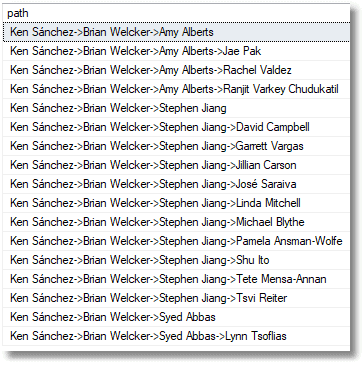
Recursive Listing
The same thing can be done using a recursive Common Table Expression (CTE), with the advantage that the natural order reflects the traversal of the nodes of the hierarchy and so you don’t need to order by the path.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
;WITH TransClosedEdges (Path, descendant, Ancestor, depth, recursion) AS (SELECT Convert(NVARCHAR(MAX), a.firstname+' '+a.lastname + ' ->' + d.firstname+' '+d.lastname), StaffClosure.descendant, StaffClosure.ancestor, depth, 1 FROM dbo.StaffClosure INNER JOIN dbo.Staff AS a ON a.Employee_ID = StaffClosure.ancestor INNER JOIN dbo.Staff AS d ON d.Employee_ID = StaffClosure.descendant WHERE StaffClosure.descendant <> StaffClosure.ancestor AND StaffClosure.ancestor = ( SELECT employee_id FROM staff WHERE employee LIKE 'Ken J Sánchez. Chief Executive Officer') AND depth = 1 UNION ALL SELECT ee.Path + ' ->' + Staff.firstname+' '+Staff.lastname, e.descendant, e.ancestor, e.depth, ee.recursion + 1 FROM dbo.StaffClosure AS e INNER JOIN TransClosedEdges AS ee ON e.ancestor = ee.descendant INNER JOIN dbo.Staff ON Staff.Employee_ID = e.descendant WHERE e.descendant <> e.ancestor AND e.depth = 1) SELECT path FROM TransClosedEdges; |
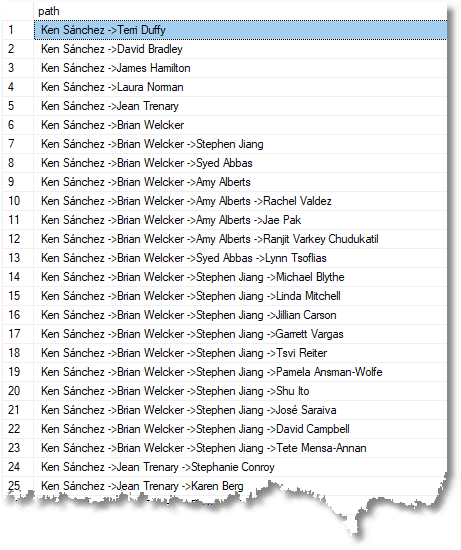
In case you wish to preserve the order of the result, you can provide a row count and then subsequently sort by that row count, by adding …
|
1 |
SELECT row_number() OVER (ORDER BY (SELECT NULL)), path FROM TransClosedEdges; |
… in the final line
Both these queries allow you report the management structure starting at whatever point you wish. The Recursive CTE was suggested by Vadim Tropashko, in his book SQL Design Patterns (Rampant Techpress, Kittrell, NC, USA, 2006.). Here is another version that is handy for a simpler indented list of the structure. This version can be easily turned into a YAML document and thence into JSON.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
;WITH TransClosedEdges (name, TheOrder, descendant, Ancestor, recursion) AS (SELECT Convert(NVARCHAR(MAX), a.employee),0, StaffClosure.descendant, StaffClosure.ancestor, 1 FROM dbo.StaffClosure INNER JOIN dbo.Staff AS a ON a.Employee_ID = StaffClosure.ancestor WHERE StaffClosure.descendant = StaffClosure.ancestor AND employee LIKE 'Ken J Sánchez. Chief Executive Officer' UNION ALL SELECT Convert(NVARCHAR(MAX), staff.employee),Convert(INT,Row_Number() OVER (ORDER BY (SELECT NULL))), e.descendant, e.Ancestor, recursion+1 FROM dbo.staffClosure AS e INNER JOIN TransClosedEdges ee ON ee.descendant=e.ancestor AND e.depth=1 INNER JOIN staff ON Staff.Employee_ID = e.descendant) SELECT space(recursion*4)+name FROM TransClosedEdges ORDER BY TheOrder; |
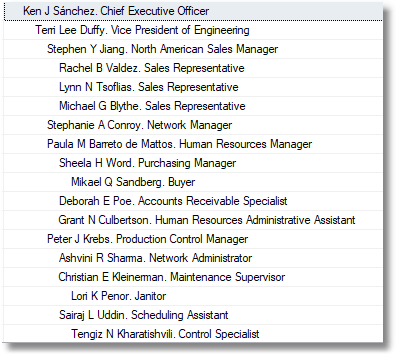
Here, I’ve used the employee’s job title too, which is handy for double-checking that everyone is reporting to the right manager!
Adding an Employee
Let’s create a new employee, Philip J Factor IIIrd.
|
1 2 3 4 |
INSERT INTO Staff ( employee, FirstName,Lastname) SELECT 'Philip J Factor IIIrd. Tool Designer','Philip','Factor' |
Now, we’d like him to report to Ovidiu V Cracium. Senior Tool Designer. We need to insert a new leaf node, including the self-referencing edge. Then we take Ovidiu V Cracium’s connections and copy them to Philip but adding 1 to the depth. Then all we need is the edge that links Ovidiu to Philip.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
DECLARE @boss INT = ( SELECT Staff.Employee_ID FROM dbo.Staff WHERE Staff.employee LIKE 'Ovidiu V Cracium. Senior Tool Designer' ); DECLARE @Report INT = ( SELECT Staff.Employee_ID FROM dbo.Staff WHERE Staff.employee LIKE 'Philip J Factor IIIrd. Tool Designer' ); INSERT INTO dbo.StaffClosure (ancestor, descendant, depth) VALUES (@Report, @Report, 0), (@boss, @Report, 1); INSERT INTO dbo.StaffClosure (ancestor, descendant, depth) SELECT ancestor, @Report, depth + 1 FROM dbo.StaffClosure WHERE StaffClosure.descendant = @boss AND ancestor <> descendant; |
Now we can check that he is there OK (Normally, you’d turn this code into a function but I’ve unwrapped it, so you can see the cogs move)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
;WITH TransClosedEdges (name, TheOrder, descendant, Ancestor, recursion) AS (SELECT Convert(NVARCHAR(MAX), a.employee),0, StaffClosure.descendant, StaffClosure.ancestor, 1 FROM dbo.StaffClosure INNER JOIN dbo.Staff AS a ON a.Employee_ID = StaffClosure.ancestor WHERE StaffClosure.descendant = StaffClosure.ancestor AND employee LIKE 'Ovidiu V Cracium. Senior Tool Designer' UNION ALL SELECT Convert(NVARCHAR(MAX), staff.employee),Convert(INT,Row_Number() OVER (ORDER BY (SELECT NULL))), e.descendant, e.Ancestor, recursion+1 FROM dbo.staffClosure AS e INNER JOIN TransClosedEdges ee ON ee.descendant=e.ancestor AND e.depth=1 INNER JOIN staff ON Staff.Employee_ID = e.descendant) SELECT space(recursion*4) + name FROM TransClosedEdges ORDER BY TheOrder; |
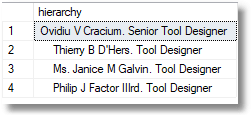
We can also use our table-valued function to check the reporting line
|
1 2 3 4 5 6 7 |
DECLARE @Employee_ID INT = ( SELECT Staff.Employee_ID FROM dbo.Staff WHERE Staff.employee LIKE 'Ovidiu V Cracium. Senior Tool Designer' ) SELECT * FROM dbo.ReportingLine(@Employee_ID) ORDER BY ReportingLine.path |
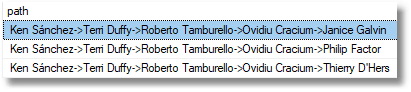
Record That an Employee Has Left
Now let’s imagine that Roberto Tamburello, the Engineering Manager, has left the company. We can’t just delete him from the staff. First, we need to decide who his team should now report to. Terri Lee Duffy, Vice President of Engineering, isn’t doing that much, so let’s transfer Roberto’s team to him. In a sense, it is a bit of a promotion for the team because they report directly to a manager who is higher up in the pecking order. Depths will be affected, and so on. Our routine needs to be robust enough to transfer the leaderless team anywhere else in the organization: not just up and down the same branch.
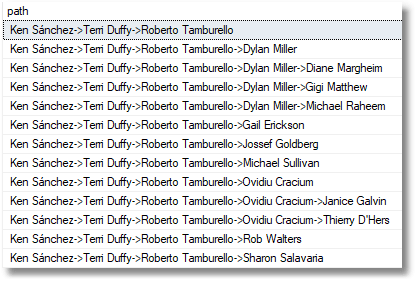
Here is the reporting line for Terri Duffy before we do anything
First, we get the IDs of the participants
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
DECLARE @AddToReports INT = ( SELECT Staff.Employee_ID FROM dbo.Staff WHERE Staff.employee LIKE 'Terri Lee Duffy. Vice President of Engineering' ); DECLARE @remove INT = ( SELECT Staff.Employee_ID FROM dbo.Staff WHERE Staff.employee LIKE 'Roberto Tamburello. Engineering Manager' ); /* create a table that contains the altered branch */ DECLARE @BranchClosure TABLE (ancestor INT NOT NULL, descendant INT NOT NULL, Depth INT NOT NULL) INSERT INTO @BranchClosure (ancestor, descendant, Depth) --GET the relationships of the reports to @remove -- up to the level of the removal of the node, but at the new depth SELECT StaffClosure.ancestor, StaffClosure.descendant, StaffClosure.Depth-- the existing depth FROM dbo.StaffClosure WHERE StaffClosure.ancestor = @remove AND StaffClosure.Depth > 0 UNION ALL --get the interrelationships of the reports within the branch SELECT StaffClosure.ancestor, StaffClosure.descendant, StaffClosure.Depth --these stay at the existing depth FROM dbo.StaffClosure WHERE StaffClosure.ancestor IN ( SELECT descendant --the existing depth FROM dbo.StaffClosure WHERE ancestor = @remove AND Depth > 0 ) UNION ALL --the relationships above the new boss SELECT f.ancestor, g.descendant, g.Depth + f.Depth AS depth FROM (---all the new relationships from the branch to the new part of the tree SELECT StaffClosure.ancestor, StaffClosure.descendant, StaffClosure.Depth FROM dbo.StaffClosure WHERE StaffClosure.descendant = @AddToReports AND StaffClosure.Depth > 0 ) AS f CROSS JOIN --for every leaf in the branch we give them the edge to the trunk ( SELECT StaffClosure.descendant, StaffClosure.Depth --the existing depth FROM dbo.StaffClosure WHERE StaffClosure.ancestor = @remove AND StaffClosure.Depth > 0 ) AS g BEGIN TRANSACTION /* delete any existing versions of the relationships */ DELETE FROM dbo.StaffClosure FROM dbo.StaffClosure AS sc INNER JOIN @BranchClosure AS BC ON BC.descendant = sc.descendant /* first update the old manager to the new*/ UPDATE @BranchClosure SET [@BranchClosure].ancestor = @AddToReports WHERE [@BranchClosure].ancestor = @remove /* and insert the new relationships */ INSERT INTO dbo.StaffClosure (ancestor, descendant, Depth) SELECT [@BranchClosure].ancestor, [@BranchClosure].descendant, [@BranchClosure].Depth FROM @BranchClosure /* mop up any residual */ DELETE FROM dbo.StaffClosure WHERE StaffClosure.ancestor = @remove OR StaffClosure.descendant = @remove; COMMIT TRANSACTION; |
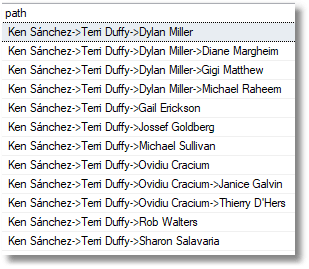
Now here is Terri Duffy’s team
General Reporting
These tend to be very simple to do, owing to the comprehensive way that the edges are placed in the closure table.
How many direct reports does ‘Stephen Y Jiang. North American Sales Manager’ have?
|
1 2 3 4 5 6 7 |
SELECT count(*) FROM Staffclosure d INNER JOIN staff dstaff ON d.descendant=dstaff.employee_id INNER JOIN staff boss ON d.ancestor= boss.employee_ID WHERE boss.employee = 'Stephen Y Jiang. North American Sales Manager' and d.descendant <> d.ancestor AND depth=1 |
How many indirect reports does ‘Ken J Sánchez. Chief Executive Officer’ have?
|
1 2 3 4 5 6 7 |
SELECT Count(*) FROM Staffclosure d INNER JOIN staff dstaff ON d.descendant=dstaff.employee_id INNER JOIN staff boss ON d.ancestor= boss.employee_ID WHERE boss.employee = 'Ken J Sánchez. Chief Executive Officer' and d.descendant <> d.ancestor AND depth<>1 |
Which of AdventureWorks staff have the most direct reports?
|
1 2 3 4 5 6 7 8 |
SELECT TOP 100 boss.employee, Count(*) FROM Staffclosure d INNER JOIN staff dstaff ON d.descendant=dstaff.employee_id INNER JOIN staff boss ON d.ancestor= boss.employee_ID and d.descendant <> d.ancestor AND depth=1 GROUP BY boss.employee ORDER BY Count(*) desc |
Using Recursive Queries
There is an occasional need for a recursive function. Getting a JSON document for an organisation hierarchy is an example of where it is handy.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
IF Object_Id('dbo.JSONStaffReportingTo', 'FN') IS NOT null DROP FUNCTION dbo.JSONStaffReportingTo; GO CREATE FUNCTION JSONStaffReportingTo (@Ancestor INT) RETURNS NVARCHAR(MAX) BEGIN RETURN (SELECT Coalesce( (SELECT '{"' + String_Escape(Staff.employee, 'json') + '": [' + Stuff( --get a list of reports (SELECT ',' + dbo.JSONStaffReportingTo(StaffClosure.descendant) FROM dbo.StaffClosure WHERE @Ancestor = StaffClosure.ancestor AND depth = 1 FOR XML PATH(''), TYPE).value('.', 'varchar(max)'),1,1,'') + ']}'), '"' + String_Escape(Staff.employee, 'json') + '"' )AS reports FROM dbo.Staff WHERE Staff.Employee_ID = @Ancestor ); END; GO SELECT dbo.JSONStaffReportingTo(Staff.Employee_ID) FROM dbo.Staff WHERE Staff.employee LIKE 'Stephen Y Jiang. North American Sales Manager'; |
Which gives (after formatting) …
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "Stephen Y Jiang. North American Sales Manager":[ "Michael G Blythe. Sales Representative", "Linda C Mitchell. Sales Representative", "Jillian Carson. Sales Representative", "Garrett R Vargas. Sales Representative", "Tsvi Michael Reiter. Sales Representative", "Pamela O Ansman-Wolfe. Sales Representative", "Shu K Ito. Sales Representative", "José Edvaldo Saraiva. Sales Representative", "David R Campbell. Sales Representative", "Mr. Tete A Mensa-Annan. Sales Representative" ] } |
Read also: Window functions for hierarchical queries
Extending the Model
The whole point of the closure pattern is that we can give the edges other attributes. We’ve actually done this in the previous example with the depth attribute. We’ll add another, the time the edge started and ended.
Imagine we have a playground with some children. Fortunately, they all have different names, so we can use the name as a primary key to make life simpler.
|
1 2 3 4 5 |
CREATE TABLE Participants (name NVARCHAR(10) PRIMARY KEY) INSERT INTO Participants (name) VALUES ('Mary'), ('Atilla'), ('Gengis'), ('Catherine'), ('Vlad'), ('lucrezia'), ('Nell'), ('Adolf') |
We now create the closure table
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE TeamClosure --where we store our edges ( ancestor NVARCHAR(10) NOT NULL, descendant NVARCHAR(10) NOT NULL, Depth INT NOT NULL, --this is handy to have but not essential StartTime DATETIME NOT NULL, FinishTime DATETIME null, PRIMARY KEY (ancestor, descendant),--enforce the rules FOREIGN KEY (ancestor) REFERENCES Participants (name), FOREIGN KEY (descendant) REFERENCES Participants (name) ); |
We can now simply add the reflexive closure
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
INSERT INTO TeamClosure(Ancestor, Descendant, depth, StartTime) SELECT name AS Ancestor,name AS descendent, 0, '4/4/2018 12:00'FROM Participants This time, we add the entire story into the closure table INSERT INTO TeamClosure(Ancestor, Descendant, depth, StartTime) values ('Lucrezia','Mary',1, '4/4/2018 12:20'), --first Mary joined Lucrezia's gang ('Lucrezia','Atilla',1, '4/4/2018 12:22'), --two minutes later came Atilla ('Lucrezia','Vlad',1, '4/4/2018 12:30'), --eight minutes later came Vlad ('Lucrezia','Adolf',1, '4/4/2018 12:30'), --along with Adolf --then Gengis and Nell joined Adolf’s subteam, Gengis, then nell ('Lucrezia','Gengis',2,'4/4/2018 12:40'), -- it's Lucrezia's gang ('Adolf','Gengis',1,'4/4/2018 12:40'), -- but he is with Adolf's group ('Lucrezia','Nell',2,'4/4/2018 12:42'), -- it's Lucrezia's gang for her too ('Adolf','Nell',1,'4/4/2018 12:42'), -- but she is with Adolf's group --then Catherine joined Vlad’s subteam ('Lucrezia','Catherine',2,'4/4/2018 12:45'), -- it's Lucrezia's gang ('Vlad','Catherine',1,'4/4/2018 12:48') -- but she is with Vlad's group UPDATE TeamClosure SET TeamClosure.FinishTime = '4/4/2018 13:40' WHERE TeamClosure.descendant = 'Nell' --then Nell goes UPDATE TeamClosure SET TeamClosure.FinishTime = '4/4/2018 13:52' WHERE TeamClosure.descendant = 'Gengis' --then Gengis goes |
We can now display the organization tree at any time.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
IF Object_Id('dbo.GangStructure') IS NOT NULL DROP FUNCTION dbo.GangStructure GO CREATE FUNCTION dbo.GangStructure /** Summary: > Show the reporting chain of lucrezia's gang at any time Author: Phil Factor Date: 04/04/2018 Database: PhilFactor Examples: - Select * from dbo.GangStructure('4/4/2018 12:42') Returns: > A table showing the gang structure **/ (@ThePointInTime DATETIME) RETURNS TABLE --WITH ENCRYPTION|SCHEMABINDING, .. AS RETURN ( WITH TransClosedEdges (Path, Ancestor, descendant, depth, recursion) AS (SELECT Convert(NVARCHAR(MAX),TeamClosure.ancestor + '->' + TeamClosure.descendant), TeamClosure.ancestor, TeamClosure.descendant, TeamClosure.Depth, 1 FROM dbo.TeamClosure WHERE TeamClosure.descendant <> TeamClosure.ancestor AND TeamClosure.ancestor = 'Lucrezia' AND TeamClosure.Depth = 1 AND @ThePointInTime BETWEEN TeamClosure.StartTime AND Coalesce(TeamClosure.FinishTime,GetDate()) UNION ALL SELECT ee.Path + '->' + e.descendant, e.ancestor, e.descendant, e.Depth, ee.recursion + 1 FROM dbo.TeamClosure AS e INNER JOIN TransClosedEdges AS ee ON e.ancestor = ee.descendant WHERE e.descendant <> e.ancestor AND e.Depth = 1 AND @ThePointInTime BETWEEN e.StartTime AND Coalesce(e.FinishTime,GetDate())) SELECT TransClosedEdges.Path FROM TransClosedEdges ) GO Select * from dbo.GangStructure('4/4/2018 12:30') |
This is at the point that Adolf, Atilla, Mary and Vlad had joined the gang but Gengis and Neil hadn’t appeared

|
1 |
Select * from dbo.GangStructure('4/4/2018 12:42') |
Now Neil and Gengis have joined Adolf’s faction
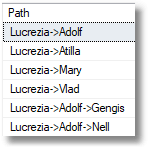
|
1 |
Select * from dbo.GangStructure('4/4/2018 13:00') |
Catherine has turned up to be Vlad’s sidekick
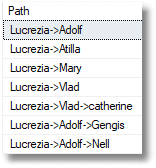
|
1 |
Select * from dbo.GangStructure('4/4/2018 14:00') |
Now Neil and Gengis have both flounced off indoors
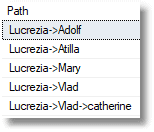
OK, at this stage it looks like overkill, but this system is capable of a great deal of elaboration at little cost.
Conclusions
There are two main points about hierarchies and trees for representing such data as parts lists, organizations or routes.
- The first is that the record of the relationships should be held separately from the entities that have the relationships. They are different entities with different attributes. Even with the simplest of hierarchies, such as a file system, the files are different than directories. In staff hierarchies, staff members don’t cease to exist the moment they no longer report to a manager, and organizational structures change unceasingly.
- The second point is that once one gets over the idea that one must pack everything into one table, other ways of doing hierarchies beyond Adjacency lists, Nested Sets or Path Enumerations become attractive. There is no single Closure Table pattern. I’ve seen several, but they make a type of storage that before now seemed slightly scary to the traditional relational database developer, seem much more natural.
I think that the two points should be considered separately. Different applications require different patterns, and Adjacency Lists, Nested Sets and Path Enumerations all have their uses. There are certain applications where the nature of the edges is irrelevant, so it is perfectly fine in that case to hold them in the one relational table. We just don’t have to do it that way.
Fast, reliable and consistent SQL Server development…
FAQs: Closure tables in SQL Server
1. What is a closure table in SQL?
A closure table stores every path in a hierarchy as a separate row, with columns for ancestor, descendant, and path length. For a hierarchy A → B → C → D, the closure table contains: A→A, A→B, A→C, A→D, B→B, B→C, B→D, C→C, C→D, D→D. “Find all descendants of A” becomes WHERE ancestor = ‘A’ – no recursion needed.
2. How does a closure table compare to adjacency lists and nested sets?
Adjacency lists (parent_id) are simple but require recursive CTEs for subtrees. Nested sets use left/right values for fast reads but expensive inserts. Closure tables balance both: fast subtree queries, moderate insert cost, and natural support for edge attributes (dates, relationship types). Trade-off: more storage than adjacency lists.
3. Should you use closure tables or SQL Server graph databases?
SQL Server 2017+ Graph uses native MATCH syntax and graph query optimization. Use graph for pattern matching and variable-length traversals. Use closure tables for standard SQL compatibility, temporal tracking of changes, or pre-2017 SQL Server versions.






Load comments