
Database Normal Forms are a sequence of progressive design rules that prevent data anomalies (insert anomalies, update anomalies, deletion anomalies) by eliminating specific kinds of redundancy.
First Normal Form (1NF) requires atomic column values and no repeating groups. Second Normal Form (2NF) requires every non-key column to depend on the whole key, not just part of it (relevant only for composite keys).
Third Normal Form (3NF) requires every non-key column to depend only on the key, not on other non-key columns.
Boyce-Codd Normal Form (BCNF) strengthens 3NF to require every non-trivial functional dependency to have a superkey on the left side.
Fourth Normal Form (4NF) eliminates multi-valued dependencies.
Fifth Normal Form (5NF) eliminates join dependencies.
Domain-Key Normal Form (DKNF) is the theoretical ideal where all constraints are expressible as domain constraints and key constraints.
Most production schemas target 3NF or BCNF; higher forms are rare outside specialised cases. The article covers each form with a worked example showing the anomaly it prevents.
Everyone gives lip service to normalized databases. But the truth is that normalization is a lot more complicated than most people know. First of all, I’ll bet almost no one reading this article (including me!) could name and define all of the current Normal Forms. Thankfully, you don’t really need all of the complexity that is possible. Let’s back up a step and ask, “why do you want to normalize database?” as opposed to just using a plain old file system.
The original Normal Forms were created by Dr. Codd in 1970. He borrowed this term because at the time, we were trying to “normalize relations” with the Soviet Union when it still existed.
Even before RDBMS, we had network and hierarchical databases. Their first goal was to remove redundancy. We want to store one fact, one way, one place, and one time. Normalization goes a step further. The goal of normalization is to prevent anomalies in the data. An anomaly could be an insertion anomaly, update anomaly, or deletion anomaly. This means that doing one of those basic operations destroys a fact or creates a falsehood.
Normal Forms
Let’s just start off with a list of the current Normal Forms defined in the literature. Some of them are obscure, and you probably won’t ever run into them, but they’re nice to know.
0NF: Unnormalized Form
1NF: First Normal Form
2NF: Second Normal Form
3NF: Third Normal Form
EKNF: Elementary Key Normal Form
BCNF: Boyce–Codd Normal Form
4NF: Fourth Normal Form
ETNF: Essential Tuple Normal Form
5NF: Fifth Normal Form
DKNF: Domain-Key Normal Form
6NF: Sixth Normal Form
I’m not going to discuss all of these normal forms, nor am I going to go into a lot of detail. I just want you to be aware of them.
First Normal Form (1NF)
Zero or Un-Normal Form is just in the list for completeness and to get a starting point. Normal Forms are built on top of each other. The idea is that if a table is in (n)th Normal Form, then it’s automatically also in (n-1)th Normal Form. The convention is that we begin with the First Normal Form. What’s remarkable is that people don’t get this right after all these decades. There are three properties a table must have to be in 1NF.
1) The table needs a PRIMARY KEY, so there are no duplicate rows. Here’s where we get into problems. By definition, a key is a minimal subset of columns that uniquely identifies each row. If it has too many columns, the subset is called a super key. Later, we realized that the key is a key, and there’s nothing special about a PRIMARY KEY, but that term (and SQL syntax) have become part of the literature because that’s how sequential files had to be organized before RDBMS. Sequential files can be sorted only one way, and each position referenced in that sorted order only one way. Tape files and punch card data processing depended on sorted order, and we spent a lot of time physically doing that sorting. This is just how we thought of processing data before we had random-access, good hashing and other tricks for data retrieval.
There’s also nothing to stop the table from having more than one key or keys with multiple columns. In a file system, each file is pretty much unrelated to any other file, but in a relational model, the tables are not standalone but have relationships among themselves.
Programmers learning RDBMS forget that a key must be made up of values taken from columns in the rows of the table. This means we do not use things like the IDENTITY table property or a physical disk location as a key. It’s clearly not an attribute of the entities being modeled by the table, but something that comes from a physical storage method.
2) No repeating groups are allowed. A repeating group is a subset of columns that store an array record structure or some other “non-flat” data structure. For example, FORTRAN and other procedural languages have arrays. COBOL, Pascal and PL/1 allow one record to contain multiple occurrences of the same kind of data. In COBOL, there’s a keyword OCCURS <n> TIMES that marks a repeated structure. The C family uses struct {..} for records and square brackets for arrays.
In the old days, we referred to files whose records all had the same simple structure as a flat file. Older programmers sometimes think that SQL was based on a flat file, and they did not have to unlearn the techniques they had in their toolbox already. Wrong. Flat files had no constraints or interrelationships, while tables do. Anytime you see someone writing SQL where there are no REFERENCES, CHECK() or DEFAULT clauses in their DDL, they probably learned to program on old flat file systems.
3) All of the values stored in the columns of a row are atomic. This means I cannot take them apart without destroying some of the meaning. In SQL, there is a big difference between a field and a column. Read the ANSI/ISO Standards; the term field refers to part of a column which can be used by itself. For example, a date column is made up of three fields: year, month, and day. In order to get a date, you have to have all three fields, but you can still get information from each field.
Consider a requirement to maintain data about class schedules at a school. We are required to keep the (course_name, class_section, dept_name, class_time, room_nbr, professor_name, student_id, student_major, student_grade) as a record. Let’s build a file first. I’m going to use Pascal because even if you’ve never written in it, you can almost immediately read it. The only things you need to know when you’re reading it is that:
1) ARRAY [i:j] OF <data type> declares an array with explicit upper and lower bounds and its data type. In particular, ARRAY [1:n] OF CHAR is how they represent a string of characters.
2) The RECORD..END construct marks a record.
3) You can nest them to create an array of records, a record with arrays, etc.
Here’s a possible declaration of a student classes file in Pascal:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Classes = RECORD course_name: ARRAY [1:7] OF CHAR; class_section: CHAR; class_time_period: INTEGER; room_nbr: INTEGER; room_size: INTEGER; professor_name: ARRAY [1:25] OF CHAR; dept_name: ARRAY [1:10] OF CHAR; students: ARRAY [1:class_size] OF RECORD student_id ARRAY [1:5] OF CHAR; student_major ARRAY [1:10] OF CHAR; student_grade CHAR; END; END; |
This table is not yet in First Normal Form (1NF). The Pascal file could be “flattened out” into SQL to look like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TABLE Classes (course_name CHAR(7) NOT NULL, class_section CHAR(1) NOT NULL, class_time_period INTEGER NOT NULL, room_nbr INTEGER NOT NULL, room_size INTEGER NOT NULL, professor_name CHAR(25) NOT NULL, dept_name CHAR(10) NOT NULL, student_id CHAR(5) NOT NULL, student_major CHAR(10) NOT NULL, student_grade CHAR(1) NOT NULL, PRIMARY KEY (course_name, class_section, student_id)); |
This table is acceptable to SQL. In fact, we can locate a row in the table with a combination of (course_name, class_section, student_id), so we have a key. But what we are doing is hiding the original Students record array, which has not changed its nature by being flattened.
There are problems.
If Professor ‘Jones’ of the Mathematics department dies, we delete all his rows from the Classes table. This also deletes the information that all his students were taking a Mathematics class and maybe not all of them wanted to drop out of school just yet. I am deleting more than one fact from the database. This is called a deletion anomaly.
If student ‘Wilson’ decides to change one of his Mathematics classes, formerly taught by Professor ‘Jones’, to English, we will show Professor ‘Jones’ as an instructor in both the Mathematics and the English departments. I could not change a simple fact by itself. This creates false information and is called an update anomaly.
If the school decides to start a new department, which has no students yet, we cannot put in the data about the professor_name we just hired until we have classroom and student data to fill out a row. I cannot insert a simple fact by itself. This is called an insertion anomaly.
There are more problems in this table, but you see the point. Yes, there are some ways to get around these problems without changing the tables. We could permit NULLs in the table. We could write triggers to check the table for false data. These are tricks that will only get worse as the data and the relationships become more complex. The solution is to break the table up into other tables, each of which represents one relationship or simple fact.
Second Normal Form (2NF)
Dr. Codd also introduced some mathematical notation for discussing relational theory. A single headed arrow can be read as determines, a key type of relationship. A double-headed arrow says the left-hand expression determines a subset of the right-hand expression. A “bowtie” is a symbol for doing a join on the left and right expressions. Let’s not worry about the bowtie for now, but you might want to remember that this was the original symbol in ANSI X3 flowchart symbols for a file merge.
A table is in Second Normal Form (2NF) if it is in 1NF and has no partial key dependencies. That is, if X and Y are columns and X is a key, then for any Z that is a proper subset of X, it cannot be the case that Z → Y. Informally, the table is in 1NF and it has a key that determines all non-key attributes in the table.
In the Pascal example, our users tell us that knowing the student_ID and course_name is sufficient to determine the class_section (since students cannot sign up for more than one class_section of the same course_name) and the student_grade. This is the same as saying that (student_id, course_name) → (class_section, student_grade).
After more analysis, we also discover from our users that (student_id → student_major) assuming that students have only one major. Since student_id is part of the (student_id, course_name) key, we have a partial key dependency! This leads us to the following decomposition:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
CREATE TABLE Classes (course_name CHAR(7) NOT NULL, class_section CHAR(1) NOT NULL, class_time_period INTEGER NOT NULL, room_nbr INTEGER NOT NULL, room_size INTEGER NOT NULL, professor_name CHAR(25) NOT NULL, PRIMARY KEY (course_name, class_section)); CREATE TABLE Enrollment (student_id CHAR(5) NOT NULL REFERENCES Students (student_id), course_name CHAR(7) NOT NULL, class_section CHAR(1) NOT NULL, student_grade CHAR(1) NOT NULL, PRIMARY KEY (student_id, course_name)); CREATE TABLE Students (student_id CHAR(5) NOT NULL PRIMARY KEY, student_major CHAR(10) NOT NULL); |
At this point, we are in 2NF. Every attribute depends on the entire key in its table. Now if a student changes majors, it can be done in one place. Furthermore, a student cannot sign up for different sections of the same class, because we have changed the key of Enrollment. Unfortunately, we still have problems.
Notice that while room_size depends on the entire key of Classes, it also depends on room_nbr. If the room_nbr is changed for a course_name and class_section, we may also have to change the room_size, and if the room_nbr is modified (we knock down a wall), we may have to change room_size in several rows in Classes for that room_nbr.
Third Normal Form (3NF)
The next Normal Form can address these problems. A table is in Third Normal Form (3NF) if it is in 2NF, and all the non-key columns are determined by “the key, the whole key, and nothing but the key. So help you, Codd.” This cute little slogan is due to Chris Date, not me.
The usual way that 3NF is explained is that there are no transitive dependencies, but this is not quite right. A transitive dependency is a situation where we have a table with columns (A, B, C) and (A → B) and (B → C), so we know that (A → C). In our case, the situation is that (course_name, class_section) → room_nbr and room_nbr → room_size. This is not a simple transitive dependency, since only part of a key is involved, but the principle still holds. To get our example into 3NF and fix the problem with the room_size column, we make the following decomposition:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE TABLE Rooms (room_nbr INTEGER NOT NULL PRIMARY KEY, room_size INTEGER NOT NULL); CREATE TABLE Students (student_id CHAR(5) NOT NULL PRIMARY KEY, student_major CHAR(10) NOT NULL); CREATE TABLE Classes (course_name CHAR(7) NOT NULL, class_section CHAR(1) NOT NULL, PRIMARY KEY (course_name, class_section), class_time_period INTEGER NOT NULL, room_nbr INTEGER NOT NULL REFERENCES Rooms(room_nbr)); CREATE TABLE Enrollment (student_id CHAR(5) NOT NULL REFERENCES Students(student_id), course_name CHAR(7) NOT NULL, PRIMARY KEY (student_id, course_name), class_section CHAR(1) NOT NULL, FOREIGN KEY (course_name, class_section) REFERENCES Classes(course_name, class_section), student_grade CHAR(1) NOT NULL); |
A common misunderstanding about relational theory is that 3NF tables have no transitive dependencies. As indicated above, if X → Y, X does not have to be a key if Y is part of a key. We still have a transitive dependency in the example — (room_nbr, class_time_period) → (course_name, class_section) — but since the right side of the dependency is a key, it is technically in 3NF. The unreasonable behavior that this table structure still has is that several course_names can be assigned to the same room_nbr at the same class_time.
Another form of transitive dependency is a computed column. For example:
|
1 2 3 4 5 6 7 |
CREATE TABLE Boxes (width INTEGER NOT NULL, length INTEGER NOT NULL, height INTEGER NOT NULL, volume INTEGER NOT NULL CHECK (width * length * height = volume), PRIMARY KEY (width, length, height)); |
The volume column is determined by the other three columns, so any change to one of the three columns will require a change to the volume column. You can use a computed column in this example which would look like:
(volume INTEGER COMPUTED AS (width * length * height) PERSISTENT)
Elementary Key Normal Form (EKNF)
Elementary Key Normal Form (EKNF) is a subtle enhancement on 3NF. By definition, EKNF tables are also in 3NF. This happens when there is more than one unique composite key and they overlap. Such cases can cause redundant information in the overlapping column(s). For example, in the following table, let’s assume that a course code is also a unique identifier for a given subject in the following table:
|
1 2 3 4 5 6 7 |
CREATE TABLE Enrollment (student_id CHAR(5) NOT NULL, course_code CHAR(6) NOT NULL, course_name VARCHAR(15) NOT NULL, PRIMARY KEY (student_id, course_name), UNIQUE (student_id, course_code) --- alternative key ); |

This table, although it is in 3NF, violates EKNF. The PRIMARY KEY of the above table is the combination of (student_id, course_name). However, we can also see an alternate key (student_id, course_code) as well. The above schema could result in update and deletion anomalies because values of both course_name and course_code tend to be repeated for a given subject.
The following schema is a decomposition of the above table in order to satisfy EKNF:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE Subjects (course_code CHAR(6) NOT NULL PRIMARY KEY, course_name VARCHAR(15) NOT NULL); CREATE TABLE Enrollment (student_id CHAR(5) NOT NULL REFERENCES Students(student_id), course_code CHAR(6) NOT NULL REFERENCES Subjects(course_code), PRIMARY KEY (student_id, course_code)); |
For reasons that will become obvious in the following section, ensuring a table is in EKNF is usually skipped, as most designers will move directly on to Boyce-Codd Normal Form after ensuring that a schema is in 3NF. Thus, EKNF is included here only for reasons of historical accuracy and completeness.
Before you think that no one would design a data model with multiple keys, I have a story. Many years ago, a taxicab company in a major city identified its vehicles four ways; by the state issued license tag, a city issued taxi medallion number, a company issued vehicle number and the VIN. Taxi medallions were very valuable because the city limits the number of them issued. By rotating the paperwork, medallions and the physical fenders (Checker cab fenders unbolt easily, and they had the internal vehicle number) among the vehicles, the company was able share the medallions. The fraud was discovered when a taxicab was involved in an accident and it had different company vehicle numbers on the fenders, the medallion didn’t match the license plate, and there are some other irregularities. This was an example of how a man with a dozen wristwatches is never quite sure exactly what time it is.
Boyce-Codd Normal Form (BCNF)
A table is in BCNF when for all nontrivial Functional Dependencies (X → A), X is a superkey for the whole schema. A superkey is a unique set of columns that identify each row in a table, but you can remove some columns from it and it will still be a key. Informally, a superkey is carrying extra weight.
BCNF is the Normal Form that actually removes all transitive dependencies. A table is in BCNF if for all (X → Y), X is a key — period. We can go to this Normal Form just by adding another key with UNIQUE (room_nbr, class_time_period) constraint clause to the table Classes.
Third Normal Form was concerned with the relationship between key and non-key columns. However, a column can often play both roles. Consider a table for computing each salesman’s bonus gifts that has for each salesman his base salary, the number of gift points he has won in a contest, and the bonus gift awarded for that combination of salary_range and gift_points. For example, we might give a fountain pen to a beginning salesman with a base pay rate between $15,000.00 and $20,000.00 and 100 gift_points, but give a car to a master salesman, whose salary is between $30,000.00 and $60,000.00 and who has 200 gift_points. The functional dependencies are, therefore,
(pay_step, gift_points) → gift_name
gift_name → gift_points
Let’s start with a table that has all the data in it and normalize it.

|
1 2 3 4 5 |
CREATE TABLE Gifts (salary_amt DECIMAL(8,2) NOT NULL gift_points INTEGER NOT NULL, PRIMARY KEY (salary_amt, gift_points), gift_name VARCHAR(10) NOT NULL); |
This schema is in 3NF, but it has problems. You cannot insert a new gift into our offerings and points unless we have a salary to go with it. If you remove any sales points, you lose information about the gifts and salaries (e.g., only people in the $30,000.00 to $32,000.00 sales range can win a car). And, finally, a change in the gifts for a particular point score would have to affect all the rows within the same pay step. This table needs to be broken apart into two tables:

|
1 2 3 4 5 |
CREATE TABLE Gifts (salary_amt DECIMAL(8,2) NOT NULL, gift_points INTEGER NOT NULL, PRIMARY KEY(salary_amt, gift_points), gift_name VARCHAR(10) NOT NULL); |

The dependencies are:
(salary_amt, gift_points) → gift
gift → gift_points
|
1 2 3 |
CREATE TABLE GiftsPoints (gift_name VARCHAR(10) NOT NULL PRIMARY KEY, gift_points INTEGER NOT NULL)); |
Fourth Normal Form (4NF)
Fourth Normal Form (4NF) makes use of multi-valued dependencies. The problem it solves is that the table has too many of them. For example, consider a table of departments, their projects, and the parts they stock. The MVD’s in the table would be:
dept_name ↠ jobs
dept_name ↠ parts
Assume that dept_name ‘d1’ works on jobs ‘j1’, and ‘j2’ with parts ‘p1’ and ‘p2’; that dept_name ‘d2’ works on jobs ‘j3’, ‘j4’, and ‘j5’ with parts ‘p2’ and ‘p4’; and that dept_name ‘d3’ works on job ‘j2’ only with parts ‘p5’ and ‘p6’. The table would look like this:

If you want to add a part to a dept_name, you must create more than one new row. Likewise, to remove a part or a job from a row can destroy information. Updating a part or job name will also require multiple rows to be changed.
The solution is to split this table into two tables, one with (dept_name, jobs) in it and one with (dept_name, parts) in it. The definition of 4NF is that we have no more than one MVD in a table. If a table is in 4NF, it is also in BCNF.
Fifth Normal Form (5NF)
Fifth Normal Form (5NF), also called the Join-Projection Normal Form or the Projection-Join Normal Form, is based on the idea of a lossless JOIN or the lack of a join-projection anomaly. This problem occurs when you have an n-way relationship, where (n > 2). A quick check for 5NF is to see if the table is in 3NF and all the keys are single columns.
As an example of the problems solved by 5NF, consider a table of mortgages that records the buyer, the seller, and the lender:

This table is a three-way relationship, but because older tools allow only binary relationships it might have to be expressed in an E-R diagram as three binary relationships, which would generate CREATE TABLE statements leading to these tables:
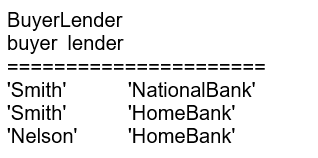
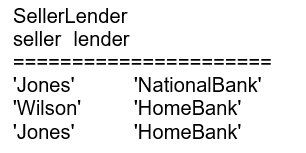

The trouble is that when you try to assemble the original information by joining pairs of these three tables together, thus:
|
1 2 3 4 5 6 7 |
SELECT BS.buyer, SL.seller, BL.lender FROM BuyerLender AS BL, SellerLender AS SL, BuyerSeller AS BS WHERE BL.buyer = BS.buyer AND BL.lender = SL.lender AND SL.seller = BS.seller; |
You will recreate all the valid rows in the original table, such as (‘Smith’, ‘Jones’, ‘National Bank’), but there will also be false rows, such as (‘Smith’, ‘Jones’, ‘Home Bank’), which were not part of the original table. This is called a join-projection anomaly.
There are also strong JPNF and over strong JPNF, which make use of JOIN dependencies (JD for short). Unfortunately, there is no systematic way to find a JPNF or 4NF schema, because the problem is known to be NP complete. This is a mathematical term that means as the number of elements in a problem increase, the effort to solve it increases so fast and requires so many resources that you cannot find a general answer.
As an aside, Third Normal Form is very popular with CASE (Computer Assisted Software Engineering) tools and most of them can generate a schema where all of the tables are in 3NF. They obtain the Functional Dependencies from an E-R (Entity-Relationship) diagram or from a statistical analysis of the existing data, then put them together into tables and check for Normal Forms.
The bad news is that it is often possible to derive more than one 3NF schema from a set of Functional Dependencies. Most of CASE tools that produce an E-R diagram will find only one of them, and go no further. However, if you use an ORM (Object Role Model) tool properly, the schema will be in 5NF. I suggest strongly that you get any of the books by Terry Halpin on this technique.
Domain-Key Normal Form (DKNF)
Ronald Fagin defined Domain/Key Normal Form (DKNF) in 1981 as a schema having all of the domain constraints and functional dependencies enforced. There is not yet a general algorithm that will always generate the DKNF solution given a set of constraints. We can, however, determine DKNF in many special cases and it is a good guide to writing DDL in the real world.
Aggregation Level Redundancy
A common example is the Invoices and Invoice_Details idiom which puts detail summary data in the order header. This is usually a column for invoice_total which has to be re-computed when an order item changes. What has happened is a confusion in levels of aggregation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TABLE Invoices (invoice_nbr CHAR(15) NOT NULL PRIMARY KEY, customer_name VARCHAR(35) NOT NULL, invoice_terms CHAR(6) NOT NULL CHECK (invoice_terms IN ('cash', 'credit', 'coupon)), invoice_amt_tot DECIMAL(12,2) NOT NULL); CREATE TABLE Invoice_Details (invoice_nbr CHAR(15) NOT NULL REFERENCES Invoices (invoice_nbr) ON DELETE CASCADE, CHECK (line_nbr > 0), item_gtin CHAR(15) NOT NULL, PRIMARY KEY (invoice_nbr, item_gtin), invoice_qty INTEGER NOT NULL CHECK (invoice_qty > 0), unit_price DECIMAL(12,2) NOT NULL) |
But did you notice that Invoices.invoice_amt_tot = SUM (Invoice_Details.invoice_qty * Invoice_Details.unit_price)?
Entire Table Redundancy
Entire tables can be redundant. This often happens when there are two different ways to identify the same entity.
|
1 2 3 4 |
CREATE TABLE Map (location_name VARCHAR(35) NOT NULL PRIMARY KEY, location_longitude DECIMAL(9,5) NOT NULL), location_latitude DECIMAL(9,5) NOT NULL); |
I can use a formula to compute the distance between two locations with this table. But I can also build a table of straight-line distances directly:
|
1 2 3 4 5 |
CREATE TABLE Paths (origin_loc CHAR(35) NOT NULL, dest_loc CHAR(35) NOT NULL, travel_dist DECIMAL(10,3) NOT NULL, PRIMARY KEY (origin_loc, dest_loc)); |
This is the ultimate redundancy. I strongly recommend you don’t put something like this in your schema because it will defeat the whole purpose of normalization.
The Moral to the Story
To reiterate, the whole purpose of normalization is to prevent anomalies. Normalization is declarative, so we don’t need procedural code for this purpose. But we do need some knowledge about relationships. I guess that’s why we call it a relational database.






Load comments