
In the Newsgroups I frequent, I find that I constantly have to remind people that rows are not records, columns are not fields and tables are not files. After teaching SQL and writing books on the language for a few decades, I have found that if a person can switch his mindset from procedural code and sequential files to declarative code and sets, then SQL and data modelling become much, much easier. It is an epiphany, much like when recursion suddenly makes sense to a procedural programmer. If you are a native LISP programmer, replace “recursion” with “iteration” in that last sentence.
“
When a business
rule is in the DDL,
it is done one way,
one place, one time
”
Part of this epiphany is realizing that DDL (Data Declaration Language), DML (Data Manipulation Language) and DCL (Data Control Language) are all an intrinsic part of SQL and not disjoint languages that stand apart. This article deals with the DDL, but better DDL makes for better DML and DCL. When a business rule is in the DDL, it is done one way, one place, one time. You do not have to hope that every application and every DML statement gets all the rules right. You do not have to hope that a change in the rules will be corrected in hundred or even thousands of places in the system.
An Overview of Constraints: DDL versus DML
Since DDL is declarative, the SQL engine can convert row and column constraints into search conditions that can be used by the optimizer, by adding them to the execution plan under the covers. It is a little trickier than it sounds because there is a subtle difference between DDL and DML logic. Let’s start with a sample table, Foobar, which has no CHECK() constraints on it, and load some sample data into it:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE Foobar (foo_nbr CHAR(5) NOT NULL PRIMARY KEY, a INTEGER, b INTEGER NOT NULL, c INTEGER NOT NULL); INSERT INTO Foobar VALUES ('Fred', NULL, 12, 10), ('Teri', 14, 12, 11), ('Mike', 3, 12, 12); |
Then run the following query:
|
1 2 3 |
SELECT foo_nbr, a, b, c FROM Foobar WHERE a < b; |
This query will return the result set: (‘Mike’, 3, 12, 12) because the WHERE clause returns UNKNOWN for (‘Fred’, NULL, 12, 10) and FALSE for (‘Teri’, 14, 12, 11). The UNKNOWN is treated as a FALSE in the DML. That should not surprise even a beginning SQL programmer. But now, let’s add a CHECK () constraint and see how the rules change.
|
1 2 3 4 5 6 7 |
DROP TABLE Foobar; CREATE TABLE Foobar (foo_nbr CHAR(5) NOT NULL PRIMARY KEY, a INTEGER, b INTEGER NOT NULL, c INTEGER NOT NULL, CHECK (a < b)); -- same search condition as query |
Now load the table with the new constraint on it:
|
1 2 3 |
INSERT INTO Foobar VALUES ('Fred', NULL, 12, 10); -- accept, UNKNOWN INSERT INTO Foobar VALUES ('Teri', 14, 12, 11); -- reject! FALSE INSERT INTO Foobar VALUES ('Mike', 3, 12, 12); -- accept, TRUE |
The CHECK () constraint clause returns UNKNOWN, as per the usual rules of SQL’s Three-Valued Logic (3VL). However, the rules for DDL are nor the rules for DML. The CHECK () constraint treats UNKNOWN and TRUE the same. Thus, the row (‘Fred’, NULL, 12, 10) can go into the table, but the query will not return it in the result set.
The reason for this is to allow the tables to hold NULLs without having to write complicated search conditions, which would be a mess of “CHECK (<some constraint on my column> OR <my column> IS NULL)“, all over the schema. It gets even worse for multi-column constraints because you would have to consider all the possible combinations of NULLs and values in that table. The idea is that if you wanted to prohibit NULLs in a column, then you would have used NOT NULL in the declaration for that column. So you get the “benefit of the doubt” when you leave it off.
NOTE:
As an aside to SQL Server programmers, there is only a NOT NULL constraint in Standard SQL and NULL is strictly dialect.
CHECK () Constraint Basics
New SQL programmers do not appreciate the fact that, in modern SQL products, the search conditions in the CHECK () clauses are passed along to the optimizer for queries, inserts, updates and deletes. They consider them to be data integrity features only. Yes, data integrity is important — nay, vital — to the RDBMS, but it is nice to get a performance bonus.
The biggest mistake is not to use all the CHECK () constraints you can put on a table. From the data integrity side, this means that all or most of the business rules are in one place. An application program or direct query tool cannot override these rules.
Another feature that is often missed by less-experienced SQL coders is that constraints can be given names. These names are global to the schema and are not at the table level. The syntax is simply:
|
1 |
"CONSTRAINT <constraint name> CHECK (<search condition>)" |
The name will appear in error messages when the constraint is violated. There two reasons that the names are global. First, local names would be confusing when you have a multi-table query or statement. Secondly, in Standard SQL, there is a CREATE ASSERTION statement that lets you put a CHECK () on the schema as a whole. If a table is empty, then all constraints are TRUE in SQL. This lets you handle empty tables, constraints that deal with multiple tables, and so forth, in one place.
A single column can have more than one CHECK () constraint on it. A more sophisticated error is to lump all of the rules into one honking long CHECK () that has a list of search conditions separated by OR‘s and a vague name like “bad foobar code” that does not give enough information to be helpful. But if each of these checks were placed in its own constraint, then the constraint names would give the end user some extra help — “foobar code too high”, “foobar code too low“, “foobar code <= 0“, or whatever. It also means that when a rule changes, only one constraint has to be altered.
If a CHECK () constraint involves one, and only one, column then it can be placed on the end of the column declaration before the comma that separates the column declarations in the CREATE TABLE statement. If a CHECK () constraint involves more than one column then it has be placed by itself, separated from the column declarations in the CREATE TABLE statement. Some people have trouble finding the missing comma in multi-column constraints since the error message in most SQL products just says something about a bad column reference and does not suggest the missing comma. Technically, all CHECK () constraints can be done with the stand-alone syntax, but the single column syntax keeps the constraint next to that column and makes “cut & paste” a bit easier. The multi-column constraints can appear anywhere in the CREATE TABLE statement, but try to put it near the columns involved.
CASE Expressions in CHECK () Constraints
The first advanced trick you can do with a CHECK () constraint is to use a CASE expression to build in complex logic. Many programmers do not think of this trick because, in their original programming language, there was a CASE statement and not a CASE expression. The CASE statement (also known as CASE in Pascal and ADA, switch in C, computed GOTO in COBOL and so forth) is a “flow of control” construct, like the IF-THEN-ELSE statement in all procedural programming languages. Declarative programming languages have no control flow by definition.
The CASE expression has two forms and it returns a value of one data type. For constraints, the searched case expression is the most useful. Here is the BNF for it:
|
1 2 3 4 5 6 7 |
<searched case> ::= CASE WHEN <when operand> THEN <result> .. [ELSE <result>] END |
The first step is to look at all the THEN clauses and ELSE to find the highest data type in them; that is the data type of the expression. It is easy to screw up by not watching that behaviour and putting something like “ELSE ‘Not found’ END” which will promote everything to a CHAR (n) data type.
The WHEN…THEN…clauses are executed in left to right order. The first WHEN clause that tests TRUE returns the value given in its THEN clause. And, yes, you can nest CASE expressions inside each other. If no explicit ELSE clause is given for the CASE expression, then the database will insert a default ELSE NULL clause. If you want to return a NULL in a THEN clause, then you must use a CAST (NULL AS <data type>) expression. I recommend always giving the ELSE clause, so that you can change it later when you find something explicit to return.
In the CHECK () constraints, you assign the results some constant value, such as ‘T’ and ‘F’ for TRUE and FALSE. This lets you do complex logic in the DDL, such as:
|
1 2 3 4 5 6 7 8 9 10 |
CONSTRAINT special_foobar_rule CHECK (CASE WHEN foobar_code = 0 AND floob_score > 10 THEN 'T' WHEN foobar_code = 1 AND spy_nbr = '007' THEN 'T' WHEN foobar_code = 2 AND arrest_cnt > 3 THEN 'T' .. ELSE 'F' END = 'T') |
The SQL Standard defines other functions in terms of the CASE expression, which makes the language a bit more compact and easier to implement. The COALESCE () expression returns the first expression in its parameter list that is not NULL and cast it as the highest data type in the parameter list. If the list is all NULLs, then the result of the expression is NULL. For example, to assure one or more of several options is given, you can use CHECK(COALESCE (option_1, option_2, option_3) IS NOT NULL).
Basic DRI Actions
Declarative Referential Integrity (DRI) uses the PRIMARY KEY or UNIQUE constraints on one table (called the referenced table) to assure that matching columns in a second table (called the referencing table) have the same values. The referenced and referencing table can be the same table, but ignore that for the sake of this discussion. For example, if we have a business rule that we do not sell things that are not in inventory, then the skeleton schema might look like this:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE Inventory (product_id CHAR(15) NOT NULL PRIMARY KEY, ..); CREATE TABLE Orders (order_nbr CHAR(15) NOT NULL PRIMARY KEY, product_id CHAR(15) NOT NULL REFERENCES Inventory (product_id) ON UPDATE CASCADE ON DELETE CASCADE, ..); |
People often have trouble with this construct because they think of a table as a file. Files are separate units of storage, while a table is a part of a schema; the schema is the unit of storage. There are also DRI action subclauses which can make changes in the referenced table to all the referencing table’s matching columns. The most common case is shown on the Orders table of this example. When an inventory item changes its product_id, then all of the references to it change to the new value — ON UPDATE CASCADE. When an inventory item is deleted, then all of the rows in the referencing tables with that product_id are also deleted — ON DELETE CASCADE.
This obviously saves a lot of programming on the application side, but it also tells the optimizer about the relationship among the tables, so it can pick a better execution plan.
DRI for Transition Constraints
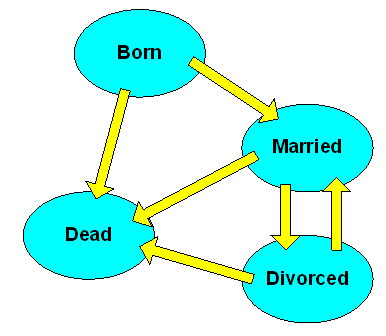
A transition constraint says that an entity can be updated only in certain ways. These constraints are often modelled as a state transition diagram. There is an initial state, flow lines that show what are the next legal states, and one or more termination states. As a very simple example, consider your marital life. Notice that we have to start with Born and you are single. It is important to have one initial state, but you can have many termination states. For example, after you are born, you can die or get married, but you have to be married to get a divorce. The state diagram is shown in on the right.
In this example, we have only one termination state, Dead. Let’s start with a table skeleton and try to be careful about the possible states of our life:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE Inventory (product_id CHAR(15) NOT NULL PRIMARY KEY, ..); CREATE TABLE Orders (order_nbr CHAR(15) NOT NULL PRIMARY KEY, product_id CHAR(15) NOT NULL REFERENCES Inventory (product_id) ON UPDATE CASCADE ON DELETE CASCADE, ..); |
We are being good programmers, using a DEFAULT and a CHECK() constraint, but this does not prevent us from turning Born directly to Dead, converting Divorced to Married, and so on. You can actually use CHECK () constraints to enforce our state diagram, but you have to store the current and previous states:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE TABLE MyLife (.. previous_state VARCHAR(10) NOT NULL, current_state VARCHAR(10) DEFAULT 'Born' NOT NULL, CHECK (CASE WHEN (previous_state = 'Born' AND current_state IN ('Married', 'Born', 'Divorced')) THEN 'T' WHEN (previous_state = 'Married' AND current_state IN ('Divorced', 'Dead')) THEN 'T' WHEN (previous_state = 'Divorced' AND current_state IN ('Married', 'Dead')) THEN 'T' ELSE 'F' END = 'T') ..); |
In effect, the state diagram is converted into a search condition. This procedure has advantages; it will pass information to the optimizer, will port, and will usually run faster than procedural code.
Another declarative way to enforce Transition Constraints is put the state transitions into a separate table and then reference the legal transitions. This requires that the target table have both the previous, and the current, state in two columns. Using this example, we would have something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
CREATE TABLE StateChanges (previous_state VARCHAR(15) NOT NULL, current_state VARCHAR(15) NOT NULL, PRIMARY KEY (previous_state, current_state)); INSERT INTO StateChanges VALUES ('Born', 'Born'), -- initial state ('Born', 'Married'), ('Born', 'Dead'), ('Married', 'Divorced'), ('Married', 'Dead'), ('Divorced', 'Married'), ('Divorced', 'Dead'), ('Dead', 'Dead'); -- terminal state |
The target table looks like this.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE MyLife (.. previous_state VARCHAR(15) DEFAULT 'Born' NOT NULL, current_state VARCHAR(15) DEFAULT 'Born' NOT NULL, FOREIGN KEY (previous_state, current_state) REFERENCES StateChanges (previous_state, current_state) ON UPDATE CASCADE, ..); |
If you want to hide this from the users, then you can use an updatable view:
|
1 2 3 4 |
CREATE VIEW MyLife (.., marital_status, ..) AS SELECT .., current_state, .. FROM; |
The immediate advantages to doing so are that this will pass information to the optimizer and will port, as with the CHECK () constraint version. However, since the rules are separated from the table declaration, you can maintain them easily.
A not-so-obvious advantage is that the StateChanges table can contain other data and conditions, such as temporal change data. Your ‘Born’ cannot change to ‘Married” until you are of legal age. You cannot go from ‘Married’ to ‘Divorced’ for (n) days and so forth.
Summary
“A problem well stated is a problem half solved.” — Charles F. Kettering
This is just a small sample of some declarative DDL techniques you can use in place of traditional procedural code. I have not gotten to UNIQUE and PRIMARY KEY constraints or CREATE ASSERTION statements yet! And, while I avoid them as much as possible, there are also many kinds of TRIGGERs that you can add to a table. Wow! Maybe there is another article waiting to be written.






Load comments