
People often say of SQL that since it’s a declarative language you don’t have to tell it how to get the data you want; you just describe the data you’re after. This is true: describe what you want and you’ll get what you asked for, but there’s no guarantee that you’ll get it at the speed or cost you were hoping. It’s a bit like getting into a taxi-cab in a strange city. You can tell the driver where you want to go and hope that he will take the best route to get you there, but sometimes the journey takes longer and costs more than you expect, unless you give the driver a few clues about the route you expect him to take.
It doesn’t matter how good the Optimizer gets, there are bound to be cases when its algorithms don’t cope well with your requirements. It may be that the available statistics are misleading, or that the Optimizer has to make some assumptions about your data that simply aren’t true. If this happens, you need to find a way to give the Optimizer some guidance.
This article describes a visual approach to designing SQL queries, especially complex queries, which should allow you to work out appropriate executions plan. As well as being a useful method for writing new queries, this approach is especially useful for “debugging” and re-engineering queries where the Optimizer is not behaving well and needs some help. The ideas are simple and essentially database neutral, even though the coding methods that get you from the plan to the SQL are likely to be database dependent.
Know your data
Before you can optimize a query, you first need to know:
- How much data you expect to handle (data volume)
- Where that data is (data scatter)
Volume and scatter are equally important when assessing how much work has to be done to return the required results, and how much time it will take. If you need to acquire a large volume of data that is scattered over a wide area of the database, your query is unlikely to operate very quickly. However, you could still manage to acquire a large volume of data very quickly if you have taken advantage of (say) a clustered index to ensure that it’s all packed it into a relatively small space. So, the first two questions you always have to address are: “How much data?” and “Where is the data?”
You then have a further problem to address: how to get to that data. Let’s say you want to pick up 50 rows from a table based on a certain condition; it sounds straightforward, but what is the most efficient way of picking up just those 50 rows? You might have a choice between:
- A “perfectly precise” index
- A reasonably precise index that identifies 100 rows of which you will have to discard 50
- A fairly “wasteful” index that identifies 500 rows of which you have to discard 450
Here’s an important idea: if you had to choose between the second and third indexes can you tell, from what I’ve written so far, which one is going to be more efficient? The correct answer to that question is “no”. Picking up just 100 rows and discarding 50 clearly sounds more efficient than picking up 500 and discarding 450, but remember: clustering, in other words the way the data is physically grouped or scattered, matters a lot.
Suppose you have one index that identifies 10 rows from each of 10 pages, with the 50 rows you require grouped in just 5 of those 10 pages and another index that identifies 100 rows from each of 5 pages. Is it better to visit 10 different pages and discard 50 rows, or visit just 5 pages but discard 450 rows? Visiting the smaller number of pages is probably the better bet.
Remember that you can understand your application and your data better than the Optimizer; sometimes the Optimizer chooses a bad execution plan because it doesn’t know the data, or how your application handles that data, as well as you do.
If a picture paints a thousand words…
…why not draw your query? If you’ve got a complex SQL statement with many tables, you have a real need to collect and present a lot of information in a way that can be easily grasped. Drawing a picture is a good idea, especially if you’re trying to debug someone else’s SQL.
My approach is simple:
- Read through the SQL statement and draw a box for each table and a line between boxes for every join condition.
- If you are aware of the cardinality of the join (one-to-one, one-to-many, many-to-many), then put a “crow’s foot” at the “many” end(s) of the line.
- If you have a filter predicate on a table, draw an arrow coming into the box and write the predicate by it.
- If a “table” is actually an in-line view, or sub-query including multiple tables, draw a light outline around the entire group of tables.
For example, say you have a schema which defines a fairly simple order-processing system: customers place orders, orders can have multiple order lines, an order line is for a product, and products come from suppliers; some products can be substituted by other products. One day you are asked to report on “orders placed over the last week by customers based in London, for products supplied by producers based in Leeds that could have been supplied from an alternative location”
Assuming we only want the details from each order for the specific product line this might turn into a query like that shown in Listing 1.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECT {list of columns} FROM customers cus INNER JOIN orders ord ON ord.id_customer = cus.id INNER JOIN order_lines orl ON orl.id_order = ord.id INNER JOIN products prd1 ON prd1.id = orl.id_product INNER JOIN suppliers sup1 ON sup1.id = prd1.id_supplier WHERE cus.location = 'LONDON' AND ord.date_placed BETWEEN dateadd(day, -7, getdate()) AND getdate() AND sup1.location = 'LEEDS' AND EXISTS ( SELECT NULL FROM alternatives alt INNER JOIN products prd2 ON prd2.id = alt.id_product_sub INNER JOIN suppliers sup2 ON sup2.id = prd2.id_supplier WHERE alt.id_product = prd1.id AND sup2.location != 'LEEDS' ) |
Listing 1: A query to retrieve alternate suppliers
It’s possible that my verbal description of the schema is not immediately visible in the SQL, but applying a visual approach leads to a picture of the query that looks as shown in Figure 1. Don’t be surprised if it takes two or three attempts to draw a clear, tidy picture, especially if you’re reverse engineering someone else’s SQL; my first drafts often end up with all the tables crammed into one corner of the page.
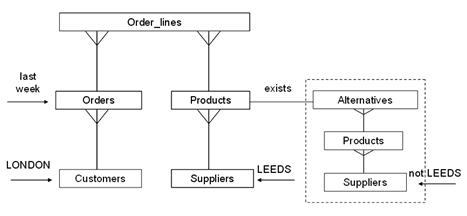
Figure 1: A first-draft picture of our query
Based on this diagram, we can start to fill in some of the numeric information that we need. The level of detail will depend on how familiar we are with all the tables involved, and how well we know the basic application. In this case, I’ll use the Orders table to demonstrate the principles of the sort information we need. Some of this information will come from the INFORMATION_SCHEMA and some may have to come from querying the data, but ideally most of it we will already know because we are familiar with how the application works and the nature of our data:
- Rows: 250,000
- Pages: 8,000
- Starting cardinality: 2,400
- Final cardinality: 20
- Current relevant indexes into Orders:
- (date_placed) very good clustering with ca. 400 rows per day
- (id_customer)very poor clustering with 10 to 150 rows per customer
- Current relevant indexes leading out of Orders:
- order_lines (id_order, line_no) very good clustering with 1 to 15 rows per order
- customers (id) primary key
Note that I would normally draw the relevant indexes as arrows between the boxes and label them with their statistics, and I would also write the table statistics into the boxes; long lists of text under the diagram aren’t helpful. However, sometimes a large piece of paper is needed to get the sketch right, and space on this web page is limited.
The “starting cardinality” and “final cardinality” need some explanation. The starting cardinality is the number of rows I expect to get from this table if this is the first table visited in the query; in other words, it’s the number of rows that match any constant predicates I have on the table. The original query is about “orders over the last week”, and I might simply know that we typically get about 2,400 orders per week. Alternatively, I might have to run a simple query, select count(*) from orders group by week, to get an estimate.
The final cardinality is the number of rows from this table that will appear in the final result set, and it can be much harder to estimate this figure without help from someone who knows the business well. In this case, our best estimates on these figures indicate a significant difference between starting and final cardinalities. This means that, at some stage, I may have to do a lot of work to get rid of the excess rows, and that “throwaway” may be the work that I need to minimize.
Having collected all the information about what’s in the tables, what we want from the tables, how we can reach it, and how much work it will take, we just have to pick a starting table in the diagram and then keep repeating the questions: Which table shall I visit nextHow will I get there? In order to answer these questions, each time, consider the four sub-questions, in loose order of precedence:
- Can I aggregate the current result set to reduce the volume (significantly) before I go to the next table?
- Is there a table I can go to next that will eliminate data (cheaply)?
- Is there a table which will only extend the row size (slightly) without increasing the row count?
- Which table increases the row count by the smallest amount (cheaply)?
If you allow these questions to bias your choice of “the next table” to visit, it will tend to keep the intermediate data volume small, and the workload low. Inevitably, there are compromises between a choice that, for example, increases row lengths dramatically (option 3) and one that increases row counts slightly (option 4), and so on. However, if you take these options as a weak, rather than rigid, guideline, and keep thinking a couple of steps ahead, you won’t go far wrong.
In a data warehouse, or DSS, you might find that you could pick virtually any table as the starting table in your analysis and work through several paths before you find the most appropriate one, but the general principle would be to pick a table that returned a small amount of data at relatively low cost.
In an OLTP system, there are more likely to be just one or two obvious places to start, assuming you have a fairly sound knowledge of the business. In this example, the obvious starting points are the Orders table and the Customers table. After all, the report is about “orders for a few customers over a short time period”, so starting at the customer/order end of the picture feels like it will provide a small starting data set. However, for the purposes of demonstration, let’s be awkward and see what happens if we pick the Suppliers table as the starting point.
From the Suppliers table (which returns only a few rows for “Leeds”), the only sensible choice is to go to the Productshi table by way of the “foreign key” index, which you can assume would be there. Of course, technically, we could go to any table, provided we didn’t feel threatened by the resulting Cartesian (cross) product.
From the Products table, we could go to the Order_lines table or the Alternatives table. The visit to the Order_lines table will result in a massive increase in the number of rows, and we’d be picking rows that were scattered across the entire length of a very large table, so we’d be using an expensive index in a nested loop join, or doing a table scan with a hash join.
On the other hand, if we go to the Alternatives table, with the expectation of following through to the Products and Suppliers table in the subquery, coming back to address the Order_lines table later, then we may find that there are lots of products that don’t have alternative suppliers, and so the number of rows could decrease, making that the better choice. This number would decrease again when we get to suppliers who were not from Leeds.
Eventually, however, we will have to revisit what’s left of the Products table and join into Order_lines, and my general knowledge of what goes into a table like Order_lines tells me that this will be a large data set, generated very inefficiently. A single product is likely to appear in a lot of order lines, scattered over a wide range of the table; not a nice prospect.
So, the only sensible options for the starting point are Orders or Customers and, after visiting those two, the sequence of tables is going to be: Order_lines, Products, Suppliers, (Alternatives, Products, Suppliers).
So, should we start Customers–Orders or Orders–Customers? This is where indexing and clustering becomes really important.
As it stands, and considering the current list of indexes that relate to the Orders table, if we pick up customers for London we then have to use the (id_customer) index into the Orders table to collect all the orders for those customers, and then discard any orders outside the one week date range. Looking back at the statistics, we have 250,000 orders and about 2,400 per week, which means our data covers a total range of two years (104 weeks). So, if we pick a customer and then pick up all the orders for that customer, we would end up discarding about 99% of the orders we collected. Given the volume of data, and the way the orders are scattered over time, this is going to do a lot of work to collect a lot of data; most of which we will then discard.
The alternative, then, is to start at the Orders table, pick up the 2,400 orders for the one week range, using the (date_placed) index, and join to the Customers table on its primary key index to discard all the customers not from London. Orders are likely to be very well clustered by time, and since recent orders are the ones that are most likely to be subject to ongoing processing they will probably be cached and stay cached. This means that even though we pick up a lot of orders to start with, we can probably do so very efficiently.
In the worst case, we may then have to visit about 2,400 customer rows and they are likely to be scattered randomly through the Customers table, so this might be a bit of a performance (I/O) threat. However, a reference table such as Customers is likely to benefit from a reasonable amount of caching when compared with a transactional table such as Orders, so that threat may be one that we are prepared to ignore. This leads us to the sketch shown in Figure 2.
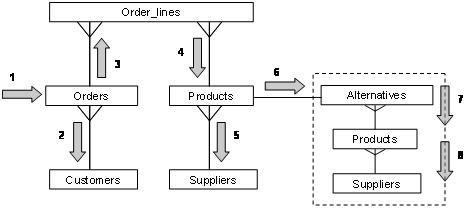
Figure 2: The order in which the tables should be accessed
Once we’ve decided that this is the appropriate path through the query, we can take steps to see that it happens, possibly through the simple expedient of re-arranging the table order in the query and applying the “force order” hint.
On the other hand, if this query is sufficiently important, and if we are early on in the design stages of the system, there are some structural features we might want to consider.
Choosing indexes
We may have created a clustered index on the Customers table, but if it’s a simple heap table with a non-clustered primary key index on customers(id), we could consider including the Location column in the index so that we can avoid visiting the table to check the location. This arrangement, i.e. a small primary key with included column, may give us much better caching than creating the table with a clustered index on the customers(id).
Alternatively, if we created an index on the Orders table, on (id_customer, date_placed) we could consider starting our query at the Customers table because we could use this new index to get very accurately into the Orders table for each customer we pick from the Customers table: This index might be quite large, though, with little caching benefit for this particular query: so maybe (date_placed, id_customer) would be better.
This brings us back to clustering, of course. There are two obvious candidates for a clustered index on Orders: date_placed and id_customer. Which, if either, should we use, or (whisper it) should we create the table as a simple heap table?
This fundamental design question should be addressed very early in the design stages of the system, of course, and depends on whether we expect to query the table by customer, by date, or (as here) by a combination of the two.
Since the data is going to arrive in date order anyway, it would naturally tend to cluster itself by date even if we used a simple heap table, so the benefit of a clustered index on date_placed is probably not going to be significant. On the other hand, data insertion would probably be much more expensive if we created a clustered index on id_customer and, unless we regularly run queries for the full history for a customer, a non-clustered index on (id_customer, date_placed) will probably give us good enough performance for queries based on individual customers.
Ultimately, of course, there is always a level of risk involved in changing the indexing strategy on a live system, and we hope that we can solve problems of badly performing SQL by addressing the code, adjusting statistics, or using hints to enforce the optimum execution plan. Drawing the right pictures makes it easier to see and understand the choices available to you, and gives you a firmer basis for making difficult decisions.
Conclusion
To write an efficient query, you need to know how much data you have to acquire and where it’s going to be. You also need to know what options you have for acquiring the data and how much effort you are going to waste visiting data that you don’t need so that you can decide the best order for visiting tables.
For complex queries the best way to design the query is to start by drawing a diagram of all the tables involved, showing the joins between the tables, indicating the volume of data involved, and describing the indexes that allow you to get from one table to the next. A diagram of this sort will make it much easier to understand the efficiency of the possible paths that your query could take through the tables.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments