
Use CHAR for fixed-length data like state codes, phone numbers, or postal codes where every value is the same length – it pads shorter values with spaces and uses consistent storage. Use VARCHAR for variable-length data like names, addresses, or descriptions where lengths vary significantly – it stores only the characters entered plus 2 bytes of overhead.
Use VARCHAR(MAX) when you need to store strings longer than 8,000 bytes (up to 2 GB), typically for large text fields, XML fragments, or JSON documents. CHAR is faster for fixed-width data; VARCHAR is more space-efficient for variable data; VARCHAR(MAX) has different storage and query plan behavior than standard VARCHAR.
Introduction
In every database, there are different kinds of data that need to be stored. Some data is strictly numeric, while other data consists of only letters or a combination of letters, numbers, and even special symbols. Whether it is just stored in memory or on disk, each piece of data requires a data type. Picking the correct data type depends on the characteristics of the data being stored. This article explains the differences between CHAR, VARCHAR, and VARCHAR(MAX) in SQL Server.
When selecting a data type for a column, you need to think about the characteristics of the data to pick the correct data type. Will each value be the same length, or will the size vary greatly between values? How often will the data change? Will the length of the column change over time? There might also be other factors, like space efficiency and performance, that might drive your decision on a data type.
The CHAR, VARCHAR, and VARCHAR(MAX) data types can store character data. This article will discuss and compare these three different character data types. The information found in this article will help you decide when it is appropriate to use each of these data types.
CHAR the fixed-length character data type
The CHAR data type is a fixed-length data type. It can store characters, numbers, and special characters in strings up to 8000 bytes in size. CHAR data types are best used for storing data that is of a consistent length. For example, two-character State codes in the United States, single-character sex codes, phone numbers, postal codes, etc. A CHAR column would not be a good choice for storing data where the length varies greatly. Columns storing things like addresses or memo fields would not be suitable for a CHAR column data type.
This doesn’t mean a CHAR column can’t contain a value that varies in size. When a CHAR column is populated with strings shorter than the length of the column, spaces will be padded to the right. The number of spaces padded is based on the size of the column less the length of characters being stored. Because CHAR columns are fully populated by adding spaces, when needed, each column uses the same amount of disk space or memory. Trailing spaces also make it a challenge when searching and using CHAR columns. More on this in a moment.
What is VARCHAR (variable-length character data type)?
VARCHAR columns, as the name implies, store variable-length data. They can store characters, numbers, and special characters just like a CHAR column and can support strings up to 8000 bytes in size. A variable-length column only takes up the space it needs to store a string of characters, with no spaces added to pad out the column. For this reason, VARCHAR columns are great for storing strings that vary greatly in size.
To support variable-length columns, the length of the data needs to be stored along with the data. Because the length needs to be calculated and used by the database engine when reading and storing variable-length columns, they are considered a little less performant than CHAR columns. However, when you consider they only use the space they need, the savings in disk space alone might offset the performance cost of using a VARCHAR column.
Read also:
Temporary tables and data type selection in SQL Server
AI embeddings in SQL Server 2025
Differences between CHAR and VARCHAR data types
The fundamental difference between CHAR and VARCHAR is that the CHAR data type is fixed in length, while the VARCHAR data type supports variable-length columns of data. But they are also similar. They both can store alphanumeric data. To better understand the differences between these two data types, review the similarities and differences found in Table 1.
Table 1: Differences between CHAR and VARCHAR
|
CHAR |
VARCHAR |
|
Used to store strings of fixed size |
Used to store strings of variable length |
|
Can range in size from 1 to 8000 bytes |
Can range in size from 1 to 8000 bytes |
|
Uses a fixed amount of storage, based on the size of the column |
Use varying amounts of storage space based on the size of the string stored. |
|
Takes up 1 to 4 byte for each character, based on collation setting |
Takes up 1 to 4 byte for each character based on collation and requires one or more bytes to store the length of the data |
|
Better performance |
Slightly poorer performance because length has to be accounted for. |
|
Pads spaces to the right when storing strings less than the fixed size length |
No padding necessary because it is variable in size |
What does the “N” mean in CHAR(N) or VARCHAR(N)
The “N” does not mean the maximum number of characters that can be stored in a CHAR or VARCHAR column but instead means the maximum number of bytes a data type will take up. SQL Server has different collations for storing characters. Some character sets, like Latin, store each character in one byte of space. In contrast, other character sets, like the one for Japanese, require multiple bytes to store a character.
CHAR and VARCHAR columns can store up to 8000 bytes. If a single-byte character set is used, up to 8000 characters can be stored in a CHAR or VARCHAR column. If a multi-byte collation is used, the maximum number of characters that a VARCHAR or CHAR can store will be less than 8000. A discussion on collation is outside the scope of this article, but if you want to find out more about single and multi-byte character sets, then check out this documentation.
Truncation error
When a column is defined as a CHAR(N) or VARCHAR(N), the “N” represents the number of bytes that can be stored in the column. When populating a CHAR(N) or VARCHAR(N) column with a character string, a truncation error like shown in Figure 1 might occur.
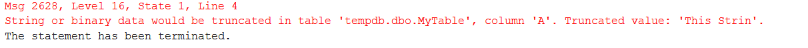
Figure 1: Truncation error
This error occurs when trying to store a string longer than the maximum length of a CHAR or VARCHAR column. When a truncation error like this occurs, the TSQL code terminates, and any following code will not be executed. This can be demonstrated using the code in Listing 1.
Listing 1: Code to produce truncation error
|
1 2 3 4 5 6 7 |
USE tempdb; GO CREATE TABLE MyTable (A VARCHAR(10)); INSERT INTO MyTable VALUES ('This String'); -- Continue on SELECT COUNT(*) FROM MyTable; GO |
The code in Listing 1 produced the error in Figure 1 when the INSERT statement is executed. The SELECT statement following the INSERT statement was not executed because of the truncation error. The truncation error and script termination might be exactly the functionality you might want, but there are times when you might not want a truncation error to terminate your code.
Suppose there is a need to migrate data from an old system to a new system. In the old system, there is a table MyOldData that contains data created using the script in Listing 2.
Listing 2: Table in old system
|
1 2 3 4 5 6 7 |
USE tempdb; GO CREATE TABLE MyOldData (Name VARCHAR(20), ItemDesc VARCHAR(45)); INSERT INTO MyOldData VALUES ('Widget', 'This item does everything you would ever want'), ('Thing A Ma Jig', 'A thing that dances the jig'); GO |
The plan is to migrate the data in MyOldData table to a table named MyNewTable, which has a smaller size for the ItemDesc column. The code in Listing 3 is used to create this new table and migrate the data.
Listing 3: Migrating data to a new table
|
1 2 3 4 5 6 |
USE tempdb; GO CREATE TABLE MyNewData (Name VARCHAR(20), ItemDesc VARCHAR(40)); INSERT INTO MyNewData SELECT * FROM MyOldData; SELECT * FROM MyNewData; GO |
When the code in Listing 3 is run, you get a truncation error similar to the error in Figure 1, and no data is migrated.
In order to successfully migrate the data, you need to determine how to deal with the data truncation to make sure all rows migrate across. One method is to truncate the item description using the SUBSTRING function by running the code in Listing 4.
Listing 4: Eliminating truncation error with SUBSTRING
|
1 2 3 4 5 6 7 8 9 |
DROP Table MyNewData GO USE tempdb; GO CREATE TABLE MyNewData (Name VARCHAR(20), ItemDesc VARCHAR(40)); INSERT INTO MyNewData SELECT Name, substring(ItemDesc,1,40) FROM MyOldData; SELECT * FROM MyNewData; GO |
When running the code in Listing 4, all records are migrated. Those with an ItemDesc longer than 40 will be truncated using the SUBSTRING function, but there is another way.
If you want to avoid the truncation error without writing special code to truncate columns that are too long, you can set the ANSI_WARNINGS setting to off, as done in Listing 5.
Listing 5: Eliminating truncation error by setting ANSI_WARNINGS to off.
|
1 2 3 4 5 6 7 8 9 10 |
DROP Table MyNewData GO USE tempdb; GO CREATE TABLE MyNewData (Name VARCHAR(20), ItemDesc VARCHAR(40)); SET ANSI_WARNINGS OFF; INSERT INTO MyNewData SELECT * FROM MyOldData; SET ANSI_WARNINGS ON; SELECT * FROM MyNewData; GO |
By setting the ANSI_WARNINGS off, the SQL Server engine does not follow the ISO standard for some error conditions, one of those being the truncation error condition. When this setting is turned off, SQL Server automatically truncates the source column to fit in target columns without producing an error. Care should be used when turning off ANSI_WARNINGS because other errors might also go unnoticed. Therefore, changing the ANSI_WARNING setting should be used cautiously.
VARCHAR(MAX)
The VARCHAR(MAX) data type is similar to the VARCHAR data type in that it supports variable-length character data. VARCHAR(MAX) is different from VARCHAR because it supports character strings up to 2 GB (2,147,483,647 bytes) in length. You should consider using VARCHAR(MAX) only when each string stored in this data type varies considerably in length, and a value might exceed 8000 bytes in size.
You might be asking yourself, why not use VARCHAR(MAX) all the time, instead of using VARCHAR? You could, but here are a few reasons why you might not want to do that:
VARCHAR(MAX) columns cannot be included as a key column of an index.
VARCHAR(MAX) columns do not allow you to restrict the length of the column.
In order to store large strings, VARCHAR(MAX) columns use LOB_DATA allocation units for large strings. LOB_DATA storage is much slower than using IN_ROW_DATA storage allocation units.
LOB_DATA storage doesn’t support page and row compression.
You might be thinking VARCHAR(MAX) columns will eliminate the truncation error that we saw earlier. That is partially true, provided you don’t try to store a string value longer than 2,147,483,647 bytes. If you do try to store a string that is longer than to 2,147,483,647 bytes in size, you will get the error shown in Figure 2.
 |
Figure 2: Error when a string is longer than 2 GB in size
You should only use VARCHAR(MAX) columns when you know some of the data you are going to store exceed the 8000-byte limit of a VARCHAR(N) column, and all of the data is shorter than the 2 GB limit for the VARCHAR(MAX) column.
Concatenation problems with CHAR Columns
When a CHAR column is not fully populated with a string of characters, the extra unused characters are padded with spaces. When a CHAR column is padding with spaces, it might cause some problems when concatenating CHAR columns together. To better understand this, here are a few examples that use the table created in Listing 6.
Listing 6: Sample Table
|
1 2 3 4 5 6 7 8 9 |
USE tempdb; GO CREATE TABLE Sample ( ID int identity, FirstNameChar CHAR(20), LastNameChar CHAR(20), FirstNameVarChar VARCHAR(20), LastNameVarChar VARCHAR(20)); INSERT INTO Sample VALUES ('Greg', 'Larsen', 'Greg', 'Larsen'); |
The Sample table created in Listing 6 contains 4 columns. The first two columns are defined as CHAR(20) and the second two columns are defined as VARCHAR(20) columns. These columns will be used to store my first and last name.
In order to demonstrate the concatenation problem associated with padded CHAR columns, run the code in Listing 7.
Listing 7: Showing concatenation problem
|
1 2 |
SELECT FirstNameChar + LastNameChar AS FullNameChar, FirstNameVarChar + LastNameVarChar AS FullNameVarChar FROM Sample; |
Report 1 contains the output when Listing 7 is executed
Report 1: Output when code in Listing 7 is run

In Report 1, the FirstNameCHAR column contains several spaces between my first and last name. These spaces came from the spaces that were padded onto the FirstNameCHAR column when it was stored in the CHAR column. The FullNameVARCHAR column does not contain any spaces between first and last name. No spaces are padded when column values are less than the length of the VARCHAR column.
When concatenating CHAR columns, you might need to remove the trailing spaces to get the results you want. One method of eliminating the spaces can be done using the RTRIM function, as shown in Listing 8.
Listing 8: Removing trailing spaces using the RTRIM function
|
1 2 3 |
SELECT RTRIM(FirstNameChar) + RTRIM(LastNameChar) AS FullNameChar, FirstNameVarChar + LastNameVarChar AS FullNameVarchar FROM Sample; |
Output in Report 2 created when Listing 8 is executed is shown below.
Report 2: Output when Listing 8 is run
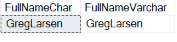
By using the RTRIM function, all the additional spaces added to the FirstNameCHAR and the LastNameCHAR columns were removed before the concatenation operations were performed.
Problems searching CHAR columns for spaces
Because CHAR columns might be padded with spaces, searching for a space might be problematic.
Suppose you have a table containing phrases, like the one created in Listing 9.
Listing 9: Creating Phrase table
|
1 2 3 4 5 6 7 |
USE tempdb; GO CREATE TABLE Phrase (PhraseChar CHAR(100)); INSERT INTO Phrase VALUES ('Worry Less'), ('Oops'), ('Think Twice'), ('Smile'); |
Some phrases in table Phrase consist of just a single word, while the rest have two words. To search the Phrase table to find all the phrases that contain two words, the code in Listing 10 is used.
Listing 10: Trying to find two-word phrases
|
1 |
SELECT PhraseChar FROM Phrase WHERE PhraseChar like '% %'; |
The output in Report 3 is produced when Listing 10 is run.
Report 3: Output when Listing 10 is executed

Why did all the phrases in the Phrase table get returned when only two rows contained 2-word phrases? The search string % % also found the spaces that were padded to the end of the column values. Once again, the RTRIM can be used to make sure the spaces associated with the padding are not included in the search results by running the code in Listing 11.
Listing 11: Removing the trailing spaces
|
1 2 |
SELECT PhraseChar FROM Phrase WHERE RTRIM(PhraseChar) like '% %'; |
I’ll leave it up to you to run the code in Listing 11 to verify if it only finds two-word phrases.
Performance consideration between VARCHAR and CHAR
The amount of work the database engine has to perform to store and retrieve VARCHAR columns is more than it takes for a CHAR column. Every time a VARCHAR column is retrieved, the Database engine has to use the length information stored with the data to retrieve a VARCHAR column value. Using this length information takes extra CPU cycles. Whereas a CHAR column and its fixed length allow SQL Server to more easily chunk through CHAR column based on their fixed-length column definitions.
Disk space is also an issue to consider when dealing with CHAR and VARCHAR columns. Because CHAR columns are fixed-length, they will always take up the same amount of disk space. VARCHAR columns vary in size, so the amount of space needed is based on the size of the strings being storeded instead of the size of the column definition. When a large majority of the values stored in a CHAR column are less than the defined size, then possibly using a VARCHAR column might actually use less disk space. When less disk space is used, less I/O needs to retrieve and store the column value, which means better performance. For these two reasons, choose between CHAR and VARCHAR wisely based on the varying size of the string values being stored.
Read also: In-memory optimized tables in SQL Server
CHAR, VARCHAR, and VARCHAR(MAX)
CHAR columns are fixed in size, while VARCHAR and VARCHAR(MAX) columns support variable-length data. CHAR columns should be used for columns that vary little in length. String values that vary significantly in length and are no longer than 8,000 bytes should be stored in a VARCHAR column. If you have huge strings (over 8,000 bytes), then VARCHAR(MAX) should be used. In order to store VARCHAR columns, the length information along with the data is stored. Calculating and storing the length value for a VARCHAR column means SQL Server has to do a little more work to store and retrieve VARCHAR columns over CHAR column data types.
The next time you need to decide if a new column should be a CHAR, VARCHAR, or VARCHAR(MAX) column, ask yourself a few questions to determine the appropriate data type. Are all the string values to be stored close to the same size? If the answer is yes, then you should use a CHAR. If strings to be stored vary greatly in size, and values are all less than or equal to 8,000 bytes in size, then use VARCHAR. Otherwise, VARCHAR(MAX) should be used.
If you liked this article, you might also like SQL Server identity column.
Fast, reliable and consistent SQL Server development…
FAQs: When to use CHAR, VARCHAR or VARCHAR(MAX) in SQL Server
1. What is the maximum length of VARCHAR and VARCHAR(MAX) in SQL Server?
VARCHAR can store up to 8,000 bytes (characters for single-byte encodings). VARCHAR(MAX) can store up to 2^31 – 1 bytes (approximately 2 GB). For VARCHAR(MAX), values under 8,000 bytes are stored in-row by default; larger values are stored as LOB (Large Object) data with a pointer in the row, which has different performance characteristics for sorting and indexing.
2. What is the difference between CHAR and VARCHAR in SQL Server?
CHAR is a fixed-length data type that always uses the defined number of bytes, padding shorter values with trailing spaces. VARCHAR is variable-length and only uses the storage needed for the actual data plus 2 bytes of length overhead. CHAR is more efficient for columns where all values are the same length; VARCHAR is better when lengths vary, as it avoids wasting storage on padding.
3. Does CHAR or VARCHAR perform better in SQL Server?
For fixed-length data, CHAR can be marginally faster because SQL Server doesn’t need to calculate variable lengths. For variable-length data, VARCHAR is better because it reduces I/O by storing less data per row. In practice, the performance difference is usually negligible for most workloads – choose based on data characteristics rather than micro-optimization.
Load comments