
When designing a table for a database, a column might need to be populated with a different number on every row inserted. An identity column might be a good way to automatically populate a numeric column each time a row is inserted. In this article, I will discuss what a SQL Server identity column is and how it works.
What is a SQL Server identity column?
An identity column is a numeric column in a table that is automatically populated with an integer value each time a row is inserted. Identity columns are often defined as integer columns, but they can also be declared as a bigint, smallint, tinyint, or numeric or decimal as long as the scale is 0. An identity column also can not be encrypted using a symmetric key, but can be encrypted using Transparent Data Encryption (TDE). Additionally an identity column’s definitions must not allow null values. One possible drawback of using an identity column is that only one identity column per table can be used. If more than one numeric field must be populated automatically per table, consider looking at the sequence object, which is outside the scope of this article.
The values automatically generated for each row inserted are based on the seed and an increment property of the identity column. The following syntax is used when defining an identity column:
|
1 |
IDENTITY [ (seed , increment) ] |
Seed is the first value loaded into the table, and increment is added to the previous identity value loaded to create the next subsequent value. Both seed and increment values need to be supplied together if you wish to override the defaults. If no seed and increment values are provided, then the default values for seed and increment are both 1.
Defining identity column using a CREATE TABLE statement
When a table is designed, most data architects will create the layout, so the first column in the table is the identity column. In reality, this is only a standard practice and not a requirement of an identity column. Any column in a table can be an identity column, but there can only be one identity column per table. Script 1 creates a new table named Widget that contains an identity column.
Script 1: Creating a table with an identity column
|
1 2 3 4 5 6 |
CREATE TABLE Widget ( WidgetID int identity(1,1) not null, WidgetName varchar(100) not null, WidgetDesc varchar(200) not null ); |
The WidgetID is the identity column with a seed value of 1 and an increment value of 1.
The seed value determines the identity value for the first row inserted into a table. The increment value is used to determine the identity value of subsequent rows inserted into the table. For each row inserted after the first row, the increment value is added to the current identity value to determine the identity value for the new row being added. The current identity value is an integer value for the identity column of the last row inserted into the table. To see how this works, run Script 2.
Script 2: Code to insert and display three rows added to table Widget
|
1 2 3 4 5 |
INSERT INTO Widget VALUES ('thingamajig','A jig you cannot remember'), ('doodad','A hair style you cannot remember'), ('whatchamacallit', 'A thing for which you cannot remember'); SELECT * FROM Widget; |
When the code in Script 2 runs, the output in Report 1 is displayed.
Report 1: Output when Script 2 is run

In Script 2, three rows are inserted into the newly created Widget table. My script only provided column values for the WidgetName, and WidgetDesc columns and didn’t provide values for the WidgetID column. The value for the WidgetID column for the first row inserted was based on the seed defined in the CREATE TABLE statement, which was identified in Script 1. The WidgetID value 2 for the row with a WidgetName of doodad was created by adding the increment value of 1 to the last identity value inserted. The WidgetID value of 3, for the row with whatchamacallit. WidgetName, got its identity value by adding 1 to the identity value used on the second row insert.
Remember that the seed and increment values do not have to be 1 and 1, respectively; they could be whatever values are appropriate for the table. For example, a table could use a seed value of 1000 and an increment of 10, as I have done for the WidgetID column.
Script 3: Using different seed and increment value
|
1 2 3 4 5 6 |
CREATE TABLE DifferentSeedIncrement ( ID int identity(1000,10), A varchar(100), B varchar(200) ); |
The ID column in Script 3 doesn’t have the NOT NULL property identified, in the CREATE TABLE statement, as I had done with the identity column defined in Script 1. The not null column requirement can be left off because, behind the scenes, the database engine will automatically add the NOT NULL property for any identity column being created.
I’ll leave it up to you to run the code in Script 3 and insert a few rows in the DifferentSeedIncrement table. This way, you can see for yourself that the ID values generated for each new row are inserted into the DifferentSeedIncrement table and how the table is defined to SQL Server.
Uniqueness of an identity column
Creating an identity column on a table doesn’t mean an identity value will be unique. The reason identity column values might not be unique is that SQL Server allows identity values to be manually inserted, as well the seed value can be reset. I will be covering both the inserting identity values and resetting the seed value concepts in a follow up article. The SQL Server documentation clearly states that uniqueness must be enforced by using a primary key, unique constraint, or unique index. Therefore, to guarantee that an identity column only contains unique values, one of the aforementioned objects must force uniqueness for each value in an identity column.
Identifying identity columns and their definitions in database
There are a number of ways to identify the identity columns and their definitions in a database. One way is to use SQL Server Object Explorer, however, the identity column can’t be determined by just displaying the columns in a table, as shown in Figure 1
|
|
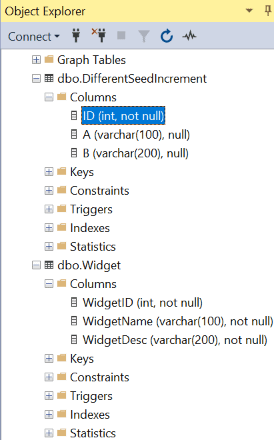
Figure 1: Displaying column definitions for tables created by Script 1 and Script 3
To determine which column is actually an identity column, the column’s properties need to be reviewed. To show the properties of a column, right-click on the column in Object Explorer and then click on the Properties item from the drop-down context menu. Figure 2 shows the properties of the WidgetID column in the Widget table.
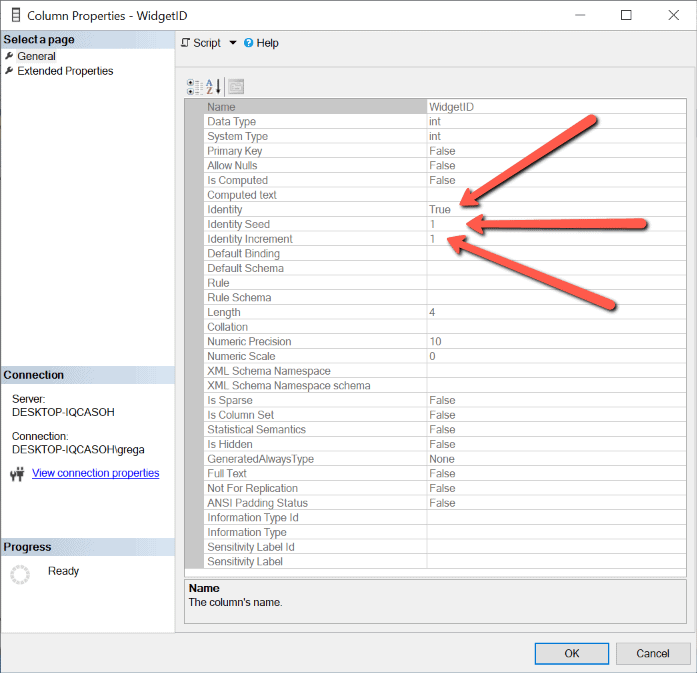
Figure 2: Properties the dbo.Widget.WidgetId column
If the Identity property has a value of True, then the column is an identity column. The seed and increment values are also displayed.
Using the Object Explorer properties method in a database with lots of tables might take a while to determine which columns are identity columns. Another method to display all the identity columns in a database is to use the sys.identity_column view, as shown in the TSQL code in Script 4.
Script 4: Script to display all identity values in a database
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT OBJECT_SCHEMA_NAME(tables.object_id, db_id()) AS SchemaName, tables.name As TableName, identity_columns.name as ColumnName, identity_columns.seed_value, identity_columns.increment_value, identity_columns.last_value FROM sys.tables tables JOIN sys.identity_columns identity_columns ON tables.object_id=identity_columns.object_id GO |
Script 4 returns the output in Report 2.
Report 2: Output when script 4 is run

Note that the last_value column for the TableName of DifferentSeedIncrement has a value of NULL. This means no rows have been inserted into this table to be able to set the LastValue.
Adding an identity column to an existing table
An existing column cannot be altered to make it an identity column, but a new identity column can be added to an existing table. To show how this can be accomplished, run the code in Script 5. This script creates a new table, adds two rows, and then alters the table to add a new identity column.
Script 5: Adding an identity column
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TABLE Invoices ( InvoiceDate date, InvoiceNumber varchar(100), PayTo varchar (100) ); INSERT INTO Invoices VALUES (getdate(), 'GL_0001', 'Greg Larsen'), (getdate(), 'GL_0002', 'Greg Larsen'); -- Add Identity Column ALTER TABLE Invoices ADD InvoiceID int identity; -- Review Rows SELECT * FROM Invoices; |
The output of Script 5 is shown in Report 3.
Report 3: Rows in Invoices table

Report 3 shows that the new InvoiceID column was added, the identity values for this column were automatically populated on all existing rows.
Altering an existing table to define an identity column
As already stated, SQL Server does not allow using the ALTER TABLE/ALTER COLUMN command to change an existing column into an identity column directly. However, there are options to modify an existing table column to be an identity column. The following example shows an option that uses a work table to alter a column in an existing table to be an identity column.
To accomplish modifying an existing column to be an identity column, the script uses the ALTER TABLE … SWITCH command. The SWITCH option was added to the ALTER TABLE statement in SQL Server 2005 as part of the partitioning feature. The TSQL code in Script 6 uses a temporary work table and the SWITCH option to support altering an existing column to make it an identity column.
Script 6: Altering an existing column to be an identity column
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
DROP TABLE Invoices -- clean up from prior example GO -- Step 1: Create Invoices table and populate with data CREATE TABLE Invoices ( InvoiceID int NOT NULL, InvoiceDate date, InvoiceNumber varchar(100), PayTo varchar (100) ); INSERT INTO Invoices VALUES (1, getdate(), 'GL_0001', 'Greg Larsen'), (2, getdate(), 'GL_0003', 'Greg Larsen'); -- Step 2: create temporary work table with same schema, but has identity column CREATE TABLE Invoices2 ( InvoiceID int identity(1,1), InvoiceDate date, InvoiceNumber varchar(100), PayTo varchar (100) ); -- Step 3: Switch Tables, drop original, and rename ALTER TABLE Invoices SWITCH TO Invoices2; -- drop original table DROP TABLE Invoices; -- Rename temp table back to original table name EXEC sp_rename 'Invoices2','Invoices'; -- Step 4: Update the current seed value for new Invoices table DBCC CHECKIDENT('Invoices'); |
Script 6 went through 4 steps to alter an existing column to be an identity column. Below are some things to consider when using this method to add an identity column to an existing table:
To use the SWITCH option on the ALTER TABLE statement, the column being changed to an identity column on the original table must not allow nulls. If it allows null, then the switch operations will fail.
Make sure to reseed the identity column of the new table using the DBCC CHECKIDENT command. If this is not done, then the next row inserted will use the original seed value, and duplicate identity values could be created if there is not a primary key, or unique constraint, or unique index on the identity column.
All foreign keys will need to be dropped prior to running the ALTER TABLE …SWITCH command.
If indexes exist on the original table, then the temporary table will also need the exact same indexes, or the switch operation will fail.
While the ALTER TABLE …SWITCH command is running, there must be no transactions running against the table. All new transactions will be prevented from starting while the switch operation is being performed.
When switching tables, security permissions could be lost because the security permissions are associated with the target table when a switch operation is performed. Therefore, make sure permissions of the original table are recreated on the target table either before or shortly after the switch operation.
Reseeding an identity column
In the previous example, I reseeded the identity column value by using the DBCC CHECKIDENT statement. There are other reasons why an identity column value might need to be reseeded, like when several rows were incorrectly inserted into a table, or erroneous rows were deleted. Mistakenly inserting erroneous rows causes the current identity to be increased for each row added. Therefore, after all the bad rows have been deleted, the next row will use the next identity value and leave a large gap in identity values. If this mistake has been made, then reseeding the identity value ensures there isn’t a big gap of missing identity values.
The DBCC CHECKIDENT command is used to reseed an identity value for a table. This command has the following syntax:
|
1 2 3 4 5 6 |
DBCC CHECKIDENT ( table_name [, { NORESEED | { RESEED [, new_reseed_value ] } } ] ) [ WITH NO_INFOMSGS ] |
The table_name parameter is the name of the table that contains an identity specification. The table must contain an identity column, otherwise, an error will occur when the DBCC CHECKINDENT command is run. If no other options are added along with this command, then the current identity value will be reset to the maximum value found in the existing identity column.
The NORESEED option specifies not to change the seed value. This option is useful to determine the current and maximum identity value. If the current and maximum values are different, then the identity value should be reseeded.
When the current identity value is less than the maximum, or there is a large gap in the identity values, the RESEED option can be used to reset the current identity value. The RESEED option can be specified with or without a new_reseed_value. When no new_reseed_value is specified, the current identity value will be set to the maximum value stored in the identity column of the table specified.
Script 6 shows how to reseed an identity column value using DBCC CHECKINDENT command without using the RESEED option. The TSQL code in script 7 shows how to set the current seed value to 2 using the RESEED option.
Script 7: Using the RESEED option
|
1 |
DBCC CHECKIDENT('Invoices',RESEED,2); |
Be careful with using the RESEED option with a new seed value. SQL Server doesn’t care what value is used for the new seed. If the new seed is set to a value less than the maximum seed value in the table, duplicate identity values might be created.
The SQL Server identity column
An identity column will automatically generate and populate a numeric column value each time a new row is inserted into a table. The identity column uses the current seed value along with an increment value to generate a new identity value for each row inserted. This article only covered some fundamental aspects of using the identity column. In a future article, more nuances of the identity columns will be explored.
If you liked this article, you might also like Improving performance with instant file initialization.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments