
Once again, here I am to talk to you about ShowPlan operators. Over the past few weeks and months, we’ve featured the ShowPlan operators used by SQL Server to build query plans. If you’re just getting started with my Showplan series, you can find a list of all my articles here. Before we start to talk about the operators of this article, I’d like to ask you to participate in the creation of this series; if you want to know more about a Showplan operator that I haven’t covered yet, please leave a comment in this article with your suggestion.
I also want to thank all of you for the kind words/comments I’m receiving about the articles; I’m flattered to know you are enjoying this series and that it has been useful for you.
Introduction
Today we’ll feature two new operators and describe how the sort operator can be used to help with the validation of a query. The sort operator has already been covered in this article, so, if you want to know more about it just click here.
In short, these operators, Split and Collapse, are used to identify a phantom unique key violation. To help to understand this better, I’ll start by explaining the unique index and how it is used by the query optimizer: Then I’ll go on to present a update command that uses these operators.
Unique Index
The Unique Index is an index that guarantees that no duplicate values are allowed in a specified key column. In other words, if you want to be sure that some value can’t be duplicated in your table, then a unique index can be made responsible for enforcing this. A classic use for a unique index is as the primary key of your table, where no duplicated rows are allowed.
Every time that you create a new index, decide whether this can be a unique index. Why? Because the Query Optimizer can then use this index to simplify a query plan: If it knows that the rows are always going to be unique, it knows that the selectivity is always one. The more selective an index has, the greater the likelihood that it will be used by a query.
Creating sample data
To illustrate the operators that are the subject of this article, I’ll start by creating one table called “TabTest”. The following script will create the table and populate it with some meaningless data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
USE tempdb GO IF OBJECT_ID('TabTest') IS NOT NULL DROP TABLE TabTest GO CREATE TABLE TabTest (ID Int IDENTITY(1,1) PRIMARY KEY, Name VarChar(250) NULL, Name2 VarChar(250) NULL, Val Int NULL, Val2 Int NULL) GO CREATE UNIQUE INDEX ix_Name_Unique ON TabTest(Name) CREATE INDEX ix_Name2_NonUnique ON TabTest(Name2) CREATE UNIQUE INDEX ix_Val_Unique ON TabTest(Val) CREATE INDEX ix_Val2_NonUnique ON TabTest(Val2) GO INSERT INTO TabTest(Name, Val) VALUES(NEWID(), 1) INSERT INTO TabTest(Name, Val) VALUES(NEWID(), 2) INSERT INTO TabTest(Name, Val) VALUES(NEWID(), 3) INSERT INTO TabTest(Name, Val) VALUES(NEWID(), 4) INSERT INTO TabTest(Name, Val) VALUES(NEWID(), 5) GO UPDATE TabTest SET Name2 = Name, Val2 = Val GO SELECT * FROM TabTest |
You’ll have noticed that the table has four indexes, one for each column. The difference between the columns Name and Name2 is that the indexes on the columns with the prefix “2” are non-unique indexes, and the index on the columns Name and Val are unique.
The value of the columns Name2 and Val2 are the same as the columns Name and Val.
Here is what the data looks like:
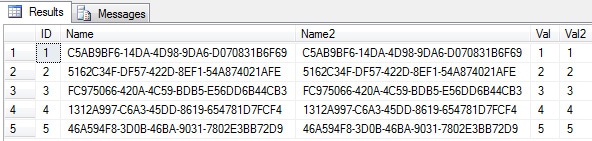
Querying an Unique Index
Now that we have created and populated the table, let’s try two queries: First, a query that selects all the rows using a filter on the column with the unique index:
|
1 2 3 4 |
SELECT * FROM TabTest WHERE Name = '1C9629D2-593A-4C42-8EEA-CFA289AE060F' GO |
For the query above we have the following execution plan:
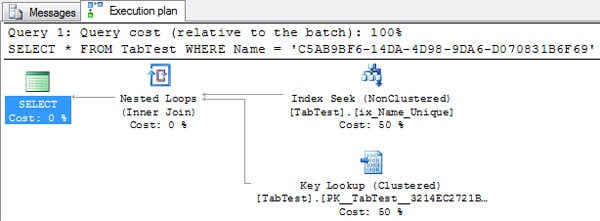
As we can see from the execution plan, SQL Server chose to perform an Index Seek on the ix_Name_Unique index and a Key Lookup to read the data on the clustered index.
Now let’s try to run the same query using the column with the non-unique index:
|
1 2 3 4 |
SELECT * FROM TabTest WHERE Name2 = 'C5AB9BF6-14DA-4D98-9DA6-D070831B6F69' GO |
For the query above we have the following execution plan:
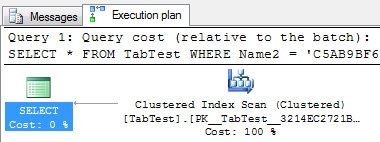
As we can see, now SQL Server chose to run a scan on the clustered index.
Because the first query is using a Unique Index, SQL Server decides to simplify matters by merely creating a Trivial Plan. Oops! I have a feeling that I haven’t yet described what a trivial plan is, so let me do it now.
Trivial Plan
An execution plan is created during the optimization process. Generally, SQL Server has to use a variety of techniques to try to optimize your query in order to create the best-possible plan. Sometimes, however, the Query Optimizer can decide that it does not need to do the full optimization process to find the best plan, Because it has determined that there is a plan that is good enough.
Within the execution plan, we can see if the query optimizer has decided that the Plan is trivial by looking at the properties of the plan: For instance, let’s look at the execution plan of the first query:

Apart from that, we also can see if the plan is trivial by looking at the XML plan:

A trivial plan is created when the Query Optimizer finds an optimal way of read the data that you are querying. For instance a “select * from table” probably will create a trivial plan that merely reads the data from the clustered index. When a trivial plan is selected, the Query Optimizer doesn’t then need to expend resources in trying to figure out the best plan because it knows that this trivial plan is the best option.
If a plan is determined to be trivial, then the query isn’t recompiled when an Update Statistics occurs on the statistics, and an Auto Update Statistics isn’t fired. Let’s see this in the practice.
Let’s try the first query. If we look at the cache plan, we can see that we have the trivial plan and that it was been reused:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
USE tempdb GO DBCC FREEPROCCACHE GO SELECT * FROM TabTest WHERE Name = 'D1397278-67CA-4EE6-B383-2E278018DC8F' GO SELECT * FROM TabTest WHERE Name = '7462AD1E-3335-44BE-AFC4-28F44FCA4F90' GO SELECT cp.objType, cp.Usecounts, st.Text AS Query, qp.query_plan.value('declare default element namespace "http://schemas.microsoft.com/sqlserver/2004/07/showplan"; (//StmtSimple/@StatementOptmLevel)[1]', 'varchar(20)') AS StatementOptmLevel, qp.query_plan FROM sys.dm_exec_cached_plans cp CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) qp WHERE st.Text like '%from TabTest%' AND st.text not like '%sys.%' AND cp.ObjType = 'Prepared' |
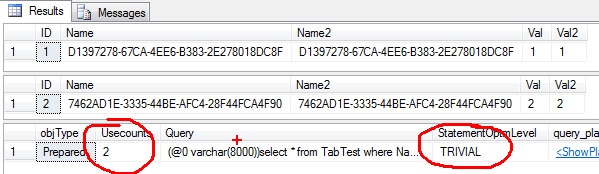
In this query, I start by freeing the plan cache; then I run the query twice. Finally, I query the DMVs to find out how many times the plan was reused, and to see the StatementOptmLevel within the XML plan.
As we can see in the picture (column UseCounts), the query was executed twice and the plan was reused.
Now, let’s insert some data in the table in order to force an automatic update statistics. If you want to know how much data do you will need to change so as to trigger an update statistics, then read the item 13 of this article.
|
1 2 3 |
INSERT INTO TabTest(Name, Val) SELECT NEWID(), ABS(CHECKSUM(NEWID())) / 1000 GO 500 |
After inserting 500 rows into the table, I’ll run the query again and check whether the plan was reused or if a new plan was created as a result of the auto update statistics. Optionally, you can check the event SP:StmtCompleted in the profiler to see if the update statistics was executed.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT * FROM TabTest WHERE Name = '74DD0A57-56CF-4331-A324-7A7E83C6043E' GO SELECT cp.objType, cp.Usecounts, st.Text AS Query, qp.query_plan.value('declare default element namespace "http://schemas.microsoft.com/sqlserver/2004/07/showplan"; (//StmtSimple/@StatementOptmLevel)[1]', 'varchar(20)') AS StatementOptmLevel, qp.query_plan FROM sys.dm_exec_cached_plans cp CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) qp WHERE st.Text like '%from TabTest%' AND st.text not like '%sys.%' AND cp.ObjType = 'Prepared' |
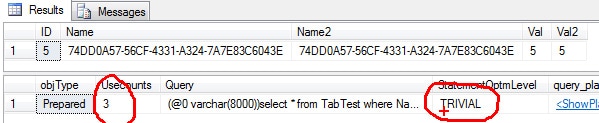
Now we can see that the plan was reused, even after we had inserted sufficient data to fire an update statistics and thereby cause the creation of a new plan.
Let’s try the same exercise with the non-trivial plan:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
USE tempdb GO DBCC FREEPROCCACHE GO SELECT * FROM TabTest WHERE Name2 = '47B12B84-6B81-4D54-A2ED-3F4BAE31835E' GO SELECT * FROM TabTest WHERE Name2 = '3901385F-2481-4126-BAF7-15B9C656952A' GO SELECT cp.objType, cp.Usecounts, st.Text AS Query, qp.query_plan.value('declare default element namespace "http://schemas.microsoft.com/sqlserver/2004/07/showplan"; (//StmtSimple/@StatementOptmLevel)[1]', 'varchar(20)') AS StatementOptmLevel, qp.query_plan FROM sys.dm_exec_cached_plans cp CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) qp WHERE st.Text like '%from TabTest%' AND st.text not like '%sys.%' AND cp.ObjType = 'Prepared' |
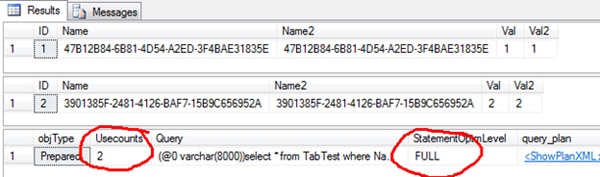
Again the plan was reused. Now let’s see what happens after we insert the new data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
INSERT INTO TabTest(Name, Val) SELECT NEWID(), ABS(CHECKSUM(NEWID())) / 1000 GO 500 UPDATE TabTest SET Name2 = Name, Val2 = Val GO SELECT * FROM TabTest WHERE Name2 = 'AC7E0C8E-1240-4537-817E-D20819971542' GO SELECT cp.objType, cp.Usecounts, st.Text AS Query, qp.query_plan.value('declare default element namespace "http://schemas.microsoft.com/sqlserver/2004/07/showplan"; (//StmtSimple/@StatementOptmLevel)[1]', 'varchar(20)') AS StatementOptmLevel FROM sys.dm_exec_cached_plans cp CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) qp WHERE st.Text like '%from TabTest%' AND st.text not like '%sys.%' AND cp.ObjType = 'Prepared' |
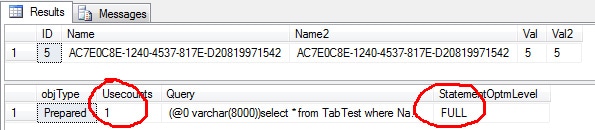
As we can see, the auto update statistics was now triggered and a new plan was created.
Full Optimization
An interesting thing is that, in the execution plans, we can only see two level of optimization, TRIVIAL and FULL. But behind the scenes we can see that the FULL optimization is divided into three steps: These steps are called Search 0, Search 1 and Search 2. (Yes, I don’t like these names either, I expected something more intuitive).
If we query the DMV sys.dm_exec_query_optimizer_info, we can see which phase was executed in a FULL optimization.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT Counter, Occurrence FROM sys.dm_exec_query_optimizer_info WHERE Counter IN (N'trivial plan', N'search 0', N'search 1', N'search 2') GO SELECT * FROM TabTest WHERE Name2 = 'AC7E0C8E-1240-4537-817E-D20819971542' OPTION (RECOMPILE) GO SELECT Counter, Occurrence FROM sys.dm_exec_query_optimizer_info WHERE Counter IN (N'trivial plan', N'search 0', N'search 1', N'search 2') |
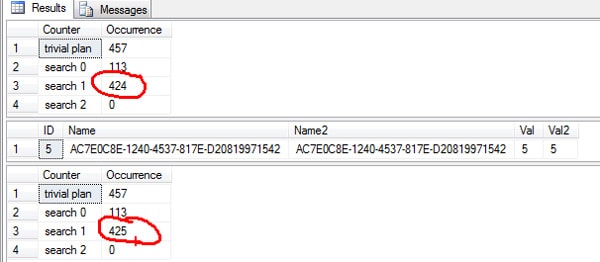
In the picture above, we can see that the Search 1 counter has increased by one. If you run the query using the unique index, you will see the trivial plan counter increasing.
Some queries require a full optimization. This means that, if you have a heavy query with lot of joins, it may use search 1 or if you have a query that maybe uses a indexed view it will use search 2. You can play with the DMV to see the level of optimization that you got in your query.
Back to – Querying an Unique Index
After explaining both trivial and full optimization, let’s see more samples that demonstrate the benefit of having a unique index.
The Query Optimizer can :avoid an unnecessary distinct:
|
1 2 3 |
SELECT DISTINCT Name FROM Tabtest GO |
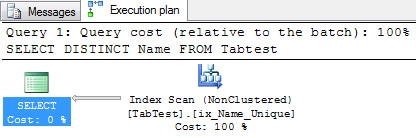
In this execution plan, the Query Optimizer knows that the DISTINCT clause is totally unnecessary, and it doesn’t waste time trying to remove the duplicated occurrences because it knows that, if the column is unique, then it is sufficient to just read the data from the index.
The Query Optimizer can avoid an unnecessary aggregation:
|
1 2 3 |
SELECT Name, SUM(Val) FROM TabTest GROUP BY Name |

As we can see, there is no aggregation needed to compute the SUM because SQL Server knows that there is only one row per Name. SQL is reading the data from the clustered index. The mere presence of the unique index is enough to enable a optimization, even though SQL Server is not actually reading the data from that index.
The Query Optimizer can avoid an assert validation:
|
1 2 3 4 |
SELECT Val, (SELECT Name FROM TabTest WHERE Name = 'C24A5A66-6008-4462-B64D-EB3F76D0A420') FROM TabTest |
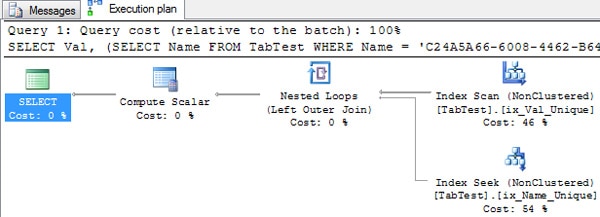
Here we can see that SQL Server is not using the operator Assert to validate the Sub-Query expression. If you want to know more about the operator assert click here.
Non-Unique Index and Updates
Every update is executed in two main steps. Firstly, SQL Server has to read the data that will be updated, and then it must update these values.
Let’s analyze a plan that updates a non-unique indexed column. Here is a query that updates the column Val2 that doesn’t have a unique index.
|
1 |
UPDATE TabTest SET Val2 = Val2 + 1 |

Execution Plan in text mode:
|
1 2 3 4 5 6 |
|--Clustered Index Update(OBJECT:([TabTest].[PK__TabTest__3214EC2703317E3D]), OBJECT:([TabTest].[ix_Val2_NonUnique]), SET:([TabTest].[Val2] = [Expr1003])) |--Compute Scalar(DEFINE:([Expr1016]=[Expr1016])) |--Compute Scalar(DEFINE:([Expr1016]=CASE WHEN [Expr1007] THEN (0) ELSE (1) END)) |--Compute Scalar(DEFINE:([Expr1003]=[TabTest].[Val2]+(1), [Expr1007]=CASE WHEN [TabTest].[Val2] = ([TabTest].[Val2]+(1)) THEN (1) ELSE (0) END)) |--Top(ROWCOUNT est 0) |--Clustered Index Scan(OBJECT:([TabTest].[PK__TabTest__3214EC2703317E3D])) |
As usual, let’s go through this execution plan step by step analyzing what is happening with some operators of the plan.
- Clustered Index Scan – Here, the SQL Server is reading the data that will be updated on the clustered index.
- TOP – The TOP operator is necessary in order to perform the SET ROWCOUNT. I know that sounds a little weird the first time that you hear it, because we aren’t executing the SET ROWCOUNT. What happens here is that, if you change the value of the ROWCOUNT, it will not trigger a recompilation of the plan, which means that SQL has to find some way to execute the query using a cached plan, plus updating just those rows specified in the ROWCOUNT.
- Compute Scalar – In this operation, we can see the new optimization that is created on SQL Server 2005 in order to avoid the update of a value that hadn’t changed. I already covered this optimization at the Item 11 of this article.
If we analyze the text execution plan, we can see that there is a case expression that checks whether the value has changed:
|
1 2 3 4 |
[Expr1007] = Scalar Operator(CASE WHEN [TabTest].[Val2] = ([TabTest].[Val2]+(1)) THEN (1) ELSE (0) END) |
As we can see, if the value is the same, the value 1 (one) will be returned to the [Expr1007] and if not, then 0 (zero) will be returned.
- Clustered Index Update – Here, the optimizer will execute the Update. An interesting thing here is that we can call this plan a “Narrow Plan” or a “Per-Row Plan”.
You’ll have probably noticed from the text execution plan that there are two indexes being updated by this operator, the clustered index and the index ix_Val2_NonUnique.
Every time that you update a column that has a non-clustered index, SQL Server has to maintain the data in the clustered and the nonclustered indexes by updating it. Usually this update is executed in the clustered index key order, which means that the nonclustered updates are executed in a random order (because it’s on the clustered index order) and not in the nonclustered key order.
Sometimes, the Query Optimizer can create a “Wide Plan” that reads the data from each updated index and executes the update in the index order
To show you a sample of a wide plan, I’ll create some new indexes and I’ll change the number of rows and pages on the statistics of the table TabTest:
|
1 2 3 4 5 6 7 |
CREATE INDEX ix1 ON TabTest (Val2) CREATE INDEX ix2 ON TabTest (Val2) UPDATE STATISTICS TabTest WITH ROWCOUNT = 50000, PAGECOUNT = 180 UPDATE STATISTICS TabTest ix_Val2_NonUnique WITH ROWCOUNT = 50000, PAGECOUNT = 180 UPDATE STATISTICS TabTest ix1 WITH ROWCOUNT = 50000, PAGECOUNT = 180 UPDATE STATISTICS TabTest ix2 WITH ROWCOUNT = 50000, PAGECOUNT = 180 GO |
After messing with the statistics, let’s try the same update:
|
1 |
UPDATE TabTest SET Val2 = Val2 + 1 |
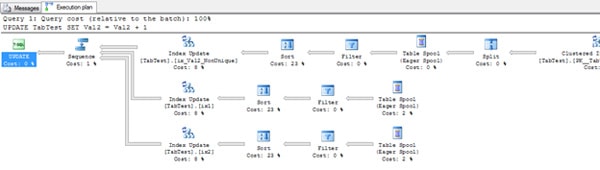

Execution Plan in Text Mode:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|--Sequence |--Index Update(OBJECT:([TabTest].[ix_Val2_NonUnique]), SET:([ID1031] = [TabTest].[ID],[Val21032] = [TabTest].[Val2]) WITH ORDERED PREFETCH ACTION:([Act1030])) | |--Sort(ORDER BY:([TabTest].[Val2] ASC, [TabTest].[ID] ASC, [Act1030] ASC)) | |--Filter(WHERE:(NOT [Expr1024])) | |--Table Spool | |--Split | |--Clustered Index Update(OBJECT:([TabTest].[PK__TabTest__3214EC27440B1D61]), SET:([TabTest].[Val2] = [Expr1003])) | |--Compute Scalar(DEFINE:([Expr1024]=[Expr1024], [Expr1025]=[Expr1025], [Expr1026]=[Expr1026])) | |--Compute Scalar(DEFINE:([Expr1024]=CASE WHEN [Expr1007] THEN (1) ELSE (0) END, [Expr1025]=CASE WHEN [Expr1007] THEN (1) ELSE (0) END, [Expr1026]=CASE WHEN [Expr1007] THEN (1) ELSE (0) END)) | |--Compute Scalar(DEFINE:([Expr1003]=[TabTest].[Val2]+(1), [Expr1007]=CASE WHEN [TabTest].[Val2] = ([TabTest].[Val2]+(1)) THEN (1) ELSE (0) END)) | |--Top(ROWCOUNT est 0) | |--Clustered Index Scan(OBJECT:([TabTest].[PK__TabTest__3214EC27440B1D61]), ORDERED FORWARD) |--Index Update(OBJECT:([TabTest].[ix1]), SET:([ID1033] = [TabTest].[ID],[Val21034] = [TabTest].[Val2]) WITH ORDERED PREFETCH ACTION:([Act1030])) | |--Sort(ORDER BY:([TabTest].[Val2] ASC, [TabTest].[ID] ASC, [Act1030] ASC)) | |--Filter(WHERE:(NOT [Expr1025])) | |--Table Spool |--Index Update(OBJECT:([TabTest].[ix2]), SET:([ID1035] = [TabTest].[ID],[Val21036] = [TabTest].[Val2]) WITH ORDERED PREFETCH ACTION:([Act1030])) |--Sort(ORDER BY:([TabTest].[Val2] ASC, [TabTest].[ID] ASC, [Act1030] ASC)) |--Filter(WHERE:(NOT [Expr1026])) |--Table Spool |
Now we have a bigger plan and we can see that SQL is updating one index per time, using the data sorted by the index key.
Unique Index and Updates
After some explanation about unique indexes, it is now time to show you, in action, the three operators that are the subject of this article. Let’s run the update in the column with the unique index and analyze the plan.
|
1 |
UPDATE TabTest SET Val = Val + 1 |

Part of the plan was omitted so as to concentrate on the topic.
In the beginning of the article I made the statement that these operators are used to avoid a phantom unique key violation. Let’s try to understand that statement a bit better.
The data on the column Val is the following:
|
1 |
SELECT ID, Val FROM TabTest |
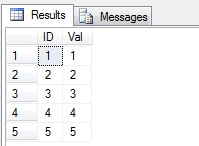
We already know that an update is executed by a delete operation followed by an insert operation. You can see an explanation about it on the Item 11 of this article. We can also detect that the update has been executed by the clustered key order.
Following this logic, let’s mimic what will happen.
- Read the first row from the clustered index to be updated. Result, ID = 1
- Find the row ID = 1 in the unique index. Result, Val = 1
- Delete the row with the value Val = 1
- Insert the new value Val = 1 + 1 (2)
Here we have a phantom unique key violation because the value 2 already exists in the Unique Index. Because this value will eventually also be updated, this is a false violation.
To avoid it, SQL Server uses the operators Split, Sort and Collapse in order to reorganize the Deletes and the Inserts.
In our table we have the following rows to be updated:
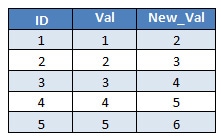
The column Val is the key column that we need to update, and the column New_Val is the value of the column after the update.
After the Split occurs, SQL Server get the deletes and the inserts of the values, and a new list is created:
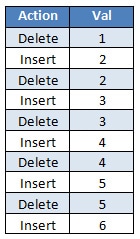
The Split creates a list with all the deletes and the inserts, but this list is not properly ordered because the insertion of the value 2 is done before the delete, so we still have the phantom violation.
The operator Sort is used to reorder the list by Action plus the Key Value, and the Deletes then appear before the Inserts. So, after the sort operation, we have the following list:
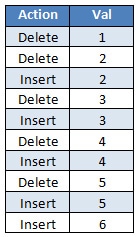
Now the delete appears before the insert. If SQL Server runs the deletes and inserts in that order then all goes well and no phantom read occurs. But we still have the collapse operator.
The collapse operator combines those adjacent ‘delete’ and ‘insert’ pairs that share the same key value into a single ‘update’. Collapse finds ‘delete’s and ‘insert’s for the same key and changes them into just one ‘update’.
For instance, why should I have to delete and insert a new row with the value 2? If I can just ignore this step then it’s a good improvement. Right?
After the collapse we have the following actions to be executed:
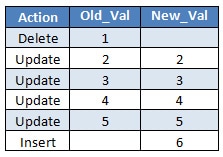
Because I know you are clever, you are probably thinking. – Ummm. Why update the value 2 to 2? Isn’t better if we got a list just like the following?
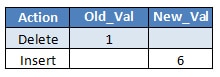
If we perform these two actions we have the expected final result.
I have to confess that I didn’t know why SQL Server executed these updates until I watched the Conor Cunningham session at the PASS 2010 talking about updates.
According to him, SQL Server needs to update the same row to guarantee that the stored engine puts the locks on the rows that are being updated. If SQL Server doesn’t lock the row, another transaction can change the row and the update would consequently fail.
Finally
I want to say ‘thank you’ to the people from the Query Optimization community (yes there are some guys out there just talking about QO) that indirectly help me to understand it better. Paul White (BTW congrats for the MVP award), Conor Cunningham, Benjamin Nevarez (BTW congrats for your Book) and Craig Freedman.
If you don’t follow these guys, you are missing a lot of good stuff about query optimization.
That’s all folks, I hope you’ve enjoyed learning about these operators, and I’ll see you soon with more “Showplan Operators”.




Load comments