

Over the past few weeks, we’ve featured the Spool operations (Table Spool(Eager Spool), Table Spool(Lazy Spool)and NonClustered Index Spool), and this week we’ll be completing the set with the Row Count Spool Showplan operator.
Of all spool operators we’ve seen, I think this is the most simple. The Row Count Spool operator just scans an input, counting how many rows are present, and returns the number of rows without any of the data they contained. This operator is used when it is important to check for the existence of rows, but not what data they hold. For example, if a Nested Loops operator performs a left anti semi join operation, and the join predicate applies to the inner input, a row count spool may be placed at the top of that input to cache the number of rows which satisfy the argument. Then, the Nested Loops operator can just use that row count information (because the actual data from the inner input is not needed) to determine whether to return the outer row or not (or rather, how many rows to return).
I know that’s a little tricky to wrap your head around at first without a concrete example, so to illustrate this behavior I’ll start, as always, by creating a table called “Pedidos” (which means Orders in Portuguese). The following script will create a table and populate it with some garbage data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
USE tempdb GO IF OBJECT_ID('Pedido') IS NOT NULL DROP TABLE Pedido GO CREATE TABLE Pedido (ID Int IDENTITY(1,1), Cliente Int NOT NULL, Vendedor VarChar(30) NOT NULL, Quantidade SmallInt NOT NULL, Valor Numeric(18,2) NOT NULL, Data DateTime NOT NULL) GO CREATE CLUSTERED INDEX ix ON Pedido(ID) GO DECLARE @I SmallInt SET @I = 0 WHILE @I < 5000 BEGIN INSERT INTO Pedido(Cliente, Vendedor, Quantidade, Valor, Data) SELECT ABS(CheckSUM(NEWID()) / 100000000), 'Fabiano', ABS(CheckSUM(NEWID()) / 10000000), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))), GetDate() - (CheckSUM(NEWID()) / 1000000) INSERT INTO Pedido(Cliente, Vendedor, Quantidade, Valor, Data) SELECT ABS(CheckSUM(NEWID()) / 100000000), 'Amorim', ABS(CheckSUM(NEWID()) / 10000000), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))), GetDate() - (CheckSUM(NEWID()) / 1000000) INSERT INTO Pedido(Cliente, Vendedor, Quantidade, Valor, Data) SELECT ABS(CheckSUM(NEWID()) / 100000000), 'Coragem', ABS(CheckSUM(NEWID()) / 10000000), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))), GetDate() - (CheckSUM(NEWID()) / 1000000) SET @I = @I + 1 END GO |
This is what the data looks like.
Figure 1. The demonstration table and data.
Next, we’ve got a sample query which will return the ID and Value for all orders only if there is no order which was placed on 2009-01-01 for more than 10 items (i.e. Quantity (Quantidade) > 10).
|
1 2 3 4 5 6 7 |
SELECT ID, Valor FROM Pedido Ped1 WHERE NOT EXISTS(SELECT 1 FROM Pedido Ped2 WHERE Ped2.Data = '20090101' AND Ped2.Quantidade > 10) OPTION(MAXDOP 1) |
For the query above, we have the following execution plan:
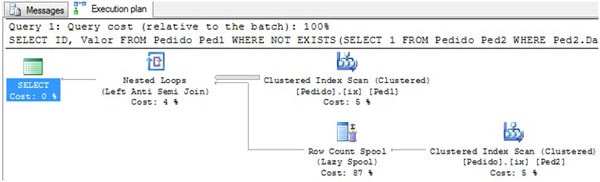
Figure 2. The graphical execution plan, clearly employing the Row Count Spool
As we can see, this plan is using the operator Row count Spool to check the EXISTS Sub Query, which returns just a true (some row’s exist) or false (no rows exist) value, and so the actual contents of the rows doesn’t matter (do you see where I’m going with this?) Let’s take a closer look at what is happening.
First, the Clustered Index Scan reads all the rows in Pedido table using the ix index, after which all rows are passed to the Nested Loops Operator to be joined with the SubQuery result. Bear in mind that this Loops operator is working as a Left anti Semi Join, which means that only one side (the outer side) of the join will be returned. In our plan, this means that only the rows read from Ped1 will be returned to the Select operator, but for each row read in Ped1, the loop will look at the Row Count Spool to see if the subquery value exists (i.e. does the spool return a row or not).
SQL Server uses the Row Count Spool operator to avoid reading the Pedido (Ped2) table over and over again. It calls the Clustered Index Scan at the bottom of the execution plan, which returns just one row (or not, if none satisfy the subquery). This row (or rather, it’s existence) is then cached in the Spool, and this cached value is reused for each row of the Ped1 table in the nested loop.
Why is this spool even necessary? Let’s look at a comparison between a plan which uses the row count spool and a plan which doesn’t. As I did in my last article, I’ve written an XML plan to force the Query Optimizer to use my (Row-Count-spool-less) plan, and you can download the query here.
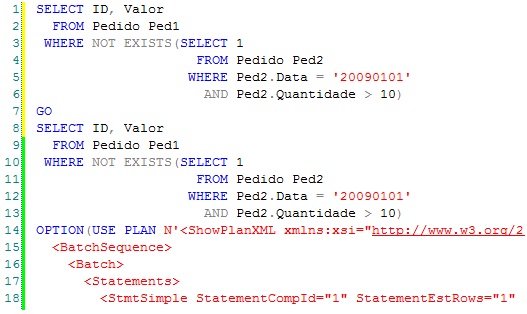
Figure 3. The two comparison queries we’re about to run, one using the row count spool, and one not.
For the queries above, we have the following execution plans:
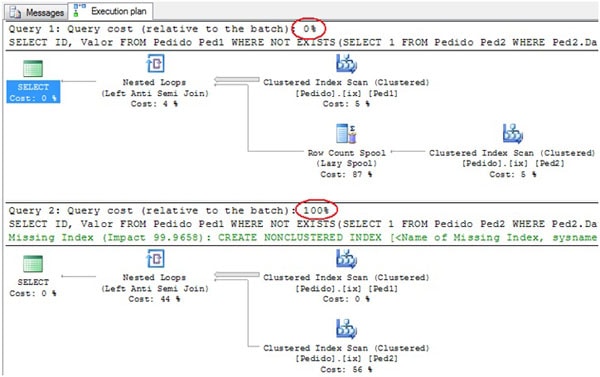
Figure 4. The comparison execution plans, illustrating the huge difference made by the row count spool operator.
Take a look at the differences between the costs of two queries; that seems like pretty strong evidence for the usefulness of the Row Count Spool operator, doesn’t it? By avoiding having to read the Pedido table for each row of the Inner input to the nested loop, SQL Server creates a huge performance gain. Just look at the IO results for the two queries above:
|
1 2 3 4 5 6 7 8 9 |
First Query using Row Count Spool: (15000 row(s) affected) Table 'Pedido'. Scan count 2, logical reads 186, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Second Query using Clustered Index Scan: (15000 row(s) affected) Table 'Pedido'. Scan count 2, logical reads 1395093, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
I’ve nothing else to say about that, because I don’t think there’s much I can add to that kind of compelling evidence. That’s all folks, I hope you’ve enjoyed learning about Spools, and I’ll see you next week with more “Showplan Operators”.
If you missed last week’s thrilling Showplan Operator, you can see it here
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments