
Hello dear readers: We’re once more going to talk about ShowPlan operators. Over the past few weeks and months, we’ve featured the ShowPlan operators that are used by SQL Server to build the query plan. If you’re just getting started with my Showplan series, you can find a list of all my articles so far here.
For quite a while, I’ve wanted to talk about the join operators (loop, merge and hash), but I always wondered whether, if I wrote on this subject, you’d find it interesting. Why should I have thought that? It is because there are already a lot of blog posts and articles on this subject. Despite that, I just couldn’t miss having those operators in my series, so I really hope that you like my approach on this topic. I’ll start by featuring the Merge Join operator. I don’t have to follow the usual order, Loop, Merge and Hash, so I’ll start with the Merge.
Introduction
Once when I was presenting a lecture on this subject, I asked the audience if there was anyone in the room that had a database with only one table. To my surprise, one person raised his hand: I was stunned into silence, to the amusement of the audience.
Simply put, a join is an operation that links one table to another, and SQL Server can use three algorithms to perform this operation, the Loop, Merge and Hash.
The merge join performs an inner join, an outer join or in some cases even a union operation. The merge join is very fast because it requires that both inputs are already sorted by the respective key columns. To do an analogy with the joins I’ll use the same example that I like to show in my presentations.
To illustrate the Merge Join behavior, I’ll start by creating two tables, one called “Cursos” (which means ‘Courses’ in Portuguese) and one table called “Alunos” (which means “Students” in Portuguese). The following script will create the tables and populate them with some garbage data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
USE tempdb GO IF OBJECT_ID('Alunos') IS NOT NULL BEGIN DROP TABLE Alunos DROP TABLE Cursos END GO CREATE TABLE Cursos (ID_Cursos INT PRIMARY KEY, Nome_Curso VARCHAR(80)) CREATE TABLE Alunos (ID_Alunos INT PRIMARY KEY, Nome_Aluno VARCHAR(80), ID_Cursos INT) Y, Nome_Curso VARCHAR(80)) GO INSERT INTO Cursos (ID_Cursos, Nome_Curso) VALUES (1, 'Medicina') INSERT INTO Cursos (ID_Cursos, Nome_Curso) VALUES (2, 'Educação FÃsica') INSERT INTO Cursos (ID_Cursos, Nome_Curso) VALUES (3, 'Sistemas de Informação') INSERT INTO Cursos (ID_Cursos, Nome_Curso) VALUES (4, 'Engenharia') INSERT INTO Cursos (ID_Cursos, Nome_Curso) VALUES (5, 'FÃsica Quantica') INSERT INTO Cursos (ID_Cursos, Nome_Curso) VALUES (6, 'Paisagismo') GO INSERT INTO Alunos (ID_Alunos, Nome_Aluno, ID_Cursos) VALUES (1, 'Fabiano Amorim', 2) INSERT INTO Alunos (ID_Alunos, Nome_Aluno, ID_Cursos) VALUES (2, 'Laerte Junior', 6) INSERT INTO Alunos (ID_Alunos, Nome_Aluno, ID_Cursos) VALUES (3, 'Fabricio Catae', 5) INSERT INTO Alunos (ID_Alunos, Nome_Aluno, ID_Cursos) VALUES (4, 'Thiago Zavaschi', 3) INSERT INTO Alunos (ID_Alunos, Nome_Aluno, ID_Cursos) VALUES (5, 'Diego Nogare', 4) INSERT INTO Alunos (ID_Alunos, Nome_Aluno, ID_Cursos) VALUES (6, 'Rodolfo Roim', 3) INSERT INTO Alunos (ID_Alunos, Nome_Aluno, ID_Cursos) VALUES (7, 'Rodrigo Fernandes', 5) INSERT INTO Alunos (ID_Alunos, Nome_Aluno, ID_Cursos) VALUES (8, 'Nilton Pinheiro', 4) |
This is what the data looks like:
|
1 |
SELECT * FROM Alunos SELECT * FROM Cursos |
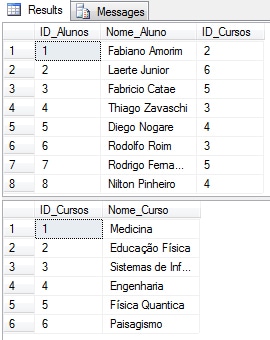
As you can see, in the table Alunos I’ve a column ID_Cursos that links to the Course that the Student is signed up for.
Now you know about the tables and the data. Before we go on with the script stuff, I’d like to show you a picture with the same tables but using something that we are more used to seeing in our real life.

I’m sure you already saw one of this card indexes in a movie rental store, a library, your dental clinic or even in your college. Before databases became commonplace, this kind of material was very popular and very useful, but in the past few years we have evolved IT systems (thanks to God for that) and now we don’t need to store our customers’ info into this kind of table since we have SQL Server to do that job.
You’ll notice that the card index Cursos is sorted by ID_Curso and the card index Alunos is ordered by Name.
If you are using the card index and I ask you “Please, could you tell me what is the Fabiano’s course?” , what is the first thing you have to do? First of all you have to scan the Aluno’s card index to find record with the info about the student Fabiano, then you have to look at the field ID_Cursos to know the number of the course, finally you have to search at the card index Cursos to find the course relative to the ID you found into the Aluno’s card.
You just did a join!
Now what if I change my question to this? ‘Please, can you give me the details about all students and all their courses? ‘. What would you have to do then?
One alternative would entail starting to scan the card index of courses and, for each course you read, you scan the card index for the students that relate to the course, and you would repeat until all the courses are read. That means that, for each course, you would have to scan the whole card index with the students’ info.
Now, can you tell me what will happen if, before we start the process of reading the students card index, I manually re-order the student card index from the Student Name to ID_Cursos order?
If I do this, I can just read one Course (which is already sorted by ID_Cursos) and read just a small part of the Students card index, because now the ID_Cursos = 1 will be the first occurrence I’ll read in the Course card, and the ID_Course = 1 will also be the first card in the Students card index. Did you understand that you don’t need to scan the Students card index anymore?
This is exactly what SQL Server does with the Merge Join algorithm, it takes advantage of the column orders and performs a very fast join. It will read the rows and, if one of inputs get to the end, it just stops the read, because that means that all possible rows have been joined.
Sort Merge Join
As you can see, both sides of the join must be sorted by the key columns before you can use the Merge Join. Sometimes the Query Optimizer can explicitly force a sort operator to precede the merge join operator, or it can read the rows from an index that is already sorted in the expected order.
The following query is using a hint to force the use of the merge join operator.
|
1 2 3 4 |
SELECT Alunos.Nome_Aluno, Cursos.Nome_Curso FROM Alunos INNER JOIN Cursos ON Alunos.ID_Cursos = Cursos.ID_Cursos OPTION (MERGE JOIN) |
For the query above we’ve the following execution plan:
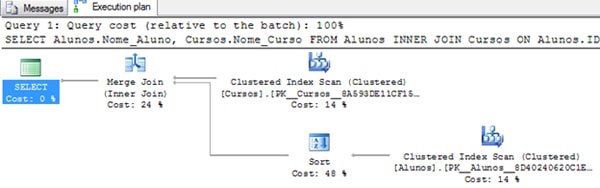
You can see in the execution plan that the Query Optimiser explicitly sorted the table Alunos by the ID_Cursos column so as to use the Merge Join , and the highest cost of the query is the Sort operator.
We could avoid this step just by creating an index into the table Alunos by the ID_Cursos column. The following creates the index:
|
1 |
CREATE NONCLUSTERED INDEX ix_ID_Curso ON Alunos(ID_Cursos) |
Now let’s look at the execution plan again.
|
1 2 3 4 |
SELECT Alunos.Nome_Aluno, Cursos.Nome_Curso FROM Alunos INNER JOIN Cursos ON Alunos.ID_Cursos = Cursos.ID_Cursos OPTION (MERGE JOIN) |
For the query above we’ve the following execution plan:
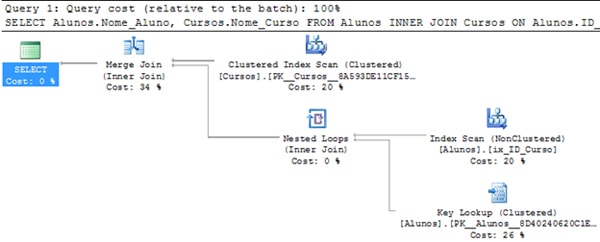
Wow no! Now the plan is using the index and we don’t need the sort anymore, but we got a plan using a Key Lookup Operator. Yes, that’s happened because we are asking for the Cursos.Nome_Curso column, and we didn’t include the column into the index, so let’s try creating a new index including the column Nome_Curso.
|
1 |
CREATE NONCLUSTERED INDEX ix_ID_Curso_Nome_Aluno ON Alunos(ID_Cursos) INCLUDE (Nome_Aluno) |
Let’s look at the execution plan again.
|
1 2 3 4 |
SELECT Alunos.Nome_Aluno, Cursos.Nome_Curso FROM Alunos INNER JOIN Cursos ON Alunos.ID_Cursos = Cursos.ID_Cursos OPTION (MERGE JOIN) |
For the query above we’ve the following execution plan:
Now, everything is perfect.
Residual Predicate
Another thing that the Query Optimiser can do, using the Merge Join operator, is to filter a new predicate into the Merge that is not part of the join of the tables, for instance:
|
1 2 3 4 5 |
SELECT Alunos.Nome_Aluno, Cursos.Nome_Curso FROM Alunos LEFT OUTER JOIN Cursos ON Alunos.ID_Cursos = Cursos.ID_Cursos AND Alunos.Nome_Aluno LIKE 'F%' OPTION (MERGE JOIN) |
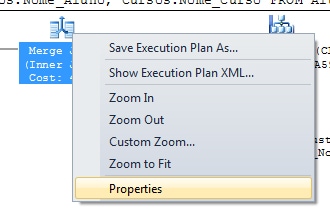
After checking whether rows from Alunos join with Cursos, SQL Server can also check whether the Nome_Aluno starts with the letter F. To see the residual predicate you can click with the right button on the Merge join Operator and then select ‘Properties’.

One to Many and Many to Many Merge Join
To show you this concept of One to Many, I would like to present a pseudo code of the merge join algorithm. All credits to Craig Freedman that wrote this code into his book.
The code is the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Get first row Cursos from input 1 Get first row Alunos from input 2 While not at the end of either input Begin If Cursos joins with Alunos Begin Output(Cursos, Alunos) Get next row Alunos from input 2 end else if Cursos < Alunos get next row Cursos from input 1 else get next row Alunos form input 2 end |
This is a very interesting code and this code works just for the One to Many joins (read more about it here).
When the Merge Join operator was executed using the Many to One algorithm you can see what happened when the property “Many to Many” of the operator is false. To see the “many to many” property you can click with the right button into the Merge join Operator and then select ‘Properties’.

Finally
I would like to thank you in advance, and ask you to write a comment giving your thoughts on this article, in my last article I received very good comments, and I really appreciate all your feedback, so please keep then coming.
That’s all folks, I hope you’ve enjoyed learning about the Merge Join operator, and I’ll see you soon with more “Showplan Operators”.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




Load comments