
It’s time to talk about a film star amongst operators: Key Lookup is such a famous operator that I couldn’t write about it without giving it the red carpet treatment.
Get yourself comfortable, grab some popcorn, and relax. I realize that you know this smooth operator, but I hope you discover something new about Key Lookup behavior and learn some good tips here. I hope to give you a fuller understanding of the Bookmark/Key Lookup by the time you finish the article.
As if seeking anonymity, this operator has changed its identity three times in the last three versions of SQL Server. In SQL 2000 it was called BookMark Lookup: SQL 2005 comes, and it was renamed and showed as a simple “Clustered Index Seek” operation: Since SQL Server 2005 SP2 it has been called a Key Lookup, which makes more sense to me. In a text execution plan, it is represented as a “Clustered Index Seek“.
First, I’ll explain a bit about the way that SQL Server uses an index, and why unordered bookmark operations are so very expensive. I’ll also create a procedure to return some information about when lookup operations are good, and when a scan turns out to be better than a lookup.

Icon at SQL Server 2000

Icon at SQL Server 2005 SP2 and 2008
Before you get distracted into thinking about RIDs/Heaps, let me say one thing, I’ll be talking about RID Lookup at another opportunity. The main focus here is about the Key Lookup operator.
In summary, the Key Lookup is used to fetch values via a clustered index, when the required data isn’t in a non-clustered index. Let’s take a look further.
I once heard Kimberly Tripp give a very good and practical analogy: Think about a Book and suppose we have two indexes, the first is a clustered index, the Contents, that appears in beginning of the book; and the non-clustered is the index in the back of a book. When you need to search for some information in the index at the back, you have a pointer, the page number, to the page that mentions the subject. This “page number” is what we call a BookMark, in SQL terms, that is the Cluster Key.
This BookMark action goes to the ‘back’ index, finds the page number that contains the information, and goes to the page. This is what a “bookmark lookup” does.
Suppose I want to know more about “bookmark lookups”; well, since I have the “Inside Microsoft SQL Server 2005 – Query Tuning and Optimization” book, I can go to the back index and see if there is information somewhere in the book. At the “B” word I have a text “BookMark Lookup” and the number of the page that talks about the subject. The index at the end of the book is a very useful.
But wait a minute, there is a snag. A Key lookup is a very expensive operation because it performs a random I/O into the clustered index. For every row of the non-clustered index, SQL Server has to go to the Clustered Index to read their data. We can take advantage of knowing this to improve the query performance. To be honest, when I see an execution plan that is using a Key Lookup it makes me happy, because I know I’ve a good chance of improving the query performance just creating a covering index. A Covering index is a non-clustered ‘composite’ index which contains all columns required by the query.
Let’s demonstrate this with some code.
The following script will create a table called TestTable and will insert 100000 rows with garbage data. An index called ix_Test will be created to be used in our lookup samples.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
IF OBJECT_ID('TestTable') IS NOT NULL BEGIN DROP TABLE TestTable END GO CREATE TABLE TestTable(ID Int Identity(1,1) PRIMARY KEY, Col1 VarChar(250) NOT NULL DEFAULT NewID(), Col2 VarChar(250) NOT NULL DEFAULT NewID(), Col3 VarChar(250) NOT NULL DEFAULT NewID(), Col4 DateTime NOT NULL DEFAULT GetDate()) GO SET NOCOUNT ON GO INSERT INTO TestTable DEFAULT VALUES GO 100000 CREATE NONCLUSTERED INDEX ix_Test ON TestTable(Col1, Col2, Col3) GO |
Now suppose the following query:
|
1 2 3 4 5 |
SET STATISTICS IO ON SELECT * FROM TestTable WHERE Col1 like 'A%' SET STATISTICS IO OFF |
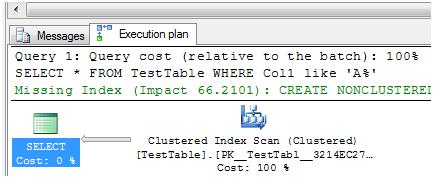
|
1 2 |
(6223 row(s) affected) Table 'TestTable'. Scan count 1, logical reads 1895, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
As we can see in the execution plan above, the Query Optimiser chose not to use the ix_Test index, but instead chose to scan the clustered index to return the rows. 6223 rows were returned and SQL made 1895 logical reads to return that data. That means the table had 1895 pages, because SQL made a Scan on the table.
Now, let’s suppose that I don’t trust the Query Optimizer to create a good plan (don’t hit me, but, do you?), and I decide add a hint to say how SQL Server should access the data. What will happen?
|
1 2 3 4 5 |
SET STATISTICS IO ON SELECT * FROM TestTable WITH(INDEX = ix_Test) WHERE Col1 like 'A%' SET STATISTICS IO OFF |
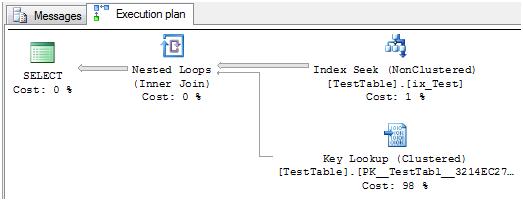
|
1 2 |
(6223 row(s) affected) Table 'TestTable'. Scan count 1, logical reads 19159, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
Here the Key lookup operator is used to read the value of the column Col4 by referencing the clustered index, since that column is not into the non-clustered index ix_Test.
Cool, now our smartest plan uses the index, and return the same 6223 rows, but, wait I minute, it read 19159 pages! In other words, it has read 17264 more than the first plan, or ten times the table size.
As you can see, a Key Lookup is a good choice only when a few rows are returned; but the retrieval cost grows with the quantity of returned rows. As Jason Massie once said, there is a point where the threshold is crossed and a scan becomes more efficient than a lookup. A scan uses a sequential IO while a lookup does random IO.
Here, we can raise a question. How many rows before a key lookup stops being a good strategy? When is this threshold crossed, and a scan performs better?
To help you with that, I’ve created a procedure called st_TestLookup: You can download the code here or click on the speech-bubble at the top of the page. I’ll not explain what I did, because this is not the intention, but you need to enable xp_cmdShell to run this code so, obviously, I don’t recommend that you to run this in a production environment.
The code below runs the procedure to TestTable, the input parameters are three. @Table_Name where you input the table that you want to analyze, @Lookup_Index where you input the nonclustered index that will be analyzed and a valid Path to SQL Server create a profiler trace to check the amount of logical IOs for each query.
Let’s look at the results.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
EXEC dbo.st_TestLookup @Table_Name = 'TestTable', @Lookup_Index = 'ix_Test', @Trace_Path = 'C:\TesteTrace.trc' GO Logical Reads to Scan 100000 rows of table TestTable: 1902 GoodPlan - Logical Reads to Lookup 100 rows of table : 339 GoodPlan - Logical Reads to Lookup 200 rows of table : 659 GoodPlan - Logical Reads to Lookup 300 rows of table : 981 GoodPlan - Logical Reads to Lookup 400 rows of table : 1301 GoodPlan - Logical Reads to Lookup 500 rows of table : 1620 BadPlan - Logical Reads to Lookup 600 rows of table : 1940 ******************* Scan *** ****** ********* ************* **************** ******************* |
The first result line shows us how many rows are in the table, and how many logical reads are used to scan the table. This is our start point: Based on that value, I then do a loop, reading values of the table. When the number of lookup IOs cross the Scan, I write a line starting with “BadPlan”, and I show the number of IOs to read “x” rows using the Key Lookup operator.
The lines with “*” is just a tentative to show these results in a graphical mode.
Based on the procedure results, we know that when we need more than 600 rows, a Scan is better than a Lookup.
That’s all folks, I see you next week with more “Showplan Operators”.
Cheers.
If you missed last week’s thrilling Showplan Operator, Compute Scalar, you can see it here
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments