
The purpose of this series of workshops is to try to encourage you to take a practical approach to SQL skills. I always find I learn things much quicker by trying things out and experimenting. Please don’t just run the samples, but make changes, alter the data, look for my mistakes, try to see if there are different ways of doing things. Please feel free to criticize or disagree with what I say, if you can back this up. This workbench on cursors is not intended to tell you the entire story, as a tutorial might, but the details on BOL should make much more sense after you’ve tried things out for yourself!
Contents
- What are cursors for?
- Where would you use a cursor?
- Global cursors
- Are Cursors Slow?
- Cursor Variables
- Cursor Optimisation
- Questions
- Acknowledgements
What are cursors for?
Cursors were created to bridge the ‘impedence mismatch’ between the ‘record- based’ culture of conventional programming and the set-based world of the relational database.
They had a useful purpose in allowing existing applications to change from ISAM or KSAM databases, such as DBaseII, to SQL Server with the minimum of upheaval. DBLIB and ODBC make extensive use of them to ‘spoof’ simple file-based data sources.
Relational database programmers won’t need them but, if you have an application that understands only the process of iterating through resultsets, like flicking through a card index, then you’ll probably need a cursor.
Where would you use a Cursor?
An simple example of an application for which cursors can provide a good solution is one that requires running totals. A cumulative graph of monthly sales to date is a good example, as is a cashbook with a running balance.
We’ll try four different approaches to getting a running total…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 |
/*so let's build a very simple cashbook */ CREATE TABLE #cb ( cb_ID INT IDENTITY(1,1),--sequence of entries 1..n Et VARCHAR(10), --entryType amount money)--quantity INSERT INTO #cb(et,amount) SELECT 'balance',465.00 INSERT INTO #cb(et,amount) SELECT 'sale',56.00 INSERT INTO #cb(et,amount) SELECT 'sale',434.30 INSERT INTO #cb(et,amount) SELECT 'purchase',20.04 INSERT INTO #cb(et,amount) SELECT 'purchase',65.00 INSERT INTO #cb(et,amount) SELECT 'sale',23.22 INSERT INTO #cb(et,amount) SELECT 'sale',45.80 INSERT INTO #cb(et,amount) SELECT 'purchase',34.08 INSERT INTO #cb(et,amount) SELECT 'purchase',78.30 INSERT INTO #cb(et,amount) SELECT 'purchase',56.00 INSERT INTO #cb(et,amount) SELECT 'sale',75.22 INSERT INTO #cb(et,amount) SELECT 'sale',5.80 INSERT INTO #cb(et,amount) SELECT 'purchase',3.08 INSERT INTO #cb(et,amount) SELECT 'sale',3.29 INSERT INTO #cb(et,amount) SELECT 'sale',100.80 INSERT INTO #cb(et,amount) SELECT 'sale',100.22 INSERT INTO #cb(et,amount) SELECT 'sale',23.80 /* You don't actually need a cursor. You can get a running total using a correlated subquery */ SELECT [Entry Type]=Et, amount, [balance after transaction]=( SELECT SUM(--the correlated subquery CASE WHEN total.Et='purchase' THEN -total.amount ELSE total.amount END) FROM #cb total WHERE total.cb_id <= #cb.cb_id ) FROM #cb ORDER BY #cb.cb_id --or you can do this simple inner join and group-by clause if you don't --like correlated subqueries SELECT [Entry Type]=MIN(#cb.Et), [amount]=MIN (#cb.amount), [balance after transaction]= SUM(CASE WHEN total.Et='purchase' THEN -total.amount ELSE total.amount END) FROM #cb total INNER JOIN #cb ON total.cb_id <= #cb.cb_id GROUP BY #cb.cb_id ORDER BY #cb.cb_id --and here is a very different technique that takes advantege --of the quirky behavionr of SET in an UPDATE command in SQL Server DECLARE @cb TABLE(cb_ID INT,--sequence of entries 1..n Et VARCHAR(10), --entryType amount money,--quantity total money) DECLARE @total money SET @total = 0 INSERT INTO @cb(cb_id,Et,amount,total) SELECT cb_id,Et,CASE WHEN Et='purchase' THEN -amount ELSE amount END,0 FROM #cb order by cb_id UPDATE @cb SET @total = total = @total + amount FROM @cb SELECT [Entry Type]=Et, [amount]=amount, [balance after transaction]=total FROM @cb ORDER BY cb_id -- or you can give up trying to do it a set-based way and -- iterate through the table DECLARE @ii INT, @iiMax INT, @CurrentBalance money DECLARE @Runningtotals TABLE (cb_id INT, Total money) SELECT @ii=MIN(cb_id), @iiMax=MAX(cb_id),@CurrentBalance=0 FROM #cb WHILE @ii<=@iiMax BEGIN SELECT @currentBalance=@currentBalance +CASE WHEN Et='purchase' THEN -amount ELSE amount END FROM #cb WHERE cb_ID=@ii INSERT INTO @runningTotals(cb_id, Total) SELECT @ii,@currentBalance SELECT @ii=@ii+1 END SELECT[Entry Type]=Et,amount,total FROM #cb INNER JOIN @Runningtotals r ON #cb.cb_id=r.cb_id /* or alternatively you can use...... ----------....A CURSOR!!! the use of a cursor will normally involve a DECLARE, OPEN, several FETCHs, a CLOSE and a DEALLOCATE */ SET Nocount ON DECLARE @Runningtotals TABLE (cb_id INT, Et VARCHAR(10), --entryType amount money, Total money) DECLARE @CurrentBalance money, @Et VARCHAR(10), @amount money --Declare the cursor --declare current_line cursor -- SQL-92 syntax--only scroll forward DECLARE current_line CURSOR fast_forward--SQL Server only--only scroll forward FOR SELECT Et,amount FROM #cb ORDER BY cb_id FOR READ ONLY --now we open the cursor to populate any temporary tables (in the case of -- cursors) etc.. --Cursors are unusual because they can be made GLOBAL to the connection. OPEN current_line --fetch the first row FETCH NEXT FROM current_line INTO @Et,@amount WHILE @@FETCH_STATUS = 0--whilst all is well BEGIN SELECT @CurrentBalance = COALESCE(@CurrentBalance,0) +CASE WHEN @Etyle="COLOR: blue">='purchase' THEN -@amount ELSE @amount END INSERT INTO @Runningtotals (Et, amount,Total) SELECT @Et,@Amount,@CurrentBalance -- This is executed as long as the previous fetch succeeds. FETCH NEXT FROM current_line INTO @Et,@amount END SELECT [Entry Type]=Et,amount,Total FROM @Runningtotals ORDER BY cb_id CLOSE current_line--Do not forget to close when its result set is not needed. --especially a global updateable cursor! DEALLOCATE current_line -- although the Cursor code looks bulky and complex, on small tables it will -- execute just as quickly as a simple iteration, and will be faster with tables -- of any size if you forget to put an index on the table through which you're -- iterating! -- The first two solutions are faster with small tables but slow down -- exponentially as the table size grows. /* here is the result of all the routines above Entry Type amount balance after transaction ---------- --------------------- ------------------------- balance 465.00 465.00 sale 56.00 521.00 sale 434.30 955.30 purchase 20.04 935.26 purchase 65.00 870.26 sale 23.22 893.48 sale 45.80 939.28 purchase 34.08 905.20 purchase 78.30 826.90 purchase 56.00 770.90 sale 75.22 846.12 sale 5.80 851.92 purchase 3.08 848.84 sale 3.29 852.13 sale 100.80 952.93 sale 100.22 1053.15 sale 23.80 1076.95 */ |
Why not try these different approaches, with tables of different sizes and see how long the routines take? (I demonstrate a suitable test-rig shortly).
Is there a quicker or more elegant solution?
Global Cursors
If you are doing something really complicated with a listbox, or scrolling through a rapidly-changing table whilst making updates, a GLOBAL cursor could be a good solution, but is is very much geared for traditional client-server applications, because cursors have a lifetime only of the connection. Each ‘client’ therefore needs their own connection. The GLOBAL cursors defined in a connection will be implicitly deallocated at disconnect.
Global Cursors can be passed too and from stored procedure and referenced in triggers. They can be assigned to local variables. A global cursor can therefore be passed as a parameter to a number of stored procedures Here is an example, though one is struggling to think of anything useful in a short example.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
CREATE PROCEDURE spReturnEmployee ( @EmployeeLastName VARCHAR(20), @MyGlobalcursor CURSOR VARYING OUTPUT ) AS BEGIN SET NOCOUNT ON SET @MyGlobalcursor = CURSOR STATIC FOR SELECT lname, fname FROM pubs.dbo.employee WHERE lname = @EmployeeLastName OPEN @MyGlobalcursor END . DECLARE @FoundEmployee CURSOR, @LastName VARCHAR(20), @FirstName VARCHAR(20) EXECUTE spReturnEmployee 'Lebihan', @FoundEmployee OUTPUT --see if anything was found --note we are careful to check the right cursor! IF CURSOR_STATUS('variable', '@FoundEmployee') = 0 SELECT 'no such employee' ELSE BEGIN FETCH NEXT FROM @FoundEmployee INTO @LastName, @FirstName SELECT @FirstName+' '+@LastName END CLOSE @FoundEmployee DEALLOCATE @FoundEmployee |
Transact-SQL cursors are efficient when contained in stored procedures and triggers. This is because everything is compiled into one execution plan on the server and there is no overhead of network traffic whilst fetching rows.
Are Cursors Slow?
So what really are the performance differences? Let’s set up a test-rig. We’ll give each routine an increasingly big cashbook to work on up to 2 million rows, and give it a task that doesn’t disturb SSMS/Query analyser too much with a large result, so we can measure just the performance of each algorithm. We’ll put the timings into a table that we can put into excel and run a pivot on to do the analysis.
We’ll calculate the average balance, and the highest and lowest balance so as to check that the results of each method agree.
Now, which solution is going to be the best?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 |
------------------------------------------------------------------------ -- Test harness ------------------------------------------------------------------------ --declare the local variables DECLARE @ii INT, @iiMax INT, @CurrentBalance MONEY DECLARE @Et VARCHAR(10), @amount MONEY --and clean up the harness from the last run. IF EXISTS (SELECT * FROM tempdb.INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME LIKE '#Events[_]%') DROP TABLE #Events IF EXISTS (SELECT * FROM tempdb.INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME LIKE '#TableSizes[_]%') DROP TABLE #TableSizes IF EXISTS (SELECT * FROM tempdb.INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME LIKE '#TempCB[_]%') DROP TABLE #TempCB IF EXISTS (SELECT * FROM tempdb.INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME LIKE '#RunningTotals[_]%') DROP TABLE #RunningTotals --Firstly, we'll make a table to record our results for each table size CREATE TABLE #Events (Event_ID INT IDENTITY(1,1),--sequence of Events 1..n [Event] VARCHAR(50) NOT NULL, --The Event we're recording [method] VARCHAR(50) NOT NULL, --the algorithm we are using TableSize INT NOT NULL, Time DATETIME DEFAULT GETDATE())--The moment that it happened CREATE TABLE #tempcb (cb_ID INT,--sequence of entries 1..n Et VARCHAR(10), --entryType amount MONEY,--quantity total MONEY) DECLARE @total MONEY CREATE TABLE #Runningtotals (cb_id INT, Total MONEY) --now, we'll have a table of the table sizes that we want CREATE TABLE #TableSizes (TableSize_ID INT IDENTITY(1,1),--TableSizes to try out with TableSize INT NOT NULL ) --and fill them with the table sizes we'll be using. (Change to taste) INSERT INTO #tablesizes (TableSize) SELECT 20 UNION SELECT 200 UNION SELECT 2000 UNION SELECT 20000 union select 200000 union select 2000000 DECLARE @tablesizeRow INT,@maxTableSizeRow INT,@TableSize INT SELECT @tablesizeRow = MIN(TableSize_ID), @maxTableSizeRow = MAX(TableSize_ID) FROM #Tablesizes WHILE @tablesizeRow <= @maxTableSizeRow BEGIN --firstly, get the number of rows SELECT @TableSize = tablesize FROM #tablesizes WHERE TableSize_ID = @TablesizeRow SELECT @TablesizeRow = @TablesizeRow + 1 --Delete the cashbook! IF EXISTS ( SELECT * FROM tempdb.INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME LIKE '#cb[_]%' ) DROP TABLE #cb --create a new randomly-generated cashbook table. CREATE TABLE #cb ( cb_ID INT IDENTITY(1, 1), Et VARCHAR(10), --entryType amount MONEY )--quantity INSERT INTO #cb (et, amount) SELECT 'balance', 465.00 SELECT @ii = 0 WHILE @ii <= @TableSize BEGIN INSERT INTO #cb (et, amount) SELECT CASE WHEN RAND() < 0.5 THEN 'sale' ELSE 'purchase' END, CAST(RAND() * 180.00 AS MONEY) SELECT @ii = @ii + 1 END --and put an index on it CREATE CLUSTERED INDEX idxcbid ON #cb (cb_id) CREATE INDEX covering ON #cb (cb_id, et, amount) --first try the correlated subquery approach... IF @TableSize < 200000 --they run out of steam pretty soon. BEGIN INSERT INTO #Events (method, event, tablesize) SELECT 'Correlated Subquery', 'start', @TableSize SELECT 'correlated subquery', MIN(g.balance), AVG(g.balance), MAX(g.balance) FROM (SELECT [balance] = (SELECT SUM(--the correlated subquery CASE WHEN total.Et = 'purchase' THEN -total.amount ELSE total.amount END) FROM #cb total WHERE total.cb_id <= #cb.cb_id ) FROM #cb) g --then we'll do the 'group by and inner join' INSERT INTO #Events (method, event, tablesize) SELECT 'group by', 'start', @TableSize SELECT 'Group by...', MIN(f.balance), AVG(f.balance), MAX(f.balance) FROM (SELECT [balance] = SUM(CASE WHEN total.Et = 'purchase' THEN -total.amount ELSE total.amount END) FROM #cb total INNER JOIN #cb ON total.cb_id <= #cb.cb_id GROUP BY #cb.cb_id ) f END ---end of the slow section -- Now let's try the "quirky" technique using SET INSERT INTO #Events (method, event, tablesize) SELECT 'Quirky Update', 'start', @TableSize SET @total = 0 TRUNCATE TABLE #TEMPCB INSERT INTO #TempCb (cb_id, Et, amount, total) SELECT cb_id, Et, CASE WHEN Et = 'purchase' THEN -amount ELSE amount END, 0 FROM #cb order by cb_id UPDATE #TempCb SET @total = total = @total + amount SELECT 'quirky Update', MIN(Total), AVG(Total), MAX(Total) FROM #TempCb -- now the simple iterative solution INSERT INTO #Events (method, event, tablesize) SELECT 'Iterative Solution', 'start',@TableSize SELECT @ii = MIN(cb_id), @iiMax = MAX(cb_id), @CurrentBalance = 0 FROM #cb TRUNCATE TABLE #RunningTotals WHILE @ii <= @iiMax BEGIN SELECT @currentBalance = @currentBalance + CASE WHEN Et = 'purchase' THEN -amount ELSE amount END FROM #cb WHERE cb_ID = @ii INSERT INTO #runningTotals (cb_id, Total) SELECT @ii, @currentBalance SELECT @ii = @ii + 1 END SELECT 'iterative method', MIN(Total), AVG(Total), MAX(Total) FROM #Runningtotals -- now the simple iterative solution INSERT INTO #Events (method, event, tablesize) SELECT 'Cursor Solution', 'start', @TableSize --Declare the cursor --declare current_line cursor -- SQL-92 syntax ---scroll forward only DECLARE current_line CURSOR fast_forward--SQL Server only ---scroll forward FOR SELECT cb_id, Et, amount FROM #cb ORDER BY cb_id FOR READ ONLY TRUNCATE TABLE #Runningtotals --now we open the cursor to populate any temporary tables OPEN current_line --fetch the first row FETCH NEXT FROM current_line INTO @ii, @Et, @amount SELECT @currentBalance = 0 WHILE @@FETCH_STATUS = 0--whilst all is well BEGIN SELECT @CurrentBalance = COALESCE(@CurrentBalance,0) + CASE WHEN @Et = 'purchase' THEN -@amount ELSE @amount END INSERT INTO #runningTotals (cb_id, Total) SELECT @ii, @currentBalance -- This is executed as long as the previous fetch succeeds. FETCH NEXT FROM current_line INTO @ii, @Et, @amount END CLOSE current_line--Do not forget to close DEALLOCATE current_line SELECT 'cursor method', MIN(Total), AVG(Total), MAX(Total) FROM #Runningtotals INSERT INTO #Events (method, event, tablesize) SELECT 'Test Run', 'End', 0 END --Now it is all done, get a report of the findings SELECT method, Tablesize, DATEDIFF(ms, Time, (SELECT time FROM #events [next] WHERE next . event_ID = this . Event_ID + 1 ) ) [Duration(ms)] FROM #Events AS [this] WHERE event = 'start' ------------------------------------------------------------------------ -- End of Test harness ------------------------------------------------------------------------ |
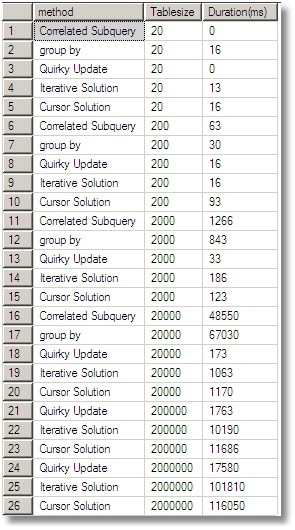
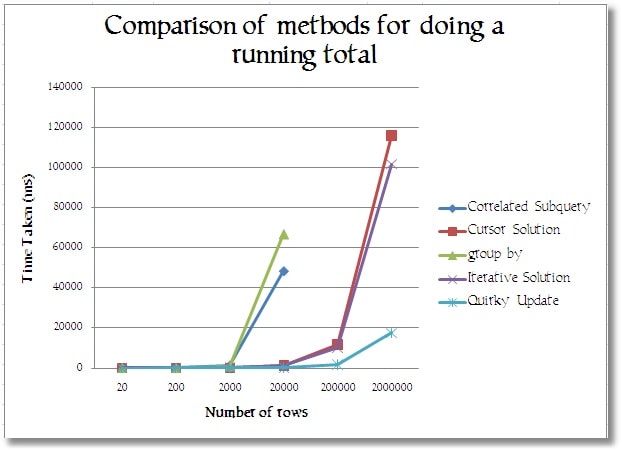
The raw data is shown here. What I have not shown is the check of the results, which shows that every solution gave consistent results.
The iterative and cursor solution both give similar results since, under the covers, they are doing similar things. They are dramatically faster than the ‘correlated subquery’ and ‘group by’ methods as one would expect.
You will see from the graph that we couldn’t even attempt the correlated subquery methods under a ‘production’ table size. It would have taken too long.
Conclusion? If you don’t feel confident about using ‘Quirky Update’ (and it is easy to mess-up, so you have to test it rigorously), then Running totals are best done iteratively, either by the cursor or the WHILE loop. The WHILE loop is more intuitive, but there is no clear reason in favour of one or the other. For almost all work in SQL Server, set-based algorithms work far faster than iterative solutions, but there are a group of problems where this isn’t so. This is one of them. For a good example of another one, see Phil Factor Speed Phreak Challenge #6 – The Stock Exchange Order Book State problem.
Cursor Variables
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
--@@CURSOR_ROWS The number of rows in the cursor --@@FETCH_STATUS Boolean value, success or failure of most recent fetch ---2 if a keyset FETCH returns a deleted row So here is a test harness just to see what the two variables will give at various points. Try changing the cursor type to see what @@Cursor_Rows and @@Fetch_Status returns. It works on our temporary Table */ --Declare the cursor DECLARE @Bucket INT --declare current_line cursor--we only want to scroll forward DECLARE current_line CURSOR keyset --we scroll about (no absolute fetch) /* TSQL extended cursors can be specified [LOCAL or GLOBAL] [FORWARD_ONLY or SCROLL] [STATIC, KEYSET, DYNAMIC or FAST_FORWARD] [READ_ONLY, SCROLL_LOCKS or OPTIMISTIC] [TYPE_WARNING]*/ FOR SELECT 1 FROM #cb SELECT @@FETCH_STATUS, @@CURSOR_ROWS OPEN current_line --fetch the first row FETCH NEXT --NEXT , PRIOR, FIRST, LAST, ABSOLUTE n or RELATIVE n FROM current_line INTO @bucket WHILE @@FETCH_STATUS = 0--whilst all is well BEGIN SELECT @@FETCH_STATUS, @@CURSOR_ROWS FETCH NEXT FROM current_line INTO @Bucket END CLOSE current_line DEALLOCATE current_line /* |
If you change the cursor type definition routine above you’ll notice that @@CURSOR_ROWS returns different values.
- A negative value >1 is the number of rows currently in the keyset. If it is -1 The cursor is dynamic.
- A 0 means that no cursors are open or no rows qualified for the last opened cursor or the last-opened cursor is closed or deallocated.
- A positive integer represents the number of rows in the cursor.
The most important type of cursors are:
- FORWARD_ONLY
- Tou can only go forward in sequence from data source, and changes made to the underlying data source appear instantly.
- DYNAMIC
- Similar to FORWARD_ONLY, but You can access data using any order.
- STATIC
- Rows are returned as ‘read only’ without showing changes to the underlying data source. The data may be accessed in any order.
- KEYSET
- A dynamic data set with changes made to the underlying data appearing instantly, but insertions do not appear.
Cursor Optimization
- Use them only as a last resort. Set-based operations are usually fastest (but not always-see above), then a simple iteration, followed by a cursor
- Make sure that the cursor’s SELECT statement contains only the rows and columns you need
- To avoid the overhead of locks, Use READ ONLY cursors rather than updatable cursors, whenever possible
- Static and keyset cursors cause a temporary table to be created in TEMPDB, which can prove to be slow
- Use FAST_FORWARD cursors, whenever possible, and choose FORWARD_ONLY cursors if you need updatable cursor and you only need to FETCH NEXT.
Questions
- What is the fastest way of calculating a running total in SQL Server? Does that depend on the size of the table?
- what does it suggest if the @@CURSOR_ROWS variable returns a -1?
- What is the scope of a cursor?
- When might you want locking in a cursor? Which would you choose?
- Why wouldn’t the use of a cursor be a good idea for scrolling through a table in a web-based application?
Acknowledgements
Thanks to Nigel Rivett, Phil Factor and Adam Machanic for their ideas. Thanks to Phil Factor for revising this to give a more comprehensive test harness.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved

Load comments