
In SQL Server 2005 and 2008, you can add an OUTPUT clause to your data manipulation language (DML) statements. The clause returns a copy of the data that you’ve inserted into or deleted from your tables. You can return that data to a table variable, a temporary or permanent table, or to the processing application that’s calls the DML statement. You can then use that data for such purposes as archiving, confirmation messaging, or other application requirements.
Both SQL Server 2005 and 2008 let you add an OUTPUT clause to INSERT, UPDATE, or DELETE statements. SQL Server 2008 also lets you add the clause to MERGE statements. In this article, I demonstrate how to include an OUTPUT clause in each one of these statements. I developed the examples used for the article on a local instance of SQL Server 2008. The examples also work in SQL Server 2005, except for those related to the MERGE statement.
If you want to try the examples in this article, you should first run the following script to create the Books table in a SQL Server database:
|
1 2 3 4 5 6 7 8 9 |
IF OBJECT_ID ('Books', 'U') IS NOT NULL DROP TABLE dbo.Books; CREATE TABLE dbo.Books ( BookID int NOT NULL PRIMARY KEY, BookTitle nvarchar(50) NOT NULL, ModifiedDate datetime NOT NULL ); |
The examples are all performed against the Books table. If you run the statements, do so in the order presented in the article, if you want your results to match the results shown here.
Using an OUTPUT Clause in an INSERT Statement
When you insert data into a table, you can use the OUTPUT clause to return a copy of the data that’s been inserted into the table. The OUTPUT clause takes two basic forms: OUTPUT and OUTPUT INTO. Use the OUTPUT form if you want to return the data to the calling application. Use the OUTPUT INTO form if you want to return the data to a table or a table variable.
For most of these examples, I return the outputted data only to a table variable. The process for returning data to a table is the same as that for a variable. If in running these examples, you prefer to return the data to a table instead of a variable, simply create a table with the same columns as the variable, then specify the table rather than the variable in the OUTPUT clause.
NOTE: Returning data to the processing application is even simpler than returning it to a table or variable. As we work through the first example, I’ll point out how that’s done.
In the first example, I declare a table variable named @InsertOutput1 with the same column structure as the Books table. I then insert a row into the Books table and output the inserted data to the variable:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
-- declare @InsertOutput1 table variable DECLARE @InsertOutput1 table ( BookID int, BookTitle nvarchar(50), ModifiedDate datetime ); -- insert new row into Books table INSERT INTO Books OUTPUT INSERTED.* INTO @InsertOutput1 VALUES(101, 'One Hundred Years of Solitude', GETDATE()); -- view inserted row in Books table SELECT * FROM Books; -- view output row in @InsertOutput1 variable SELECT * FROM @InsertOutput1; |
As you can see in the INSERT statement, the OUTPUT clause is placed between the INSERT and VALUES clause. Because I’m outputting the data to a variable, the OUTPUT clause includes two parts: the OUTPUT subclause and the INTO subclause.
The OUTPUT subclause includes the keyword INSERTED, followed a period and asterisk. The keyword is a column prefix that specifies which values to output. The asterisk indicates that all column values inserted into the Books table (BookID, BookTitle, ModifiedDate) should be outputted to the variable.
The INTO subclause defines the table or table variable that the OUTPUT clause targets. In this case, the target is the @InsertOutput1 variable. If you want to return the information to the calling application, rather than the variable (or a table), you simply omit the INTO subclause.
That’s all there is to defining an OUTPUT clause. After the INSERT statement, I include a couple SELECT statements to view the contents of the table and the variable. Because this is the first row inserted into the table, the results returned by both statements are the same, as shown in the following table:
|
BookID |
BookTitle |
ModifiedDate |
|
101 |
One Hundred Years of Solitude |
2010-07-17 12:21:31.300 |
As you can see, the values that were inserted into the Books table are also returned to the @InsertOutput1 variable. You could just as easily have saved the information to a table. Or you could have eliminated the INTO subclause and sent the data to the processing application.
Now let’s look at another example. In the next set of statements, I first declare the @InsertOutput2 table variable with the same column structure as the Books table. Then I insert a second row into the Books table and output the values to the new variable:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
-- declare @InsertOutput2 table variable DECLARE @InsertOutput2 table ( BookID int, BookTitle nvarchar(50), ModifiedDate datetime ); -- insert new row into Books table INSERT INTO Books OUTPUT INSERTED.BookID, INSERTED.BookTitle, INSERTED.ModifiedDate INTO @InsertOutput2 VALUES(102, 'Pride and Prejudice', GETDATE()); -- view inserted row in Books table SELECT * FROM Books; -- view output row in @InsertOutput2 variable SELECT * FROM @InsertOutput2; |
The primary difference between this INSERT statement and the one in the previous example as that I now use the INSERTED column prefix in the OUTPUT subclause to specify each column (rather than using the asterisk). Notice that I’ve separated the INSERTED column specifications with commas.
Because I inserted a second row into the Books table, the first SELECT statement now returns two rows, as shown in the following results:
|
BookID |
BookTitle |
ModifiedDate |
|
101 |
One Hundred Years of Solitude |
2010-07-17 12:21:31.300 |
|
102 |
Pride and Prejudice |
2010-07-17 12:23:22.100 |
However, because I’m inserting only one row into the Books table, the @InsertOutput2 variable contains only one row. As a result, the second SELECT statement returns only one row, as shown in the following table:
|
BookID |
BookTitle |
ModifiedDate |
|
102 |
Pride and Prejudice |
2010-07-17 12:23:22.100 |
In some cases, you don’t want to output all inserted values, so you must define your OUTPUT clause accordingly. In the next example, I output only the BookID and BookTitle columns:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
-- declare @InsertOutput2 table variable DECLARE @InsertOutput3 table ( BookID int, BookTitle nvarchar(50) ); -- insert new row into Books table INSERT INTO Books OUTPUT INSERTED.BookID, INSERTED.BookTitle INTO @InsertOutput3 VALUES(103, 'The Great Gatsby', GETDATE()); -- view inserted row in Books table SELECT * FROM Books; -- view output row in @InsertOutput3 variable SELECT * FROM @InsertOutput3; |
As before, I first declare a table variable, but this one includes only the BookID and BookTitle columns. Next, I define an INSERT statement, which includes an OUTPUT clause that reflects that only two columns will be outputted. That means, in the OUTPUT subclause, I add only two INSERTED column prefixes and specify the BookID and BookTitle columns.
When you run the example, the first SELECT statement, as expected, returns the three rows shown in the following table:
|
BookID |
BookTitle |
ModifiedDate |
|
101 |
One Hundred Years of Solitude |
2010-07-17 12:21:31.300 |
|
102 |
Pride and Prejudice |
2010-07-17 12:23:22.100 |
|
103 |
The Great Gatsby |
2010-07-17 12:25:25.067 |
However, the second SELECT statement returns only the BookID and BookTitle columns of the newly inserted row:
|
BookID |
BookTitle |
|
103 |
The Great Gatsby |
Now let’s look at another variation on the OUTPUT clause. Once more, I define a table variable (@InsertOutput4) that includes three columns, but this time the columns have different names and are in a different order:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
-- declare @InsertOutput4 table variable DECLARE @InsertOutput4 table ( Title nvarchar(50), TitleID int, TitleAddDate datetime ); -- insert new row into Books table INSERT INTO Books OUTPUT INSERTED.BookID, INSERTED.BookTitle, INSERTED.ModifiedDate INTO @InsertOutput4 (TitleID, Title, TitleAddDate) VALUES(104, 'Mrs. Dalloway', GETDATE()); -- view inserted row in Books table SELECT * FROM Books; -- view output row in @InsertOutput4 variable SELECT * FROM @InsertOutput4; |
Because the target column names and order don’t match the Books table, I add the target column names to the INTO subclause-enclosed in parentheses and separated by commas. The order of the target column names must also correspond to the order in which the columns are being inserted and outputted. As a result, the BookID column is matched to the TitleID column, BookTitle to Title, and ModifiedDate to TitleAddDate.
I then add the SELECT statements to verify the results. The first SELECT statement returns all four rows:
|
BookID |
BookTitle |
ModifiedDate |
|
101 |
One Hundred Years of Solitude |
2010-07-17 12:34:16.467 |
|
102 |
Pride and Prejudice |
2010-07-17 12:34:24.580 |
|
103 |
The Great Gatsby |
2010-07-17 12:34:38.330 |
|
104 |
Mrs. Dalloway |
2010-07-17 12:36:10.237 |
The second SELECT statement returns only the newly inserted row, with the columns names and values as they appear in the @InsertOutput4 variable:
|
Title |
TitleID |
TitleAddDate |
|
Mrs. Dalloway |
104 |
2010-07-17 12:36:10.237 |
You should now have a good sense of how to use an OUTPUT clause in an INSERT statement. Note, however, that most of the principles explained here apply to other DML statements as well, so let’s move on to the UPDATE statement.
Using an OUTPUT Clause in an UPDATE Statement
In the previous examples, the OUTPUT clause includes the INSERTED column prefix in the OUTPUT subclause. However, the OUTPUT clause supports a second column prefix-DELETED. The DELETED prefix returns the values that have been deleted from a table.
This is important because an UPDATE operation is actually two operations-a deletion and an insertion. As a result, you use both the INSERTED and DELETED column prefixes when adding an OUTPUT clause to an UPDATE statement. Let’s look at a few examples to demonstrate how this works.
In the following series of statements, I declare the @UpdateOutput1 variable, delete a row from the Books table, and view the results of that process:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
-- declare @UpdateOutput1 table variable DECLARE @UpdateOutput1 table ( OldBookID int, NewBookID int, BookTitle nvarchar(50), OldModifiedDate datetime, NewModifiedDate datetime ); -- update row in Books table UPDATE Books SET BookID = 105, ModifiedDate = GETDATE() OUTPUT DELETED.BookID, INSERTED.BookID, INSERTED.BookTitle, DELETED.ModifiedDate, INSERTED.ModifiedDate INTO @UpdateOutput1 WHERE BookTitle = 'Mrs. Dalloway'; -- view updated row in Books table SELECT * FROM Books; -- view output row in @UpdateOutput1 variable SELECT * FROM @UpdateOutput1; |
Notice first that the @UpdateOutput1 variable is a bit different from the table variables defined in earlier examples. In this case, we’re capturing the values associated with the update operations-those values that are deleted and those that are inserted. Because I plan to update the BookID and ModifiedDate columns, I want to preserve both the old and new values, along with the BookTitle column, which is not being updated.
After I create the @UpdateOutput1 variable, I define the UPDATE statement. Note that I’ve inserted an OUTPUT clause between the SET and WHERE clauses and that the OUTPUT subclause contains both DELETED and INSERTED column prefixes, separated by commas. I include a DELETED and INSERTED column prefix for each of the two columns I’m updating and an INSERTED column prefix for the column that will remain unchanged. The INTO subclause specifies the table variable, as you saw in previous examples.
When you run the first SELECT statement, the Books table should reflect the modified values, as shown in the following results:
|
BookID |
BookTitle |
ModifiedDate |
|
101 |
One Hundred Years of Solitude |
2010-07-17 12:34:16.467 |
|
102 |
Pride and Prejudice |
2010-07-17 12:34:24.580 |
|
103 |
The Great Gatsby |
2010-07-17 12:34:38.330 |
|
105 |
Mrs. Dalloway |
2010-07-17 12:36:10.237 |
As you can see, the BookID and ModifiedDate values have changed for the Mrs. Dalloway row. The second SELECT statement shows the specifics of the modifications, as they’ve been returned to the @UpdateOutput1 variable:
|
OldBookID |
NewBookID |
BookTitle |
OldModifiedDate |
NewModifiedDate |
|
104 |
105 |
Mrs. Dalloway |
2010-07-17 13:09:10.580 |
2010-07-17 13:09:39.683 |
When you specify the column prefixes in your OUTPUT subclause, you can create an expression that uses the prefixes to calculate a value. For instance, in the following example, I calculate the difference between the old and new ModifiedDate values:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
-- declare @UpdateOutput1 table variable DECLARE @UpdateOutput2 table ( OldBookID int, NewBookID int, BookTitle nvarchar(50), OldModifiedDate datetime, NewModifiedDate datetime, DiffInSeconds int ); -- update row in Books table UPDATE Books SET BookID = BookID + 1, ModifiedDate = GETDATE() OUTPUT DELETED.BookID, INSERTED.BookID, INSERTED.BookTitle, DELETED.ModifiedDate, INSERTED.ModifiedDate, DATEDIFF(ss, DELETED.ModifiedDate, INSERTED.ModifiedDate) INTO @UpdateOutput2 WHERE BookTitle = 'Mrs. Dalloway'; -- view updated row in Books table SELECT * FROM Books; -- view output row in @UpdateOutput2 variable SELECT * FROM @UpdateOutput2; |
The example is different from the previous example in a couple ways. First, the table variable includes an extra field (DiffInSeconds) to show the difference in seconds between the two modified dates. Next, the OUTPUT subclause includes an additional column definition in which the DATEDIFF function is used to calculate the difference between the deleted and inserted modified dates.
Once again, the first SELECT statement returns the content of the Books table, after the last row has been modified:
|
BookID |
BookTitle |
ModifiedDate |
|
101 |
One Hundred Years of Solitude |
2010-07-17 12:34:16.467 |
|
102 |
Pride and Prejudice |
2010-07-17 12:34:24.580 |
|
103 |
The Great Gatsby |
2010-07-17 12:34:38.330 |
|
106 |
Mrs. Dalloway |
2010-07-17 12:36:10.237 |
The results from the second SELECT statement show the DiffInSeconds column, which reflects the difference in seconds between the two updates:
|
OldBookID |
NewBookID |
BookTitle |
OldModifiedDate |
NewModifiedDate |
DiffInSeconds |
|
105 |
106 |
Mrs. Dalloway |
2010-07-17 13:20:34.787 |
2010-07-17 13:21:26.753 |
52 |
Once you understand how to use the OUTPUT clause in an UPDATE statement, you can see that you have all the elements necessary to add an OUTPUT clause to a DELETE statement, so let’s look at how that works.
Using an OUTPUT Clause in a DELETE Statement
In a DELETE statement, you add the OUTPUT clause between the DELETE and WHERE clauses. The following set of statements declare the @DeleteOutput1 table variable, delete a row from the Books table, and verifies the deletion:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
-- declare @DeleteOutput1 table variable DECLARE @DeleteOutput1 table ( BookID int, BookTitle nvarchar(50), ModifiedDate datetime ); -- delete row in Books table DELETE Books OUTPUT DELETED.* INTO @DeleteOutput1 WHERE BookID = 106; -- view updated row in Books table SELECT * FROM Books; -- view output row in @DeleteOutput1 variable SELECT * FROM @DeleteOutput1; |
There’s nothing new about the @DeleteOutput1 table variable. I declare it with the same table structure used in the Books table, as you saw in previous examples.
In the DELETE statement, the OUTPUT subclause uses the asterisk with the DELETED column prefix to indicate that all columns should be outputted to the @DeleteOutput1 variable. The first SELECT statement returns the following results:
|
BookID |
BookTitle |
ModifiedDate |
|
101 |
One Hundred Years of Solitude |
2010-07-17 13:09:10.573 |
|
102 |
Pride and Prejudice |
2010-07-17 13:09:10.577 |
|
103 |
The Great Gatsby |
2010-07-17 13:09:10.580 |
As you can see, the last row has been deleted from the table. The second SELECT statement confirms that the deleted row has been returned to the @DeleteOutput1 variable:
|
BookID |
BookTitle |
ModifiedDate |
|
106 |
Mrs. Dalloway |
2010-07-17 13:21:26.753 |
The next example is similar to the last except that I specify the column prefixes in the OUTPUT subclause, rather than using as asterisk:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
-- declare @DeleteOutput2 table variable DECLARE @DeleteOutput2 table ( BookID int, BookTitle nvarchar(50), ModifiedDate datetime ); -- delete row in Books table DELETE Books OUTPUT DELETED.BookID, DELETED.BookTitle, DELETED.ModifiedDate INTO @DeleteOutput2 WHERE BookID = 103; -- view updated row in Books table SELECT * FROM Books; -- view output row in @DeleteOutput2 variable SELECT * FROM @DeleteOutput2; |
As the example shows, an OUTPUT clause in a DELETE statement is similar to one in an INSERT or UPDATE statement. The key is to ensure that you’ve specified your column prefixes correctly. Not surprisingly, the first SELECT statement verifies that another row has been deleted from the Books table:
|
BookID |
BookTitle |
ModifiedDate |
|
101 |
One Hundred Years of Solitude |
2010-07-17 13:09:10.573 |
|
102 |
Pride and Prejudice |
2010-07-17 13:09:10.577 |
The deleted row has been deleted has been added to the @DeleteOutput2 variable, as shown in the results from the second SELECT statement:
|
BookID |
BookTitle |
ModifiedDate |
|
103 |
The Great Gatsby |
2010-07-17 13:09:10.580 |
You’re not limited to one OUTPUT clause in a DML statement. For instance, there might be times when you want to output the results to the processing application as well as to a variable or table. In such a case, you can include multiple clauses. The following example is similar to the previous one, except that I’ve added another OUTPUT clause:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
-- declare @DeleteOutput2 table variable DECLARE @DeleteOutput3 table ( BookID int, BookTitle nvarchar(50), ModifiedDate datetime ); -- delete row in Books table DELETE Books OUTPUT DELETED.BookID, DELETED.BookTitle, DELETED.ModifiedDate INTO @DeleteOutput3 OUTPUT DELETED.BookID, DELETED.BookTitle WHERE BookID = 103; -- view updated row in Books table SELECT * FROM Books; -- view output row in @DeleteOutput3 variable SELECT * FROM @DeleteOutput3; |
The first OUTPUT clause is the same as the last example. However, the second OUTPUT clause is new. Notice that the clause does not include an INTO subclause. This indicates that the outputted data will be sent to the calling application. Also notice that the set of column prefixes is different in the two OUTPUT clauses. The prefixes can be the same or different.
If you were to run the statements in this example after running the previous example, no data will be sent to the variable or to the calling application because that row has already been deleted. However, if the row exists, the appropriate data would be sent to both targets.
Using an OUTPUT Clause in a MERGE Statement
When working in SQL Server 2008, you can add an OUTPUT clause to a MERGE statement. The process is similar to adding the clause to an UPDATE statement; you use both the INSERTED and DELETED column prefixes.
Let’s look at an example that demonstrates how this work. First, however, we must create a second table to support the MERGE statement. The following script creates the Book2 table and populates it with two rows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
-- create second table and populate IF OBJECT_ID ('Books2', 'U') IS NOT NULL DROP TABLE dbo.Books2; CREATE TABLE dbo.Books2 ( BookID int NOT NULL PRIMARY KEY, BookTitle nvarchar(50) NOT NULL, ModifiedDate datetime NOT NULL ); INSERT INTO Books2 VALUES(101, '100 Years of Solitude', GETDATE()); INSERT INTO Books2 VALUES(102, 'Pride & Prejudice', GETDATE()); Once we've created the Books2 table, we can try a MERGE statement. In the following example, I declare the @MergeOutput1 variable, merge data from the Books table into the Books2 table, and view the results: -- declare @MergeOutput1 table variable DECLARE @MergeOutput1 table ( ActionType nvarchar(10), BookID int, OldBookTitle nvarchar(50), NewBookTitle nvarchar(50), ModifiedDate datetime ); -- use MERGE statement to perform update on Book2 MERGE Books2 AS b2 USING Books AS b1 ON (b2.BookID = b1.BookID) WHEN MATCHED THEN UPDATE SET b2.BookTitle = b1.BookTitle OUTPUT $action, INSERTED.BookID, DELETED.BookTitle, INSERTED.BookTitle, INSERTED.ModifiedDate INTO @MergeOutput1; -- view Books table SELECT * FROM Books; -- view updated rows in Books2 table SELECT * FROM Books2; -- view output rows in @MergeOutput1 variable SELECT * FROM @MergeOutput1; |
For the @MergeOutput1 variable, I include columns for both the old and new titles. I also include a column named ActionType. The column reflects the type of modification that is performed on the table when the rows are merged.
Now let’s look at the OUTPUT subclause. Notice that, in addition to the INSERTED and DELETED column prefixes, I include the $action variable. The built-in parameter returns one of three nvarchar(10) values-INSERT, UPDATE, or DELETE-and is available only to the MERGE statement. The value returned depends on the action performed on the row.
The first two SELECT statements return the data in the Books and Books2 tables after the MERGE. The results, which are identical, are shown in the following table:
|
BookID |
BookTitle |
ModifiedDate |
|
101 |
One Hundred Years of Solitude |
2010-07-17 13:09:10.573 |
|
102 |
Pride and Prejudice |
2010-07-17 13:09:10.577 |
The results from the third SELECT statement, which calls the @MergeOutput1 variable, reflect the modifications made to the Books2 table:
|
ActionType |
BookID |
OldBookTitle |
NewBookTitle |
ModifiedDate |
|
UPDATE |
101 |
100 Years of Solitude |
One Hundred Years of Solitude |
2010-07-17 15:54:11.580 |
|
UPDATE |
102 |
Pride & Prejudice |
Pride and Prejudice |
2010-07-17 15:54:11.580 |
Whether you use want to output your data modifications to a processing application, a table, or a variable, the OUTPUT clause is an easy, effective way to capture that data. By using the clause, you can reduce the number of calls to the database, eliminate the need for auditing triggers, archive modified data, or pass data on to an application for further processing. The OUTPUT clause is a flexible and easy to use-and it offers big benefits. For further information on the clause, see the topic “OUTPUT Clause (Transact-SQL)” in SQL Server Books Online.
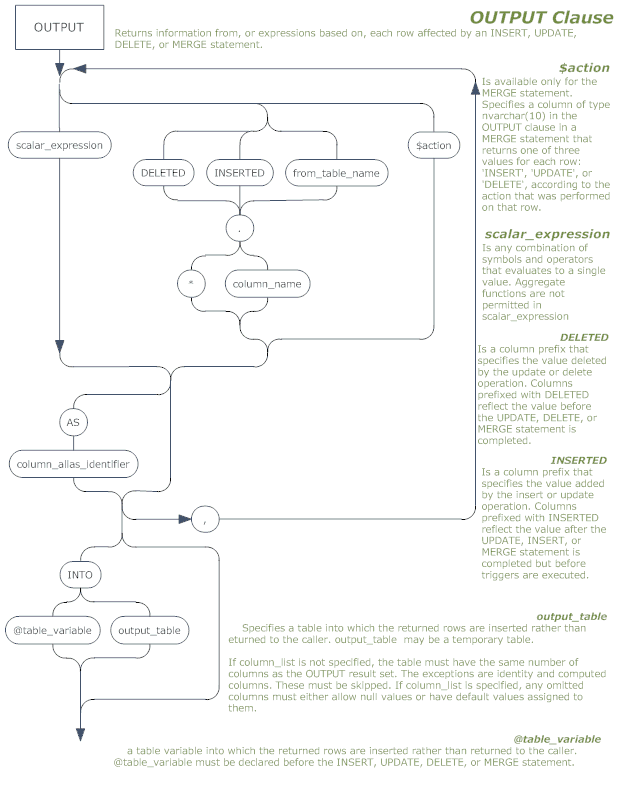
The railroad diagram for the OUTPUT clause is provided as a PDF file below.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved



Load comments