
As part of my work as a SQL Server consultant, I’ve been asked many times to reproduce locally a specific query plan from a customer’s production environment, and then to debug it. You may think that this is just a matter of restoring a production database backup onto a development machine, and then we would be ready to start trying the query. Unfortunately you can seldom do this because:
- The Production database is likely to be too large: The database backup can be too large to be restored in a local machine or to be transferred to another machine. It would take too long to take a backup of, say, a 1TB database, compress the file (suppose it is a SQL Server 2005 without native compression), send it to a FTP, download it, decompress the file, and finally restore the database.
- The data may be confidential: The customer may not be able to share their data even if you have a non-disclosure agreement, because it contains confidential information.
- Your hardware is almost certainly different: Unless you are blessed with a 1TB SSD and 32GB memory laptop your hardware will be very different from the customer’s server. The Query optimizer will produce different plans for it because it takes account of the available memory and the number of available processors.
The query optimizer will use a number of factors to come up with the best query execution plan. If you change any of them, there will be no guarantee that you will be able to reproduce a specific query plan. These factors include:
- TTable metadata: Which indexes are available and the metadata of the tables (data type columns, nullable columns etc.).
- Session SET OPTIONS: SET options may change the cardinality of a predicate or a join. For instance, setting ANSI_NULLS to OFF will make SQL Server evaluates “NULL = NULL” to true and not as UNKNOWN as expected in the default behavior: this change may affect the cardinality of a filter expression or an outer join.
- Constraints: SQL Server will try to use a foreign key or a check constraint to create a better query plan: You can see a sample here.
- Statistics: During the creation of a query plan, the Query Optimizer can read statistics to use histograms, density, string summary etc.
- Number of rows and pages in the table: Based on how many rows a logical query operator will process, the Query Optimizer can decide which physical operator will be used (i.e. a hash or a stream aggregation). In addition, the greater the number of pages in the table, the larger will be the cost associated with I/O operations, so the Query Optimizer has to consider the cost of scanning a table with many pages.
- Available physical memory: The cost of sort and hash operators depends on the relative amount of memory that is available to SQL Server. For example, if the size of the data is larger than the cache, the query optimizer knows that the data must always be spooled to disk. However, if the size of the data is much smaller than the cache, it will probably perform the operation in memory.
- Number of available CPUs: SQL Server considers different optimizations according to the number of CPUs. The cost associated to a parallel operation is different depending on the number of CPUs that are available. Even if a plan is parallel, SQL Server can identify when you have CPU pressure and will decide at the point of executing the plan not to run the actual plan using many threads, but the estimated plan will remain the same.
- 32 or 64 bit system: On a 32 bit machine you are limited to the user mode address space, so even you have a server with a lot of memory, you cannot necessarily use all that memory in a sort or hash join operation.
So bearing in mind that it is almost impossible to keep all these factors the same in test, the question then is: how can one simulate a production environment in a lab machine?
The answer is:
- Generate a script of the database metadata including the statistics information
- Set the database session options
- Simulate the same CPU/Memory hardware from the production server.
The items 1 and 2 are not so complex to do and they are fully documented. Basically what you have to do is to generate a script using SSMS and it will create the commands using WITH STATS_STREAM to set a specific histogram in a statistics without the need to populate the tables with real data: Even if the table is empty, the statistics will be the same as those in the production server. To simulate the hardware, you’ll need to use an undocumented DBCC command called OPTIMIZER_WHATIF, let’s explore it a little bit to see how to use it and how it can affect a query plan.
Before we start a very important note:
Note: DBCC OPTIMIZER_WHATIF is an undocumented command, you can’t trust that this will not change in a service pack or a new product release, use it carefully and never use in a production environment.
DBCC OPTIMIZER WHAT_IF()
The objective of this DBCC command is to set some of the hardware information that the query optimizer uses to create a query plan such as the CPU and memory. The changed settings will be applied only in the session scope.
|
1 2 3 4 5 6 |
DBCC TRACEON (2588) WITH NO_INFOMSGS -- TF to enable help to undocumented commands DBCC HELP ('OPTIMIZER_WHATIF') WITH NO_INFOMSGS /* dbcc OPTIMIZER_WHATIF ({property/cost_number | property_name} [, {integer_value | string_value} ]) */ |
If you run the OPTIMZER_WHATIF with property 0 and the traceflag 3604 you can see which values are actually used:
|
1 2 3 |
DBCC TRACEON(3604) WITH NO_INFOMSGS DBCC OPTIMIZER_WHATIF(0) WITH NO_INFOMSGS; GO |
You’ll see different results depending on the version of SQL Server that you are running, because the optimizer_whatif has received new properties/options since it was first made available in SQL Server 2005. This is the result I get from SQL Server 2012 RTM:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
--------------------------------------------------------- Optimizer what-if status --------------------------------------------------------- property_number current_value default_value property_name --------------------------------------------------------- 1 0 0 CPUs 2 0 0 MemoryMBs 3 0 0 Bits 4 1000 1000 ParallelCardThreshold 5 1 1 ParallelCostThreshold 6 200 200 ParallelCardCrossProd 7 50 50 LowCEThresholdFactorBy10 8 12 12 HighCEThresholdFactorBy10 9 100000 100000 CEThresholdFactorCrossover 10 10 10 DMLChangeThreshold |
I’ll not touch on items 4 to 10 because I don’t understand them myself. For now, let’s see a practical example that uses a server with 16 CPUs. Let’s try to simulate the same query plan on my humble notebook.
Suppose you have the following query to perform a running aggregation in a table called TestRunningTotals:
|
1 2 3 4 5 6 7 8 9 |
SELECT ID_Account, ColDate, ColValue, (SELECT SUM(b.ColValue) FROM TestRunningTotals b WHERE b.ColDate <= a.ColDate) AS RunningTotal FROM TestRunningTotals a ORDER BY ID_Account, ColDate OPTION (RECOMPILE) |
In a production server with 16 cores available we get the following query plan:

As we can see, the query is running in parallel and it is taking 41 seconds to run (because I really ran in a server with 16 cores). The CPU usage is very high since many cores are working to process the query.The CPU usage graph when running the multithreaded query is shown below.
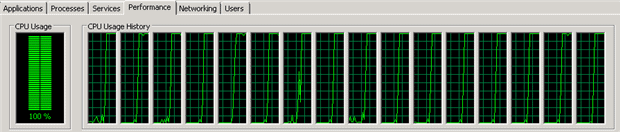
If I run the same query, but throttling it by specifying the hint ‘MAXDOP 1‘, the query takes 4 minutes and 24 seconds to run; and, as one might expect, the CPU usage is much lower since there is only one thread running the query. The following is the CPU usage graph that one sees when running the query with only one thread.
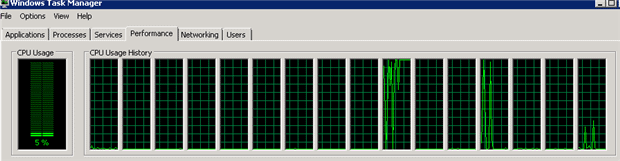
Now let’s suppose you have to optimize this query to consume less CPU, but you can’t limit the MAXDOP because, without running in parallel, it is taking too long to run the query.
First you have to simulate the same query plan in a test environment, so let’s first get the script to create the table and the statistics related to it:

To complete the script generation you can follow the instructions from following Microsoft KB: http://support.microsoft.com/?kbid=914288.
Because the script generated is too big, I’ll not post it here, but you can download the script here.
After we have created the database and the table related to the query, let’s see the query plan:
|
1 2 3 4 5 6 7 8 9 |
SELECT ID_Account, ColDate, ColValue, (SELECT SUM(b.ColValue) FROM TestRunningTotals b WHERE b.ColDate <= a.ColDate) AS RunningTotal FROM TestRunningTotals a ORDER BY ID_Account, ColDate OPTION (RECOMPILE) |
This is the actual query plan:

Since the query doesn’t have any real data, you’ll not be able to test it; but, from the perspective of the query optimizer, the table has the same data as the production table.
As we can see, the plan isn’t the same. The plan generated on my notebook isn’t running in parallel. Since my notebook only has four cores, the query optimizer considers that it would be too expensive to run this plan in parallel and so it doesn’t create a parallel plan.
To force the query optimiser to optimize the plan on the same production hardware I could use DBCC OPTIMIZER_WHATIF to mimic 16 cores, let’s see:
|
1 2 3 4 5 6 7 8 9 10 11 |
DBCC OPTIMIZER_WHATIF(1, 16); GO SELECT ID_Account, ColDate, ColValue, (SELECT SUM(b.ColValue) FROM TestRunningTotals b WHERE b.ColDate <= a.ColDate) AS RunningTotal FROM TestRunningTotals a ORDER BY ID_Account, ColDate OPTION (RECOMPILE) |
Actual query plan:

Now that you have the same plan as you got from production environment, you can start trying to create indexes, or change the query to obtain a plan with better cost and potentially better performance.
You can also set the other configurations like memory and 64 bits, for instance:
|
1 2 3 4 |
-- Set ammount of memory in MB, in this case 512GB DBCC OPTIMIZER_WHATIF(2, 524288); -- Set to 64 bit system DBCC OPTIMIZER_WHATIF(3, 64); |
To reset the values to default, you can call it using value 0, for instance DBCC OPTIMIZER_WHATIF(2,0) will reset the CPU property.
Conclusion
Using this technique, you can simulate a production environment “in-house” using nothing more than an ordinary laptop, with a very few commands. This simulation of the production environment is sufficient to enable you to debug or optimize SQL Queries that might otherwise require production data to deal with.
I am sure I don’t need to tell you not to use this is in production environment, do I? This is undocumented stuff, so nobody can guarantee what it is really doing, or that there aren’t horrible side-effects unless Microsoft chooses to make it officially public and documented.
That’s all folks…
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments