
Introduction
Today, many organizations store and transmit data in an XML data format. Because of the ubiquity and readability of the XML format, it has become convenient and popular to both consume and provide data using XML. Because XML data is used so widely, it is increasingly important to be able to query XML values efficiently. XML indexes were designed to complement the XML data type and have been available since SQL Server 2005. When these indexes are used properly, they can dramatically reduce execution time in queries made against XML columns.
How Do XML Indexes Work?
When no indexes are present, an XML field must be ‘shredded’ when the query is executed. This means that the XML data is peeled apart from the XML tags, and organized into a relational format. An XML index does this work ahead of time, representing the XML data in an already-shredded version, thereby allowing easy filtering.
Some XML Index Ground Rules
XML indexes can be applied only to columns of the XML data type. In order to use XML indexes on a specific table, the table must have a clustered index on the primary key column (a primary key constraint includes a clustered index upon creation by default).
There are 2 types of XML indexes – primary and secondary.
A primary XML index essentially contains one row of information for each node in the XML column. This information is made up of XML node values, types, and paths. A primary index is a ‘pre-shredded’ representation of the XML blob – an easy-to-filter copy of the XML data.
Secondary XML indexes are dependent on primary XML indexes – you cannot create any secondary indexes without first having created a primary index.
Secondary XML indexes come in 3 types: PATH, VALUE, and PROPERTY indexes. Secondary indexes are designed to provide additional optimization for certain types of XML queries.
- PATH secondary indexes often help to optimize queries that make use of a path. An exist() method in the query usually indicates that a PATH index may improve the query execution.
- PROPERTY secondary indexes are designed to be helpful with queries where the primary key field is used, and where multiple values are retrieved from a single XML instance.
- VALUE secondary indexes are good for queries that use wildcards in a path to find known values – if the full path is not known, but the value being filtered IS known, a VALUE index will probably optimize the query execution.
The basic syntax to create an XML index is:
|
1 2 3 4 5 6 |
CREATE [ PRIMARY ] XML INDEX index_name ON <object> ( xml_column_name ) [ USING XML INDEX xml_index_name [ FOR { VALUE | PATH | PROPERTY } ] ] [ WITH ( <xml_index_option> [ ,...n ] ) ] [ ; ] |
Using a Primary XML Index
Let’s jump right in and start experimenting with XML indexes.
We have an existing Employee table with 500000 employee records. A sampling of the table is shown below:
|
1 2 3 |
--get sample from employee data table SELECT TOP 1 * FROM Employee GO |

We will need to generate XML data from the Employee table for the purposes of testing the benefits of XML indexes. To do this, we’ll create a script that builds out an XML representation of the Employee data fields – but first, we’ll need to create a table to hold the XML data:
|
1 2 3 4 5 6 7 |
--create table to hold xml data CREATE TABLE EMP_XML ( ID INT PRIMARY KEY, EMP_DETAILS XML ) GO |
We’ve created the table with a primary key, which by default creates a clustered index on the primary key column – a necessity if we plan on creating XML indexes on this new table. We can now run a script that populates the new EMP_XML table. Our script will do this via the FOR XML clause, using the PATH mode to create the ‘Employee’ root node:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
--run script to convert employee records to xml data DECLARE @counter INT = 1 DECLARE @row VARCHAR(MAX) WHILE @counter <= 500000 BEGIN SET @row = ( SELECT SSN AS '@ssn', DOB AS '@dob', FirstName AS 'FirstName', MiddleName AS 'MiddleName', LastName AS 'LastName', [State] AS 'Address/@state', ZipCode AS 'Address/@zip', Street AS 'Address/Street', City AS 'Address/City', ID AS 'Internal/@ID', Salary AS 'Internal/Salary', HireDate AS 'Internal/Hiredate', Department AS 'Internal/Department' FROM Employee WHERE ID = @counter FOR XML PATH ('Employee') ) INSERT EMP_XML VALUES(@counter,@row) SET @counter += 1 END |
Notice that we’ve designated some of the source table’s fields as nodes or nested nodes, and others as node attributes in the XML table. We now have a table containing all 500000 records of employee data, in XML format:
|
1 2 3 |
--get sampling of new xml records SELECT TOP 5 * FROM EMP_XML GO |
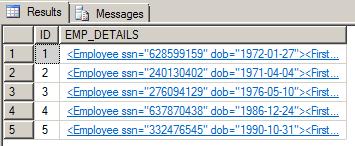
The first record’s EMP_DETAILS field, expanded:
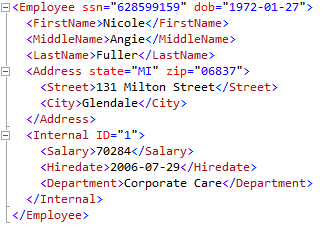
We can see that all fields from the source table are now represented as XML nodes and attributes. We’ll use this table to test the performance benefits of the XML index.
Comparing Query Execution Times
Let’s now look at some basic filtering operations that we may want to perform on our new employee XML data.
Before running any queries, let’s turn on STATISTICS TIME to measure the query execution time:
|
1 2 3 |
--turn on statistics time SET STATISTICS TIME ON GO |
We’ll now use a simple example to demonstrate the benefits of using a primary XML index. To locate the street address for an employee having a Social Security Number of 574582264, we can use the following XQuery statement:
|
1 2 3 4 5 |
--find employee address by ssn SELECT EMP_DETAILS.value('(/Employee/Address/Street)[1]','varchar(50)') AS StreetAddress FROM EMP_XML WHERE EMP_DETAILS.exist('/Employee[@ssn=574582264]') = 1 GO |
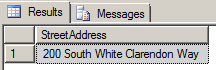
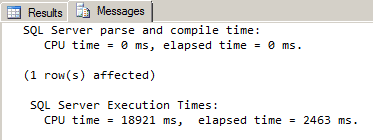
The elapsed time, under SQL Server Execution Timesin the Messages tab, represents the actual query execution time in milliseconds. We can see that the query time was 2463 ms. Now let’s add a primary XML index to the table:
|
1 2 3 4 |
--create primary xml index CREATE PRIMARY XML INDEX [IX_EMP_DETAILSx] ON EMP_XML(EMP_DETAILS) GO |
We’ve created a primary index on the EMP_DETAILS column of the table – the only XML field. Creating the primary XML index on a table with this many records may take a few minutes. XML data is being collected and stored during the primary XML index creation, including node values, node types, and the paths from each node to the root.
Now that a primary XML index is on the EMP_DETAILS field, we’ll run the same query again:
|
1 2 3 4 5 |
--find employee address by ssn SELECT EMP_DETAILS.value('(/Employee/Address/Street)[1]','varchar(50)') AS StreetAddress FROM EMP_XML WHERE EMP_DETAILS.exist('/Employee[@ssn=574582264]') = 1 GO |
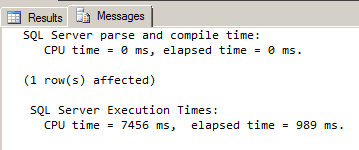
We see that the elapsed time and CPU time were both reduced by about 60% as a result of creating the primary XML index! We can tell for sure that the XML index was used by examining the graphical execution plan. To see this in SSMS, go to the Query menu before running the query and then select Include Actual Execution Plan. After running the query, look at the results in the Execution Plan tab:
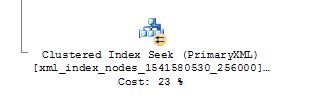
A node that is displayed for a PrimaryXML index seek or scan in the graphical execution plan indicates that the XML index was indeed used for the query.
Disabling XML Indexes
Let’s assume we have received a request to find all address information for employees who:
- Live in Michigan
- Have a first name of ‘Desiree’
Before we create a query for this request, let’s disable the primary XML index, so we can compare the before and after time statistics. By disabling an index, we can retain the index definition whilst clearing out the stored data about the table. A disabled index is not used by the query execution plan. The current status of XML indexes can be checked by using:
|
1 2 3 4 5 6 |
--check disabled status for xml indexes SELECT name, is_disabled FROM sys.indexes WHERE OBJECT_ID = OBJECT_ID('EMP_XML') AND type_desc = 'XML' GO |
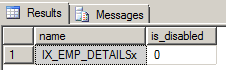
To disable our primary index, we’ll run the following ALTER INDEX statement, with the DISABLE argument:
|
1 2 3 |
--disable primary xml index ALTER INDEX IX_EMP_DETAILSx ON EMP_XML DISABLE GO |
The primary XML index is now rendered ineffective.
To return the results we need for the ‘addresses’ request, we can include a FLWOR expression in our query, within an XQuery query() method:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
--get all address data for specific employees SELECT EMP_DETAILS.value('(/Employee/FirstName)[1]', 'varchar(50)') AS FirstName, EMP_DETAILS.value('(/Employee/LastName)[1]', 'varchar(50)') AS LastName, EMP_DETAILS.query(' for $Address in /Employee/Address return $Address ') AS [Address] FROM EMP_XML WHERE EMP_DETAILS.exist('/Employee/FirstName[.="Desiree"]') = 1 AND EMP_DETAILS.exist('/Employee/Address[@state="MI"]') = 1 GO |
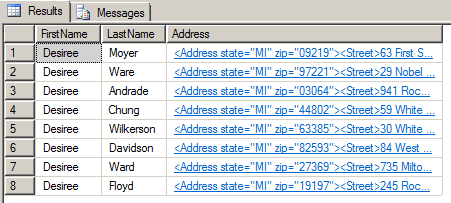
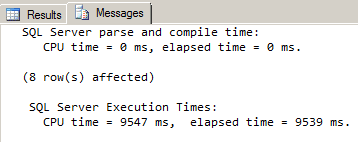
This query gives us the results we are looking for; every element and attribute value under the Address node, and it also includes FirstName and LastName values for clarity. The FLWOR expression iterated the Address node and returned the State, Zip, Street, and City values. After running this query a few times, the elapsed execution time consistently shows a time of around 9539ms. Now that we’ve tested this query without using any XML indexes, let’s re-enable our primary XML index.
Rebuilding XML Indexes
An XML index, like any index, can be re-enabled by simply using the REBUILD option in an ALTER INDEX statement. To rebuild our primary XML index, we’ll run the following:
|
1 2 3 |
--rebuild primary xml index ALTER INDEX IX_EMP_DETAILSx ON EMP_XML REBUILD GO |
The primary XML index is now re-enabled. Be aware that rebuilding an index can have serious performance implications, limiting access to the table from other processes. Other types of indexes accept the REBUILD argument with the WITH (ONLINE = ON) hint to reduce this performance hit, but not XML indexes. If we were to attempt a REBUILD WITH (ONLINE = ON) on our primary XML index, we’d get the following error:
|
1 2 3 |
--attempt primary xml index rebuild with online=on ALTER INDEX IX_EMP_DETAILSx ON EMP_XML REBUILD WITH (ONLINE = ON) GO |

XML indexes can only use the WITH (ONLINE = OFF) option.
Now that we have re-enabled our primary XML index, it will be considered in the query execution plan. Let’s re-run our previous query and examine the statistics time again:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
--get all address data for specific employees SELECT EMP_DETAILS.value('(/Employee/FirstName)[1]', 'varchar(50)') AS FirstName, EMP_DETAILS.value('(/Employee/LastName)[1]', 'varchar(50)') AS LastName, EMP_DETAILS.query(' for $Address in /Employee/Address return $Address ') AS [Address] FROM EMP_XML WHERE EMP_DETAILS.exist('/Employee/FirstName[.="Desiree"]') = 1 AND EMP_DETAILS.exist('/Employee/Address[@state="MI"]') = 1 GO |
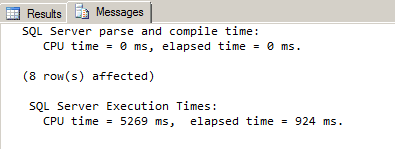
Our previous execution time was 9539 milliseconds. We’ve reduced the time by 90% by using just a primary XML index! Although this is a great optimization gain, let’s see if we can increase efficiency for this query even more, using a secondary XML index.
Using Secondary XML Indexes
How can we decide which secondary index to use for our query?
PATH secondary indexes are designed to help improve queries that contain a good amount of path expressions. Queries that use the exist() method are usually good candidates for a PATH index. Our last query uses 2 instances of the exist() method in its WHERE clause, and also includes path expressions in the select list. The PATH index seems promising for our query.
PROPERTY secondary indexes are intended for queries where the primary key is a known value, and multiple return values are required from the same XML instance. We are returning multiple return values from the same XML instance. A PROPERTY index also seems like it would be helpful with our query.
VALUE secondary indexes are useful for searching for known element or attribute values, without necessarily knowing the element or attribute names, or the full path to the value. Queries that use wildcards for portions of a path would probably benefit from a VALUE index. In our query, we do know the paths to the elements and attributes we are filtering, as well as the values. A VALUE index could help, but probably not as much as a PATH index would.
Using PATH Secondary XML Indexes
The PATH secondary XML index is known to help with queries that have an exist() expression in the WHERE clause. Since our query uses 2 instances of the exist() method, let’s try aPATH secondary index, and see if it improves performance. We’ll create thePATH index as follows:
|
1 2 3 4 5 |
--create secondary xml path index CREATE XML INDEX [IX_EMP_DETAILS_pathx] ON EMP_XML(EMP_DETAILS) USING XML INDEX [IX_EMP_DETAILSx] FOR PATH GO |
Note that we need to reference the primary XML index (IX_EMP_DETAILSx) in the index create statement with the USING clause, to specify that it will be a secondary XML index. A primary XML index is required in order to implement any secondary index. The ‘FOR PATH’ option is what designates the index as a PATH index. Now that we have a PATH secondary index, let’s re-run our query and view the execution time results:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
--get all address data for specific employees SELECT EMP_DETAILS.value('(/Employee/FirstName)[1]', 'varchar(50)') AS FirstName, EMP_DETAILS.value('(/Employee/LastName)[1]', 'varchar(50)') AS LastName, EMP_DETAILS.query(' for $Address in /Employee/Address return $Address ') AS [Address] FROM EMP_XML WHERE EMP_DETAILS.exist('/Employee/FirstName[.="Desiree"]') = 1 AND EMP_DETAILS.exist('/Employee/Address[@state="MI"]') = 1 GO |
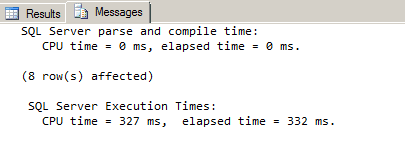
We see another huge performance gain by using the PATH secondary XML index – another reduction in execution time by more than 60%.
Using PROPERTY Secondary XML Indexes
With our ‘addresses’ query, a PROPERTY secondary XML index could be slightly more advantageous than a PATH index, because in addition to using paths, our query also returns multiple values. Let’s experiment and see if adding a PROPERTY index will increase optimization.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
--create secondary xml property index CREATE XML INDEX [IX_EMP_DETAILS_propertyx] ON EMP_XML(EMP_DETAILS) USING XML INDEX [IX_EMP_DETAILSx] FOR PROPERTY GO --get all address data for specific employees SELECT EMP_DETAILS.value('(/Employee/FirstName)[1]', 'varchar(50)') AS FirstName, EMP_DETAILS.value('(/Employee/LastName)[1]', 'varchar(50)') AS LastName, EMP_DETAILS.query(' for $Address in /Employee/Address return $Address ') AS [Address] FROM EMP_XML WHERE EMP_DETAILS.exist('/Employee/FirstName[.="Desiree"]') = 1 AND EMP_DETAILS.exist('/Employee/Address[@state="MI"]') = 1 GO |
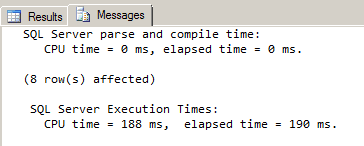
After running the ‘addresses’ query again, this time with a PROPERTY index in place, we see yet another reduction in execution time – from 332 ms. to 190 ms. It seems pretty obvious that the PROPERTY index was the reason for the performance gain here, but how can we tell for sure? We now have 2 different secondary indexes on our table, PATH and PROPERTY, and their nodes both look similar in the graphical execution plan:
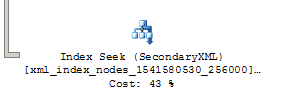
To find out, all we have to do is hover over the SecondaryXML node and look in the ‘Object’ section of the popup – OR right-click the node, select Properties, and examine the ‘Object’ section of the pane:
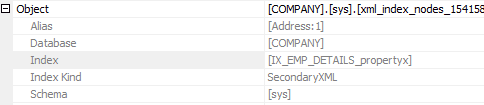
We can clearly see the name of the index (IX_EMP_DETAILS_propertyx) that was used in the query. The PROPERTY index was utilized for our query. This is a good example of how experimenting with secondary XML indexes can result in highly optimized queries.
Using VALUE Secondary XML Indexes
We have received another request: write a query that returns all details for all employees living in zip code 98679. Let’s imagine that we aren’t familiar with the XML structure, but still need to query it without bothering to look up schema details. We are not sure of the node attribute name – is it ‘zip‘, ‘zipcode‘, or ‘zip code‘? We do know that it is listed as a node attribute, not a node element. We’ll choose a query that reflects what we know about the XML structure:
|
1 2 3 4 5 |
--get all employee details for specific zipcode SELECT ID, EMP_DETAILS FROM EMP_XML WHERE EMP_DETAILS.exist('//@*[.="98679"]') = 1 GO |
We’ve used the ‘//‘ path wildcard to indicate that we don’t know the full path to the attribute, and the ‘*‘ attribute wildcard to allow for the value to be found in any element attribute. The ‘@‘ shows that we know that the zip code value is an element attribute value.
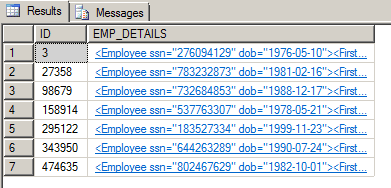
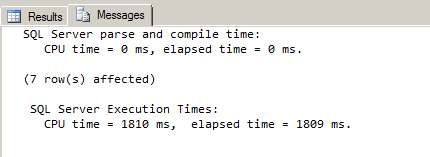
The results are processed in 1809 ms. If we look at the graphical execution plan, we see that the PATH secondary index was used almost exclusively:
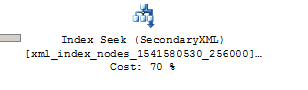
Since our ‘zipcode’ query uses an incomplete path AND a wildcard, it’s a good candidate for a VALUE secondary index. Let’s create a VALUE index, and test the execution time from a second query run:
|
1 2 3 4 5 6 7 8 9 10 11 |
--create secondary xml value index CREATE XML INDEX [IX_EMP_DETAILS_valuex] ON EMP_XML(EMP_DETAILS) USING XML INDEX [IX_EMP_DETAILSx] FOR VALUE GO --get all employee details for specific zipcode SELECT ID, EMP_DETAILS FROM EMP_XML WHERE EMP_DETAILS.exist('//@*[.="98679"]') = 1 GO |
The VALUEindex reduced the query execution time to less than a millisecond!
We can see the SecondaryXML index node in the graphical execution plan:
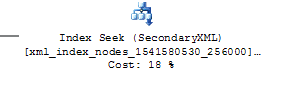
Let’s check the ‘Object’ section of the node’s Properties pane to confirm that the VALUE index was used:
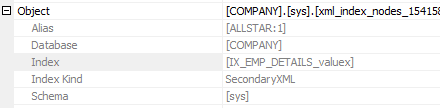
We see that the VALUE index (IX_EMP_DETAILS_valuex) was used for the query.
If we had run this query without any XML indexes (by disabling the primary index and all secondary indexes), the query execution time results would have been as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
--disable all 3 secondary xml indexes ALTER INDEX [IX_EMP_DETAILS_valuex] ON EMP_XML DISABLE GO ALTER INDEX [IX_EMP_DETAILS_propertyx] ON EMP_XML DISABLE GO ALTER INDEX [IX_EMP_DETAILS_pathx] ON EMP_XML DISABLE GO --disable primary xml index ALTER INDEX IX_EMP_DETAILSx ON EMP_XML DISABLE GO --get all employee details for specific zipcode SELECT ID, EMP_DETAILS FROM EMP_XML WHERE EMP_DETAILS.exist('//@*[.="98679"]') = 1 GO |
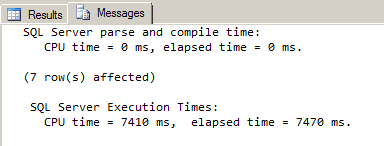
So, a query that originally cost more than 7 seconds has now been optimized so that it takes less than 1 millisecond.
Disadvantages
Some disadvantages to using XML indexes include:
- As with any index, data modifications are more expensive. Updates and inserts to an XML field that is indexed will take longer, as the index(es) must be maintained and updated.
- XML indexes can claim massive amounts of disk space. To get an idea of how our XML indexes have affected disk space, consider how the sp_spaceused statistics have changed with each index addition:
123--get disk space used info for tableEXEC sp_spaceused 'EMP_XML'GO
- With no XML indexes:

- After adding the primary XML index:

- After adding the PATH secondary index:

- After adding the VALUE secondary index:

- Ater adding the PROPERTY secondary index:

- The cumulative index space used for the table was increased by more than 2GB after adding the primary XML index and the 3 secondary indexes. That is a substantial disk space cost overhead for the XML indexes , considering that the data size of the 500000-row table is only about 300MB.
Conclusion
We’ve looked at some of the reasons that using XML indexes can increase a query’s performance, and have gone over some of the basic rules for using them.
We’ve delved into some specific test cases in order to prove the performance benefits of XML indexes on the XML data type. We found by comparing time statistics that using a primary XML index can reduce query execution times dramatically. We looked at the different types of secondary XML indexes, and saw that by implementing the correct secondary index, a query’s performance can be optimized even further.
We also reviewed some disadvantages to using XML indexes, such as increased table modification times due to index maintenance, and increased disk space consumption. However, when XML indexes are used correctly to support specific query demands, any increased disk and index maintenance costs may be seen as a small price for such large query performance gains.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments