
XML data is often stored in files, outside of a database. One obvious use for XML file storage is to hold configuration data that is read by web servers and other systems. If ad-hoc querying of XML files becomes necessary, it’s important to find accurate and efficient ways to extract just the data you require from the XML, and return the results as a table. In this post, we’ll look into finding the best ways to perform ad-hoc queries against XML files using SQL Server’s XQuery implementation and end up with the results in a table.
Let’s use Microsoft’s sample Books.xml file, which contains 12 book entity records that include element and attribute values for book id, author, title, genre, publication date, and description. A sample book node looks like this:
|
1 2 3 4 5 6 7 8 |
<book id="bk109"> <author>Kress, Peter</author> <title>Paradox Lost</title> <genre>Science Fiction</genre> <price>6.95</price> <publish_date>2000-11-02</publish_date> <description>After an inadvertant trip through a Heisenberg Uncertainty Device, James Salway discovers the problems of being quantum.</description> </book> |
For our purposes, I’ve created a local copy of Books.xml on C:. Let’s assume that we want to query this local file from SQL Server, returning the results of our query in a relational format – this can be referred to as ‘shredding‘ XML node values.
Importing XML data using a CTE
Our first step will be to find a way to access the XML file from SQL Server. One way to do this is to use the versatile OPENROWSET function. It can be used to import many different formats of bulk data. We can use OPENROWSET in a CTE (Common Table Expression) to directly access the XML data from the BLOB (Binary Large OBject) that OPENROWSET converts it into, for each time we run a query against it:
|
1 2 3 4 5 6 7 8 |
--query the XML Blob using a CTE (pulling from the XML file each time) WITH XmlFile (Contents) AS ( SELECT CONVERT (XML, BulkColumn) FROM OPENROWSET (BULK 'C:\Books.xml', SINGLE_BLOB) AS XmlData ) SELECT * FROM XmlFile GO |
The ‘SINGLE_BLOB’ argument of OPENROWSET designates the XML data into a Blob of data type VARBINARY(MAX) – this type also is limited to a size of 2GB. The CTE creates a table expression named ‘XMLFile’ and its singlular column to hold the data – giving us the ability to reference the XML data properly while running XQuery statements against it.
Importing XML data using a function
Another way we can access the XML data from the file on demand is by creating a function that returns an XML variable. A variable of the XML data type can hold up to 2 GB of XML data – for context, our entire Books.xml file is only 5KB. We can easily create a SQL Server scalar function to do this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
--create function to return XML data from file as XML variable USE AdventureWorks2012 GO CREATE FUNCTION fn_BooksXML() RETURNS XML AS BEGIN DECLARE @books XML; SELECT @books = CONVERT (XML, BulkColumn) FROM OPENROWSET (BULK 'C:\Books.xml', SINGLE_BLOB) AS XmlData; RETURN @books; END GO |
We’ve created this function in the AdventureWorks2012 database. It can be called like this:
|
1 2 |
--call function to return all XML file data SELECT AdventureWorks2012.dbo.fn_BooksXML() AS [Books XML Data]; |
Obviously, creating a function to pull XML data is more of a permanent way to access an XML file, as opposed to an ad-hoc script.
Filtering XML data using FLWOR
Now that we have found ways to access our XML file data from SQL Server, we can start looking for the best way to run queries against it. To start with, let’s say we are looking for a query that will return author names for books in the ‘Computer’ genre category. An obvious first possible solution might be to use the iterative power of the XQuery FLWOR statement. FLWOR stands for For, Let, Where, Order by, and Return. FLWOR is an integral part of XQuery. A possible FLWOR solution to our problem might look like this:
|
1 2 3 4 5 6 7 8 |
--use a FLWOR statement to find all authors in Computer genre SELECT AdventureWorks2012.dbo.fn_BooksXML().query('for $Book in /catalog/book let $Genre := $Book/genre let $Author := $Book/author where $Genre = "Computer" return $Author ') AS [Computer Book Authors] GO |
We’ve used a FLWOR statement inside of an XQuery query() method, accessing the XML data from the file using our function This does return the values that we want:

|
1 2 3 4 |
<author>Gambardella, Matthew</author> <author>O'Brien, Tim</author> <author>O'Brien, Tim</author> <author>Galos, Mike</author> |
But it definitely does not present the results in the relational format we are looking for – the data is returned in its native format, an XML fragment, instead. We could try stripping the FLWOR results of the XML tags using the XQuery data() function:
|
1 2 3 4 5 6 7 8 |
--use a FLWOR statement to find all authors in Computer genre (remove XML tags) SELECT AdventureWorks2012.dbo.fn_BooksXML().query('for $Book in /catalog/book let $Genre := $Book/genre let $Author := $Book/author where $Genre = "Computer" return data($Author) ') AS [Computer Book Authors] GO |
However, this method still returns the results contained in one record – only now without the XML tags:

Incidentally, using the data() method makes it easy to return a delimited list. A few changes to our script, which includes the introduction of the concat() XQuery function, produces a delimited result set:
|
1 2 3 4 5 6 7 8 |
--use a FLWOR statement to find all authors in Computer genre (remove XML tags and delimit) SELECT AdventureWorks2012.dbo.fn_BooksXML().query('for $Book in /catalog/book let $Genre := $Book/genre let $Author := $Book/author where $Genre = "Computer" return concat("[",data($Author)[1],"]") ') AS [Computer Book Authors] GO |

Although FLWOR is a powerful way to produce iterative results, it returns values in an XML format by default.
Filtering XML data using XQuery value() method
Another option we can try is to do our search using a path inside of an XQuery value() method. The value() method simply pulls the value data from an XML node element or attribute. Let’s use value() for our situation, this time using the CTE method to pull the XML data from the file:
|
1 2 3 4 5 6 7 8 |
--use XQuery value() method within a CTE WITH XmlFile (Contents) AS ( SELECT CONVERT (XML, BulkColumn) FROM OPENROWSET (BULK 'C:\Books.xml', SINGLE_BLOB) AS XmlData ) SELECT Contents.value('(/catalog/book/genre[. = "Computer"]/../author)[1]', 'varchar(50)') AS [Computer Book Authors] FROM XmlFile GO |
Within the value() method’s XQuery path, we are indicating here that only genre nodes with a value of ‘Computer’ should be examined. Then, we use the parent node axis abbreviation (‘..’) path step to back up to the book node – where its genre node meets that requirement – and then look at its author node. This works because the genre and author nodes are on the same level inside of the book node. Our results for the above query are:
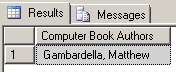
We can immediately see a major problem with using this solution for our purposes – it returns matches for just the first book node; The Value() method will only return one node at a time. This is due to the singleton requirement of the value() method. The singleton requirement forces us to indicate which book node instance we are referring to – even if there is only one instance. However, the XML data contains multiple book nodes, and we need to look at each one in order to get an accurate answer to our request. We’ve indicated that we want the results from the first book node instance returned – by using the ‘[1]’ as a singleton. Therefore, if we change that to ‘[2],’ we get:
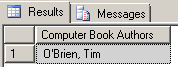
This type of value() query will work fine when using XML fragments having only one node instance, or where only one instance’s values were required. In our case, however, this is not what we want.
Filtering XML data using XQuery nodes() method
We have another possible way to get the results we want: using the XQuery nodes() method. The nodes() method is designed to shred XML node values into a relational format – nodes() actually returns a rowset based on the shredded XML. This sounds like exactly what we need. Let’s try an XQuery nodes() query:
|
1 2 3 4 5 6 7 |
--use XQuery nodes() method within a CTE WITH XmlFile (Contents) AS ( SELECT CONVERT (XML, BulkColumn) FROM OPENROWSET (BULK 'C:\Books.xml', SINGLE_BLOB) AS XmlData ) SELECT c.value('(author)[1]', 'varchar(50)') AS [Computer Book Authors] FROM XmlFile CROSS APPLY Contents.nodes ('(//book/genre[. = "Computer"]/..)') AS t(c); |
This query uses CROSS APPLY to create a kind of self join back to the XmlFile table expression. The CROSS APPLY requires table (t) and column (c) aliases. You may notice that we’ve used a basic XQuery statement in the value() method, but most of the real filtering is done in the nodes() method. Again, we have indicated that the values should be looked for in the genre nodes, and we’ve used the parent::node() axis abbreviation again to point back to the genre node’s parent book node. You’ll also notice that we are again able to employ the value() method, despite its singleton requirement. This is possible because the nodes() method shreds the XML nodes into a relational structure – the value() method is returning values for each record in a rowset generated by nodes(). So, the rowset generated by nodes()contains all book nodes where the genre is ‘Computer.’ The value() method indicates that the author node from the given book node is where the value should be taken from.
The query returns the following:
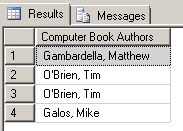
We’ve finally returned the results in the relational format we are looking for. We can eliminate redundant authors by adding the following change:
|
1 2 3 4 5 6 7 8 9 |
--use XQuery nodes() method within a CTE to get distinct authors WITH XmlFile (Contents) AS ( SELECT CONVERT (XML, BulkColumn) FROM OPENROWSET (BULK 'C:\Books.xml', SINGLE_BLOB) AS XmlData ) SELECT DISTINCT x.[Computer Book Authors] FROM( SELECT c.value('(author)[1]', 'varchar(50)') AS [Computer Book Authors] FROM XmlFile CROSS APPLY Contents.nodes ('(//book/genre[. = "Computer"]/..)') AS t(c) )x; |

Working around Case-sensitivity in XQuery
Our query is case-sensitive. Genre node matches for the value ‘Computer’ are not the same as matches for the value ‘computer.’ To work around case-sensitivity in XQuery statements, you can use either the upper-case() or lower-case() functions:
|
1 2 3 4 5 6 7 8 9 10 11 |
--use XQuery nodes() method within a CTE to get distinct authors, resolving case-sensitivity WITH XmlFile (Contents) AS ( SELECT CONVERT (XML, BulkColumn) FROM OPENROWSET (BULK 'C:\Books.xml', SINGLE_BLOB) AS XmlData ) SELECT DISTINCT x.[Computer Book Authors] FROM ( SELECT c.value('(author)[1]', 'varchar(50)') AS [Computer Book Authors] FROM XmlFile CROSS APPLY Contents.nodes ('(//book/genre[lower-case(.) = "computer"]/..)') AS t(c) )x; |
The lower-case() XQuery function forces the genre node value to be lower-case, and then compares it with the lower-case value ‘computer.’
Using the XQuery contains() function to find substrings
Our query is also currently limited to finding exact matches to the lower-case value ‘computer’ in genre nodes. This means that node values with any accidental spaces, for example, will be excluded from our results. Also, if we wanted to search for text in the description nodes, we would have to type the entire lengthy text in our XQuery statement in order to find matches. To allow for substring searches, XQuery provides the contains() function. We’ll use this in conjunction with our current query by making the following changes:
|
1 2 3 4 5 6 7 8 9 10 11 |
--use XQuery nodes() method within a CTE to get distinct authors, resolve case-sensitivity - returning substring matches WITH XmlFile (Contents) AS ( SELECT CONVERT (XML, BulkColumn) FROM OPENROWSET (BULK 'C:\Books.xml', SINGLE_BLOB) AS XmlData ) SELECT DISTINCT x.[Computer Book Authors] FROM ( SELECT c.value('(author)[1]', 'varchar(50)') AS [Computer Book Authors] FROM XmlFile CROSS APPLY Contents.nodes ('(//book/genre[contains(lower-case(.), "comp")]/..)') AS t(c) )x; |
We have modified the way the lower-case() function is used so that we could nest it inside of the contains() function. Even though we are only searching for a substring of the genre node value (‘comp’), we still get the correct results:
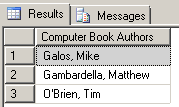
Importing and filtering XML data using a view
If we want to establish a more complete, permanent database-oriented solution, we can create a view that encapsulates some of the work we did earlier, allowing for very easy SQL querying against a result set returned by XQuery:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
--create view to return all XML data from file USE AdventureWorks2012 GO CREATE VIEW v_BooksXML AS WITH XmlFile (Contents) AS ( SELECT CONVERT (XML, BulkColumn) FROM OPENROWSET (BULK 'C:\Books.xml', SINGLE_BLOB) AS XmlData ) SELECT c.value('(@id)', 'varchar(10)') AS [ID], c.value('(author)[1]', 'varchar(100)') AS [Author], c.value('(title)[1]', 'varchar(100)') AS [Title], c.value('(genre)[1]', 'varchar(50)') AS [Genre], c.value('(price)[1]', 'decimal(8,2)') AS [Price], c.value('(publish_date)[1]', 'date') AS [Date], c.value('(description)[1]', 'varchar(200)') AS [Description] FROM XmlFile CROSS APPLY Contents.nodes ('(//book)') AS t(c) GO |
Now we can simple query the view, without using XQuery at all:
|
1 2 3 4 |
--query view SELECT DISTINCT Author FROM AdventureWorks2012..v_BooksXML WHERE Genre LIKE 'comp%' GO |
Efficiency comparisons
How do all of these different methods of accessing XML file data compare in terms of query speed? To check this, we’ll run the different methods together as a batch (making changes to WHERE criteria in the FLWOR statements to provide a better comparison to the other queries):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
--XQuery nodes() method within a CTE WITH XmlFile (Contents) AS ( SELECT CONVERT (XML, BulkColumn) FROM OPENROWSET (BULK 'C:\Books.xml', SINGLE_BLOB) AS XmlData ) SELECT DISTINCT x.[Computer Book Authors] FROM ( SELECT c.value('(author)[1]', 'varchar(50)') AS [Computer Book Authors] FROM XmlFile CROSS APPLY Contents.nodes ('(//book/genre[contains(lower-case(.), "comp")]/..)') AS t(c) )x --XQuery nodes() method using function SELECT DISTINCT x.[Computer Book Authors] FROM ( SELECT c.value('(author)[1]', 'varchar(50)') AS [Computer Book Authors] FROM (SELECT AdventureWorks2012.dbo.fn_BooksXML()) AS y(z) CROSS APPLY z.nodes ('(//book/genre[contains(lower-case(.), "comp")]/..)') AS t(c) )x --use a FLWOR statement within CTE ;WITH XmlFile (Contents) AS ( SELECT CONVERT (XML, BulkColumn) FROM OPENROWSET (BULK 'C:\Books.xml', SINGLE_BLOB) AS XmlData ) SELECT Contents.query('for $Book in /catalog/book let $Genre := $Book/genre let $Author := $Book/author where $Genre [contains(lower-case(.), "comp")] return $Author ') AS [Computer Book Authors] FROM XmlFile GO; --FLWOR statement using function SELECT AdventureWorks2012.dbo.fn_BooksXML().query('for $Book in /catalog/book let $Genre := $Book/genre let $Author := $Book/author where $Genre [contains(lower-case(.), "comp")] return $Author ') AS [Computer Book Authors] GO --view SELECT DISTINCT Author FROM AdventureWorks2012..v_BooksXML WHERE Genre LIKE 'comp%' GO |

The view is the most expensive method by far, and at 71% of the total batch cost, its query cost is roughly 10x either of the others. The differences between using a CTE versus a function seem negligible, as both the nodes() methods and the FLWOR statements cost around 7% of the batch. A minor exception is the FLWOR statement that uses a function – costing slightly more than its CTE counterpart at 8%.
Summary
We started out with an XML file that we wanted to filter for specific results, returning the values in a relational format. We first found a way to pull the XML data into a form that SQL Server could easily access and run queries against, using the OPENROWSET function. A more permanent extension of that idea was to create a function that encapsulated the same logic. We made several attempts to find the proper query solution, at first using an iterative FLWOR statement, but that did not return results relationally. We then tried using a plain XQuery value() method query, but discovered that the value() method’s singleton requirement restricted us to returning only one record at a time. We ended up finding a good resolution by using the XQuery nodes() method – the advantage that nodes() has is that it returns a rowset of the XML data, shredded and organized relationally. We also made a few modification to our nodes() query, eliminating the case-sensitivity and exact-value-match restrictions. We then incorporated some of that logic into a view that can be filtered using a SQL Server WHERE clause, rather than using XQuery criteria. The view solution is arguably the most straightforward solution, providing the creation of a permanent object is allowed. However, a batch query cost comparison showed us that the view method is by far the most costly.
Load comments