

A view in MongoDB is a read-only queryable object defined by an aggregation pipeline running against one or more source collections – conceptually similar to a SQL view defined by a SELECT statement, but using MongoDB’s document-oriented aggregation framework instead of SQL. MongoDB supports two view types: (1) standard views – virtual collections computed on demand each time they’re queried, no storage overhead, always current with source-collection state; (2) on-demand materialised views – precomputed result sets stored as collections via $merge, updated on demand by re-running the defining pipeline, useful for expensive aggregations where query-time performance matters more than perfect freshness. Creating a view requires defining the aggregation pipeline: typical operators include $match (filter), $project (select fields), $lookup (join other collections – MongoDB’s equivalent of SQL joins), $group (aggregate), $sort. This article walks through: creating views via db.createCollection and db.runCommand; building single-collection views with filtering and projection; building multi-collection views using $lookup joins; updating or dropping views; and the MongoDB Compass GUI approach for creating views visually. Views are read-only (you cannot INSERT/UPDATE/DELETE through them) and inherit the read permissions of their source collections plus any pipeline-added restrictions.
This article is part of Robert Sheldon's continuing series on Mongo DB. To see all of the items in the series, click here.
Like many relational database systems, MongoDB supports the use of views. A view is a read-only object in a MongoDB database that works much like a collection, except that the data is not persisted to disk. MongoDB retrieves the view’s documents from the source collection when a client calls the view. In this sense, a view is essentially a saved query that MongoDB runs at the time the view is invoked.
This article, which is part of a series on MongoDB, introduces you to views and how you can create, query, and update them. It also includes a number of examples that demonstrate how they work. The article focuses exclusively on standard views, which are one of two types of views in MongoDB. The platform also supports on-demand materialized views that persist data to disk. However, materialized views are beyond the scope of this article. For now, we’ll stick with standard views, which is a good place to start when learning about views.
Note: For the examples in this article, I used the same MongoDB Atlas and MongoDB Compass environments I used for the previous articles in this series. Refer to the first article for details about setting up these environments. The examples require the hr database and candidates collection, which were used in previous articles. If you haven’t set them up, you should do so now, assuming you want to try out the examples in this article.
Introducing views in MongoDB
Adding a view to a MongoDB database is a fairly straightforward process. You can use either MongoDB Shell or the MongoDB Compass interface. For this article, I focus primarily on running commands in MongoDB Shell, although I provide an overview of the GUI approach later in the article.
To create a view in MongoDB Shell, you can use either the createView or createCollection database method. I’ve used the createView method in the examples here because I like the fact that the name clearly telegraphs what you’re trying to achieve. If you want to learn how to use the createCollection method, refer to the MongoDB article db.createCollection().
When you create a view in MongoDB, you must define an aggregation pipeline that determines which documents to return when a client queries the view. You must also provide a name for a view, as well as the source collection, as shown in the following syntax:
|
1 2 3 4 5 6 |
db.createView( "<view_name>", "<source_collection>", [<pipeline>], { "collation" : { <settings> } } ) |
In MongoDB, a createView method consists of the following components:
- db. System variable for referencing the current database and accessing the properties and methods available to the database object.
- createView. A method available to the database object for creating a view based on the target collection.
- view_name. Placeholder for the name that will be assigned to the view. The view’s name is a string value.
- source_collection. Placeholder for the target collection. For this article, we’ll be using the
candidatescollection. The collection’s name is a string value. - pipeline. Placeholder for the aggregation pipeline that determines which documents to return from the target collection. The pipeline is defined as an array, which means it must be enclosed in square brackets. In addition, it cannot include the
$outor$mergestage. - collation. An optional component that lets you specify a view’s collation. If the option is not included, the method uses the collation defined on the target collection. For this article, we won’t be including this option. To learn how to specify a collation, refer to the MongoDB article db.createView().
The sections to follow walk you through the process of creating a view, based on the syntax above. You’ll also learn how to update and delete a view.
Creating views in MongoDB
Before I show you how to create a view, there are a few preparatory steps you might need take to ensure you can use the candidates collection for the examples to follow. The exact steps depend on whether or not you already created the collection for a previous article.
If the collection does not exist, you should create it now within the hr database. You can then skip the next two steps because they’re specific to those with an existing collection.
If the collection does exist, the first step is to ensure that no validation rules are defined on the candidates collection. To remove any validation rules, run the following runCommand statement:
|
1 |
db.runCommand( { collMod: "candidates", validator: {} } ); |
As you learned in the previous article, the runCommand method calls the collMod database command, which specifies the candidates collection. The method also calls the validator command. The command’s argument is an empty document (curly brackets), which means that no rules will be defined. If rules already exist, they will be removed.
The second step is to remove any documents in the collection. For this, you can use a deleteMany statement to specify that all documents should be deleted, as in the following example:
|
1 |
db.candidates.deleteMany({}); |
At this point, the candidates collection should contain no validation rules or documents, whether or not it already existed. Now run the following insertMany statement, which adds 10 documents to the collection:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
db.candidates.insertMany([ { "_id": 101, "name": "Drew", "position": "Senior Developer", "dept": 1001, "active": true }, { "_id": 102, "name": "Parker", "position": "Data Scientist", "dept": 1001, "active": true }, { "_id": 103, "name": "Harper", "position": "Marketing Manager", "dept": 1004, "active": true }, { "_id": 104, "name": "Darcy", "position": "Senior Developer", "dept": 1001, "active": false }, { "_id": 105, "name": "Carey", "position": "SEO Specialist", "dept": 1004, "active": false }, { "_id": 106, "name": "Avery", "position": "Network Admin", "dept": 1002, "active": true }, { "_id": 107, "name": "Robin", "position": "Security Specialist", "dept": 1002, "active": true }, { "_id": 108, "name": "Koda", "position": "QA Specialist", "dept": 1001, "active": true }, { "_id": 109, "name": "Jessie", "position": "Brand Manager", "dept": 1004, "active": false }, { "_id": 110, "name": "Dana", "position": "Market Analyst", "dept": 1004, "active": true } ]); |
With the documents in place, you can now create your first view. As I mentioned earlier, a view requires an aggregation pipeline that determines which documents to return. I find it useful to first define the pipeline in a separate query to make sure it will return the correct documents. For example, the following statement calls the aggregate method, which in turn, specifies an aggregation pipeline:
|
1 2 3 |
db.candidates.aggregate( [ { $match: { $and: [ { "dept": 1001 }, { "active": true } ] } } ] ); |
I won’t go in great detail here because aggregations are explained in the fourth article in this series, Building MongoDB Aggregations. In this example, the pipeline includes only one stage, $match, which specifies that the pipeline should return only those documents in which the dept value is 1001 and the active value is true. The aggregate statement should return the following three documents:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ _id: 101, name: 'Drew', position: 'Senior Developer', dept: 1001, active: true } { _id: 102, name: 'Parker', position: 'Data Scientist', dept: 1001, active: true } { _id: 108, name: 'Koda', position: 'QA Specialist', dept: 1001, active: true } |
Once you’re satisfied with your aggregation pipeline, you can use it in a createView statement to define the view, as shown in the following example:
|
1 2 3 4 5 |
db.createView( "rd_candidates", "candidates", [ { $match: { $and: [ { "dept": 1001 }, { "active": true } ] } } ] ); |
The statement begins by calling the db system variable and the createView database method. The method takes three arguments: a name for the view (rd_candidates), the name of the target collection (candidates), and the aggregation pipeline.
When you run this statement, MongoDB adds the view to the hr database. You can then access the view much like any collection in the database. For example, the following find statement returns all three documents in the view:
|
1 |
db.rd_candidates.find(); |
Because a view’s data is not persisted to disk, any changes to the underlying collection are reflected in the documents returned by the view. For example, the following updateOne statement modifies the document with an _id value of 108, changing the active field value from true to false:
|
1 2 3 4 |
db.candidates.updateOne( { "_id" : 108 }, { $set: { "active": false } } ); |
If you rerun the find statement, it will now return only two documents because the view is looking only for documents whose dept value is 1001 and active value is true:
|
1 |
db.rd_candidates.find(); |
You’re not limited to such a basic find statement. You can define whatever type of query you need to return the required data. For example, the following find statement specifies that the position value must be Senior Developer for the view’s documents to be returned:
|
1 |
db.rd_candidates.find( { "position": "Senior Developer" } ); |
The find statement now returns only one document. Of course, you can make your find statements much more specific, depending on the source data and your specific requirements. The main point here is that you can search a view just like searching a collection. However, you cannot modify the data through a view like you can in some relational database systems.
Joining collections in a view
As you saw in the previous section, the key to creating a view is to define an aggregation pipeline. One of the advantages of using a pipeline is that you can include a $lookup stage that retrieves data from a second collection. The $lookup stage makes it possible to create a join condition, similar to the way you can join tables in a relational database.
Before I demonstrate how this works, you need to prepare your test environment by adding another collection to the hr database. The following createCollection statement adds the org collection, and the insertMany statement adds five documents to the collection:
|
1 2 3 4 5 6 7 8 |
db.createCollection("org"); db.org.insertMany([ { "_id": 1001, "dept": "R&D", "location": "Building C" }, { "_id": 1002, "dept": "IT", "location": "Building C" }, { "_id": 1003, "dept": "Purchasing", "location": "Building B" }, { "_id": 1004, "dept": "Marketing", "location": "Building B" }, { "_id": 1005, "dept": "Legal", "location": "Building A" } ]); |
With the collection in place, you can create your aggregation pipeline, once again defining it first within an query. The following aggregate statement begins with a $match stage, followed by several other stages, which are necessary to handle the lookup operation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
db.candidates.aggregate( [ { $match: { "active": false } }, { $lookup: { from: "org", localField: "dept", foreignField: "_id", as: "dept_name" } }, { $project: { name: 1, position: 1, dept_name: "$dept_name.dept" } } , { $unwind: "$dept_name" } ] ); |
The $match stage specifies that the active field value must be false. This stage is followed by a $lookup stage, which performs a left outer join, based on the specified fields. The stage includes the following options:
from. Specifies the target collection, which in this case isorg. The target collection must be in the same database as the primary collection (candidates).localField. A field in the primary collection that matches a field in the target collection. For this example, we’ll use thedeptfield in thecandidatescollection.foreignField. The field in the target collection that contains the matching values. For this example, we’ll use the_idfield in theorgcollection.as. A name for the field returned by the$lookupstage. For this example, we’ll usedept_namefor the returned field name The field is returned as an array that contains the documents whosecandidates.deptvalue matches theorg._idvalue. Because the_idfield is a unique identifier, only one document will be returned per match.
The $lookup stage is followed by the $project stage and $unwind stage. The $project stage specifies which fields to include in the results. It does not include the _id field because it is included by default. It also does not include the active field. Since all the field’s values in the returned documents are false, the field is not needed (unless you want to include it for confirmation).
Notice that the $lookup stage pulls only the name of the department from the dept_name field. Unfortunately, the field name is still returned as an array. This is why the pipeline also includes $unwind stage, which deconstructs the array. Again, refer to the article on aggregating data for more information about these two stages.
When you run the aggregate statement, it returns the four documents whose active value is false, as shown in the following results:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
{ _id: 104, name: 'Darcy', position: 'Senior Developer', dept_name: 'R&D' } { _id: 105, name: 'Carey', position: 'SEO Specialist', dept_name: 'Marketing' } { _id: 108, name: 'Koda', position: 'QA Specialist', dept_name: 'R&D' } { _id: 109, name: 'Jessie', position: 'Brand Manager', dept_name: 'Marketing' } |
Once you’re satisfied with your aggregation, you can plug it into your createView statement, as in the following example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
db.createView( "inactive", "candidates", [ { $match: { "active": false } }, { $lookup: { from: "org", localField: "dept", foreignField: "_id", as: "dept_name" } }, { $project: { name: 1, position: 1, dept_name: "$dept_name.dept" } } , { $unwind: "$dept_name" } ] ); |
The createView statement defines a view named inactive. Notice that the method’s second argument is still candidates because this is the primary collection. After you create the view, you can run the following find statement to verify that the view returns the expected documents:
|
1 |
db.inactive.find(); |
The find statement should return the same four documents returned by the previous aggregate statement.
Updating and deleting views in MongoDB
MongoDB provides two methods for updating a view in MongoDB Shell. The first method is to use the runCommand method, which lets you specify options for updating a view, as shown in the following example:
|
1 2 3 4 5 |
db.runCommand( { collMod: "rd_candidates", viewOn: "candidates", "pipeline": [ { $match: { "dept": 1001 } } ] } ); |
The runCommand statement includes the following three database commands:
collMod. Specifies the target collection or, as in this case, the target view. We’ll be using the view we created above,rd_candidates.viewOn. Specifies the view’s underlying source collection or view, which in this case is thecandidatescollection.pipeline. Defines the updated aggregation pipeline. The pipeline has been simplified to return only those documents with adeptvalue of1001.
After you update the view, you can run the following find statement, which should return the four documents in department 1001:
|
1 |
db.rd_candidates.find(); |
Another method you can use to update a view is to first drop the view and then re-create it. To drop the view, run the following command:
|
1 |
db.rd_candidates.drop(); |
The command calls the db system variable, which is followed by the view’s name. You can then use the drop method that’s available to the view object to remove the view. After you’ve dropped the view, you can run a createView statement that re-creates the view, using the updated pipeline definition:
|
1 2 3 4 5 |
db.createView( "rd_candidates", "candidates", [ { $match: { "dept": 1001 } } ] ); |
As you’ve no doubt figured out, you can also use the drop method simply to remove a view, without re-creating it:
|
1 |
db.rd_candidates.drop(); |
The following command does the same thing with the inactive view:
|
1 |
db.inactive.drop(); |
That’s really all there is to updating and dropping views. It’s up to you which method you use to update a view—the runCommand method or the drop/createView method—as long as you don’t start dropping views that your applications still rely on.
Creating views in MongoDB Compass
I also want to provide you with an overview of how you can use the Compass GUI to create a view. I won’t spend a lot of time on this because the process of creating a view is simply a matter of building an aggregation pipeline and saving it as a view. In in the fifth article in this series, Building MongoDB Aggregations in MongoDB Compass, I explain how to use the GUI to build a pipeline.
Let me demonstrate with a simple example. Start by opening the candidates collection in the main Compass window and then go to the Aggregations tab. Add a $match stage and specify that the active field must be true. The following figure shows what the Aggregations tab should look like at this point.
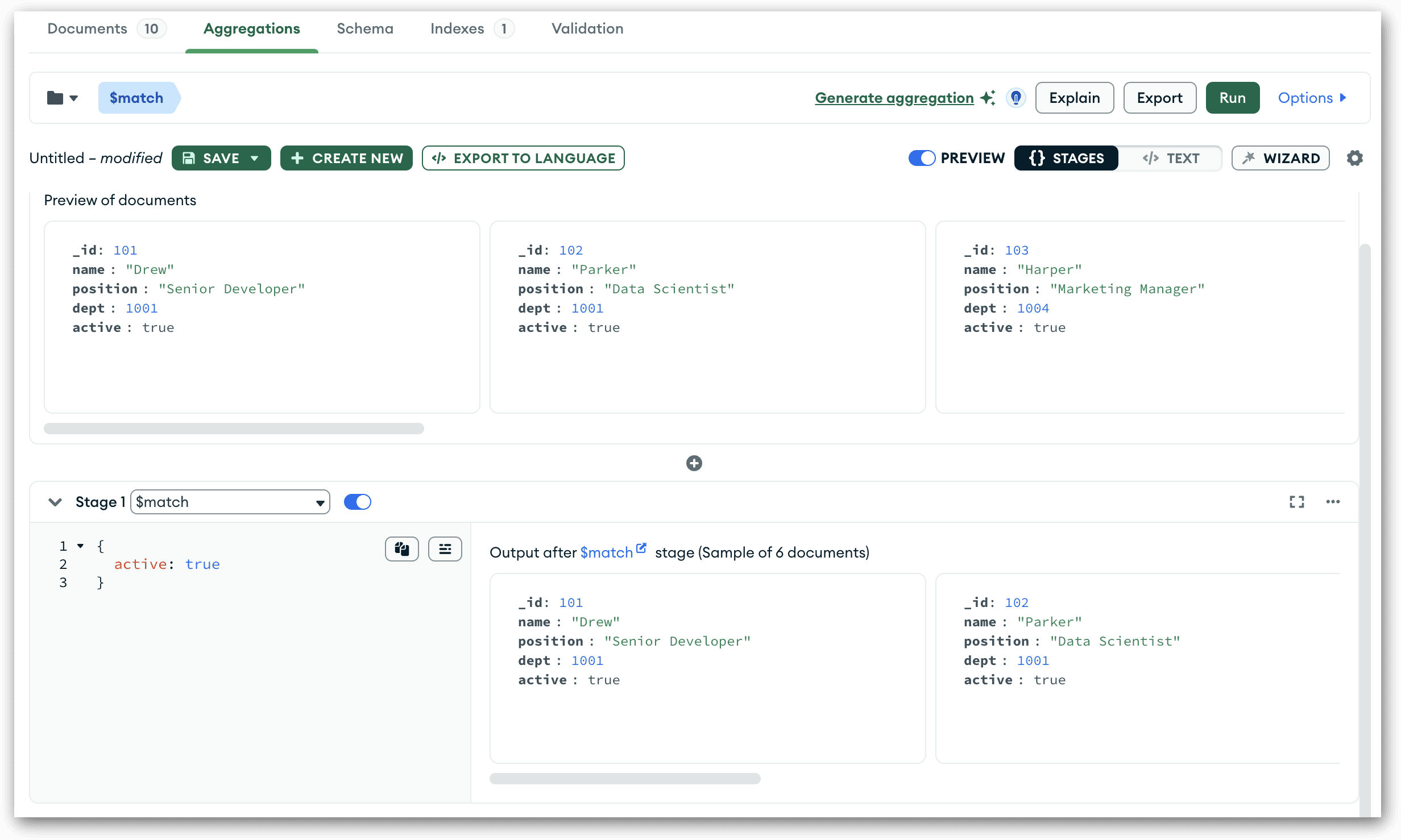
This is the only stage you’ll be adding. You can run the pipeline if you want to verify the pipeline’s documents. Just be sure to return to editing mode when you’re done. Next, click the Save button and select Create view from the drop-down list. When the Create a View dialog box appears, type active in the name text box, and then click Create.
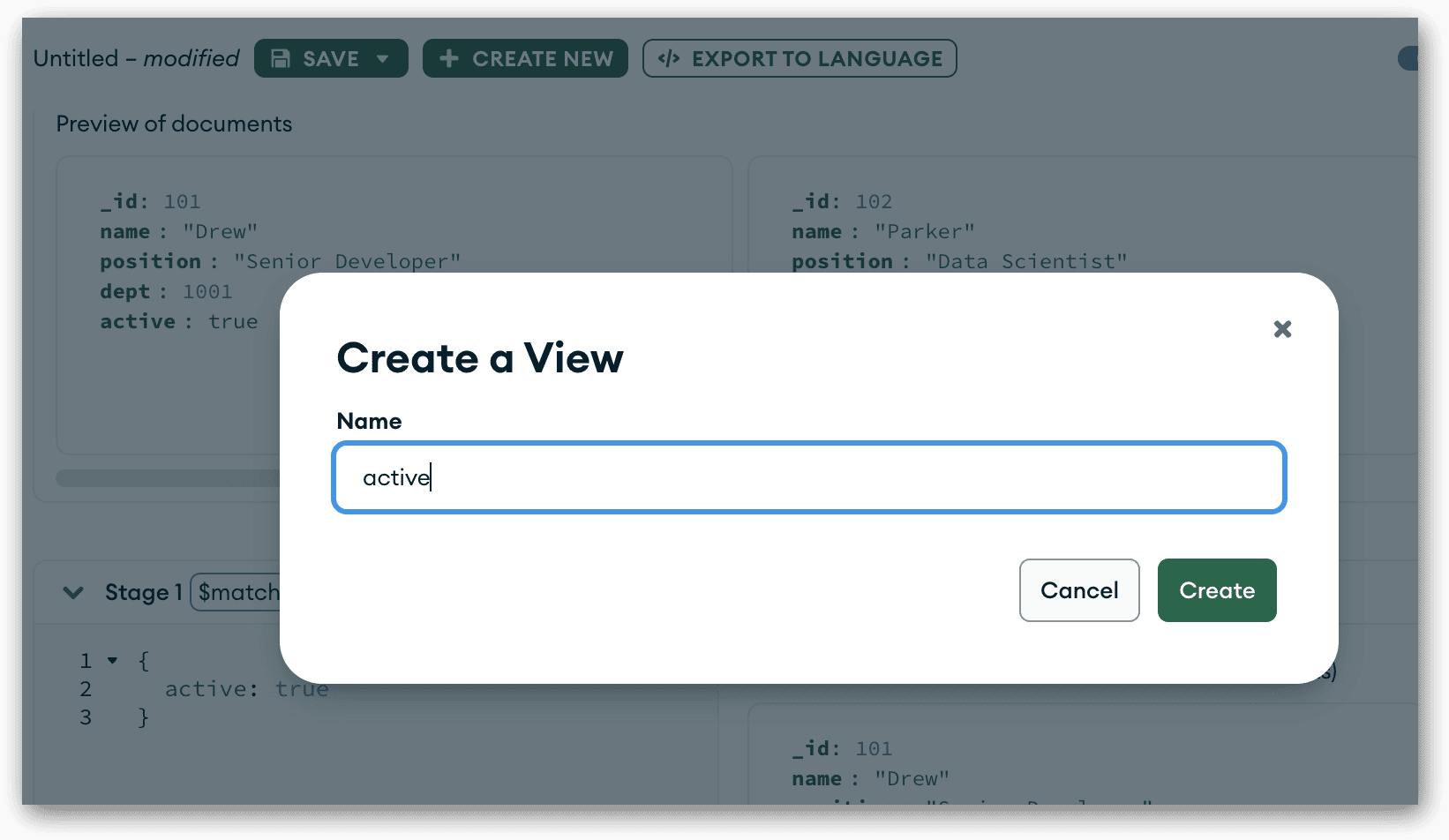
Compass will add the view to the database, open a new tab for the view, and display the documents returned by that view. The following figure shows the documents in Table View.
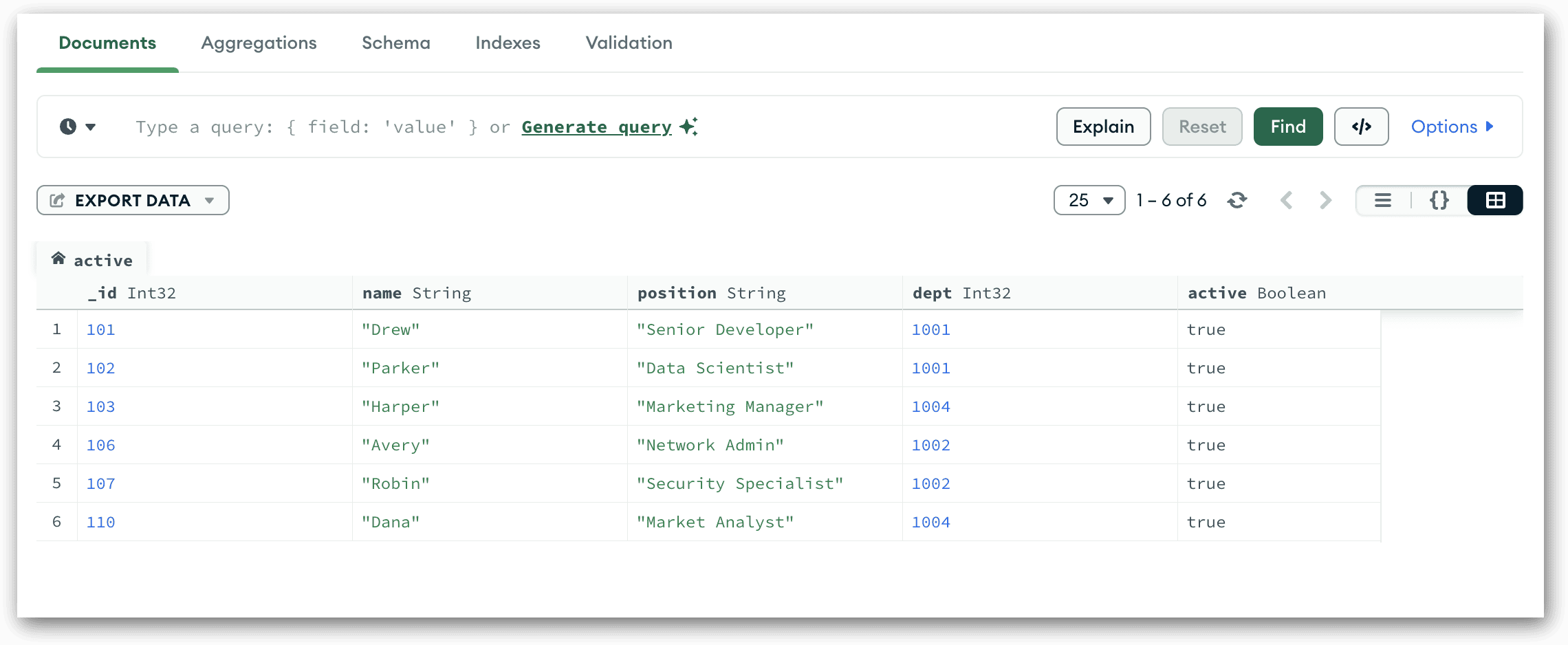
That’s all there is to creating a view in the Compass GUI. That hard part, of course, is building the pipeline, which you must get right to return the documents you need.
Getting started with views in MongoDB
Views are a handy feature in MongoDB because they provide an extra layer of abstraction between a client and the collection’s document structure. Views make it possible to exclude personal and private information and return only the data specified in the view definition. Views also make it easy to build predefined queries that include complex expressions and computed data, as well as pull data from other collections, while taking up relatively little disk space.
You can learn more about views in the MongoDB documentation and other resources. A good place to start is with the MongoDB topic Views. This will also point you to details about working with materialized views. The better you understand how to work with views and create them in your databases, the more you’ll benefit from their use. Indeed, views can be a valuable tool in supporting most data-driven applications.



Load comments