
By default, SQL Server adopts a pessimistic approach to concurrency, acquiring locks in order to avoid read phenomena such as dirty reads, non-repeatable reads and phantom reads, depending on the required ANSI isolation level. As a result, readers block writers and writers block readers.
However, the ANSI SQL definitions of each of the transaction isolation levels specify only which of the behaviors each level allows, not how to implement them. Under an alternative concurrency model, enabled via snapshot-based isolation, SQL Server can prevent some or all of these read phenomena, depending on the mode of snapshot-based isolation in use, without the need to acquire locks, therefore greatly reducing blocking in the database.
In order to achieve this “optimistic” concurrency, SQL Server uses a row versioning technique, whereby it stores in tempdb copies (versions) of all the previously committed versions of any data rows, since the beginning of the oldest open transaction (i.e. it keeps those copies as long as there are any transactions that might need to access them). The space in tempdb used to store previous versions of changed rows is the version store. When using this row versioning, readers do not block writers, and writers do not block readers (though writers do still take locks and will block other writers).
In this article, we’ll discuss:
- row versioning and how it works
- snapshot-based isolation, the new modes of operation it introduces, snapshot isolation (SI) and read committed snapshot isolation (RCSI), and how they work
- the potential for update conflicts in SI mode
- monitoring and managing the version store – especially disk space usage.
Some people consider row versioning concurrency to be the ultimate troubleshooting technique to avoid most, though not all, blocking problems. While it’s true that row versioning concurrency greatly reduces SQL Server’s dependence on the use of locks to enforce ACID-compliance for its transactions, it does bring with it a whole new set of troubleshooting techniques, and a few problematic issues. As such, I prefer to view it as simply an alternative way to handle concurrent database access.
Overview of Row Versioning
Before row versioning concurrency was introduced in SQL Server 2005, the only way to reduce blocking, and increase concurrency (without rewriting code) was to use READ UNCOMMITTED isolation, whereby readers are allowed to perform dirty reads (reading whatever data is there at the time, regardless of whether it’s currently being updated) and so aren’t blocked by writers. The downsides to this are clear and we’ve discussed them previously. If our results must always be based on committed data, we need to be willing to wait for changes to be committed.
With SQL Server 2005 and later, we have a better, row versioning alternative. In fact, two better options, in the form of the two flavors of snapshot-based isolation: snapshot isolation and a non-blocking flavor of READ COMMITTED isolation called “read committed snapshot isolation.”
These snapshot-based isolation levels rely on row versioning, rather than locking, to prevent read phenomena. Row versioning works, as we’ll discuss in more detail in the next section, by making any transaction that changes data store the old row versions in an area of tempdb called the version store. By keeping the old versions of the data around, a “snapshot” of the database (or a part of the database) can be constructed from these old versions. The term “snapshot” refers to the set of rows that are valid for the point in time of the operation being performed.
RCSI prevents dirty reads without the need for transactions to acquire shared locks when reading data. Instead of blocking when unable to acquire a shared lock, if a required database page is being modified, the reader retrieves, from the version store, the previously committed values of the set of rows it needs. In this case, it retrieves a snapshot of the data as it existed at the time the current statement started. RSCI does not prevent non-repeatable reads or phantoms.
Use of SI prevents dirty reads, non-repeatable reads, and phantom reads, again without the need for reading transactions to acquire locks; the readers simply retrieve a snapshot of the data, as it existed at the time the current transaction started.
This is the big difference between row versioning and pessimistic concurrency: with the former, writers and readers will not block each other. In other words, using locking terminology, a session requesting an exclusive lock will not block when another session is reading data in the requested resource and, conversely, a session trying to read data will not block when the requested resource currently has an exclusive lock.
In this way, system concurrency is increased. Note, however, that SQL Server still acquires locks during data modification operations, so writers will still block writers, and everything we’ve discussed previously about lock types, lock modes, and lock duration is still relevant to row versioning.
In order for the row versioning mechanism to work correctly, SQL Server must keep old versions of any row that a transaction updates or deletes. If multiple updates are made to the same row, then multiple older versions of the row might need to be maintained, and these multiple older versions must be maintained for as long as there are any transactions that might need to access them. For these reasons, we often refer to row versioning as multi-version concurrency control.
As you can imagine, to support the storing of multiple older versions of rows in the version store may require a lot of additional disk space in the tempdb database. Just as all databases in a SQL Server instance share the tempdb database, all databases that use row versioning share the same space in the version store.
In addition, we cannot set a maximum or minimum size for the version store; all space in the tempdb database is available for use by any process, in any database that needs tempdb space, for any reason, be it for user-defined temporary tables, system worktables, or the version store.
How Row Versioning Works
When we update a row in a table or index, the new row is marked with a value called the transaction sequence number (XSN) of the transaction that is doing the update. The XSN is a monotonically increasing number, which is unique within each SQL Server database. When updating a row, the previous version of the row is stored in the version store, and the new version of the row contains a pointer to the old version of the row in the version store. The new row also stores the XSN value, reflecting the time the row was modified.
Each old version of a row in the version store might, in turn, contain a pointer to an even older version of the same row. All the old versions of a particular row are chained together in a linked list, and SQL Server might need to follow several pointers in a list to reach the right version. The version store must retain versioned rows for as long as there are operations that might require them. As long as a transaction is open, all versions of rows that have been modified by that transaction must be kept in the version store, and version of rows read by a statement (RCSI) or transaction (SI) must be kept in the version store as long as that statement or transaction is open. In addition, the version store must also retain versions of rows modified by now-completed transactions if there are any older versions of the same rows.
In Figure 1, Transaction T3 generates the current version of the row, and it is stored in the normal data page. The previous versions of the row, generated by Transaction T2 and Transaction Tx, are stored in pages in the version store (in tempdb).
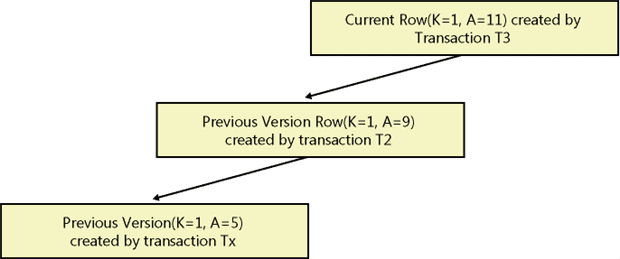
Figure 1: Versions of a row.
Before switching to a row-versioning-based isolation level, for reduced blocking and improved concurrency, we must carefully consider the tradeoffs. In addition to requiring extra management to monitor the increased use of tempdb for the version store, versioning slows the performance of UPDATE operations, due to the extra work involved in maintaining old versions. The same applies, to a much lesser extent, for DELETE operations, since the version store must maintain at most one older version of the deleted row.
Be aware that data modification operations will bear this cost, even if there are no current readers of the data. Once we configure a database to use one of the snapshot-based isolation levels, every UPDATE and DELETE operation will create a version. Any readers using row versioning will incur the extra cost of traversing the pointers to find the appropriate version of the requested row.
In addition, remember that the optimistic concurrency model of SI assumes (optimistically) that not many update conflicts will occur. As such, it may not be suited to cases where we expect many concurrent updates to the same rows.
Under snapshot-based isolation, writers don’t block readers, but simultaneous writers are still not allowed. In the default pessimistic model, the first writer will block all subsequent writers but, using SNAPSHOT isolation, subsequent writers could receive error messages regarding update conflicts, and the application would need to resubmit the original request. For reasons that we’ll discuss in a later section, these update conflicts will occur only when using SI, not with the enhanced read committed snapshot isolation level.
Snapshot-based Isolation Levels
As noted previously, SQL Server provides two types of snapshot-based isolation, both of which use row versioning to maintain the snapshot (the set of rows valid for the point in time the operation was performed):
- read committed snapshot isolation (RCSI) – queries return committed data as of the beginning of the current statement
- snapshot isolation (SI) – queries return committed data as of the beginning of the current transaction
Enabling snapshot-based isolation
Let’s first see how to enable each flavor, and then we’ll examine how each one works.
Enabling RCSI
We enable and disable the first type, RCSI, with the ALTER DATABASE command, as shown in Listing 1.
|
1 2 |
ALTER DATABASE AdventureWorks SET READ_COMMITTED_SNAPSHOT ON |
Listing 1: Enabling RCSI in the AdventureWorks database.
Once such a command has completed, no further changes are required, and RCSI will be the default isolation level for that database. Any transaction that would have operated under the default READ COMMITTED isolation will run under RCSI. Of course, we can change a connection to operate in another isolation level besides READ COMMITTED, but any READ COMMITTED transactions will operate using RCSI.
Ironically, for an isolation level intended to help avoid blocking, the ALTER DATABASE command in Listing 1 will block if there are any connections in the database other than the one issuing the command. Until the change is successful, the database continues to operate as if it is not in RCSI mode.
We can avoid the blocking by specifying a TERMINATION clause for the ALTER command, as shown in Listing 2.
|
1 2 |
ALTER DATABASE AdventureWorks SET READ_COMMITTED_SNAPSHOT ON WITH NO_WAIT |
Listing 2: Enabling RCSI in the AdventureWorks database without blocking.
If there are any users in the database, rather than block, Listing 2 will fail with the following error:
|
1 |
Msg 5011, Level 14, State 5, Line 1 User does not have permission to alter database 'AdventureWorks', the database does not exist, or the database is not in a state that allows access checks. Msg 5069, Level 16, State 1, Line 1 ALTER DATABASE statement failed. |
Alternatively, we could specify one of the ROLLBACK termination options, to kill any current database connections. For full details on the various termination options, please see the ALTER DATABASE command in Books Online.
Enabling SI
We must enable the second type of snapshot-based isolation,SI, in two places. First, we must enable it at the database level, just as for RCSI, using an ALTER DATABASE command such as that showing in Listing 3.
|
1 2 |
ALTER DATABASE AdventureWorks SET ALLOW_SNAPSHOT_ISOLATION ON; |
Listing 3: Enabling SI in the AdventureWorks database.
It must also be set at the session level, just as for any of the non-default ANSI levels, using SET TRANSACTION ISOLATION LEVEL SNAPSHOT.
When altering the database to allow SI, the presence of other connections will not necessarily block the command in Listing 3 but the presence of any active (i.e. data-modifying) transactions in the database, will block the ALTER DATABASE command. However, this does not mean that there is no effect until the statement completes. Changing the database to allow full SI can be a deferred operation. The database can actually be in one of four states with regard to ALLOW_SNAPSHOT_ISOLATION. It can be ON or OFF, but it can also be IN_TRANSITION_TO_ON or IN_TRANSITION_TO_OFF.
When we ALTER a database to ALLOW_SNAPSHOT_ISOLATION, SQL Server waits for the completion of all currently active transactions and in the meantime the database status is set to IN_TRANSITION_TO_ON. At this point, any new UPDATE or DELETE transactions will start generating versions in the version store.
During the transition period, we can open a new session, and execute the SET TRANSACTION ISOLATION LEVEL SNAPSHOT command successfully, but no new SNAPSHOT transactions can actually start until the transactions that were active when we issued the ALTER DATABASE are complete. This is because any data modification transactions that were already running at that time will not be storing row versions, as the data is changed, so any new SI transactions would have no committed versions of the data to read.
If we try to SELECT data in a SI session, while the database is still in a transition state, we see the following error message:
|
1 |
Msg 3956, Level 16, State 1, Line 1 Snapshot isolation transaction failed to start in database 'AdventureWorks' because the ALTER DATABASE command which enables snapshot isolation for this database has not finished yet. The database is in transition to pending ON state. You must wait until the ALTER DATABASE Command completes successfully. |
As soon as all transactions have finished that were active when the ALTER command began, the ALTER can finish and the state change will be complete. The database will now be in the state ALLOW_SNAPSHOT_ISOLATION.
Taking the database out of ALLOW_SNAPSHOT_ISOLATION mode is similar and, again, there is a transition phase.
- SQL Server waits for the completion of all active transactions, and the database status is set to
IN_TRANSITION_TO_OFF. - New snapshot transactions cannot start.
- Existing snapshot transactions still execute snapshot scans, reading from the version store.
- New transactions continue generating versions.
Working with RCSI
RCSI is a statement-level snapshot isolation, which means any queries will see the most recent committed values as of the beginning of the statement(as opposed to the beginning of the transaction). Remember that RCSI is just a non-locking variation of READ COMMITTED isolation, so there is no guarantee that read operations are repeatable.
The best way to understand what this means is to see it in action. Example 1 shows two transactions running in the AdventureWorks database, which has been enabled for RCSI. Before either transaction starts running, the ListPrice value of Product 922 is 3.99.
| Time | Transaction 1 | Transaction 2 |
| 1 | BEGIN TRAN |
BEGIN TRAN |
| 2 | SELECT ListPrice |
|
| 3 | COMMIT TRAN |
SELECT ListPrice |
| 4 | COMMIT TRAN |
Example 1: A SELECT running in RCSI.
We should note that at Time = 2, the change made by Transaction 1 is still uncommitted, so it still holds a lock on the row for ProductID = 922. However, Transaction 2 will not block on that lock; it will have access to an old version of the row with a last committed ListPrice value of 3.99. After Transaction 1 has committed and released its lock, Transaction 2 will see the new value of the ListPrice.
Again, keep in mind that RCSI is just a variation of the default isolation level READ COMMITTED. The same behaviors, indicated back in Table 1-1, are allowed and disallowed. In READ COMMITTED isolation, the only guarantee is that we won’t read dirty (uncommitted) data. With pessimistic concurrency, SQL Server prevents us from reading the dirty data by locking it, and preventing other processes from reading that data, until the transaction commits or rolls back, and the data is no longer dirty. With row versioning concurrency, SQL Server prevents us from reading the dirty data by providing us with older versions of the data that were committed.
The biggest benefit of RCSI is that we can introduce greater concurrency because readers do not block writers and writers do not block readers. Don’t forget that writers do still block writers, because the normal locking behavior applies to all UPDATE, DELETE, and INSERT operations. No SET options are required for any session to take advantage of RCSI, so we can reduce the concurrency impact of blocking and deadlocking without any change in our applications.
Working with SI
SI offers a transactionally consistent view of the data. Any data read will be the most recent committed version, as of the beginning of the transaction, rather than the statement. This prevents, not only dirty reads, but also non-repeatable reads and phantom reads. A key point to keep in mind is that the transaction does not start at the BEGIN TRAN statement; for the purposes of SI, a transaction starts the first time the transaction accesses any data in the database.
As an example of SI, let’s revisit our example from the RCSI section, and see how the behavior differs. If you’re going to run this example, make sure you set READ_COMMITTED_SNAPSHOT to OFF for the database. Example 2 shows two transactions running in the AdventureWorks database, which has been enabled for SI by setting ALLOW_SNAPSHOT_ISOLATION to ON. Before either transaction starts running, the ListPrice value of Product 923 is 4.99.
| Time | Transaction 1 | Transaction 2 |
| 1 | BEGIN TRAN |
|
| 2 | UPDATE Production.Product |
SET TRANSACTION ISOLATION |
| 3 | BEGIN TRAN |
|
| 4 | SELECT ListPrice |
|
| 5 | COMMIT TRAN |
|
| 6 | SELECT ListPrice |
|
| 7 | COMMIT TRAN |
|
| 8 | SELECT ListPrice |
Example 2: A SELECT running in a SNAPSHOT transaction.
Even though Transaction 1 has committed, Transaction 2 continues to return the initial value it read of 4.99, until Transaction 2 completes. Only after Transaction 2 is done, will the connection read a new value for ListPrice.
Viewing database state
We can enable a database for SI and/or RCSI but enabling one does not automatically enable or disable the other. We enable or disable each one individually using separate ALTER DATABASE commands.
The catalog view sys.databases contains several columns that report on the snapshot isolation state of a database. The column snapshot_isolation_state has possible values of 0 to 4, indicating each of the four possible SI states, and the snapshot_isolation_state_desc column spells out the state. Table 1 summarizes what each state means.
| Snapshot Isolation State | Description |
| OFF | SI is disabled in the database. In other words, transactions in snapshot isolation are not allowed. Database versioning state is initially set to OFF during recovery. If versioning is enabled, versioning state is set to ON after recovery. |
| IN_TRANSITION_TO_ON | The database is in the process of enabling SI. It waits for the completion of all update transactions that were active when the ALTER DATABASE command was issued. New update transactions in this database start paying the cost of versioning by generating row versions. Transactions under snapshot isolation cannot start. |
| ON | SI is enabled. New snapshot transactions can start in this database. Existing snapshot transactions (in another snapshot-enabled database) that start before versioning state is turned ON cannot do a snapshot scan in this database because the snapshot those transactions are interested in is not properly generated by the update transactions. |
| IN_TRANSITION_TO_OFF | The database is in the process of disabling the SI state and is unable to start new snapshot transactions. Update transactions still pay the cost of versioning in this database. Existing snapshot transactions can still do snapshot scans. IN_TRANSITION_TO_OFF does not become OFF until all existing transactions finish. |
Table 1: Possible values for database option ALLOW_SNAPSHOT_ISOLATION.
The is_read_committed_snapshot_on column has a value of 0 or 1. Table 2 summarizes what each state means.
READ_COMMITTED_SNAPSHOT State |
Description |
| 0 | READ_COMMITTED_SNAPSHOT is disabled.
Database versioning state is initially set to 0 during recovery. If |
| 1 | READ_COMMITTED_SNAPSHOT is enabled. Any query with READ COMMITTED isolation will execute in the non-blocking mode. |
Table 2: Possible values for the database option READ_COMMITTED_SNAPSHOT.
We can see the values of each of these snapshot states for all our databases with the query in Listing 4.
|
1 2 3 4 5 |
SELECT name , snapshot_isolation_state_desc , is_read_committed_snapshot_on , * FROM sys.databases |
Listing 4: Determining snapshot setting for all databases.
Update conflicts
One crucial difference between the two row versioning concurrency levels is that SI can potentially result in update conflicts when a process (such as a transaction that first reads data and then tries to update it) sees the same data for the duration of its transaction and is not blocked even though another process is changing the same data.
Example 3 illustrates two transactions attempting to update the Quantity value of the same row in the ProductInventory table in the AdventureWorks database. Two clerks receive shipments of a product with ProductID 872, and attempt to update their inventory. The AdventureWorks database has ALLOW_SNAPSHOT_ISOLATION set to ON, and before either transaction starts, the Quantity value of Product 872 is 324.
| Time | Transaction 1 | Transaction 2 |
| 1 | SET TRANSACTION ISOLATION |
|
| 2 | BEGIN TRAN |
|
| 3 | SELECT Quantity |
|
| 4 | BEGIN TRAN |
SELECT ListPrice |
| 5 | UPDATE |
|
| 6 | COMMIT TRAN |
|
| 7 | Process will receive Error 3960. |
Example 3: An update conflict in snapshot isolation.
The conflict happens because Transaction 2 started when the Quantity value was 324. When Transaction 1 updated that value, SQL Server saved the row version with a value of 324 in the version store. Transaction 2 will continue to read that row for the duration of the transaction. If SQL Server allowed both UPDATE operations to succeed, we would have a classic lost update situation. Transaction 1 added 200 to the quantity, and then Transaction 2 would add 300 to the original value and save that. The 200 added by Transaction 1 would be completely lost. SQL Server will not allow that.
When Transaction 2 first tries to do the UPDATE, it doesn’t get an error immediately – it is simply blocked. Transaction 1 has an exclusive lock on the row, so when Transaction 2 attempts to get an exclusive lock, it is blocked. If Transaction 1 had rolled back its transaction, Transaction 2 would have been able to complete its UPDATE. However, Transaction 1 committed, so SQL Server detects a conflict and generates the following error:
|
1 |
Msg 3960, Level 16, State 2, Line 1 Snapshot isolation transaction aborted due to update conflict. You cannot use snapshot isolation to access table 'Production.ProductInventory' directly or indirectly in database 'AdventureWorks' to update, delete, or insert the row that has been modified or deleted by another transaction. Retry the transaction or change the isolation level for the update/delete statement. |
Conflicts are possible only with SI (and not with RCSI) because SI is transaction based, not statement based. If we executed the example in Example 3 in a RCSI-enabled database, the UPDATE statement executed by Transaction 2 would not use the old value of the data. It would be blocked when trying to read the current Quantity and then, when Transaction 1 finished, it would read the new updated Quantity as the current value and add 300 to that. Neither update would be lost.
When working in SI, be aware that conflicts can happen. We can minimize their likelihood but, as with deadlocks, there is no guarantee that conflicts will never happen. We must write applications to handle conflicts appropriately, and not assume that the UPDATE has succeeded. If conflicts occur occasionally, consider it part of the price to pay for use of SI. If they occur too often, you might need to take extra steps.
If update conflicts are proving to be a problem, consider carefully whether SI is necessary for that database. If it is, determine whether the statement-based RCSI might offer the required behavior without the cost of detecting and dealing with conflicts.
If full SI really is required, then you might consider using the UPDLOCK query hint to prevent the conflicts. In our example, Transaction 2 could use UPDLOCK on its initial SELECT as shown in Listing 5.
|
1 2 3 |
SELECT Quantity FROM Production.ProductInventory WITH ( UPDLOCK ) WHERE ProductID = 872; |
Listing 5: Using UPDLOCK to prevent update conflicts in SI.
The UPDLOCK hint will force SQL Server to acquire UPDATE locks for Transaction 2, on the selected row. When Transaction 1 then tries to update that row, it will block. It is not using SI, so it will not be able to see the previous value of Quantity. Transaction 2 can perform its UPDATE because Transaction 1 is blocked, and it will commit. Transaction 1 can then perform its UPDATE on the new value of Quantity, and neither UPDATE will be lost.
Summary of snapshot-based isolation levels
SI and RCSI are similar, in the sense that they are based on versioning of rows in a database. However, there are some key differences in how we enable these options from an administration perspective, and in how they affect our applications. We’ve discussed many of these differences already but, for completeness, Table 3 lists both the similarities and the differences between the two types of snapshot-based isolation.
| Snapshot Isolation State | Description |
| OFF | SI is disabled in the database. In other words, transactions in snapshot isolation are not allowed. Database versioning state is initially set to OFF during recovery. If versioning is enabled, versioning state is set to ON after recovery. |
| IN_TRANSITION_TO_ON | The database is in the process of enabling SI. It waits for the completion of all update transactions that were active when the ALTER DATABASE command was issued. New update transactions in this database start paying the cost of versioning by generating row versions. Transactions under snapshot isolation cannot start. |
| ON | SI is enabled. New snapshot transactions can start in this database. Existing snapshot transactions (in another snapshot-enabled database) that start before versioning state is turned ON cannot do a snapshot scan in this database because the snapshot those transactions are interested in is not properly generated by the update transactions. |
| IN_TRANSITION_TO_OFF | The database is in the process of disabling the SI state and is unable to start new snapshot transactions. Update transactions still pay the cost of versioning in this database. Existing snapshot transactions can still do snapshot scans. IN_TRANSITION_TO_OFF does not become OFF until all existing transactions finish. |
Table 1: Possible values for database option ALLOW_SNAPSHOT_ISOLATION.
The is_read_committed_snapshot_on column has a value of 0 or 1. Table 2 summarizes what each state means.
| SNAPSHOT | READ COMMITTED SNAPSHOT |
The database must be configured to allow SI, and the session must issue the command SET TRANSACTION ISOLATION LEVEL SNAPSHOT. |
The database must be configured to use RCSI, and sessions must use the default isolation level. No code changes are required. |
| Enabling SI for a database is an online operation. It allows the DBA to turn on versioning for one particular application, such as big reporting snapshot transactions, and turn off versioning after the reporting transaction has started to prevent new snapshot transactions from starting.
Turning on SI state in an existing database is synchronous. When the ALTER DATABASE command is given, control does not return to the DBA until all existing update transactions that need to create versions in the current database finish. At this time, ALLOW_SNAPSHOT_ISOLATION is changed to ON. Only then can users start a snapshot transaction in that database. Turning off SI is also synchronous. |
Enabling RCSI for a database requires an X lock on the database. All users must be kicked out of a database to enable this option. |
| There are no restrictions on active sessions in the database when this database option is enabled. | There should be no other sessions active in the database when you enable this option. |
If an application runs a snapshot transaction that accesses tables from two databases, the DBA must turn on ALLOW_SNAPSHOT_ISOLATION in both databases before the application starts a snapshot transaction. |
RCSI is really a table-level option, so the table from each database can have its own individual setting. One table might get its data from the version store, and the other table will be reading only the current versions of the data. There is no requirement that both databases must have the RCSI option enabled. |
The IN_TRANSITION versioning states do not persist. Only the ON and OFF states are remembered on disk. |
The IN_TRANSITION versioning states do not persist. Only the ON and OFF states are remembered on disk. |
When a database is recovered after a server crash, shut down, restored, attached, or made ONLINE, all versioning history for that database is lost. If database versioning state is ON, we can allow new snapshot transactions to access the database, but we must prevent previous snapshot transactions from accessing the database. Those previous transactions are interested in a point in time before the database recovers. |
N/A. This is an object-level option; it is not at the transaction level. |
If the database is in the IN_TRANSITION_TO_ON state, ALTER DATABASE SET ALLOW_SNAPSHOT_ISOLATION OFF will wait for about 6 seconds and might fail if the database state is still in the IN_TRANSITION_TO_ON state. The DBA can retry the command after the database state changes to ON. This is because changing the database versioning state requires a U lock on the database, which is compatible with regular users of the database who get an S lock but not compatible with another DBA who already has a U lock to change the state of the database. |
N/A. This option can be enabled only when there is no other active session in the database. |
| For read-only databases, versioning is automatically enabled. You still can use ALTER DATABASE SET ALLOW_SNAPSHOT_ISOLATION ON for a read-only database. If the database is made read-write later, versioning for the database is still enabled. | Similar. |
| If there are long-running transactions, a DBA might need to wait a long time before the versioning state change can finish. A DBA can cancel the wait, and versioning state will be rolled back and set to the previous one. | N/A. |
You cannot use ALTER DATABASE to change database versioning state inside a user transaction. |
Similar. |
You can change the versioning state of tempdb. The versioning state of tempdb is preserved when SQL Server restarts, although the content of tempdb is not preserved. |
You cannot turn this option ON for tempdb. |
| You can change the versioning state of the master database. | You cannot change this option for the master database. |
| You can change the versioning state of model. If versioning is enabled for model, every new database created will have versioning enabled as well. However, the versioning state of tempdb is not automatically enabled if you enable versioning for model. | Similar, except that there are no implications for tempdb. |
You can turn this option ON for msdb. |
You cannot turn on this option ON for msdb because this can potentially break the applications built on msdb that rely on blocking behavior of READ COMMITTED isolation. |
| A query in an SI transaction sees data that was committed before the start of the transaction, and each statement in the transaction sees the same set of committed changes. | A statement running in RCSI sees everything committed before the start of the statement. Each new statement in the transaction picks up the most recent committed changes. |
| SI can result in update conflicts that might cause a rollback or abort the transaction. | There is no possibility of update conflicts. |
Table 3: SNAPSHOT vs. READ COMMITTED SNAPSHOT isolation.
The Version Store
As soon as we enable a SQL Server database for ALLOW_SNAPSHOT_ISOLATION or READ_COMMITTED_SNAPSHOT, all UPDATE and DELETE operations start generating versions of the previously committed rows, and they store those row versions in the version store, on data pages in tempdb. SQL Server must retain version rows in the version store only as long as there are snapshot transactions and queries that might need them. SQL Server provides several DMVs that contain information about active snapshot transactions and the version store. We won’t cover all the details of all of those DMVs, but we’ll look at some of the crucial ones that can help us determine how much use is being made of the version store, and what snapshot transactions might be affecting the versions that need to be kept available.
The first DMV we’ll look at, sys.dm_tran_version_store, contains information about the actual rows in the version store. Run the code in Listing 6 to make a copy of the Production.Product table, and then turn on ALLOW_SNAPSHOT_ISOLATION in the AdventureWorks database. Finally, verify that the option is ON and that there are currently no rows in the version store. Remember to close any active transactions currently using AdventureWorks.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
USE AdventureWorks; IF EXISTS ( SELECT 1 FROM sys.tables WHERE name = 'NewProduct' ) DROP TABLE NewProduct; GO SELECT * INTO NewProduct FROM Production.Product; GO ALTER DATABASE ADVENTUREWORKS SET ALLOW_SNAPSHOT_ISOLATION ON; GO SELECT name , snapshot_isolation_state_desc , is_read_committed_snapshot_on FROM sys.databases WHERE name = 'AdventureWorks'; GO SELECT COUNT(*) FROM sys.dm_tran_version_store GO |
Listing 6: Enabling a database for SNAPSHOT isolation.
Having verified that ALLOW_SNAPSHOT_ISOLATION is ON (and making sure READ_COMMITTED_SNAPSHOT is OFF) and there are no rows in the version store, we can proceed. Listing 7 runs a simple UPDATE statement on the NewProduct table and then re-examines the version store. What we should see is that, as soon as we enable ALLOW_SNAPSHOT_ISOLATION, SQL Server starts storing row versions, even if there are no snapshot transactions that need to read those versions.
|
1 2 3 4 5 6 |
UPDATE NewProduct SET ListPrice = ListPrice * 1.1; GO SELECT COUNT(*) FROM sys.dm_tran_version_store; GO |
Listing 7: Checking the version store after an update of data in an SI-enabled database.
We should now see 504 rows in the version store, because there are 504 rows in the NewProduct table. SQL Server writes to tempdb the previous version of each row, prior to the update.
Snapshot-based isolation and heavily updated databases
SQL Server starts generating versions in tempdb as soon as we enable a database for one of the snapshot-based isolation levels. In a heavily updated database, this can affect the behavior of other queries that use tempdb, as well as the server itself.
The version store maintains a linked list of previously committed versions of each row in the database. The current row points to the next older row, which can point to an older row, and so on. The end of the list is the oldest version of that particular row. To support row versioning, a row needs 14 additional bytes of overhead information: 8 bytes are for the pointer to the previous version of the row, and 6 bytes are to keep track of the XSN representing the time the row was modified. If a database is in a snapshot-based isolation level, all changes to both data and index rows must be versioned. A snapshot query traversing an index still needs access to index rows pointing to the older (versioned) rows. Therefore, in the index levels, we might have old values, as ghosts, existing simultaneously with the new value, and the indexes can require more storage space.
SQL Server will remove the extra 14 bytes of versioning information if we change the database to a non-snapshot isolation level. Having changed the database option, each time we update a row containing versioning information, SQL Server removes the versioning bytes.
Management of the version store
SQL Server manages the version store size automatically, and maintains a cleanup thread to make sure it does not keep versioned rows around longer than needed. For queries running under SI, the version store retains the row versions until the transaction that modified the data completes and the transactions containing any statements that reference the modified data complete. For SELECT statements running under RCSI, a particular row version is no longer required, and is removed, once the SELECT statement has executed.
SQL Server performs the regular cleanup function as a background process, which runs every minute and reclaims all reusable space from the version store. If tempdb actually runs out of free space, SQL Server calls the cleanup function and will increase the size of the files, assuming we configured the files for auto-grow. If the disk gets so full that the files cannot grow, SQL Server will stop generating versions. If that happens, any snapshot query that needs to read a version that was not generated due to space constraints will fail.
Although a full discussion of monitoring and troubleshooting the tempdb and the version store is beyond the scope of this book, note that more than a dozen performance counters can help, including counters to keep track of transactions that use row versioning. The counters below are contained in the SQLServer :Transactions performance object. SQL Server Books Online provides additional details and additional counters.
- Free space in
tempdb– This counter monitors the amount of free space in thetempdbdatabase. We can track this value to detect whentempdbis running out of space, which might lead to problems keeping all the necessary version rows. - Version store size – This counter monitors the size in KB of the version store. Monitoring this counter can help determine a useful estimate of the additional space you might need for
tempdb. - Version generation rate and version cleanup rate – These counters monitor the rate at which space is acquired and released from the version store, in KB per second.
- Update conflict ratio – This counter monitors the ratio of update snapshot transactions that have update conflicts. It is the ratio of the number of conflicts compared to the total number of update snapshot transactions.
- Longest transaction running time – This counter monitors the longest running time in seconds of any transaction using row versioning. It can be used to determine whether any transaction is running for an unreasonable amount of time, as well as helping us to determine the maximum size needed in
tempdbfor the version store. - Snapshot transactions – This counter monitors the total number of active snapshot transactions.
Snapshot transaction metadata
Besides sys.dm_tran_version_store, two other important DMVs for observing snapshot transaction behavior are sys.dm_tran_transactions_snapshot, and sys.dm_tran_active_snapshot_database_transactions.
All three of these views contain a column called transaction_sequence_num, which is the XSN discussed earlier. Each transaction is assigned a monotonically increasing XSN value when it starts a snapshot read, or when it writes data in a snapshot-enabled database. The XSN is reset to 0 when SQL Server is restarted. Transactions that do not generate version rows and do not use snapshot scans will not receive a XSN.
Another column, transaction_id, is also used in some of the snapshot transaction metadata. A transaction ID is a unique identification number assigned to the transaction. It is used primarily to identify the transaction in locking operations. However, it can also help us to identify which transactions are involved in snapshot operations. The transaction ID value is incremented for every transaction across the whole server, including internal system transactions so, regardless of whether or not that transaction is involved in any snapshot operations, the current transaction ID value is usually much larger than the current XSN.
We can check current transaction number information using the view sys.dm_tran_current_transaction, which returns a single row containing the columns below.
transaction_id– Displays the transaction ID of the current transaction. When selecting from the view inside a user-defined transaction, we should continue to see the sametransaction_idevery time we select from the view. When running aSELECTfromsys.dm_tran_current_transactionoutside of a transaction, theSELECTitself will generate a newtransaction_idvalue and a different value will be seen every time the sameSELECTis executed, even in the same connection.transaction_sequence_num– The XSN of the current transaction, if it has one. Otherwise, this column returns 0.transaction_is_snapshot– Value is 1 if the current transaction was started underSNAPSHOTisolation; otherwise, it is 0. That is, this column will be 1 if the current session has explicitly issuedSET TRANSACTION I SOLATION LEVEL SNAPSHOT.first_snapshot_sequence_num– When the current transaction started, it took a snapshot of all active transactions, and this value is the lowest XSN of the transactions in the snapshot.last_transaction_sequence_num– The most recent XSN generated by the system.first_useful_sequence_num– The upper bound (i.e. oldest) XSN of a transaction that is storing row versions. SQL Server need not retain in the version store any rows with an XSN less than this value.
In order to demonstrate how the values in the snapshot metadata are updated, we’ll create a simple versioning scenario, as shown in Listing 8a. It will not provide a complete overview, but it will allow you to start exploring the versioning metadata for your own queries. The example uses the AdventureWorks database, which has ALLOW_SNAPSHOT_ISOLATION set to ON.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
-- This is Connection 1 USE AdventureWorks; GO IF EXISTS ( SELECT 1 FROM sys.tables WHERE name = 't1' ) DROP TABLE t1; GO CREATE TABLE t1 ( col1 INT PRIMARY KEY , col2 INT ); GO INSERT INTO t1 VALUES ( 1, 10 ), ( 2, 20 ), ( 3, 30 ); GO SET TRANSACTION ISOLATION LEVEL SNAPSHOT; GO BEGIN TRAN SELECT * FROM t1; GO SELECT * FROM sys.dm_tran_current_transaction; SELECT * FROM sys.dm_tran_version_store; SELECT * FROM sys.dm_tran_transactions_snapshot; -- The transaction is NOT committed or rolled back |
Listing 8a: Examining metadata within a snapshot transaction.
The sys.dm_tran_current_transaction view should show something like this: the current transaction does have an XSN, and the transaction is a snapshot transaction. Also note that the first_useful_sequence_num value is the same as this transaction’s XSN because currently there are no other valid snapshot transactions. Let’s refer to this transaction’s XSN as XSN1.
The version store should be empty (unless you’ve done other snapshot tests within the last minute). Also, sys.dm_tran_transactions_snapshot should be empty, indicating that there were no snapshot transactions that started while other transactions were still in progress.
Listing 8b starts a new connection (Connection 2), runs an UPDATE, and examines some of the metadata for the current transaction.
|
1 2 3 4 5 6 7 8 9 |
-- This is Connection 2: BEGIN TRAN GO UPDATE t1 SET col2 = 100 WHERE col1 = 1 SELECT * FROM sys.dm_tran_current_transaction; GO |
Listing 8b: Start an UPDATE, running concurrently with the SNAPSHOT transaction from Listing 8a, and examine the metadata.
Note that, although this second transaction has an XSN because it will generate versions, it is not running in SI, so the transaction_is_snapshot value is 0. We’ll refer to this transaction’s XSN as XSN2.
Listing 8c starts our third transaction (our second SNAPSHOT transaction), in Connection 3, to perform another SELECT (don’t worry, this is the last one and we won’t be keeping it around.) It will be almost identical to the first SELECT, but there will be an important difference in the metadata results.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- This is Connection 3: SET TRANSACTION ISOLATION LEVEL SNAPSHOT; GO BEGIN TRAN SELECT * FROM t1; GO SELECT * FROM sys.dm_tran_current_transaction; SELECT * FROM sys.dm_tran_transactions_snapshot; GO |
Listing 8c: Examining metadata when a second SNAPSHOT transaction is running.
In the sys.dm_tran_current_transaction view, we’ll see a new XSN for this transaction (XSN3), and that the value for first_snapshot_sequence_num and first_useful_sequence_num are both the same as XSN1. The query against the sys.dm_tran_transactions_snapshot view reveals that this transaction with XSN3 has two rows, indicating the two transactions that were active when this one started. Both XSN1 and XSN2 show up in the snapshot_sequence_num column.
We can now either COMMIT or ROLLBACK this transaction in Connection 3, and then close the connection. Having done so, go back to Connection 2, where we started the UPDATE, and COMMIT it. Now, go back to the first SELECT transaction in Connection 1 and rerun the SELECT statement (SELECT * FROM t1;), staying in the same transaction.
Even though the UPDATE in Connection 2 has committed, we will still see the original data values because we are running a SNAPSHOT transaction. We can examine the sys.dm_tran_active_snapshot_database_transactions view with the query in Listing 9.
|
1 2 3 4 5 6 7 8 |
SELECT transaction_sequence_num , commit_sequence_num , is_snapshot , session_id , first_snapshot_sequence_num , max_version_chain_traversed , elapsed_time_seconds FROM sys.dm_tran_active_snapshot_database_transactions |
Listing 9: Examining sys.dm_tran_active_snapshot_database_transactions.
The output is omitted, as it is too wide for the page, but there are many interesting columns returned. In particular, the transaction_sequence_num column contains XSN1, which is the XSN for the current connection. We could actually run this query from any connection; it shows all active snapshot transactions in the SQL Server instance and, because it includes the session_id, we can join it to sys.dm_exec_sessions to get information about the connection that is running the transaction, as shown in Listing 10.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT transaction_sequence_num , commit_sequence_num , is_snapshot , t.session_id , first_snapshot_sequence_num , max_version_chain_traversed , elapsed_time_seconds , host_name , login_name , transaction_isolation_level FROM sys.dm_tran_active_snapshot_database_transactions t JOIN sys.dm_exec_sessions s ON t.session_id = s.session_id |
Listing 10: Query to return information about active snapshot transactions and the sessions running those transactions.
Another column of note is max_version_chain_traversed. Although now its value should be 1, we can change that. Go back to Connection 2, in Listing 8b, and run the UPDATE statement shown in Listing 11 and then examine the version store to see the rows being added. Note that we use BEGIN TRAN and COMMIT TRAN for the UPDATE, even though they are not necessary for a single statement transaction, to make it clear that this transaction is complete.
|
1 2 3 4 5 6 7 8 |
BEGIN TRAN UPDATE t1 SET col2 = 300 WHERE col1 = 1 COMMIT TRAN; SELECT * FROM sys.dm_tran_version_store; |
Listing 11: Querying the version store after a second UPDATE.
Return to Connection 1, run the same SELECT inside the original transaction and look again at the max_version_chain_traversed column in sys.dm_tran_active_snapshot_database_transactions. You should see that the number keeps growing. Repeated UPDATE operations, either in Connection 2 or in a new connection, will cause the max_version_chain_traversed value to keep increasing, as long as Connection 1 stays in the same transaction. Keep this in mind as an added cost of using snapshot isolation. As we perform more updates on data needed by snapshot transactions, our read operations will take longer because SQL Server will have to traverse a longer version chain to get the data needed by our transactions.
This is just the tip of the iceberg regarding how we can use the snapshot and transaction metadata to examine the behavior of our snapshot transactions.
Choosing a Concurrency Model
Pessimistic concurrency is the default in SQL Server 2005 and was the only choice in all earlier versions of SQL Server. Transactional behavior is guaranteed by locking, at the cost of greater blocking. When accessing the same data resources, readers can block writers and writers can block readers.
SQL Server was designed and built, initially, to use pessimistic concurrency. Therefore, we should consider using that model unless we can verify that row versioning concurrency really will work better for our applications. If we have an application where the cost of blocking is becoming excessive, and where many of the operations need to be performed in READ UNCOMMITTED isolation, row versioning concurrency is definitely worth considering.
Warning: The NOLOCK hint and RCSI
If application code invokes READ UNCOMMITTED isolation by using the NOLOCK hint (or the equivalent READUNCOMMITTED hint), changing the database to RCSI will have no effect. The NOLOCK hint will override the database setting, and SQL Server will continue to read the uncommitted (dirty) data. The only solution is to update the code to remove the hints.
In most situations, RCSI is recommended over SI for several reasons.
- RCSI consumes less
tempdbspace than SI. - RCSI works with distributed transactions; SI does not.
- RCSI does not produce update conflicts.
- RCSI does not require any change in your applications. All that is needed is one change to the database options. Any of your applications written using the default
READ COMMITTEDisolation level will automatically use RCSI after making the change at the database level.
Use of SI can be considered in the following situations:
- The probability is low that any transactions will have to be rolled back because of an update conflict.
- Reports, based on long-running, multi-statement queries, need to be generated with point-in-time consistency. Snapshot isolation provides the benefit of repeatable reads without being blocked by concurrent modification operations.
Row versioning concurrency does have benefits, but also be aware of the costs. To summarize the benefits:
SELECToperations do not acquire shared locks, so readers and writers will not block each other.- All
SELECToperations will retrieve a consistent snapshot of the data. - The total number of locks needed is greatly reduced compared to pessimistic concurrency, so less system overhead is used.
- SQL Server will need to perform fewer lock escalations.
- Deadlocks will be less likely to occur.
When weighing concurrency options, we must consider the cost of the snapshot-based isolation levels.
SELECTperformance can be negatively affected when long-version chains must be scanned. The older the snapshot, the more time it will take to access the required row in an SI transaction.- Row versioning requires additional resources in
tempdb. - Whenever either of the snapshot-based isolation levels is enabled for a database,
UPDATEandDELETEoperations must generate row versions. In general,INSERToperations do not generate row versions, but there are some cases where they might. In particular, if we insert a row into a table with a unique index, then if there is an older version of the row with the same key value as the new row, and that old row still exists as a ghost, our new row will generate a version. - Row versioning information increases the size of every affected row by 14 bytes.
UPDATEperformance might be slower due to the work involved in maintaining the row versions.- If SQL Server detects a conflict, it may roll back an
UPDATEoperation that is using SI. We must program our applications to deal with any conflicts that occur. - Carefully manage the space in
tempdb. If there are very long-running transactions, SQL Server must retain intempdball the versions generated byUPDATEtransactions during that time. Iftempdbruns out of space,UPDATEoperations won’t fail, butSELECToperations that need to read versioned data might fail.
To maintain a production system using either of the snapshot-based isolation levels, be sure to allocate enough disk space for tempdb so that there is always at least 10 percent free space. If the free space falls below this threshold, system performance may suffer because SQL Server will expend more resources trying to reclaim space in the version store. The formula below provides a rough estimate of the size required by the version store.
[size of common version store] =
2 * [version store data generated per minute]
* [longest running time (minutes) of the transaction]
For long-running transactions, it might be useful to monitor the generation and cleanup rate using Performance Monitor, to estimate the maximum size needed.
This article has been an extract from the book SQL Server Concurrency: Locking, Blocking and Row Versioning. You can pick up a free PDF of the book from Red Gate or buy a paperback or Kindle version from Amazon.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments