
Charles Bachman died on 2017-07-13 at age 92. I will bet that most of the readers of this article don’t remember him or, maybe, never heard of him. He was one of the early pioneers in databases, but he had the unfortunate habit of putting his money on the wrong horse. He was the principal architect of the navigational, or CODASYL, database model. I thought of him because I was looking in my library and came across my copy of ‘ANSI X3.133-1986 database language NDL’, the specification for a network model language. It’s dead, having expired in 1998, and even when we created it we were not expecting it to live very long. The main reason for writing and specifying it was to get common terms in a standard for reference.
The relational model became standard, perhaps due to a contest at the ACM event. Two teams were presented with a medium to high complex database business problem. The relational and the navigational solutions were compared, and the navigational solution was wrong! If anyone has a copy of the test question, I would love to get it forwarded to me; I would love to figure out a solution using SQL, with all the additions that have been made to the language after SQL-92.
There were many early navigational database products. None of them followed NDL completely. The most successful one was IMS from IBM, which is still sold today and has a huge installed base. It’s very hierarchical and depends on negotiating tree structures. IDMS is another popular product, but there were also products like TOTAL from Cincom.
I worked with a version of TOTAL on HP/3000 hardware marketed as IMAGE 3000, which is fairly representative of the products at the time. Each unit of work consisted of a hash table (which had to be a prime number of pre-allocated records because of the weak hashing algorithm), and simple linked lists of subordinate records. Now here’s where we start to get into terminology. At one point this relationship was referred to as ‘slave and master’ which was a little offensive, so in the NDL we used ‘owner and record’ which then became ‘parent and child’ in the literature.
In 1963 Bachman developed the Integrated Data Store (IDS) for General Electric. This was one of the first navigational database products. This product evolved into IDMS from Cullinane Information Systems (later Cullinet) on IBM mainframes. Charlie Bachman innovated a true network DBMS at Honeywell, but it didn’t turn into a serious product at that time. B. F. Goodrich, however, ran a version.
He was not ignored by the academic community. He received the Turing Award from the Association for Computing Machinery (ACM) in 1973 for his ‘outstanding contributions to database technology’.
He was elected as a Distinguished Fellow of the British Computer Society in 1977 for his pioneering work in database systems. He was awarded a National Medal of Technology and Innovation (2012) for ‘fundamental inventions in database management, transaction processing, and software engineering’. He was elected to ACM Fellow (2014) for contributions to database technology, notably the integrated data store. In 2015, he was made a Fellow of the Computer History Museum for his early work on developing database systems. Mr. Bachman published dozens of articles and papers in both the trade and the academic press. The most important paper was probably The Programmer as Navigator. (1973 ACM Turing Award lecture, Communications of the ACM vol. 16, no. 11, November 1973) in which he explained basic concepts of navigational databases.
Logical Data Model
Bachman also made another contribution to databases. His Bachman diagrams were an early attempt at systematically building logical data models. Before that, we wrote file layouts using code sheets provided by IBM and ANSI X3.5 program flowcharts. Flowcharts are one of the worst ways to define programs because you’re not sure what’s flowing; sometimes it’s data and sometimes it’s control. That is why that particular standard expired decades ago.
The Bachman diagrams are made up of boxes and arrows. In fact, there was a small-circulation newsletter for DBAs and systems analysts who worked with IDMS and other older mainframe database products entitled ‘Boxes and Arrows’ based on the appearance of Bachman diagrams.
The main structuring concepts in this model are ‘records’ and ‘sets’. Records essentially follow the COBOL definition ordered sequences of fields of different types: this allows complex internal structure such as repeating items and repeating groups. There are no virtual or computed fields. The set concept should not be confused with the mathematical set that used in an RDBMS. A CODASYL set represents a one-to-many relationship between records: one owner, many members. Unlike a strictly hierarchical data model, a record can be a member of many different sets. But unlike the set concept from RDBMS, these guys are ordered (so they are not really sets) and the records within a set are also in a sequence!
Records have a locator represented by a value known as a database key. Did you ever wonder where Sybase got the idea of the IDENTITY table property when they first implemented SQL? In IDMS, as in most other CODASYL implementations, the database key is directly related to the physical address of the record on disk, without regard to any of the values in the record. In short, it’s not relational. Database keys are then used as pointers to linked lists and trees. This means that the logical model and the physical implementation look a lot alike. Here’s the trade-off with this approach; Database retrieval can be pretty efficient because it’s really fast to traverse lists. But loading and restructuring these linked lists can be very expensive. Also, if a linked list was broken, you needed special utility programs to try and rebuild them. It was not always possible to do these rebuilds. Finally, if you needed to access the data in a particular order, which was not how the sets or records are physically ordered, then you have the overhead of sorting.
Flavors of Pointers
Many SQL programmers have never worked with pointers. When I explained the nested set model to programmers in some of my classes, the older programmers have a real hard time with it because they want to build tree structures with pointer chains. This is why you will see an organizational chart done with (emp_id, boss_emp_id) pairs to model the head and tail of a pointer chain link. This was so much a part of the mindset at the start of RDBMS, that the Oracle sample database (‘Scott/Tiger’ is the nickname it’s gotten over the decades because of the user and the password in it) is built on this adjacency list model.
However, younger programmers look at this approach in SQL and see it as a badly denormalized table. The same employee identifier appears in multiple places in the same table, in violation of First Normal Form (1NF). It requires very complex constraints to prevents cycles ensure that the hierarchy is a proper tree.
The nested set model doesn’t have the normal form violations and redundancy. New programmers who didn’t grow up with assembly language and low-level machine constructs look at it and say “Oh, this is XML tags written in a different language!” instead.
Simple Linked List
When people on SQL forums refer to a ‘link table’, they are using the term that refers to pointer chains. The simplest possible list structure is a single linked list, which would look something like this
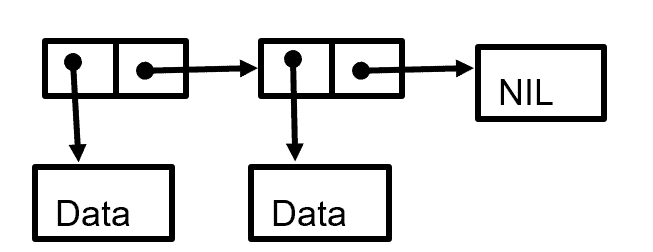
You enter the chain at a node and either pull out the data attached to it or get the address of the next link in the chain. Eventually will follow the path down to a ‘nil’ node (not to be confused with the NULL in SQL). You’ll notice that the structure allows you to move in only one direction.
This limitation on traversal is not as bad as you might first think. If you been working with SQL Server for a few decades, you will remember that the cursors in the very early versions of the product also could only read forward. The reason for this was very simple; the early tape drives from which model of cursors was developed could only read in one direction! This was not just on small machines, but pretty much on all the mainframe tape drives too. You just got in the habit of writing programs that would work with this limitation. Yes, we were very simple back in those days.
If you really needed to go back to a prior record in the sequence, you had to close a cursor then reopen it, remember the count of record you had read, and begin rereading from the front of the cursor all over again. Yuck.
Double Linked List.
The NDL Standard included next and prior commands. They could move up and down pointer chains in both directions. This obviously requires another part of the node to have the prior address as well as the next address. This reflects the way magnetic tapes work today. It’s also pretty much how everybody thinks of linked lists today. It costs you one extra pointer per node and gives you quite a bit of control over your data navigation. Most of the time, a pointer’s the same size as an integer; did you ever wonder why people traditionally use the integer datatypes for their identifiers when they’re learning SQL? It is a rule of all advances in technology that a new technology will first imitate the old technology and then eventually find its own voice. This is why your cell phone’s camera makes a clicking sound like a mechanical shutter. This imitation is called a ‘skeuomorph’, and it’s a great crossword puzzle word. Thus, early skyscrapers tried to look as much like Greek and Roman temples as they could, until the fact that skyscrapers are tall finally sank into people’s minds and we began to celebrate that fact.
Junctions
The junction refers to a collection of pointers that go to various data nodes. You will see people referring to ‘junction tables’ in SQL forums, not realizing this concept is not relational at all. What they usually want to do in the relational model would be a multi–table VIEW or query. When you did this with pointer chains, traversing it could be complicated. Each vendor had different implementations, but when we got to SQL, all we had was the REFERENCES clause.
REFERENCES
In SQL we have the concept of a reference, and referential integrity. It has nothing whatsoever to do with any kind of traversal. It’s derived from a data modeling concept of weak and strong entities. A weak entity is one that requires a strong entity in order to exist. For example, it doesn’t make any sense to have order items unless you have an order. Strong entity can exist on its own; you might have an order with no items on it yet.
In SQL we have referenced tables and referencing tables. Unlike pointer chains, they can be on the same table. Circular links in the pointer chain is usually a problem. Since pointers are based on traversals, you can wind up in an endless loop when you try to follow the chain.
If you had a good algorithm’s course, you might remember some of the tricks for detecting cycles in linked list structures (create two pointers, hold both on a node in the list, and advance one of them one node at a time; if the two pointers are ever equal again, you have a cycle. Otherwise, repeat the procedure on the next node in the list. If you go through all the nodes in your list, then there was no cycle). This is essentially how a recursive CTE (common table expression) works in SQL Server, but if it finds a cycle it continues running until it reaches an upper limit of repetitions.
Self-REFERENCE Constraints
The best example of a self-reference is Kuznetsov’s History Table SQL idiom which builds an unbroken temporal chain from the current row to the previous row. This is easier to show with code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE Tasks (task_id CHAR(5) NOT NULL, task_score CHAR(1) NOT NULL, previous_end_date DATE, -- null means first task current_start_date DATE DEFAULT CURRENT_TIMESTAMP NOT NULL, CONSTRAINT previous_end_date_and_current_start_in_sequence CHECK (prev_end_date <= current_start_date), current_end_date DATE, -- null means unfinished current task CONSTRAINT current_start_and_end_dates_in_sequence CHECK (current_start_date <= current_end_date), CONSTRAINT end_dates_in_sequence CHECK (previous_end_date <> current_end_date) PRIMARY KEY (task_id, current_start_date), UNIQUE (task_id, previous_end_date), -- null first task UNIQUE (task_id, current_end_date), -- one null current task FOREIGN KEY (task_id, previous_end_date) -- self-reference REFERENCES Tasks (task_id, current_end_date)); |
Well, that looks complicated! Let’s look at it column by column. Task_id explains itself. The previous_end_date will not have a value for the first task in the chain, so it is NULL-able. The current_start_date and current_end_date are the same data elements, temporal sequence and PRIMARY KEY constraints we had in the simple history table schema.
The two UNIQUE constraints will allow one NULL in their pairs of columns and prevent duplicates. Remember that UNIQUE is not like PRIMARY KEY, which implies UNIQUE NOT NULL.
In ANSI/ISO Standard SQL a constraint can be executed immediately at the start of a transaction or deferred until the end of the transaction. SQL Server assumes the constraints are immediate, so there’s no way to validate a constraint that isn’t already in place when you begin a transaction. The trick is to turn off the constraint, insert a starting row, turn the constraint back on and then self-reference it in the same table. You might want to play with this a little bit. It can be tricky. Fortunately, Alex Kuznetsov has written a Simple Talk article to explain in more detail how it is done.
The database can be in a state that would otherwise be illegal. But at the end of the session all constraints must be TRUE or UNKNOWN.
In SQL Server, you can disable constraints and then turn them back on. It actually is restricted to disabling FOREIGN KEY constraints and CHECK constraints. PRIMARY KEY, UNIQUE, and DEFAULT constraints are always enforced. The syntax for this is part of the ALTER TABLE statement. The syntax is simple:
|
1 |
ALTER TABLE <table name> NOCHECK CONSTRAINT [<constraint name> | ALL]; |
This is why you should name the constraints; without user given names, you have to look up what the system gave you and they are always long and messy. The ALL option will disable all of the constraints in the entire schema. Be careful with it.
To re-enable, the syntax is similar and explains itself:
|
1 |
ALTER TABLE <table name> CHECK CONSTRAINT [<constraint name> | ALL]; |
When a disabled constraint is re-enabled, the database does not check to ensure any of the existing data meets the constraints. So, for this table, the body of a procedure to get things started would look like this:
|
1 2 3 4 5 6 |
BEGIN ALTER TABLE Tasks NOCHECK CONSTRAINT ALL; INSERT INTO Tasks (task_id, task_score, current_start_date, current_end_date, previous_end_date) VALUES (1, 'A', '2010-11-01', '2010-11-03', NULL); ALTER TABLE Tasks CHECK CONSTRAINT ALL; END; |
REFERENTIAL Actions
A REFERENCES clause has more power than a simple link. You can attach actions to the referencing constraints in one table which will affect matching columns in the referenced table. Think about these in terms of the strong and weak entity model. The syntax is fairly straightforward:
|
1 2 3 4 |
[FOREIGN KEY (ref_column list)] REFERENCES referenced_table_name (ref_column list) ON DELETE {NO ACTION | CASCADE | SET NULL | SET DEFAULT} ON UPDATE {NO ACTION | CASCADE | SET NULL | SET DEFAULT} |
If you have a single column reference, there is no need to put a list of referencing columns in a FOREIGN KEY clause, so you don’t need the foreign key clause. Just add the constraint to the single column definition. The referenced columns must be UNIQUE, so they are usually the PRIMARY KEY of the referenced table. However, it’s perfectly all right to reference a UNIQUE() constraint in the referenced table.
It is also possible to add a constraint name to the REFERENCES clause. If you have the name, then you can use it to alter the table, by dropping it or by putting it in a NO CHECK state. This is local syntax, and not ANSI/ISO Standard. The standards have a deferred option which describes how constraint is handled at various times in the execution of a statement. It can get a little tricky and I’m not going to discuss it here.
When the database changes in some way, we have what’s called a database event. The two database events that referable referential actions are concerned with are updates and deletions. There are four options. We picked these options by looking at what people had been writing triggers.
NO ACTION This is the default and it pretty much explains itself. This is the default option, which says that you cannot modify the referencing columns unless first change the referenced columns. To make that a little more real, this is how you would enforce a rule that says you cannot take an order for an item that isn’t in inventory.
CASCADE A cascade option is probably the most common one in actual use. If I have a delete with the cascade when I remove something in the reference table, it is also deleted from all of the referencing tables. Again, a more of a real world of example, if I delete an account, I can also delete all the REFERENCES to it in my databases. If I update an account number, I can cascade this update to all the referencing tables.
SET NULL This pretty much explains itself. This assumes that the referenced columns are all null-able. Since a PRIMARY KEY cannot have null-able columns by definition, this can never be used on them. However, it’s okay for things with UNIQUE() constraints
SET DEFAULT This pretty much explains itself. This assumes that the referenced columns all have a default value.
Conclusion
In theory, anything you can do with procedural code, you can do with declarative code. The gimmick is you don’t do it the same way or with the same mindset.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments