
SSIS 2008 Crib sheet
For things you need to know rather than the things you want to know
Contents
Introduction
Like most SQL Server 2008 components, SQL Server Integration Services (SSIS) includes a number of new features and enhancements that improve performance and increase developer and administrator productivity. The improvements range from changes to the architecture-in order to better support package development and execution-to the addition of SSIS Designer tasks and components that extend SSIS capabilities and provide more effective data integration.
In this crib sheet, I provide an overview of several of these enhancements and give a brief explanation of how they work. Although this is not an exhaustive list of the changes in SSIS 2008, the information should provide you with a good understanding of the product’s more salient new features and help you better understand how these improvements might help your organization.
SSIS Architecture
The SQL Server 2008 team has made several important changes to the SSIS architecture, including redesigning the data flow engine, implementing a new scripting environment, and upgrading Business Intelligence Development Studio (BIDS).
Data Flow Engine
In SSIS 2005, the data flow is defined by a set of execution trees that describe the paths through which data flows (via data buffers) from the source to the destination. Each asynchronous component within the data flow creates a new data buffer, which means that a new execution tree is defined. A data buffer is created because an asynchronous component modifies or acts upon the data in such a way that it requires new rows to be created in the data flow. For example, the Union All transformation joins multiple data sets into a single data set. Because the process creates a new data set, it requires a new data buffer, which, in turn, means that a new execution tree is defined.
The following figure shows a simple data flow that contains a Union All transformation used to join together two datasets.
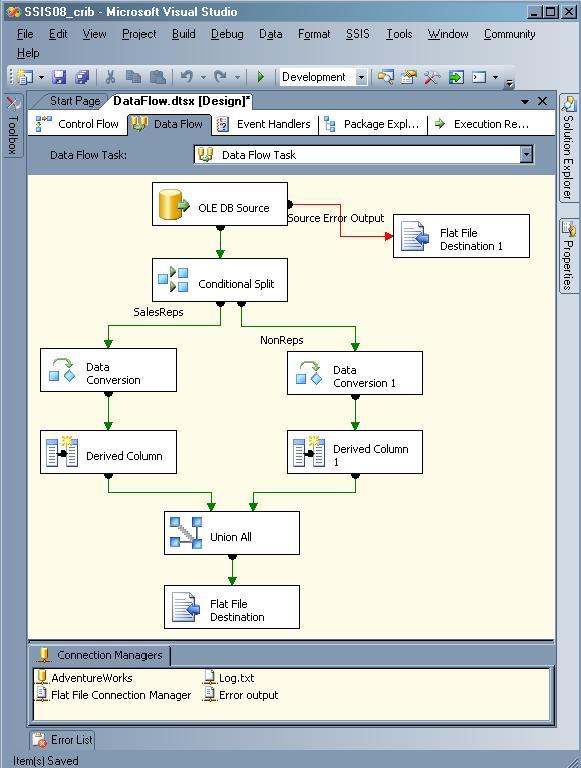
Because the Union All transformation is asynchronous-and subsequently generates a new dataset-the data sent to the Flat File destination is assigned to a new buffer. However, the Data Conversion and Derived Column transformations are synchronous, which means that data is passed through a single buffer. Even the Conditional Split transformation is synchronous and outputs data to a single buffer, although there are two outputs.
If you were to log the PipelineExecutionTrees event (available through SSIS logging) when you run this package, the results would include information similar to the following output:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
begin execution tree 1 output "OLE DB Source Output" (11) input "Conditional Split Input" (83) output "SalesReps" (143) input "Data Conversion Input" (187) output "Data Conversion Output" (188) input "Derived Column Input" (148) output "Derived Column Output" (149) input "Union All Input 1" (257) output "Derived Column Error Output" (150) output "Data Conversion Error Output" (189) output "NonReps" (169) input "Data Conversion Input" (219) output "Data Conversion Output" (220) input "Derived Column Input" (236) output "Derived Column Output" (237) input "Union All Input 2" (278) output "Derived Column Error Output" (238) output "Data Conversion Error Output" (221) output "Conditional Split Default Output" (84) output "Conditional Split Error Output" (86) end execution tree 1 begin execution tree 2 output "OLE DB Source Error Output" (12) input "Flat File Destination Input" (388) end execution tree 2 begin execution tree 0 output "Union All Output 1" (258) input "Flat File Destination Input" (329) end execution tree 0 |
As the logged data indicates, the data flow engine defines three execution trees, each of which are associated with a data buffer:
|
Execution tree 1 |
All components between the OLE DB source output and the Union All input, including the Conditional Split component. |
|
Execution tree 2 |
From the OLE DB source error output to the Flat File destination input. |
|
Execution tree 0 |
From the Union All output to the Flat File destination input. |
From this, you can see that most of the work is done in the first execution tree. The issue that this approach raises is that, in SSIS 2005, the data flow engine assigns only a single execution thread to each execution tree. (To complicate matters, under some conditions, such as when there are not enough threads, a single thread can be assigned to multiple execution trees.) As a result, even if you’re running your package on a powerful multiprocessor machine, a package such as the one above will use only one or two processors. This becomes a critical issue when an execution tree contains numerous synchronous components that must all run on a single thread.
And that’s where SSIS 2008 comes in. The data flow can now run multiple components in an execution tree in parallel. If you were to run the same package in SSIS 2008, the PipelineExecutionTrees event output would look quite different:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
Begin Path 0 output "Union All Output 1" (258); component "Union All" (256) input "Flat File Destination Input" (329); component "Flat File Destination" (328) End Path 0 Begin Path 1 output "OLE DB Source Output" (11); component "OLE DB Source" (1) input "Conditional Split Input" (83); component "Conditional Split" (82) Begin Subpath 0 output "SalesReps" (143); component "Conditional Split" (82) input "Data Conversion Input" (187); component "Data Conversion" (186) output "Data Conversion Output" (188); component "Data Conversion" (186) input "Derived Column Input" (148); component "Derived Column" (147) output "Derived Column Output" (149); component "Derived Column" (147) input "Union All Input 1" (257); component "Union All" (256) End Subpath 0 Begin Subpath 1 output "NonReps" (169); component "Conditional Split" (82) input "Data Conversion Input" (219); component "Data Conversion 1" (218) output "Data Conversion Output" (220); component "Data Conversion 1" (218) input "Derived Column Input" (236); component "Derived Column 1" (235) output "Derived Column Output" (237); component "Derived Column 1" (235) input "Union All Input 2" (278); component "Union All" (256) End Subpath 1 End Path 1 Begin Path 2 output "OLE DB Source Error Output" (12); component "OLE DB Source" (1) input "Flat File Destination Input" (388); component "Flat File Destination 1" (387) End Path 2 |
The first thing you’ll notice is that the execution trees are now referred to as “paths” and that a path can be divided into “subpaths.” Path 1, for example, includes two subpaths, which are each launched with the Conditional Split outputs. As a result, each subpath can run in parallel, allowing the data flow engine to take better advantage of multiple processors. For more complex execution trees, the subpaths themselves can be divided into additional subpaths that can all run in parallel. The best part is that SSIS schedules thread allocation automatically, so you don’t have to try to introduce parallelism manually into your packages (such as adding unnecessary Union All components to create new buffers). As a result, you should see improvements in performance for those packages you upgrade from SSIS 2005 to 2008 when you run them on high-end, multiprocessor servers.
Scripting Environment
SSIS includes the Script task and Script component, which allow you to write scripts that can be incorporated into the control flow and data flow. The basic function of the Script task and component are relatively the same in SSIS 2005 and SSIS 2008. However, the difference between the two versions is in the scripting environment itself. In SSIS 2005, the Script task and component use Microsoft Visual Studio for Applications (VSA). In SSIS 2008, the Script task and component use Microsoft Visual Studio 2005 Tools for Applications (VSTA).
The following example shows the ScriptMain class for the Script task in SSIS 2008. The first thing you might notice is that the script is written in C#.
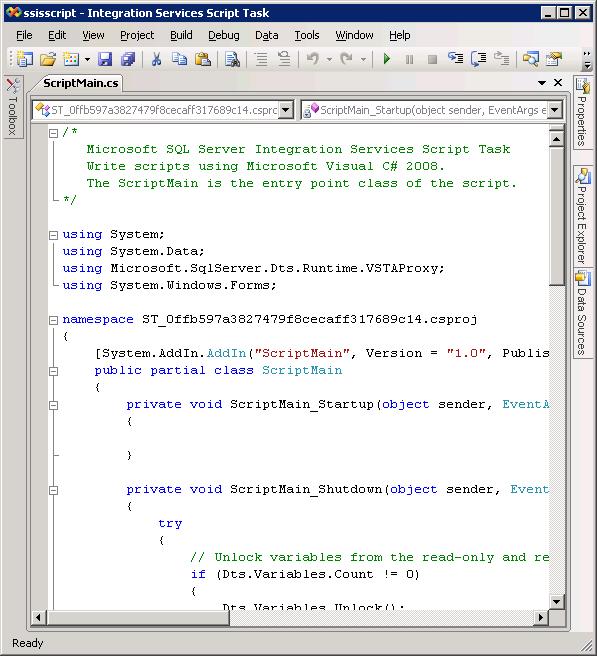
In SSIS 2005, you are limited to writing scripts in Visual Basic.NET. However, in SSIS 2008, because the VSTA environment is used, you can write scripts in C# or Visual Basic.NET.
Another advantage to VSTA is that you can now add Web references to your script. (This option is not available in SSIS 2005.) As a result, you can easily access the objects and the methods available to the Web services. VSTA also lets you add managed assemblies to your script at design time, and you can add assemblies from any folder on your computer. In general, VSTA makes it easier to reference any .NET assemblies.
If you’re upgrading an SSIS 2005 package to SSIS 2008 and the package contains a Script task or component, SSIS makes most of the necessary script-related changes automatically. However, if your script references IDTSxxx90 interfaces, you must change those references manually to IDTSxxx100. In addition, you must change user-defined type values to inherit from System.MarshalByRefObject if those values are not defined in the mscorlib.dll or Microsoft.SqlServer.VSTAScriptTaskPrx.dll assemblies.
Business Intelligence Development Studio
In SSIS 2005, BIDS is based on Visual Studio 2005, but in SSIS 2008, BIDS is based on Visual Studio 2008. For the most part, you won’t see much difference in your development environment. However, the biggest advantage to this change is that you can have BIDS 2005 and BIDS 2008 installed on the same machine, allowing you to edit SSIS 2005 and 2008 packages without having to switch between different environments.
SSIS Designer Tasks and Components
SSIS Designer is the graphical user interface (GUI) in BIDS that lets you add tasks, components, and connection managers to your SSIS package. As part of the changes made to SSIS to improve performance and increase productivity, SSIS Designer now includes the elements necessary to support data profiling, enhanced cached lookups, and ADO.NET connectivity.
Data Profiling
The Data Profiling task, new to SSIS 2008, lets you analyze data in a SQL Server database in order to determine whether any potential problems exist with the data. By using the Data Profiling task, you can generate one or more of the predefined reports (data profiles), and then view those reports with the Data Profile Viewer tool that is available when you install SSIS.
To generate data profile reports, you simply add a Data Profiling task to your control flow, and then select one or more profile types in the Data Profiling Task editor (on the Profile Requests page). For example, the following figure shows the Column Statistics profile type.
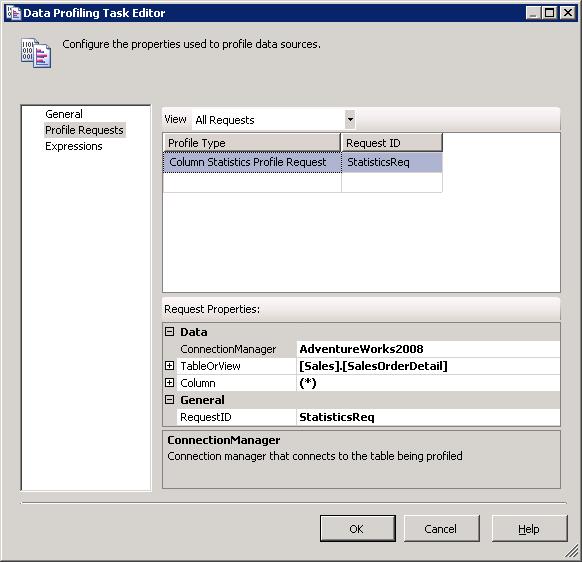
Although the figure shows only one configured profile type, you can add as many types as necessary, each specific to a data source. The Data profiling task supports eight profile types:
|
Candidate Key |
Provides details that let you determine whether one or more columns are suitable to use as a candidate key. |
|
Column Length Distribution
|
Provides the lengths of distinct values in a string column and the percentage of rows that share each length. |
|
Column Null Ratio |
Provides the number and percentage of null values in a column. |
|
Column Pattern |
Provides one or more regular expressions that represent the different formats of the values in a column. |
|
Column Statistics |
Provides details about the values in a column, such as the minimum and maximum values. |
|
Column Value Distribution
|
Provides the distinct values in a column, the number of instances of that value, and the percentage of rows that have that value. |
|
Functional Dependency |
Provides details about the extent to which values in one column depend on the values in another column. |
|
Value Inclusion |
Provides details that let you determine whether one or more columns are suitable as a foreign key. |
For each profile type that you select, you must specify an ADO.NET connection, a table or view, and the columns on which the profile should be based. You must also specify whether to save the profile data to a variable or to an .xml file. Either way, the data is saved in an XML format. If you save the results to a variable, you can then include other logic in your package, such as a Script task, to verify the data. For example, you can create a script that reads the results of a Column Statistics profile and then takes specific actions based on those results.
If you save the data to a file, you can use the Data Profile Viewer to view the data profile that you generated when you ran the Data Profiling task. To use the Data Profile Viewer, you must run the DataProfileViewer.exe utility. By default, the utility is saved to the Program Files\Microsoft SQL Server\100\DTS\Binn folder on the drive where you installed SSIS. After the utility opens, you can open the .xml file from within the utility window. The following figure shows the Column Statistics report generated for the OrderQty column in the Sales.SalesOrderDetail table.
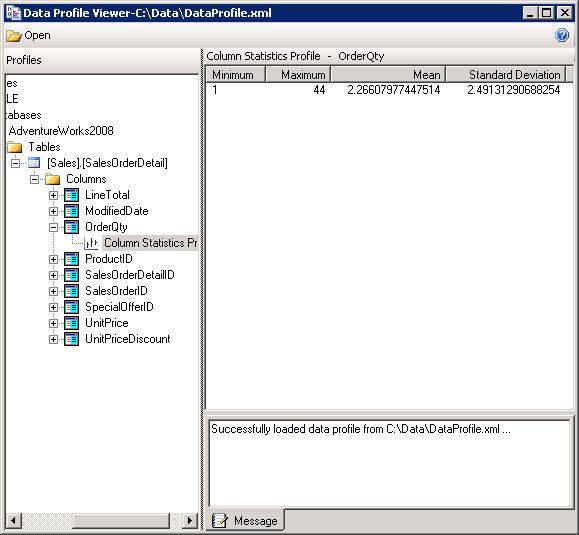
If you specified that multiple reports should be generated, all those reports will be available when you open the file in the Data Profile Viewer. You simply maneuver through the database hierarchy to view the specific data profiles.
Cached Lookups
In SSIS 2005, you perform lookup operations in the data flow by using the Lookup transformation to retrieve lookup data from an OLE DB data source. You can, optionally, configure the component to cache the lookup dataset, rather than retrieving the data on a per row basis. In SSIS 2008, your caching options for performing lookup operations have been extended through the Cache transformation and Cache connection manager. By using the new transformation and connection manager, you can cache lookup data from any type of data source (not only an OLE DB source), persist the data to the memory cache or into a cache file on your hard drive, and use the data in multiple data flows or packages.
The primary purpose of the Cache transformation is to persist data through a Cache connection manager. When configuring the transformation, you must, in addition to specifying the connection manager, define the column mappings. The following figure shows the Mappings page of the Cache Transformation Editor.
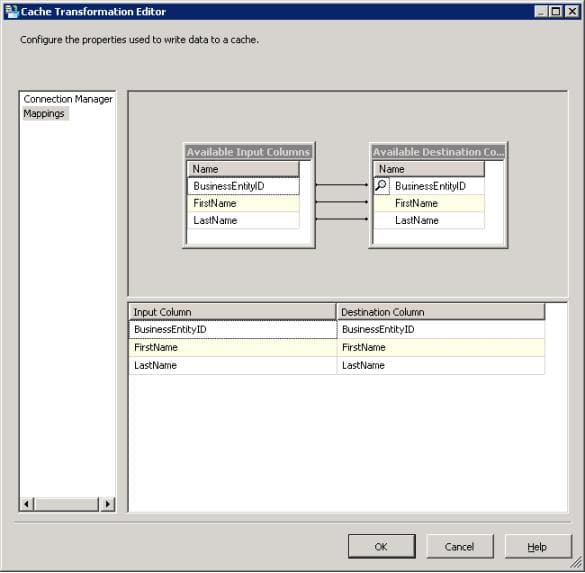
As you can see, you must map the appropriate input columns to the output columns so the correct lookup data is being cached. In this example, I am caching employee IDs, first names, and last names. I will later use a Lookup transformation to look up the employee names based on the ID.
To support cached lookups, you must, along with configuring the Cache transformation, configure the Cache connection manager. The following figure shows the General tab of the Connection Manager Editor.
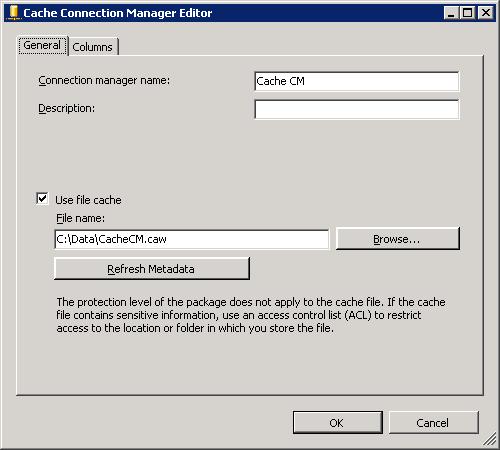
At a minimum, you must provide a name for the connection manager. By default, the lookup data will be stored in the memory cache in the format it is received through the data flow pipeline. However, you can instead store the data in a cache (.caw) file by providing a path and file name. You can also modify the data format (data type, length, etc.) on the Columns tab, within the restrictions that govern type conversion in SSIS.
When you use the Cache transformation and connection manager to cache your lookup data, you must perform the caching operation in a package or data flow separate from the data flow that contains the Lookup transformation. In addition, you must ensure that the caching operation runs prior to the package or data flow that contains the Lookup transformation. Also, when you configure the Lookup transformation, be sure to specify full cache mode and use the Cache connection manager you created to support the lookup operation.
ADO.NET
SSIS 2008 now includes the ADO.NET source and destination components. (The ADO.NET source replaces the DataReader source in SSIS 2005; however, SSIS 2008 continues to support the DataReader destination.) The ADO.NET source and destination components function very much like the OLE DB source and destination components. The editors are similar in the way you configure data access, column mappings, error output, and component properties. In addition, because you access data through an ADO.NET connection manager, you can access data through any supported .NET provider, including the ODBC data provider and the .NET providers for OLE DB.
Data Integration
SSIS 2008 has made it easier to work with different types of data by enhancing the SQL Server Import and Export wizard and by adding new SSIS data types to provide better support for data/time data.
SQL Server Import and Export Wizard
When you launch the SQL Server Import and Export wizard in BIDS, the wizard attempts to match the data types of the source data to the destination data by using SSIS types to bridge the data transfer. In SSIS 2005, you had little control over how these SSIS types were mapped to one another. However, in SSIS 2008, a new screen has been added to the wizard to allow you to analyze the mapping so you can address any type mismatch issues that might arise.
The following figure shows the Review Data Type Mapping screen of the SQL Server Import and Export wizard. In this scenario, I am attempting to import data from a text file into a SQL Server database.
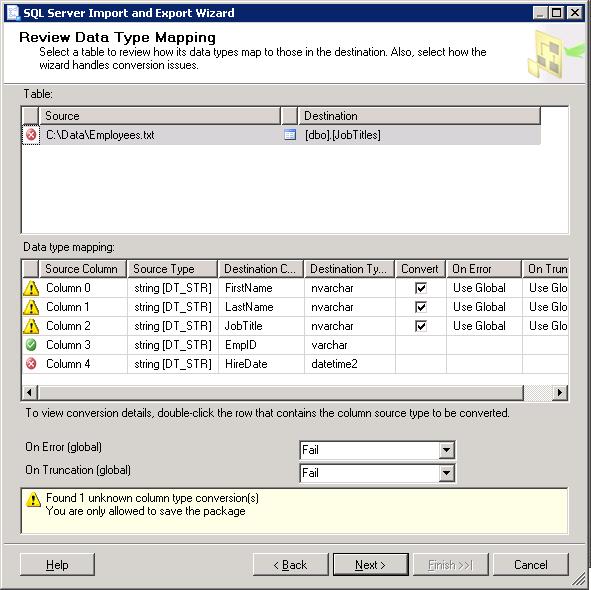
The data in the text file is comma-delimited. For this example, you can assume that each row includes the correct number of columns (with the correct data) necessary to match the target table. The target table is based on the following table definition:
|
1 2 3 4 5 6 7 |
CREATE TABLE [dbo].[JobTitles]( [FirstName] [nvarchar](30) NOT NULL, [LastName] [nvarchar](30) NOT NULL, [JobTitle] [nvarchar](30) NOT NULL, [EmpID] [varchar](10) NOT NULL, [HireDate] [datetime2](7) NULL ) ON [PRIMARY] |
If you refer again to the figure above, you’ll see that the screen shows how the columns are mapped from the source data to the destination data. Each column is marked with one of the following icons:
|
Green circle with
|
The data can be mapped without having to convert the data. |
|
Yellow triangle with exclamation point
|
The data will be converted based on predefined type mappings. A Data Conversion transformation will be added to the SSIS package that the wizard creates. |
|
Red circle with X |
The data cannot be converted. You can save the package but you cannot run it until you address the conversion issue. |
As you can see, the first three columns are marked with the yellow warning icons. You can view how the columns will be converted by double-clicking the row for that column information. When you do, a message box similar to the following figure is displayed.
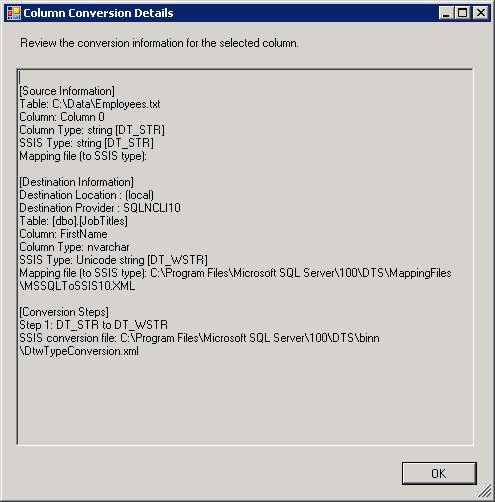
The message box provides details about how the source data will be mapped to an SSIS type, how the destination data will be mapped to an SSIS type, and how the two SSIS types will be mapped. The message box also provides the location and name of the XML files that are used to map the types. Notice that, in this case, the SSIS conversion is from the DT_STR type to the DT_WSTR type-a conversion from a regular string to a Unicode string.
You can also display a message box for the column that shows an error, as shown in the following figure.
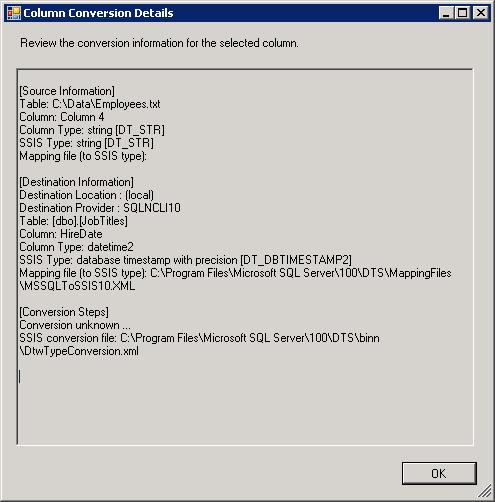
As you can see in the last section, the SSIS conversion is unknown. This means that a conversion cannot be mapped between the two SSIS data types that are used to bridge the source and destination data.
To map SSIS data types, SSIS uses the DtwTypeConversion.xml file, which by default is created in the Program Files\Microsoft SQL Server\100\DTS\binn folder on the drive where SSIS is installed. The following XML shows several mappings in the DtwTypeConversion.xml file that are defined by default for the DT_STR data type:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<!-- Convert from DT_STR--> <dtw:ConversionEntry> <dtw:SourceType>DT_STR</dtw:SourceType> <dtw:DestinationType TypeName="DT_I1"> <dtw:ConversionStep StepNum="1" ConvertToType="DT_I1"/> </dtw:DestinationType> <dtw:DestinationType TypeName="DT_I2"> <dtw:ConversionStep StepNum="1" ConvertToType="DT_I2"/> </dtw:DestinationType> <dtw:DestinationType TypeName="DT_I4"> <dtw:ConversionStep StepNum="1" ConvertToType="DT_I4"/> </dtw:DestinationType> |
If a mapping does not exist between two SSIS data types and the data is formatted in such a way that a conversion would be possible, you can add a mapping to the file. For instance, in the example shown in the figures above, the SQL Server Import and Export wizard is trying to map a string in the source data to a DATETIME2 data type in the destination data. (This is the column that is marked as with the error icon.) The first step that the wizard takes is to retrieve the string value as an SSIS DT_STR type. The value then needs to be converted to an SSIS type consistent with the target column type-DATETIME2. In SSIS, a data type consistent with DATETIME2 is DT_DBTIMESTAMP2. In other words, DT_STR should be converted to DT_DBTIMESTAMP2 in order to bridge the source data to the destination data. However, the DtwTypeConversion.xml file does not contain a DT_STR-to-DT_DBTIMESTAMP2 mapping. If you add this mapping to the file, the wizard will be able to automatically convert the data. Then, when you run the wizard, you’ll see a warning icon rather than an error icon.
Date/Time Data Types
In the previous section, I reference the DT_DBTIMESTAMP2 data type. This is one of the new date/time data types supported in SSIS 2008. These new types let you work with a wider range of date and time values than in SSIS 2005. In addition, the new types correspond to several of the new Transact-SQL date/time types supported in SQL Server 2008 as well as types in other relational database management systems (RDBMSs). The following types have been added to SSIS 2008:
|
DT_DBTIME2 |
A time value that provides the hour, minute, second, and fractional second up to seven digits, as in ’14:24:36.5643892′. The DT_DBTIME2 data type corresponds to the new TIME data type in Transact-SQL. |
|
DT_DBTIMESTAMP2
|
A date and time value that provides the year, month, day, hour, minute, second, and fractional second up to seven digits, as in ‘2008-07-21 14:24:36.5643892’. The DT_DBTIMESTAMP2 data type corresponds to the new DATETIME2 data type in Transact-SQL. |
|
DT_DBTIMESTAMPOFFSET |
A date and time value that provides the year, month, day, hour, minute, second, and fractional second up to seven digits, like the DT_DBTIMESTAMP2 data type. However, DT_DBTIMESTAMPOFFSET also includes a time zone offset based on Coordinated Universal Time (UTC), as in ‘2008-07-21 14:24:36.5643892 +12:00’. The DT_DBTIMESTAMPOFFSET data type corresponds to the new DATETIMEOFFSET data type in Transact-SQL. |
Moving Forward
In this article, I’ve tried to provide you with an overview of many of the important new features in SSIS 2008. However, as I mentioned earlier, this is not an exhaustive list. For example, SSIS 2008 also includes the SSIS Package Upgrade wizard, which lets you easily upgrade SSIS 2005 packages to 2008. In addition, the SSIS executables DTExec and DTUtil now support switches that let you generate memory dumps when a running package encounters an error. You can also take advantage of new features in SQL Server 2008 from within SSIS, such as using Change Data Capture (CDC) to do incremental loads. The more you work with SSIS 2008, the better you’ll understand the scope of the improvements that have been made. In the meantime, this article should have provided you with a good foundation in understanding how SSIS 2008 might benefit your organization in order to improve performance and productivity.



Load comments