
What is Partitioning and Why use it?
Table Partitioning is a way to segregate your data using a particular scheme or set of rules. The main reason for doing this is query performance; when you partition data and you have chosen a good partitioning scheme relevant to your data it means that as long as you stick to the partitioning scheme rules your query only “touches” the data in that partition. It was introduced in SQL 2005.
Imagine a 60 million row table, querying this depending on the complexity of the query; number of joins and criteria etc may take a considerable amount of time. In the world of partitioning , the number of rows queried is reduced according the granularity of the partitioning scheme.
There is of course some downsides to this. The first is that queries that cross the partition rules will take longer, arguably not longer than querying the non-partitioned table but this will be dependent on the number of partitions and again the granularity.
The second ,for small to medium size companies, most important problem is that true partitioning requires SQL Server Enterprise Edition. The current big daddy of the SQL family. This can be a very hard financial pill to swallow. Some may argue, including Microsoft, that if you are dealing with such a large volume of data that you must be a large, financially rich company and that this is not a barrier. The ability to partition/split data is a common request – especially as data grows and there are natural splits within your schema to take advantage of.
I am going to show a way to have table partitioning in SQL Server databases without the need for the Enterprise Edition of SQL Server that can easily to used in 2000, 2005 or 2008.
To achieve a version of partitioning without Enterprise Edition turns out to be relatively simple and offers nearly all of the benefits of true partitioning.
Lets say we have a ficticious company called NurseBank. NurseBank is operated in 3 Regions; England, Scotland and Wales. Every time a Nurse visits a Patient a Visit record is created and this is assigned to a Region who deals with the booking of Nurses for that Region.
In our original schema we would have had something like this for the Visit table:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE Visit ( VisitID INT IDENTITY(1,1) NOT NULL, RegionId INT NOT NULL, VisitDate DATETIME NOT NULL, NurseId INT NOT NULL, ClientId INT NOT NULL, CONSTRAINT PK_Visit_VisitID PRIMARY KEY (VisitId) ) |
Now, if you created that table; drop it. We are going to create 3 new tables to cater for the new partitions.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
CREATE TABLE dbo.Visit_England ( VisitId INT NOT NULL , RegionId INT NOT NULL CONSTRAINT CK_Visit_England CHECK (RegionId = 1), VisitDate DATETIME NOT NULL, NurseId INT NOT NULL, ClientId INT NOT NULL, CONSTRAINT PK_Visit_England PRIMARY KEY (VisitId,RegionId) ) CREATE TABLE dbo.Visit_Scotland ( VisitId INT NOT NULL , RegionId INT NOT NULL CONSTRAINT CK_Visit_Scotland CHECK (RegionId = 2), VisitDate DATETIME NOT NULL, NurseId INT NOT NULL, ClientId INT NOT NULL, CONSTRAINT PK_Visit_Scotland PRIMARY KEY (VisitId,RegionId) ) CREATE TABLE dbo.Visit_Wales ( VisitId INT NOT NULL , RegionId INT NOT NULL CONSTRAINT CK_Visit_Wales CHECK (RegionId = 3), VisitDate DATETIME NOT NULL, NurseId INT NOT NULL, ClientId INT NOT NULL, CONSTRAINT PK_Visit_Wales PRIMARY KEY (VisitId,RegionId) ) |
With these three tables created. We can create the Partitioned View that will allow us to select, update and insert data into the partitions.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE VIEW dbo.Visit WITH SCHEMABINDING AS SELECT VisitId, RegionId, VisitDate,NurseId, ClientId FROM dbo.Visit_Scotland UNION ALL SELECT VisitId, RegionId, VisitDate,NurseId, ClientId FROM dbo.Visit_England UNION ALL SELECT VisitId, RegionId, VisitDate,NurseId, ClientId FROM dbo.Visit_Wales |
You can now insert data into the Visit view as we would have done previously with the original table (with one exception that I will cover shortly).
|
1 2 3 4 5 6 7 8 |
-- INSERT INTO England Region Visit table INSERT INTO Visit (VisitId, RegionId, VisitDate, NurseId, ClientId) VALUES (1000,1,GETDATE(),4122,5211) -- INSERT INTO Scotland Region Visit table INSERT INTO Visit (VisitId, RegionId, VisitDate, NurseId, ClientId) VALUES (1001,2,GETDATE(),4123,5212) |
The interesting and important aspect is what SQL Server does when insert happens and what query plan is used to select the data.
|
1 |
SELECT VisitID FROM Visit WHERE RegionId = 1 |
This will produce the following query plan:

As you can see it correctly uses the Visit_England partitioned table. If the Region is omitted from the WHERE clause, the query plan is vastly different and of course cannot determine the correct table to use so basically it UNION joins them all as shown below.
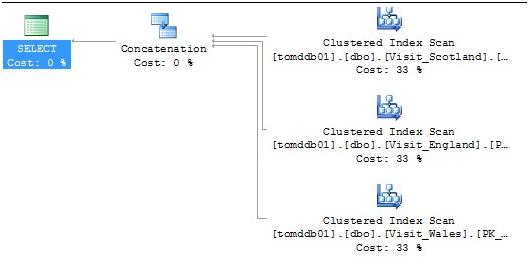
I don’t think I need to say but this is bad. However, the whole point of partitioning the data is when you have a need to do so (large volumes of data) and you have a viable partitioning scheme that will avoid the above type of plan as much as possible.
Lastly, I wanted to mention the exception I hinted at before.
For a partitioned view to work fully (as in allow inserts) , your partitioned table cant have an identity column.
What! I hear you say, whats the point of that? How I can use this?. Well, in most situations the partitioning of the data is done to improve the read performance of queries. If this is the case then the perfect scenario for this type of partitioning is to partition the data on a replicated separate database. The way this works is that you have your inserts performed on your main database or cluster and when the data is replicated to the other database (lets call this the readonly but it isn’t a physical readonly – its just we wont be doing writes on it) the replication procedure is modified to insert into the Partitioned View and the original table thats replicated.
In this way you don’t need an identity column on the partitioned tables as this would be known and passed into the table via replication.
I hope you find this example useful, this is by no means the only way to improve performance and you really must consider all available options but I thought this was a useful and relatively painless method to try and one we currently use in our business.
If you are interested in using true Table Partitioning, I’d recommend the article Partitioning in SQL Server 2008 on SQL Server Central by Muhammad Shujaat Siddiqi.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments