
The Performance of Traversing a SQL Hierarchy
It is well known, and blogged to death, that the way to traverse a hierarchy that is stored in a T-SQL table as an adjacency list, is to use a recursive Common Table Expression (rCTE). But what if there was a faster way of traversing an adjacency list? Would you use it?
The adjacency list approach to saving a hierarchy is quite common and can represent:
- Reporting levels between managers and their successive employees.
- A parts hierarchy, particularly the case of parts in a kit with the kit/assembly having multiple levels. Another example is parts succession, where older parts are replaced by newer ones.
- A Bill of Materials (BOM).
Today we’ll look at various ways a hierarchy represented as an adjacency list can be traversed and compare the elapsed times for each method.
Data Setup – A Simple Hierarchy as an Adjacency List
Let’s create an adjacency list (ManagersDirectory) and insert a simple hierarchy into it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
CREATE TABLE dbo.ManagersDirectory ( ManagerID INT ,EmployeeID INT ,CONSTRAINT md_pk1 PRIMARY KEY (ManagerID, EmployeeID) ); GO INSERT INTO dbo.ManagersDirectory -- Level 1 elements SELECT 1, 10 UNION ALL SELECT 1, 20 UNION ALL SELECT 1, 30 -- Level 2 elements UNION ALL SELECT 10, 100 UNION ALL SELECT 10, 101 UNION ALL SELECT 10, 102 UNION ALL SELECT 20, 200 UNION ALL SELECT 20, 201 UNION ALL SELECT 20, 202 UNION ALL SELECT 30, 300 UNION ALL SELECT 30, 301 UNION ALL SELECT 30, 302 -- Level 3 elements UNION ALL SELECT 100, 1000 UNION ALL SELECT 100, 1001 UNION ALL SELECT 100, 1002 UNION ALL SELECT 200, 2000 UNION ALL SELECT 200, 2001 UNION ALL SELECT 200, 2002 UNION ALL SELECT 300, 3000 UNION ALL SELECT 300, 3001 UNION ALL SELECT 300, 3002 UNION ALL SELECT 101, 1003 UNION ALL SELECT 101, 1004 UNION ALL SELECT 101, 1005 UNION ALL SELECT 201, 2003 UNION ALL SELECT 201, 2004 UNION ALL SELECT 201, 2005 UNION ALL SELECT 301, 3003 UNION ALL SELECT 301, 3004 UNION ALL SELECT 301, 3005 UNION ALL SELECT 102, 1006 UNION ALL SELECT 102, 1007 UNION ALL SELECT 102, 1008 UNION ALL SELECT 202, 2006 UNION ALL SELECT 202, 2007 UNION ALL SELECT 202, 2008 UNION ALL SELECT 302, 3006 UNION ALL SELECT 302, 3007 UNION ALL SELECT 302, 3008; SELECT ManagerID, EmployeeID FROM dbo.ManagersDirectory; |
The final SELECT returns all 39 elements we’ve created in our adjacency list. We put a primary key on the most common place you’d expect to find one: ManagerID and EmployeeID.
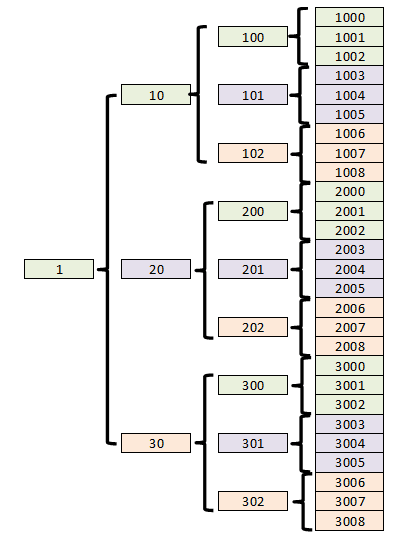
Pictorially, this hierarchy looks like this (three children reporting to each parent):
Traverse the Hierarchy Using a Traditional rCTE
When we generate the traversal, we add a level counter and a string that represents the manager-to-employee reporting relationship for this hierarchy. It uses the same rCTE that you’ve seen many times before. You’ll have to excuse me for complaining about everyone rehashing this over and over, while I’m doing the same, but hopefully in the end I’ll add a little value.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
DECLARE @TopLevel INT = 1 -- Top level manager (node) ,@NumLevels INT = 3; -- Depth of the hiearchy to traverse WITH HierarchyTraaversal AS ( -- rCTE anchor: retrieve the top level node SELECT [Level]=1, ManagerID, EmployeeID ,MgrEmp=CAST(ManagerID AS VARCHAR(8000)) + '/' + CAST(EmployeeID AS VARCHAR(8000)) FROM dbo.ManagersDirectory WHERE ManagerID = @TopLevel UNION ALL -- rCTE recursion: retrieve the following nodes SELECT [Level]+1, a.ManagerID, a.EmployeeID ,MgrEmp=MgrEmp + '/' + CAST(a.EmployeeID AS VARCHAR(8000)) FROM dbo.ManagersDirectory a JOIN HierarchyTraaversal b ON b.EmployeeID = a.ManagerID WHERE [Level] < @NumLevels --+ 1 ) SELECT [Level], ManagerID, EmployeeID, MgrEmp FROM HierarchyTraaversal ORDER BY [Level], ManagerID, EmployeeID; |
This produces the fairly familiar results (39 rows), abbreviated below:
|
1 2 3 4 5 6 7 8 9 10 11 |
Level ManagerID EmployeeID MgrEmp 1 1 10 1/10 1 1 20 1/20 1 1 30 1/30 2 10 100 1/10/100 2 10 101 1/10/101 <snip> 3 301 3005 1/30/301/3005 3 302 3006 1/30/302/3006 3 302 3007 1/30/302/3007 3 302 3008 1/30/302/3008 |
A Non-traditional Hierarchy Traversal in T-SQL
It has been said that T-SQL only supports recursion through a recursive CTE. Or does it? Let’s see if we can persuade SQL Server to let us create a recursive FUNCTION:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
CREATE FUNCTION dbo.HierarchyTraversal ( @Levels INT ,@TopLevel INT ) RETURNS @H TABLE ( [Level] INT ,ManagerID INT ,EmployeeID INT ,MgrEmp VARCHAR(8000) ) AS BEGIN IF @Levels > 0 INSERT INTO @H -- The top level manager SELECT 1, ManagerID, EmployeeID ,CAST(ManagerID AS VARCHAR(8000)) + '/' + CAST(EmployeeID AS VARCHAR(8000)) FROM dbo.ManagersDirectory WHERE ManagerID = @TopLevel UNION ALL -- The remainder of the hierarchy SELECT [Level]+1, a.ManagerID, a.EmployeeID ,MgrEmp + '/' + CAST(a.EmployeeID AS VARCHAR(8000)) FROM dbo.ManagersDirectory a JOIN dbo.HierarchyTraversal(@Levels-1, @TopLevel) b ON b.EmployeeID = a.ManagerID; RETURN END |
Note where we reference dbo.HierarchyTraversal (the FUNCTION we are creating) in the JOIN. Thanks to the miracle of deferred name resolution we gleefully receive the message back from SQL Server Management Studio (SSMS) that our “Command(s) completed successfully.”
When we run this FUNCTION to traverse our adjacency list:
|
1 2 3 |
SELECT [Level], ManagerID, EmployeeID, MgrEmp FROM dbo.HierarchyTraversal(@NumLevels, @TopLevel) ORDER BY [Level], ManagerID, EmployeeID; |
We behold with wonder that the returned results are identical to those returned by the rCTE!
Note that the FUNCTION cannot be given the property WITH SCHEMABINDING, nor can it be an in-line Table Valued FUNCTION (TVF). It only works with a multi-line TVF. Another limitation is that if you ever exceed 32 levels, this function is going to throw an error.
The Method of Repeating JOINs
Another way to do this is with a series of repeating JOINs, using UNION ALL operators to combine each successive level. For our tiny hierarchy, this can be achieved as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
-- Manager level node and its children SELECT [Level]=1, ManagerID, EmployeeID ,MgrEmp=CAST(ManagerID AS VARCHAR(8000)) + '/' + CAST(EmployeeID AS VARCHAR(8000)) FROM dbo.ManagersDirectory a1 WHERE a1.ManagerID = @TopLevel UNION ALL -- Children of the manager level node plus those children SELECT [Level]=2, a2.ManagerID, a2.EmployeeID ,MgrEmp=CAST(a1.ManagerID AS VARCHAR(8000)) + '/' + CAST(a2.ManagerID AS VARCHAR(8000)) + '/' + CAST(a2.EmployeeID AS VARCHAR(8000)) FROM dbo.ManagersDirectory a1 JOIN dbo.ManagersDirectory a2 ON a1.EmployeeID = a2.ManagerID WHERE a1.ManagerID = @TopLevel UNION ALL -- Final levels SELECT [Level]=3, a3.ManagerID, a3.EmployeeID ,MgrEmp=CAST(a1.ManagerID AS VARCHAR(8000)) + '/' + CAST(a2.ManagerID AS VARCHAR(8000)) + '/' + CAST(a3.ManagerID AS VARCHAR(8000)) + '/' + CAST(a3.EmployeeID AS VARCHAR(8000)) FROM dbo.ManagersDirectory a1 JOIN dbo.ManagersDirectory a2 ON a1.EmployeeID = a2.ManagerID JOIN dbo.ManagersDirectory a3 ON a2.EmployeeID = a3.ManagerID WHERE a1.ManagerID = @TopLevel; |
This too returns the same results as our prior attempts. Of course, it only works if you reconstruct the query based on the number of levels you want to traverse, unless you construct the query with dynamic SQL.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
DECLARE @SQL NVARCHAR(MAX) = N'' ,@SQLParms NVARCHAR(MAX) = N'@TopLevel INT' ,@J INT = 1 ,@J1 VARCHAR(2) ,@RC INT; WHILE @J <= @NumLevels + 1 BEGIN -- This character string version of @J is used frequently in later string concatenations SELECT @J1 = CAST(@J AS VARCHAR); -- The Tally table must return enough numbers to handle the number of desired levels. -- @NumLevels was set earlier to 3. WITH Tally (n) AS ( SELECT 1+ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) a(n) ) SELECT @SQL = @SQL + 'SELECT [Level]=' + @J1 + ', a' + @J1 + '.ManagerID, a' + @J1 + '.EmployeeID' + CHAR(10) + ' ,MgrEmp=CAST(a1.ManagerID AS VARCHAR(8000)) + ''/'' + ' + CHAR(10) + ISNULL(( SELECT ' CAST(a' + CAST(n AS VARCHAR) + '.ManagerID AS VARCHAR(8000)) + ''/'' +' + CHAR(10) FROM Tally WHERE n BETWEEN 2 AND @J FOR XML PATH(''), TYPE ).value('.', 'NVARCHAR(4000)'), '') + ' CAST(a' + @J1 + '.EmployeeID AS VARCHAR(8000))' + CHAR(10) + -- Used in our performance test harness to suppress display of the final results -- CASE @J WHEN 1 THEN 'INTO #Temp3' + CHAR(10) ELSE '' END + 'FROM dbo.ManagersDirectory a1' + CHAR(10) + ISNULL(( SELECT 'JOIN dbo.ManagersDirectory a' + CAST(n AS VARCHAR) + ' ON a' + CAST(N-1 AS VARCHAR) + '.EmployeeID = a' + CAST(N AS VARCHAR) + '.ManagerID' + CHAR(10) FROM Tally WHERE n BETWEEN 2 AND @J FOR XML PATH, TYPE ).value('.', 'NVARCHAR(4000)'), '') + 'WHERE a1.ManagerID = @TopLevel ' + CASE WHEN @J < @NumLevels + 1 THEN CHAR(10) + 'UNION ALL' + CHAR(10) ELSE '' END; SELECT @J = @J + 1; END PRINT @SQL; -- EXEC sp_executesql @SQL, @SQLParms, @TopLevel = @TopLevel; |
A look at the printed SQL query should show that it is identical to the first but will grow in size and complexity depending on the number of levels (@NumLevels) you’ve set. Note the line we commented out in the middle, which we’ll use in our test harness later to dump the results to a temporary table when we do our timings.
The Set-based Loop
Since any recursive CTE can always be rewritten as a set-based loop, even though I don’t particularly like loops, we’ll give it a go nonetheless.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
-- The first select is equivalent to the anchor leg of the rCTE. -- It creates the temporary table we'll store results for each iteration of the loop. SELECT [Level]=ISNULL(1, 0) ,ManagerID=ISNULL(ManagerID, 0) ,EmployeeID=ISNULL(EmployeeID, 0) ,MgrEmp=CAST(ManagerID AS VARCHAR(8000)) + '/' + CAST(EmployeeID AS VARCHAR(8000)) INTO #Temp1 FROM dbo.ManagersDirectory a1 WHERE a1.ManagerID = @TopLevel -- Add a PRIMARY KEY to hopefully make the later JOIN a bit more efficient ALTER TABLE #Temp1 ADD CONSTRAINT t_pk PRIMARY KEY ([Level], ManagerID, EmployeeID); DECLARE @I INT = 2; WHILE @I < @NumLevels + 1 BEGIN -- Insert each successive level into the temporary table. INSERT INTO #Temp1 SELECT @I, b.ManagerID, b.EmployeeID ,MgrEmp=MgrEmp + '/' + CAST(b.EmployeeID AS VARCHAR(8000)) FROM #Temp1 a JOIN dbo.ManagersDirectory b ON a.EmployeeID = b.ManagerID WHERE [Level] = @I - 1 -- This is explained below. OPTION (RECOMPILE); SELECT @I = @I + 1; END SELECT [Level], ManagerID, EmployeeID, MgrEmp FROM #Temp1 ORDER BY [Level], ManagerID, EmployeeID; |
Once again, a check against our expected results shows they match. Note that, since we’re using #Temp1 to JOIN back to the ManagersDirectory table, having an index (the primary key) on the temporary table should improve the performance over the case where we have only a heap.
All of the queries we’ve shown so far, including the CREATE for our function, and the next one are in the attached resource file: 01 Example Queries.sql.
You may have noticed the OPTION (RECOMPILE) on the query within the loop. We were concerned about parameter sniffing impacting the performance of the query. So, of course, we tested that using 02 Loop With and Without RECOMPILE.sql and concluded that the query generally runs faster with the OPTION than without it. You can try it yourself at various levels to confirm our conclusion.
The WHILE Loop Revisited
Since we’ve taken our WHILE loop on a test drive, let’s drive it all the way to Memphis and see if we can meet Elvis. As perversely absurd as that sounds, the question that follows may seem even more so. Is it possible that our WHILE loop hierarchy traversal may be impacted by the Halloween Problem? I first learned about this and the SQL Optimizer’s Halloween protection in SQL MVP Itzik Ben-Gan’s article: Identifying a Subsequence in a Sequence, Part 1, where he implemented a method of avoiding SQL’s Halloween protection in his third solution. I found the problem interesting, so I was testing that solution and was frankly amazed at the lightning speed that it processed his ten million rows of test data, literally trouncing the first set-based solutions that I could come up with. The similarity of what he was doing (INSERTs into an indexed temporary table within the loop) got me to thinking that it may be applicable here. So I read the outstanding articles he recommended by SQL MVP Paul White, who clearly showed that Halloween protection can impact INSERTs (and DELETEs and MERGEs) in addition to UPDATEs. More reading led me to another article by Itzik Ben-Gan: Divide and Conquer Halloween, where he addressed the hierarchy traversal problem directly.
His solution modified to our requirements is shown below with two changes: 1) I added the OPTION(RECOMPILE) because I did a little pre-performance testing and it seemed to be marginally better and 2) his solution always traverses the entire hierarchy while I’d like mine to only go as deep as I tell it to (using @NumLevels).
First we must create two indexed temporary tables.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE #Temp3 ( [Level] INT ,ManagerID INT ,EmployeeID INT ,MgrEmp VARCHAR(8000) ,CONSTRAINT t3_pk PRIMARY KEY([Level], ManagerID, EmployeeID) ); CREATE TABLE #Temp4 ( [Level] INT ,ManagerID INT ,EmployeeID INT ,MgrEmp VARCHAR(8000) ,CONSTRAINT t4_pk PRIMARY KEY([Level], ManagerID, EmployeeID) ); |
We then populate the two temporary tables, avoiding the SQL Optimizer’s need to provide Halloween protection by alternating our INSERTs between the two temporary tables.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
-- Insert the parent level INSERT INTO #Temp3 SELECT [Level]=ISNULL(1,0), ManagerID=ISNULL(ManagerID,0), EmployeeID=ISNULL(EmployeeID,0) ,MgrEmp=CAST(ManagerID AS VARCHAR(8000)) + '/' + CAST(EmployeeID AS VARCHAR(8000)) FROM dbo.ManagersDirectory2 a1 WHERE a1.ManagerID = @TopLevel; WHILE @I < @NumLevels + 1 BEGIN -- Insert each successive level into the temporary table. IF @I % 2 = 0 -- Even iterations go into #Temp4 INSERT INTO #Temp4 SELECT @I, b.ManagerID, b.EmployeeID ,MgrEmp=MgrEmp + '/' + CAST(b.EmployeeID AS VARCHAR(8000)) FROM #Temp3 a JOIN dbo.ManagersDirectory2 b ON a.EmployeeID = b.ManagerID WHERE [Level] = @I - 1 OPTION (RECOMPILE); ELSE -- Odd iterations go into #Temp3 INSERT INTO #Temp3 SELECT @I, b.ManagerID, b.EmployeeID ,MgrEmp=MgrEmp + '/' + CAST(b.EmployeeID AS VARCHAR(8000)) FROM #Temp4 a JOIN dbo.ManagersDirectory2 b ON a.EmployeeID = b.ManagerID WHERE [Level] = @I - 1 OPTION (RECOMPILE); SELECT @I = @I + 1; END |
Now we just need to combine the results stored into our two temporary tables to obtain our hierarchy traversal.
|
1 2 3 4 5 6 7 |
-- Combine the results to get the hierarchy traversal SELECT [Level], ManagerID, EmployeeID, MgrEmp FROM #Temp3 UNION ALL SELECT [Level], ManagerID, EmployeeID, MgrEmp FROM #Temp4 ORDER BY [Level], ManagerID, EmployeeID; |
Since Itzik Ben-Gan and Paul White are both so much more eloquent and technically skilled than me, we’ll leave the explanation of detecting, and why avoiding, Halloween protection is a good thing.
A Bigger Test Harness
After learning rather quickly that generating a large test harness for an adjacency list can be quite annoying, we finally managed to do so as follows. This extends the hierarchy adding three nodes to each prior node for each iteration of the WHILE loop.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
-- Remove our small hierarchy table and add a column we'll use to generate more levels TRUNCATE TABLE dbo.ManagersDirectory; ALTER TABLE dbo.ManagersDirectory ADD [Level] INT; GO -- The first entry is the top level parent plus three children INSERT INTO dbo.ManagersDirectory SELECT 1, 2, 1 UNION ALL SELECT 1, 3, 1 UNION ALL SELECT 1, 4, 1; DECLARE @Level INT = 1; WHILE @Level <= 13 BEGIN INSERT INTO dbo.ManagersDirectory (ManagerID, EmployeeID, [Level]) SELECT EmployeeID, ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) + -- Next employee numbers will just be integers from ROW_NUMBER() above added to this. (SELECT MAX(EmployeeID) FROM dbo.ManagersDirectory) ,@Level + 1 FROM dbo.ManagersDirectory a -- This small tally table generates 3 nodes for each previous level's entry CROSS JOIN (SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3) b(n) WHERE [Level] = @Level; SELECT @Level = @Level + 1; END -- Remove the column we added to facilitate creation of the test harness. ALTER TABLE dbo.ManagersDirectory DROP COLUMN [Level]; SELECT COUNT(*) FROM dbo.ManagersDirectory; |
Be patient when you run the above script because it does take a little longer to run that the prior ones (about 3.5 minutes). To construct our hierarchy, we needed to add a Level column which we later drop off to restore the adjacency list to its original structure. The final SELECT tells us that our table now contains 7,174,452 rows.
To test the performance of this new method, we’ll run through traversals of the hierarchy from 5 to 13 levels using a batch that we’ll execute 9 times. The #Results table will capture the results for each execution of the batch. The #Sequence table is used to simulate a SQL 2012 SEQUENCE object, since we’re running our test in SQL Server 2008 R2.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE #Results ( Levels INT ,Reccount INT ,Method VARCHAR(10) ,ElapsedMS INT ); GO CREATE TABLE #Sequence ( [Counter] INT ); INSERT INTO #Sequence SELECT 4; GO |
The batch will start at level five, because below that all of the methods are pretty swift. The rest of the test harness is rather lengthy so we won’t include it here, however you can find it in the attached resources as: 03 Performance Test Harness.sql
After the final run of the timing batch (takes about 16 minutes), the results from our #Results table (reformatted) are shown below for elapsed time in milliseconds. Red font indicates the worst performing solution at the level while green font (often tied) represents the fastest solution.
|
Elapsed (ms) |
rCTE |
rFCN |
dSQL |
sbLP |
sbLPwR |
LAHP |
LAHPwR |
|
5 Levels |
16 |
63 |
63 |
30 |
76 |
46 |
16 |
|
6 Levels |
46 |
33 |
30 |
123 |
80 |
60 |
46 |
|
7 Levels |
160 |
93 |
123 |
123 |
96 |
110 |
93 |
|
8 Levels |
503 |
313 |
170 |
296 |
230 |
296 |
200 |
|
9 Levels |
1280 |
983 |
593 |
576 |
563 |
596 |
563 |
|
10 Levels |
3780 |
3113 |
1763 |
1853 |
1763 |
1843 |
1400 |
|
11 Levels |
11443 |
9630 |
5520 |
7913 |
6660 |
4573 |
4616 |
|
12 Levels |
35300 |
29790 |
17510 |
17020 |
17336 |
21740 |
15646 |
|
13 Levels |
108113 |
104420 |
57950 |
52563 |
81153 |
50156 |
52643 |
Each of our methods are abbreviated as:
- rCTE – The traditional recursive CTE approach
- rFCN – The non-traditional recursive FUNCTION approach
- dSQL – The dynamic SQL constructed from repeated JOINs and UNION ALL
- sbLP – The set-based WHILE loop
- sbLPwR – The set-based WHILE loop with RECOMPILE option
- LAHP – The set-based WHILE loop avoiding Halloween protection
- LAHPwR – The set-based WHILE loop avoiding Halloween protection with RECOMPILE option
Note that you can probably drop the OPTION(RECOMPILE) whenever your intention is to traverse the entire hierarchy to its full depth.
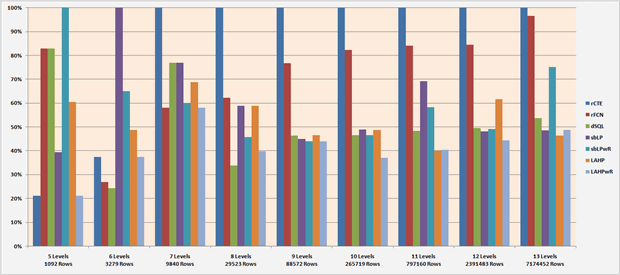
The results are clearly illustrated when you graph them as a percentage of the worst performing solution, which is usually the rCTE.
Conclusions
When traversing the hierarchy we constructed between eight and thirteen levels deep, the set-based WHILE loop avoiding Halloween protection with RECOMPILE option (LAHPwR) is most often the elapsed time winner. Perhaps surprisingly, the non-traditional recursive function seems to do just a little better than the rCTE between six and twelve levels. It is exactly tied with the set-based loop at seven levels. The repeated JOINs method seems contra-indicated across the board (except at six levels) because there’s always a faster performing solution available.
We present these results with a caveat. This is that, depending on your hierarchy one or the other results may be faster for you. Our enlarged hierarchy was exactly balanced; specifically each node had exactly three nodes growing from it. You may find that when only a few of your branches extend out to the higher depths, one of the other approaches may be more suitable for traversal. They also show that sometimes a well-constructed, set-based loop can out-perform the traditional recursive CTE approach.
While adjacency lists for storing hierarchies are quite prevalent, there are other methods that offer opportunities for high performance depending on the requirements of the results from the hierarchies. Nested sets, closure tables and the data mart concept proposed by SQL MVP Jeff Moden in his Hierarchies on Steroids – Parts One and Two all have different advantages depending on circumstance. Perhaps we’ll explore these alternatives in future submissions.
Writing fast SQL is facilitated by knowing what code patterns perform well under various circumstances. We have provided you with several code patterns in this article that you can use to traverse your adjacency list hierarchies, so that you can decide which is best for your particular case.
Further Reading
- Binary Trees in SQL By Joe Celko
- Hierarchies on Steroids #1: Convert an Adjacency List to Nested Sets by Jeff Moden
- Hierarchies on Steroids #2: A Replacement for Nested Sets Calculations be Jeff Moden
- Halloween Problem (Wikipedia)
- Identifying a Subsequence in a Sequence, Part 1 by Itzik Ben-Gan
- Divide and Conquer Halloween by Itzik Ben-Gan
Load comments