
Back in 2009 and 2010, Phil Factor hosted the SQL Speed Phreak Competition, in which programmers were challenged to construct the fastest solution to a series of common programming challenges, such as calculating a running total, or implementing a FIFO (First In, First Out) queue, where the first items purchased or returned must be the first items sold.
The submitted solutions ranged from poorly performing ‘triangular joins’, subqueries, and recursive CTES to safe-and-steady cursors, to lightning-fast but often complex and occasionally unorthodox set-based code.
I wrote a series of articles describing some of the solutions to the running total, FIFO and SSN Matching problems. My basic philosophy is that for most problems there is an easy, maintainable solution and there is a fast solution, and it’s critical to know the size of the performance difference between the two. My goal in writing the articles was to attempt to demystify some of the common techniques the SQL gurus used to wring every ounce of performance out of their solutions, and so make them more widely accessible to developers who need a faster and more scalable solution than more conventional tools, such as cursors, can offer.
The original winning solution to the running total problem, as submitted by Peter Larsson, executed in just milliseconds against a dataset of one million rows. It used some very clever pre-aggregation and pivoting techniques, but also the rather-controversial “quirky update” method. At that time, SQL Server 2008 and 2008 R2 were the latest versions of SQL Server. However, SQL Server 2012 introduced some very powerful new T-SQL window functions and enhancements, which I’ve since used widely. It occurred to me that they could offer a route to a safer, more maintainable solution for some of these problems, without compromising on speed. This article will explain what I discovered when I took another look at the running total problem, in light of these functions.
The Subscription List Problem
The original Subscription List Problem consisted of a table containing a list of subscribers, with the dates that the subscribers joined, and the dates that they cancelled their subscription, as illustrated by the sample data in Figure 1.
| Registration_ID | FirstName | LastName | DateJoined | DateLeft |
| 1 | Judith | Palmer | 2004-01-01 | NULL |
| 2 | Christa | Jackson | 2004-01-01 | NULL |
| 3 | Sophia | Grimes | 2004-01-01 | NULL |
| 19 | Bobbie | Brennan | 2004-01-05 | 2006-09-14 |
Figure 1
The challenge was to produce a report showing a running total of current subscribers for each month. There were two more things to keep in mind about the requirements: don’t calculate past the final month that has new registrations, and the original data doesn’t skip any registration months (if the source data did skip registration months, then all the solutions would need refinement to account for this).
In the original article, I started by describing a very simple cursor-based solution, which also performed expensive date manipulations and ran rather slowly. Next, I reviewed and explained the techniques used in the winning entry, and finally produced a third solution that exploited some of what I’d learned, but still used a cursor for the final running totals, rather than the ‘quirky update’.
I adopt a similar strategy here, presenting solutions as follows:
- The Aunt Kathi solution – the simplest solution I could create, which exploits the capability in SQL Server 2012, and later, to use the
OVERclause and a ‘sliding window’ of data, with aggregate functions. - Peter Larsson’s original winning code – I provide a brief review of the key techniques that made Peter’s solution fly (for further details, refer to my original article)
- The Window Function Speed Phreak Solution – clever date manipulations, pivoting and a Window function.
You can use the SubscriptionList.sql file, available for download above, to create the sample table and ten thousand subscribers. The original tests ran using the same table but containing 1 million subscribers.
On my laptop, with 16 GB of RAM and SSD storage and running SQL Server 2014, solutions 2 and 3 ran so fast for 1 million subscribers that I had to increase the number of rows in the sample data to over 10 million! With this data set, the Aunt Kathi Easy Solution ran in 3 seconds, and the other two were inseparable, at 1.7 seconds.
The Aunt Kathi Easy Solution
This problem is easy to solve using a SQL Server 2012 accumulating window aggregate function, plus the new EOMONTH function, as shown in Listing 1.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
WITH NewSubscriptions AS ( SELECT EOMONTH([DateJoined]) AS DateJoined , COUNT(*) AS PeopleJoined FROM Registrations GROUP BY EOMONTH([DateJoined]) ), Cancellations AS ( SELECT EOMONTH([DateLeft]) AS DateLeft , COUNT(*) AS PeopleLeft FROM Registrations GROUP BY EOMONTH([DateLeft]) ) SELECT DateJoined AS TheMonth , PeopleJoined , ISNULL(PeopleLeft, 0) AS PeopleLeft , SUM(PeopleJoined - ISNULL(PeopleLeft, 0)) OVER ( ORDER BY DateJoined ROWS UNBOUNDED PRECEDING ) AS CurrentSubscriptions FROM NewSubscriptions LEFT OUTER JOIN Cancellations ON DateJoined = DateLeft ORDER BY DateJoined; |
Listing 1: The Aunt Kathi Solution
The challenge requires us to return the current number of subscribers each month. The dates in the data can be any day of the month, so the first task is to manipulate the dates so that they are all the same day of the month. Then, we can count them to arrive at that month’s total.
The cursor solution of the previous article used some rather expensive date conversions to achieve this.
|
1 2 3 4 5 6 7 8 |
SELECT CAST(YEAR(DateJoined) AS VARCHAR) + '-' + CAST(MONTH(DateJoined) AS VARCHAR) + '-1' AS DateJoined , COUNT(*) , 0 , 0 FROM Registrations GROUP BY CAST(YEAR(DateJoined) AS VARCHAR) + '-' + CAST(MONTH(DateJoined) AS VARCHAR) + '-1'; |
As you can see, in my new solution, for SQL Server 2012, I used the EOMONTH function to change the DateJoined and DateLeft values to the last day of the month.
Each month, new subscribers join and some subscriptions cancel or expire. The problem is that each row of the data contains both the DateJoined and DateLeft for one subscription. Therefore, we need to obtain a count by month for each type of date.
One easy way to do this is to create a separate aggregate query to calculate the counts for each type of. In Listing 1, each of these queries is contained within a CTE. SQL Server has to scan the Registrations table twice, once to get the DateJoined count, and once to get the DateLeft count. This is where The Aunt Kathi Solution takes a performance hit of about 1.3 seconds; the original winning solution, as you’ll see later, scans the table just once.
The outer query joins the two CTEs in a LEFT OUTER join on the dates so that all months with new subscriptions are included. The outer query returns the DateJoined as "TheMonth", the number of new and cancelled subscriptions, and the running total.
To calculate the running total, I used a T-SQL accumulating aggregate window function. To change a window aggregate to an accumulating window aggregate, you add an ORDER BY to the OVER clause, in this case ordering by DateJoined. To avoid a performance penalty, I specified the frame ROWS UNBOUNDED PRECEDING. This is a shortcut for ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. If the frame is not specified, the query will use RANGE instead of ROWS. RANGE almost always performs worse than ROWS because it creates a worktable in tempdb instead of in memory.
The Original Winning Code
The original winning code ran in 1.7 seconds on my laptop against 10 million rows. When my article was originally published, it caused a bit of controversy, since it takes advantage of what has been called “the quirky update”, an undocumented method that is not guaranteed, by Microsoft, to work. At the time, the quirky update was the fastest way to calculate a running total. Listing 2 presents the winning code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
CREATE TABLE #Stage ( theMonth SMALLINT NOT NULL , PeopleJoined INT NOT NULL , PeopleLeft INT NOT NULL , Subscribers INT NOT NULL ); INSERT #Stage ( theMonth , PeopleJoined , PeopleLeft , Subscribers ) SELECT u.theMonth , SUM(CASE WHEN u.theCol = 'DateJoined' THEN u.Registrations ELSE 0 END) AS PeopleJoined , SUM(CASE WHEN u.theCol = 'DateLeft' THEN u.Registrations ELSE 0 END) AS PeopleLeft , 0 AS Subscribers FROM ( SELECT DATEDIFF(MONTH, 0, DateJoined) AS DateJoined , DATEDIFF(MONTH, 0, DateLeft) AS DateLeft , COUNT(*) AS Registrations FROM dbo.Registrations GROUP BY DATEDIFF(MONTH, 0, DateJoined) , DATEDIFF(MONTH, 0, DateLeft) ) AS d UNPIVOT ( theMonth FOR theCol IN ( d.DateJoined, d.DateLeft ) ) AS u GROUP BY u.theMonth HAVING SUM(CASE WHEN u.theCol = 'DateJoined' THEN u.Registrations ELSE 0 END) > 0; DECLARE @Subscribers INT = 0; -- The quirky update WITH Yak ( theMonth, PeopleJoined, PeopleLeft, Subscribers ) AS ( SELECT TOP 2147483647 DATEADD(MONTH, theMonth, 0) AS theMonth , PeopleJoined , PeopleLeft , Subscribers FROM #Stage ORDER BY theMonth ) UPDATE Yak SET @Subscribers = Subscribers = @Subscribers + PeopleJoined - PeopleLeft OUTPUT inserted.theMonth , inserted.PeopleJoined , inserted.PeopleLeft , inserted.Subscribers; DROP TABLE #Stage; |
Listing 2: Peter Larsson’s original winning solution
First, the dates must be manipulated. While the Aunt Kathi Easy Solution uses the EOMONTH function, the original winning solution uses a combination of DATEDIFF and DATEADD to turn each date to the first of the month.
The DATEDIFF function is used to calculate the number of months since the date represented by 0. That number is then added back to date 0 to get the original month and year. The solution applies DATEDIFF before aggregating and DATEADD after aggregating. If the functions were used in one step, the formula would look like this:
|
1 |
DATEADD(m,DATEDIFF(m,0,DateJoined),0) |
The Aunt Kathi Easy Solution used two CTEs to calculate the count for new subscriptions and cancellations for each month. The winning solution achieves the same list of months, actually the number of months past date 0, with counts, in such a way that it requires only a single scan of the Registrations table, instead of two. It uses the UNPIVOT method to cause the two date columns to line up into one column. Then the CASE expression is used to re-pivot the data into a list with a count of new subscriptions and cancellations. By using this method, the winning solution scans the table just once. Figure 2 demonstrates the transformations that the data takes in this solution.
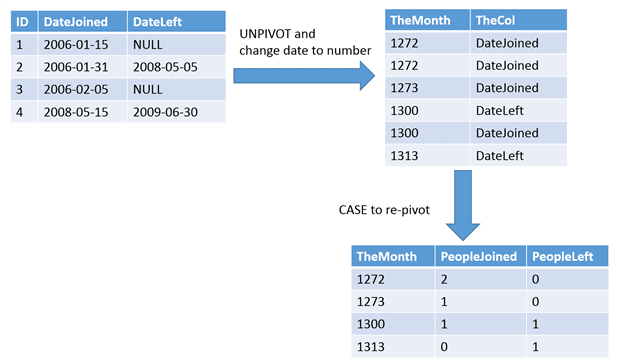
Figure 2
The number of months since date 0 and the counts are stored in a temp table, #stage. The temp table is used because the quirky update actually updatesthe source data. Using a temp table with a column to hold the answer avoids updating the original table. Months with no new subscriptions are filtered out in the HAVING clause.
The final step uses a CTE (called Yak), in which the DATEADD function turns the number of months back into a date and orders the data. The quirky update relies on the data being returned in the correct order, but updates do not support an ORDER BY clause. Usually, ordering the data is not allowed in a CTE, but the solution gets around this by using the TOP keyword, which allows you to retrieve a number or percentage of rows, in this case largest possible integer value (2147483647), to make sure that all the rows will be returned. In order to control which rows a query returns when using TOP, you can use ORDER BY to sort the data.
This is a controversial technique since the idea behind using TOP and ORDER BY within a CTE is to get the correct rows, not to actually order them. It’s possible that the rows will not be returned in order in a future version of SQL Server.
The outer query uses a variable to store a subtotal from row to row. Not only is the value of the variable updated for each row, the Subscribers column from the CTE is also updated each time. The quirky update code looks like this:
|
1 |
SET @Subscribers = Subscribers = @Subscribers + PeopleJoined - PeopleLeft |
The PeopleJoined value is added to and the PeopleLeft value is subtracted from the previous value of the variable. That total is saved in the Subscribers column and is also passed to the @Subscribers variable. It’s a row-by-row process, but it runs extraordinarily fast.
To avoid taking a performance hit later by selecting rows from the temp table once the values are calculated, the OUPUT clause is used. The OUTPUT clause returns data that is updated, inserted, or deleted, and, in this case, the results of the puzzle.
The Window Function Speed Phreak Solution
This solution adopts the use of DATEDIFF and DATEADD functions to convert dates to the first day of the month, and uses the “UNPIVOT and re-pivot with CASE" to calculate the count for new subscriptions and cancellations for each month with only a single table scan.
However, it avoids the quirky update and doesn’t need a temp table. It uses a T-SQL window accumulating aggregate to calculate the running total. This solution also runs in 1.7 seconds.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
WITH Totals AS ( SELECT DATEADD(m, u.theMonth, 0) AS TheMonth , SUM(CASE WHEN u.theCol = 'DateJoined' THEN u.Registrations ELSE 0 END) AS PeopleJoined , SUM(CASE WHEN u.theCol = 'DateLeft' THEN u.Registrations ELSE 0 END) AS PeopleLeft FROM ( SELECT DATEDIFF(MONTH, 0, DateJoined) AS DateJoined , DATEDIFF(MONTH, 0, DateLeft) AS DateLeft , COUNT(*) AS Registrations FROM dbo.Registrations GROUP BY DATEDIFF(MONTH, 0, DateJoined) , DATEDIFF(MONTH, 0, DateLeft) ) AS d UNPIVOT ( theMonth FOR theCol IN ( d.DateJoined, d.DateLeft ) ) AS u GROUP BY u.theMonth HAVING SUM(CASE WHEN u.theCol = 'DateJoined' THEN u.Registrations ELSE 0 END) > 0 ) SELECT TheMonth , PeopleJoined , PeopleLeft , SUM(PeopleJoined - PeopleLeft) OVER ( ORDER BY TheMonth ROWS UNBOUNDED PRECEDING ) AS CurrentSubscribers FROM Totals; |
Listing 3: The Window Function Speed Phreak Solution
Instead of storing the list of month numbers and the counts in a temp table, this solution adds to a CTE the code that would have been used to populate the temp table.
The outer query just returns the month, the number of people who joined and left, and uses the T-SQL SUM window aggregate function, along with the new OVER clause, to calculate the running total. This solution is guaranteed to work, unlike the quirky update, and performs exactly the same.
Conclusion
When speaking at SQL Server events, I always say that the 2012 T-SQL Window functions have given T-SQL super powers. Armed with these new powers, plus a few aggregation and data manipulation techniques that can help minimize the work that SQL Server needs to perform, we arrive at a running total solution that is fast, guaranteed to work, and not so quirky.
In the next article, I’ll explain how using the new functionality helps solve the FIFO Stock Inventory Problem.
If you are inspired to learn more about Window Functions…
I’ve written a book on the topic, Expert T-SQL Window Functions in SQL Server, and a Pluralsight online training course.



Load comments