
Editor’s Note: As these screenshots incorporate elements of Brazilian Portuguese, please bear in mind that the word ‘Codigo’ means Code, and for consistency we’ve decided to use the Portuguese term whenever refering to the columns in the test database this article features.
Here was the scene to start with: The client had purchased a really nice, latest-generation server (SAN and Blade, 32 GB RAM, 16 processors, W2K8 64, SQL2K8 64), and the whole disc apparatus was set up according to Microsoft best practices (block size of 64K, stripe size of 128K, set raids 0+1 to separate log and data).. But some counters were completely out of the ordinary. On one of the more accessible databases (Approx 400 GB – out of a total of almost 4 TB of user Databases), the disk readings were really quite scary:
|
Physical Disk |
|||
|
Date |
% Disk Read Time |
Avg Disk Queue length |
Avg Disk Sec/transfer |
|
‘Normal’ values |
should be < 2 per physical disc in the RAID array |
Typically, if the value is larger than 20 ms, the disk is over-loaded: |
|
|
2009/07/28 |
3300 |
542 |
37 |
|
2009/07/29 |
2700 |
580 |
35 |
|
2009/07/30 |
3000 |
540 |
30 |
|
SQL Server |
|
|
Date |
Page Life Expectancy |
|
‘Normal’ value |
Should be > 600 |
|
2009/07/28 |
80 |
|
2009/07/29 |
60 |
|
2009/07/30 |
75 |
To be honest, I only looked at the % Disk Read Time because it seemed pretty extreme. I couldn’t really tell what the norm was in this case, but the counter was very, very high, so I assumed there was a problem even though 100+% Disc Read Times are fairly normal in RAID arrays:
“This behavior can occur because some controllers allow the operating system to use overlapping input/output operations for multiple outstanding requests… If you have multiple disks in a Raid arrangement, the overlapped input/output happens because the operating system can read and write to multiple disks, and this could show values that are higher than 100 percent for this counter.“
– Microsoft Support Knowledge Base
I haven’t included all the counters I looked at here, just the more interesting ones. Obviously the ‘normal’ values for these counters are not hard rules; I would not be concerned if the values were 20 – 30% above these (partly because I did not have any baselines set up- as we say in Brazil, I “fell from an airplane” into this project). But as you can see, that wasn’t exactly the case, and the values were pretty strange – Daily averages of ‘lumbering-dinosaur’ disk read times, absurd disk queues and ridiculously low page life expectancies. If you’re interested, you can read more about these metrics over at Microsoft TechNet, here, here and here.
(I automated this collection rather nicely- The Perfmon captured data from this database to a .csv file in 15 seconds, and a SQL Server job uploaded that file into a table. I will be posting this routine at a later date, as it is very simple and functional, and I am always in favor of simplicity)
The worst thing about this situation was that in two days time we would be getting 4 more subsidiaries and an online Warehouse. There’s no way the disc would bear up to that kind of load, so I had two days to do something drastic. I could investigate with the Profiler easily enough, but there was no way I’d have time to rewrite the queries (which were very poorly written; the cursors looked like Christmas lights, and anyone who knows me knows that I think of them). Basically, I needed some kind of miracle, and luckily that’s exactly what was available in the fantastic “missing indexes” DMVs. In case you’ve never seen these before, they are:
|
Returns summary information about missing index groups. For example, the performance improvements that could be gained by implementing a specific group of missing indexes |
|
|
Returns information about a specific group of missing indexes, such as the group identifier and the identifiers of all missing indexes that are contained in that group. |
|
|
Returns detailed information about a missing index. For example, it returns the name and identifier of the table where the index is missing, and the columns and column types that should make up the missing index. |
|
|
Returns information about the database table columns that are missing an index. |
– Retrieved from BOL 2008.
You can find out more about them here. Now, I’m all for not reinventing the wheel, so I went to my SQL Server bible, SQLServerCentral, to find an implementation. I found the Util_MissingIndexes script by Jesse Roberge (with many thanks for the author) which, taking a table as a parameter, “reports stats on what the query optimizer records in the DMVs as ‘missing indexes’, and what it says the cost savings will be if they were present“. It returns a few columns, but the most important are:
|
Column |
Description |
|
unique_compiles |
Number of compilations and recompilations that would benefit from this missing index group. Compilations and recompilations of many different queries can contribute to this column value. |
|
user_seeks |
Number of seeks caused by user queries that the recommended index in the group could have been used for. |
|
last_user_seek |
Date and time of last seek caused by user queries that the recommended index in the group could have been used for. |
|
avg_total_user_cost |
Average cost of the user queries that could be reduced by the index in the group. |
|
equality_column |
Comma-separated list of columns that contribute to equality predicates of the form: |
|
inequality_columns |
Comma-separated list of columns that contribute to inequality predicates, for example, predicates of the form: |
|
included_columns |
Comma-separated list of columns needed as covering columns for the query. |
– Retrieved from BOL 2008.
The columns that were used in my case were user_seeks, last_user_seek ,avg_user_impact and, obviously, columns suggested as an index. Before I show you what these DMVs can do, I’ll cut to the chase now and tell you that, on the day that the subsidiaries and Warehouse were due to be brought online, and with two hours to spare, I finished the improvements and the (massively) improved counters were:
|
Physical Disk |
|||
|
Date |
% Disk Read Time |
Avg Disk Queue length |
Avg Disk Sec/transfer |
|
2009/07/31 |
1225 |
129 |
12.98293 |
|
2009/08/01 |
340 |
74 |
0.99393 |
|
2009/08/02 |
37 |
0.16785 |
0.38722 |
|
2009/08/03 |
20 |
0.15478 |
0.12452 |
|
SQL Server |
|
|
Date |
Page Life Expectancy |
|
2009/07/31 |
900 |
|
2009/08/01 |
1400 |
|
2009/08/02 |
7000 |
|
2009/08/03 |
6800 |
Much better!
The DMV Surprise
When I set out to solve this problem, I focused on the avg_user_impact and user_seek columns because I was more interested in improving 40% of queries by a factor of 50 than 90% of queries by factors of just 2 or 3. Admittedly, once I was done with that I had a second job of reviewing the unused and little-used indexes, review queries, take off cursors etc., but that’s an ongoing project, and not something I’m going to even mention here. I didn’t bother with fill factor at this point (although it is very important) because I just didn’t have time to analyze the load that these indexes would come under. As it turns out, I would be in a better position monitoring them after they were being used, and this is something I’ll tell you about another time.
To tell the truth I was expecting an improvement, just not one like this, as I am deeply skeptical of anything suggested automatically. Sure, I’ll use the Index Tuning Wizard very occasionally, but I really prefer to manually review queries. In this case, because of those phenomenal improvements to the numbers, I decided to understand a little more about these DMV’s, and I had some questions:
- When a query which uses this index is run, is the user_seeks column really updated?
- When a query which uses this index is run, is the last_user_seek column really updated?
- When columns are suggested for the index, does the optimizer take into account selectivity, density and other statistical information to make that suggestion, or does it just look at the order of WHERE clauses?
- Does the avg_user_impact column report the actual percentage of potential performance improvement?
Does the Query Optimizer know what it’s doing?
To help slake my curiosity, I decided to do some tests. I created a table of 1000000 rows with different selectivity between the columns:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TABLE [dbo].[TestDmv]( [Codigo1] [int] NOT NULL, [Codigo2] [int] NULL, [Codigo3] [int] NULL, [Codigo4] [int] NULL, [Field1] [varchar](50) NULL, [Field2] [varchar](50) NULL, [Field3] [varchar](50) NULL, [Field4] [varchar](50) NULL, CONSTRAINT [PK_TestDmv] PRIMARY KEY CLUSTERED ( [Codigo1] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] |
… and then populated the columns:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
set nocount on declare @Codigo1 int = 0 declare @Codigo2 int = 0 declare @Codigo3 int = 0 declare @Codigo4 int = 0 while @Codigo1 < 1000000 begin if (@Codigo1 between 0 and 1000) or (@Codigo1 between 2000 and 5000) or (@Codigo1 between 7000 and 9000)or (@Codigo1 between 10000 and 20000) or (@Codigo1 between 30000 and 40000) or (@Codigo1 between 40000 and 60000) or (@Codigo1 between 50000 and 80000) or (@Codigo1 between 80000 and 100000) or (@Codigo1 between 100000 and 200000) or (@Codigo1 between 300000 and 400000) or (@Codigo1 between 500000 and 500100) or (@Codigo1 between 600000 and 700000) or (@Codigo1 between 800000 and 900000) set @Codigo2 = @Codigo2 else set @Codigo2 = @Codigo2 + 1 if (@Codigo1 between 30000 and 60000) OR (@Codigo1 between 200000 and 200100) set @Codigo3 = @Codigo3 else set @Codigo3 = @Codigo3 + 1 if (@Codigo1 between 10000 and 20000) set @Codigo4 = @Codigo4 + 1 else set @Codigo4 = @Codigo4 insert into TestDmv(Field1,Field2,Field3,Field4,Codigo1,Codigo2,Codigo3,Codigo4) values ('field1 ' + CAST(@Codigo1 as CHAR(10)), 'field2 ' + CAST(@Codigo2 as CHAR(10)), 'field3 ' + CAST(@Codigo3 as CHAR(10)), 'field4 ' + CAST(@Codigo4 as CHAR(10)), @Codigo1, @Codigo2, @Codigo3, @Codigo4 ) set @Codigo1 = @Codigo1 + 1 end |
Then I ran the Missing Indexes process:

No suggestions yet, so I ran this query next:
|
1 2 3 4 5 6 7 8 |
SELECT field1, field2, field3, field4 FROM testdmv WHERE Codigo1 = 10 GO EXEC Util_MissingIndexes '','testdmv' |

Still no suggestions; the clustered index was used. Moving on to the next test, with this query…
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT field1, field2, field3, field4 FROM testdmv WHERE Codigo3 BETWEEN 10 AND 10000 AND Codigo2 BETWEEN 1 AND 1000 GO EXEC Util_MissingIndexes '','testdmv' |

… Woohoo! I had something:
- user_seeks : 1
- last_user_seek : 2009-09-30 23:06:04.820
I ran the query again…

- user_seeks : 2
- last_user_seek : 2009-09-30 23:14:22.927
It looks like we can trust the updates to the user_seek and last_user_seek Columns, so that was my first two questions pretty quickly answered – so far so good. Using the result of that little procedure, I could also see that some columns had been suggested as indexes:
- Equality_columns = NULL
- Inequality_columns = [Codigo2], [Codigo3]
- Included_columns = [Field1], [Field2], [Field3], [Field4]
Why was the equality_columns suggestion null, you ask? Because of my query conditions, which didn’t use the equality operator (=), but rather “between …” operators which were populated with values.
SQL server does not always need to go into the data pages to respond to a query if the columns requested by the query are fully “covered” or documented in the index, hence the term “covered index”. If they are not covered, SQL server has to go to the data pages to return the missing columns. This process is called BookMark Lookup (SQL2K) or RID Lookup (SQL2K5), and is computationally expensive to perform.
Yet the index order suggested by the Optimizer was Codigo2, Codigo3 and not Codigo3, Codigo2, as I wrote in my WHERE clause, and this could potentially be an ‘expensive’ index. Clearly, in this case. the order would not affect the use of the index, but the optimizer is smart enough to switch the order around if necessary, so there must have been some reason for the ordering. I created the index as suggested to see if I could figure it out:
|
1 2 3 4 |
CREATE INDEX idx_test_01 ON testdmv (Codigo2,Codigo3) include (field1,field2,field3,field4) GO EXEC Util_MissingIndexes '','testdmv' |

As you can see, the suggested index did not appear, so I decided to take a look at the IO statistics and execution plan:
|
1 |
TABLE 'TestDmv'. Scan COUNT 1, logical reads 52, physical reads 0, READ-ahead reads 0, lob logical reads 0, lob physical reads 0, lob READ-ahead reads 0. |

Now that I had another benchmark to compare against, I switched the order of the WHERE clause to Codigo3, Codigo2, and the result was:
|
1 |
TABLE 'TestDmv'. Scan COUNT 1, logical reads 123, physical reads 0, READ-ahead reads 0, lob logical reads 0, lob physical reads 0, lob READ-ahead reads 0. |
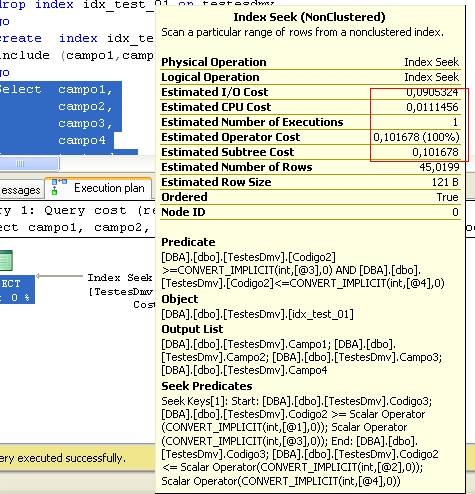
You can see that besides the logical reads, the CPU and IO costs increased, so it looks like the query optimizer knows what it’s doing. Next I needed to try using a WHERE clause with the equality operator.
|
1 2 3 4 5 6 7 8 9 |
SELECT field1, field2, field3, field4 FROM testdmv WHERE Codigo4 = 10001 AND Codigo3 = 30000 GO EXEC Util_MissingIndexes '','testdmv' |

As before, there was only data in the inequality column because the WHERE clause only had equality conditions. And also as before, the columns suggested as indexes were in a different order from the WHERE clause. At this point, I decided to investigate from a different angle – I wanted to see the selectivity of these columns, using a script written by Nilton Pinheiro.
|
1 2 3 4 5 |
SELECT [Total Lines] = COUNT(*), [Distinct Lines] = COUNT(DISTINCT <COLUMN>), -- the closer to 1, the better [selectivity] = COUNT(DISTINCT <COLUMN>)/CAST( COUNT(*) AS DEC(10,2)) FROM <yourtable> |
So, what would the selectivity of the Codigo3 and Codigo4 columns be?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT [Total Lines] = COUNT(*), [Distinct Lines] = COUNT(DISTINCT Codigo3), -- the closer to 1, the better [selectivity] = COUNT(DISTINCT Codigo3)/CAST( COUNT(*) AS DEC(10,2)) FROM testdmv SELECT [Total Lines] = COUNT(*), [Distinct Lines] = COUNT(DISTINCT Codigo4), -- the closer to 1, the better [selectivity] = COUNT(DISTINCT Codigo4)/CAST( COUNT(*) AS DEC(10,2)) FROM testdmv Codigo3 Total Lines DISTINCT Lines selectivity ----------- -------------- --------------------------------------- 1000000 969898 0.96989800000 (1 row(s) affected) Codigo4 Total Lines DISTINCT Lines selectivity ----------- -------------- --------------------------------------- 1000000 10002 0.01000200000 (1 row(s) affected) |
It turns out that the Codigo3 column was much more selective than Codigo4 – Another goal for the optimizer! But now I wondered what would happen if I had one WHERE clause using both equality and inequality conditions?
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT field1, field2, field3, field4 FROM testdmv WHERE Codigo2 BETWEEN 100 AND 100000 AND Codigo4 = 10001 AND Codigo3 = 30000 GO EXEC Util_MissingIndexes '','testdmv' |

- Equality_columns = [Codigo3],[Codigo4]
- Inequality_columns = [Codigo2]
- Included_columns = Null
By now I was pretty convinced that the optimizer knew what it was doing. In this case, I would simply create the index, putting the equality columns first and inequality after them, as we can find in the best practices on BOL:
Use the following guidelines for ordering columns in the CREATE INDEX statements you write from the missing indexes feature component output:
- List the equality columns first (leftmost in the column list).
- List the inequality columns after the equality columns (to the right of equality columns listed).
- List the include columns in the INCLUDE clause of the CREATE INDEX statement.
…so the index should always in this order (equality first and inequality after).
|
1 |
CREATE INDEX Idx_test_02 ON testdmv(Codigo3,Codigo4,Codigo2) |
So, my third question was now answered – The Optimizer does not use the ordering of the WHERE clause, but rather suggests the best indexes based in your statistics (By this point, I did not expect anything less from the optimization team).
Finally, I wanted to see if the avg_total_user_cost value really was consistent with real performance:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
DBCC dropcleanbuffers GO SET STATISTICS time ON GO SELECT field1, field2, field3, field4 FROM testdmv WHERE Codigo2 BETWEEN 100 AND 1000000 AND Codigo4 = 10001 AND Codigo3 = 30000 (30002 row(s) affected) SQL Server Execution Times: CPU time = 423 ms, elapsed time = 4471 ms. |
I created the index…
|
1 2 |
CREATE NONCLUSTERED INDEX Idx_test_03 ON [dbo].[TestDmv] ([Codigo3],[Codigo4],[Codigo2]) |
And ran the same query again, to see these results:
|
1 2 |
SQL Server Execution Times: CPU time = 31 ms, elapsed time = 1308 ms. |
Well, given that the predicted avg_user_impact was 98.71%, and I had 4471 ms brought down to1308 ms, the data from DMVs was pretty close. My last question was answered – The avg_total_user_cost is a ‘real’ number, or at least is very, very near the mark.
This is possibly one of the better features included in SQL Server. Obviously these indexes are only suggested, and we have to bear in mind a few other concerns too, like the fact that all INSERT, DELETE and UPDATE operations will be affected by these suggestions and may become very slow if we create too many indexes on the table. Nor can we forget that these indexes will also be using disk space. So analyze the potential impact before creating the them, but one thing I can tell you for sure is that we can trust the data of the “Missing indexes” DMVs. I hope this fantastic feature can help you like it helped me.


Load comments