
Just because certain SQL JOINs are possible doesn’t mean that they are a good option. The ‘conditional JOIN’ is one of these.
So what is a conditional join? This is where one key in a table is used to join either with one table or others, depending on some criterion. It sounds extraordinary, but it can happen, particularly in highly complex, sometimes auto-generated queries. It usually represents an attempt to use a polymorphic association between tables, and is a SQL Code Smell.
The term ‘Conditional JOIN’ is somewhat ambiguous, in that people refer to different problems when they use it. It seems as if programmers wish to either JOIN a table to more than one other table or to JOIN a column in a table to different columns in a second table, choosing the JOIN column based on a condition.
Since T-SQL has no syntax that would allow for putting a table name into a CASE statement, the first definition of the conditional JOIN really has no means to resolve other than to simply JOIN all the tables (likely as LEFT OUTER JOINs) and use CASE statements to pull the specific data item(s) required from the secondary tables as appropriate.
Recently I was writing a query that could be resolved using the second case. While I thought about several other ways to do it, from a coding standpoint using a CASE statement in the ON clause of the JOIN resulted in the simplest syntax to make the query work. However, was syntax that looked simple the most efficient way of doing it?
Let’s face it, sometimes in programming you don’t have the luxury of standing back and redesigning the system to avoid the requirement, but it is always best if we can optimize the performance of the SQL that meets the requirement.
Sample Data
We’ll start with a simple example to illustrate a conditional join. This code creates two tables, with one million rows of test data in the secondary table that we’ll be doing the conditional JOIN to.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
CREATE TABLE dbo.SampleLeftTable ( ID INT IDENTITY PRIMARY KEY ,num INT NOT NULL ); INSERT INTO dbo.SampleLeftTable (num) VALUES(21),(44),(53),(78); CREATE TABLE dbo.ConditionalJoinExample ( ID INT IDENTITY PRIMARY KEY ,N1 INT NOT NULL ,N2 INT NOT NULL ,N3 INT NOT NULL ,N4 INT NOT NULL ); WITH Tally(n) AS ( SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM(VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) a(n) -- 10 rows CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) b(n) -- x10 rows CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) c(n) -- x10 rows CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) d(n) -- x10 rows CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) e(n) -- x10 rows CROSS JOIN (VALUES(0),(0),(0),(0),(0),(0),(0),(0),(0),(0)) f(n) -- x10 rows ) -- = 1M rows INSERT INTO dbo.ConditionalJoinExample ( N1, N2, N3, N4 ) -- Populate each column with a random number in the range {1,100} SELECT N1 = 1+ABS(CHECKSUM(NEWID()))%100 ,N2 = 1+ABS(CHECKSUM(NEWID()))%100 ,N3 = 1+ABS(CHECKSUM(NEWID()))%100 ,N4 = 1+ABS(CHECKSUM(NEWID()))%100 FROM Tally; GO --DROP TABLE dbo.SampleLeftTable; --DROP TABLE dbo.ConditionalJoinExample; Here are the results. SELECT * FROM dbo.SampleLeftTable; ID num 1 21 2 44 3 53 4 78 SELECT TOP 10 * FROM dbo.ConditionalJoinExample; ID N1 N2 N3 N4 1 19 30 1 66 2 61 92 69 51 3 9 1 20 74 4 81 78 76 79 5 62 100 37 75 6 59 83 58 43 7 89 70 76 30 8 40 11 85 91 9 97 16 67 84 10 22 50 74 30 |
You can see that the four data columns (N1, N2, N3 and N4) contain random numbers in the range 1 to 100. We’ve selected the TOP 10 rows just to illustrate, and if you’re following along you’ll get different but similar results in the second results set. The commented-out DROPs are provided to clean up your sandbox later if you want to run these examples on your server. Note that we’ll be running them using SQL 2012, but SQL 2008 or SQL 2005 can also be used.
Scenario 1: Conditional JOIN Based on Data in the Left Table
Now suppose we have a business requirement that states we want to perform a JOIN from the left table (4 rows) to the secondary table based on the range that the value in the left table falls into. Such a JOIN may look like this.
|
1 2 3 4 5 6 7 8 9 |
SELECT a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = CASE WHEN num BETWEEN 1 AND 25 THEN b.N1 WHEN num BETWEEN 26 AND 50 THEN b.N2 WHEN num BETWEEN 51 AND 75 THEN b.N3 ELSE b.N4 END; |
And it displays results that look like this (only the first five rows are shown, out of about 40,000 returned).
|
1 2 3 4 5 6 |
ID num ID N1 N2 N3 N4 3 53 23 52 70 53 4 3 53 72 48 49 53 3 3 53 227 89 81 53 1 3 53 269 19 28 53 77 3 53 393 83 72 53 78 |
You can see that because the value of Num of the row in the left table is 53, it is matching on the third N column (N3) in the table JOINed to.
I was interested in TIME and IO STATISTICS so I ran that query with them on and we got these results.
|
1 2 3 4 5 6 7 8 9 |
(40104 row(s) affected) Table 'SampleLeftTable'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ConditionalJoinExample'. Scan count 4, logical reads 14400, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 11676892, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 20015 ms, elapsed time = 5617 ms. |
While the query only took about five and a half seconds to run, it looked suspiciously expensive in terms of CPU. The query plan for it was this.
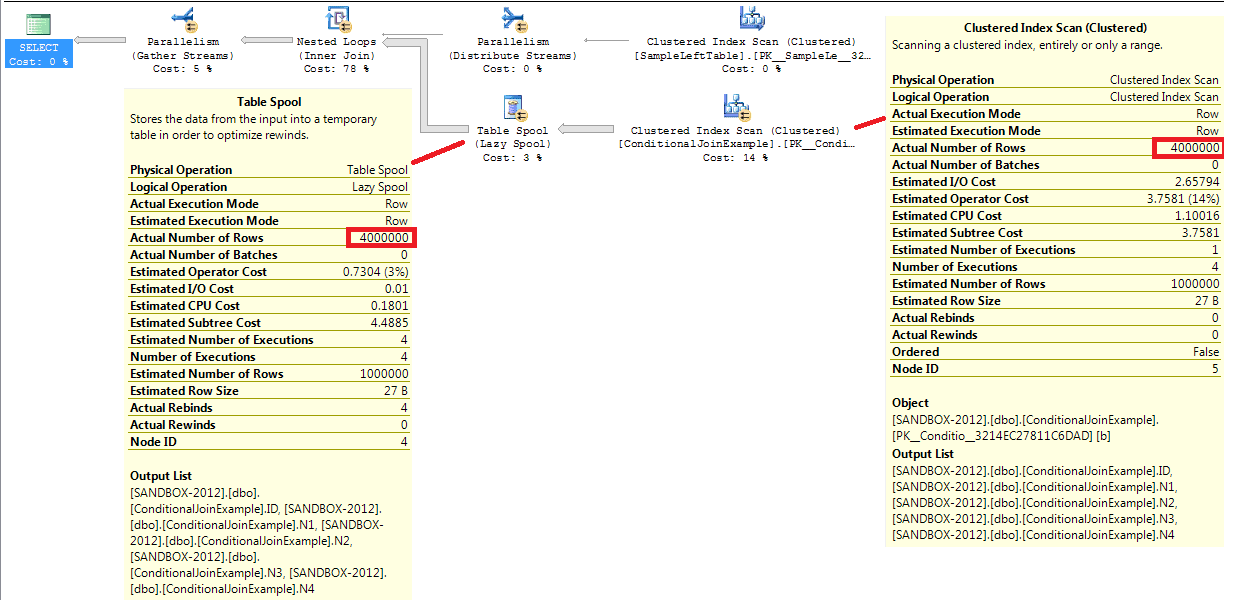
First off, we should not be surprised to see a Parallelism operator in the plans, because from our timing results we see that CPU time used is way in excess of the elapsed time for the query.
We also see that both tables are using a Clustered Index Scan operator, but when we look a little deeper into what is going on with the right table (by expanding the details of the Table Spool and Clustered Index Scan operators), we see that they’re trying to operate on four million (actual) rows of data, when there are only one million rows of data in the table!
Our first thought of course is that perhaps we can build an INDEX to speed this bad boy up a bit. So let’s try that.
|
1 |
CREATEINDEX ix5ON dbo.ConditionalJoinExample(N1,N2,N3,N4); |
When we run that same query again, we get these timing results.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 2 ms. (40104 row(s) affected) Table 'SampleLeftTable'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ConditionalJoinExample'. Scan count 4, logical reads 12928, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 11676892, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 20279 ms, elapsed time = 5949 ms. |
And they are not very impressive, being of approximately the same order of magnitude as the first. As to the query plan:

We see that while the INDEX we created is being used, it didn’t seem to help much. If you repeat this query and hover your cursor over the Index Scan (NonClustered) and Table Spool operators in the graphical query plan, you will find that the same four million actual rows were being used in the query.
It is definitely time to rewrite this query and make it run faster by finding an alternative to the conditional join.
Instead of our conditional JOIN, we can partition the big table into four parts, doing successive JOINs on each of the partitions, and then recombining the parts like this (using UNION ALL):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
-- Drop the annoyingly unhelpful INDEX DROP INDEX ix5 ON dbo.ConditionalJoinExample; SELECT a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N1 WHERE num BETWEEN 1 AND 25 UNION ALL SELECT a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N2 WHERE num BETWEEN 26 AND 50 UNION ALL SELECT a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N3 WHERE num BETWEEN 51 AND 75 UNION ALL SELECT a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N4 WHERE num BETWEEN 76 AND 100; |
While that appears to be a much more complex query (it certainly takes a lot longer to write even using copy and paste), we are pretty impressed by the timing results:
|
1 2 3 4 5 6 7 8 9 |
(40104 row(s) affected) Table 'SampleLeftTable'. Scan count 4, logical reads 8, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ConditionalJoinExample'. Scan count 20, logical reads 14600, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 249 ms, elapsed time = 389 ms. |
While this query is now running in less than half a second (with CPU time down by two orders of magnitude), it does produce a much more (seemingly) complex query plan.
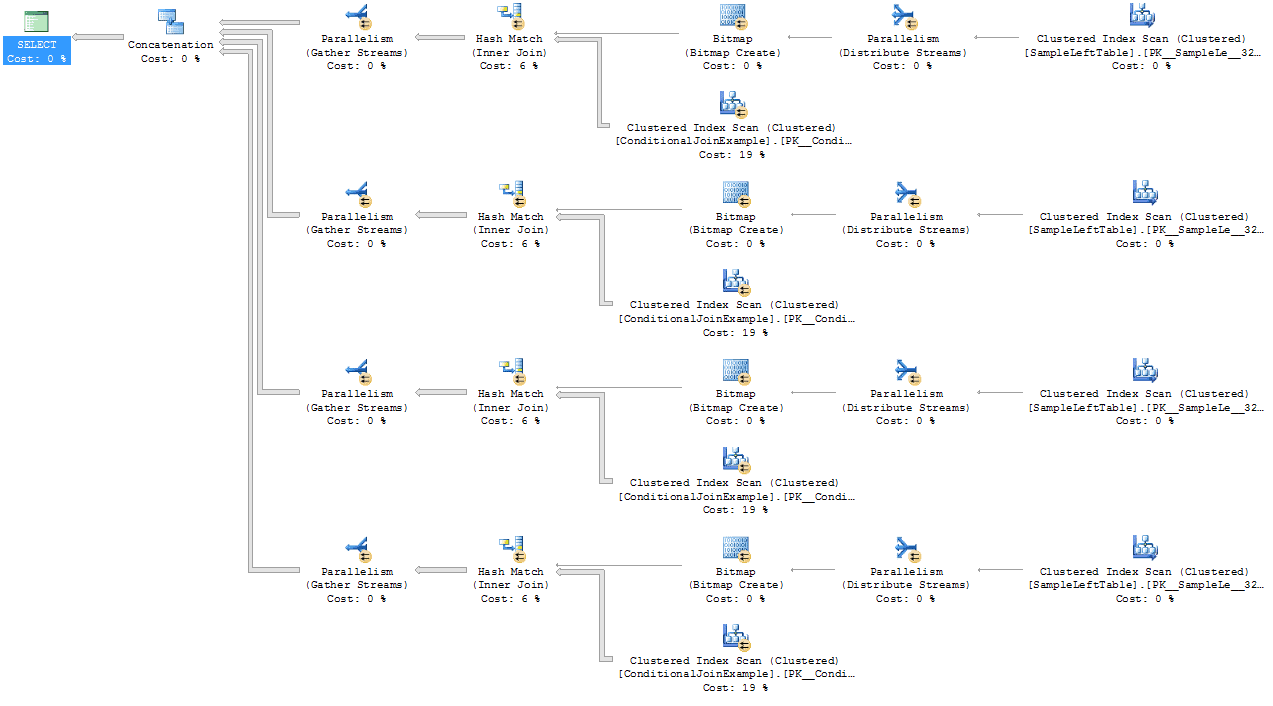
Even though SQL is doing four Clustered Index Scans of the big table, the results are overwhelmingly in favor of this query over the conditional JOIN.
SQL 2012 grumbled somewhat that an INDEX was missing that could improve the query a bit, so let’s go ahead and create the INDEX that it recommends and try again.
|
1 2 |
-- Add the recommended INDEX CREATE NONCLUSTERED INDEX ix1 ON dbo.ConditionalJoinExample (N4) INCLUDE (ID, N1, N2, N3); |
Now we get these timing results:
|
1 2 3 4 5 6 7 8 9 |
(40104 row(s) affected) Table 'SampleLeftTable'. Scan count 4, logical reads 8, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ConditionalJoinExample'. Scan count 16, logical reads 9807, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 265 ms, elapsed time = 398 ms. |
It looks to me like that recommended INDEX didn’t help one bit! And I did in fact check the query plan and found that the optimizer used the recommended INDEX.
From my perspective I’d say that the rewrite worked sufficiently that I wouldn’t hesitate to use it in production without the recommended INDEX, thus saving the space that building that INDEX would entail, not to mention the overhead having that INDEX would impose on INSERT, UPDATE and DELETE statements.
I should also point out that in our first (conditional JOIN) attempt, we were working with columns (N1, …, N4) that were all of the same data type. If in your case, you are not, there are likely additional performance detractors in getting them to the same data type, that you should watch for and consider.
Let’s drop that INDEX before we proceed with our next scenario.
|
1 |
DROP INDEXix1 ONdbo.ConditionalJoinExample; |
Scenario 2: Conditional JOIN Based on an External Parameter
Sometimes you may have a SQL problem that makes you believe that you need to drive the conditional JOIN key column by a switch of some sort, perhaps one that is passed in as a parameter in a stored procedure. Let’s look at a simplified example that does not employ a stored procedure:
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE @Switch INT = 1; SELECT a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = CASE @Switch WHEN 1 THEN b.N1 WHEN 2 THEN b.N2 WHEN 3 THEN b.N3 ELSE b.N4 END; |
Here the @Switch local variable controls the column we’ll JOIN on. Timing results look suspiciously similar to the first case we explored.
|
1 2 3 4 5 6 7 8 9 |
(40156 row(s) affected) Table 'SampleLeftTable'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ConditionalJoinExample'. Scan count 4, logical reads 14400, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 11676892, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 19297 ms, elapsed time = 5284 ms. |
Indeed, the query plan, which we won’t show here, looks remarkably similar to the first query plan we showed, right down to the four million actual row counts in the Clustered Index Scan and Table Spool operators.
Using the identical refactoring approach:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
DECLARE @Switch INT = 1; SELECT a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N1 WHERE @Switch = 1 UNION ALL SELECT a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N2 WHERE @Switch = 2 UNION ALL SELECT a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N3 WHERE @Switch = 3 UNION ALL SELECT a.ID, num, b.ID, N1, N2, N3, N4 FROM dbo.SampleLeftTable a JOIN dbo.ConditionalJoinExample b ON num = b.N4 WHERE @Switch NOT IN (1,2,3); |
We end up with a much more complicated looking query (with a similar, much more complicated query plan), that runs lickety-split!
|
1 2 3 4 5 6 7 8 9 |
(40156 row(s) affected) Table 'SampleLeftTable'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ConditionalJoinExample'. Scan count 5, logical reads 3650, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 108 ms, elapsed time = 324 ms. |
Now, if you were to be passing the @Switch variable into a stored procedure, it is quite possible that you could run into parameter sniffing issues in either or both of these cases. But we won’t explore the details here (nor how to resolve them), as they’ve been covered pretty thoroughly by SQL MVP Erland Sommarskog in his excellent blog on this subject “Slow in the Application, Fast in SSMS?“
Conclusions
You can never be certain that code that looks elegant on-screen will be executed quickly. The query that uses a conditional JOIN may seem to solve the problem, but it is worth exploring alternatives to make sure you don’t run into performance issues when your data grows large.
Some other lessons learned from the two scenarios we explored in this article are:
- The simplest looking query plan may not always perform the most efficiently.
- INDEXes recommended by SQL 2012 in the graphic query plan (and presumably by SQL Tuning Advisor) may not always help your query perform faster, even when the Optimizer chooses to use them.
- If performance counts, and it usually does, check your queries for performance issues and consider alternative ways of achieving the same result.
Finally, you may be wondering what happened in the case of my query that I mentioned early on. It wasn’t quite as simple of course as the two scenarios we explored here. It was using a big table generated by a schema-bound VIEW and there weren’t only four cases to consider (although there were four potential columns to JOIN upon). The use of a conditional JOIN got the business solution working quickly, however when I tested the performance I found it wanting. So I went that extra mile to improve upon it, and ultimately the extra effort yielded satisfactory results.
Thanks for reading, folks! I hope that one day you can use the lessons I learned here to improve the speed of at least one of your queries.
Load comments