
Oracle database, since its inception, has always used a very specific and unique architecture which served it very well. In earlier forms of this architecture, all components of the database were meant to work in a one-to-one mapping with each other. But from version 12c onwards, a completely new architecture has been introduced – Oracle Multitenant. In other words, from 12c onwards, there are two ways to create a database, as a multitenant database or a pre-12c non-multitenant database. In this series, we will learn how this new architecture works, build components within the new architecture, and learn how to manage different aspects of it, such as backup and security. In this first article, we’ll learn about the necessity of this new architecture and about its core components.
So, let’s get started.
Recap of architecture in pre-12c database versions and its limitations
In Oracle Database, there are two macro categories of components – one at the hard disk level and another at RAM level. A hard drive contains nothing except stored files, and this is also the case for Oracle Database. There are various types of files that make an Oracle database function, for example data files, control files, online redo logs etc. Besides these files, a memory component exists on the operating system RAM which is a combination of several memory structures and various background processes. This memory portion works as a bridge between the user and the physical files that exist over the disk and is known as an instance.
Here is an illustration of the pre-12c architecture:
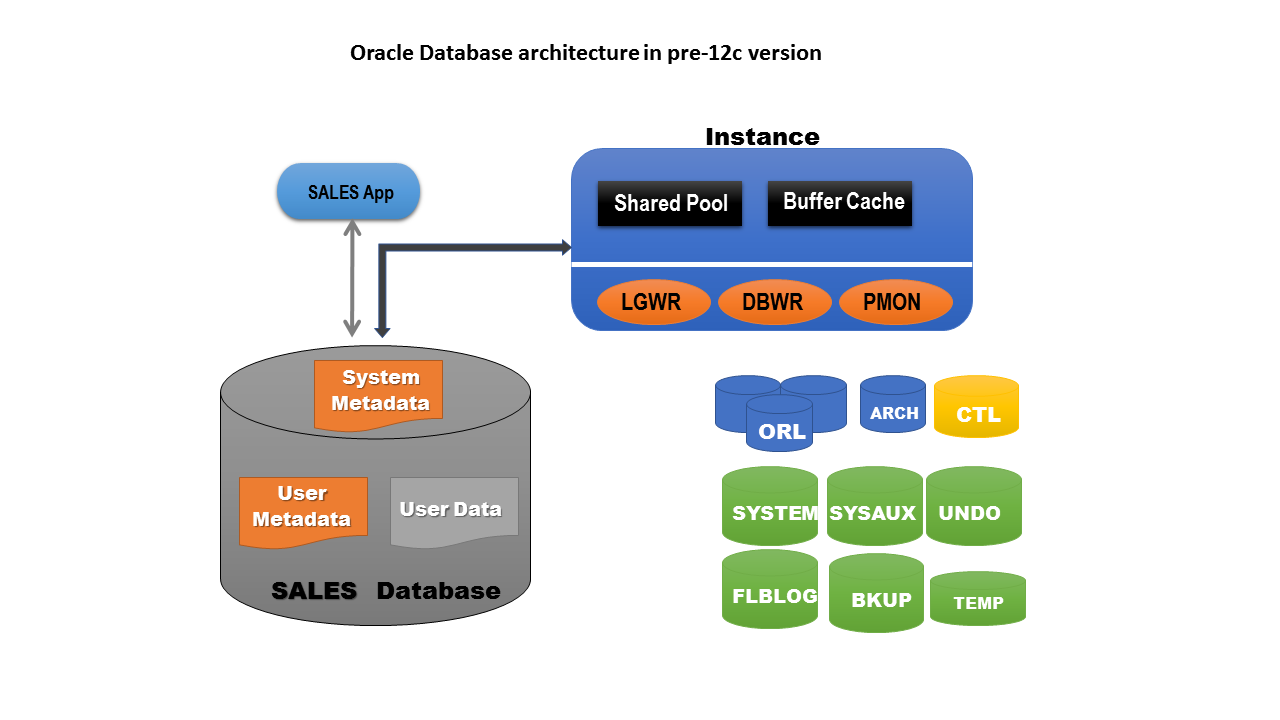
Of course, in a production system, there can’t just be one database. For example, we might have an HR database as well as our sales database. This illustration is now showing both of these databases:
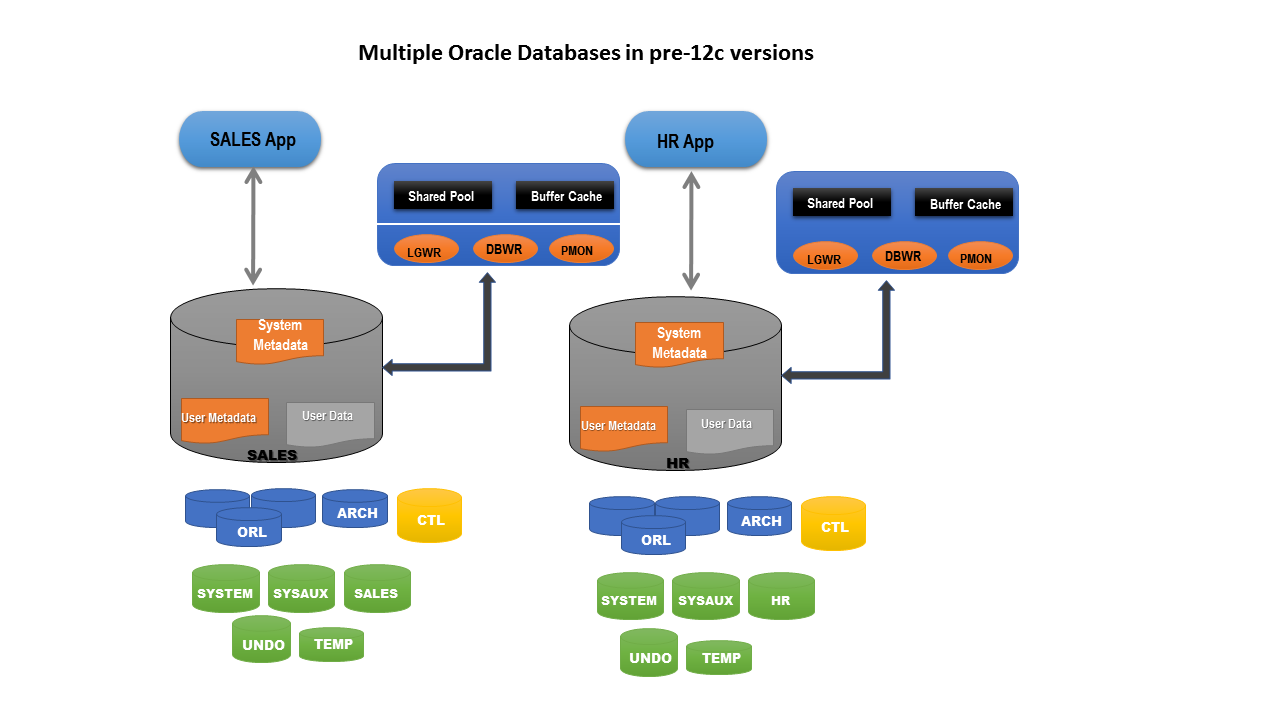
What we end up with is quite a few databases which are sitting on one server and are contending for its resources.
Each of these databases also has its own background processes, instances and system metadata repositories. Is this good? It is in a way, in that every database is an individual entity and whatever happens to it remains with it. This aspect makes it easier to administer such databases and the tasks of doing any administration or management becomes easier. But it also problematic. Each of however many databases that exist on the same server has to share its resources with every other database. Thus it’s very important to remove or reduce the impact of redundant components to free up more resources for the most important processes. Most of the components will be redundant, e.g. background processes like DBWR, LGWR etc.
Redundant structures and processes aren’t the only issues. Running a large number of databases makes housekeeping on them hard. Imagine that you have 50 databases of various versions and are required to get upgraded to 12c, apply patches, or both. How would you do it? It’s going to take a long time to run the same database upgrade and patch procedures repeatedly, increasing the time and effort on the DBA’s part.
Let’s look at an example. What if you were going for vacation, not far away, but with few close friends – and you decide to go by car. Would it be a good idea? Of course, as the cars provide privacy and comfort, and if you have an expensive car, a feeling of luxury as well. But if you think about it, by using multiple cars, you end up spending more per person, i.e. fuel costs, wear and tear, and potentially paying for multiple drivers as well. Exactly the same kind of scenario as having and managing more than one database in your data center!
That’s where 12c’s Multitenant features come into the picture – probably the biggest change in Oracle Database architecture since version 8i!
Getting Started with the New Multitenant Architecture
The issues that we have seen mentioned above are the result of many databases being created on an individual basis. Since each database is independent, it will always need resources for itself and will compete for those resources with the other databases. But how can we fix this? Before we get into the technical details, let’s pick up the same example that we discussed for the illustration of the non-multitenant databases – driving from place A to place B using cars. How about if we used a train instead? Rather than multiple engines getting wear and tear or requiring fuel in multiple cars, we can have just one engine pulling all the other compartments. Thus, by this consolidation, we now have a much better use of the same resources.
Since a picture is worth thousand words:

The concept of consolidation is now core in database architecture. Using this new architecture, multiple databases can be consolidated or to be more precise, plugged in, in a big container database and doing so reduces the requirement to create multiple instances, multiple data dictionaries and multiple background processes. Since a big container database holds multiple databases inside it, performing upgrade and patching tasks is made very simple. Upgrade or patch the container database and all underlying databases inside it are automatically upgraded and/or patched.
These plugged-in databases can also be very easily and quickly plugged-out and moved to another container database. This is very important in the case of an application vendor who hasn’t yet made support available for a particular patch or database version. Instead of keeping the rest of the databases from being upgraded, that one particular database can be plugged-out from the current container and be moved into another container database. This can be performed without the application needing any changes made or any kind of code management.
Sounds Good, but are these multi-tenant databases secure?
Security, privacy and resource control are probably the most important aspects for any database. Multitenant databases score fully on each of these fronts. Each database acts as a private silo and just like a non-multitenant database, access to any data is restricted to proper access rights granted by the owner or the administrators. Each pluggable database is managed by its own administrator or via the default account SYS . Also, once you are connected to one pluggable database, access to any other pluggable database, either in the same container or in another container database, isn’t possible. In order to connect to any pluggable database, proper privileges must be explicitly granted.
Just as we have Resource Manager available for managing resources in previous versions of the non-container databases, we have the same available for the new container databases in 12c. Resource management can be performed at a container database level as well as at the level of each pluggable database individually. This ability to manage resources at different levels allows an administrator to manage resources more efficiently.
The new architecture shouldn’t make DBAs feel that they are in an unknown territory – previous commands, views and structures are all still there. For example, there are still the similar level of the views available in the container databases- DBA/ALL/USER. But since there is now a container concept, so a new category of view is also available – CDB_*
This means we now have a DBA_USERS view showing us user information for the container we are connected to, and a new CDB_USERS view which will show details of the users belonging to either the current container or all the pluggable databases connected to that container. The new container databases can be still backed up and recovered using the traditional RMAN tool and are supported over RAC and Data Guard. As for managing them graphically, DBAs can use the Enterprise Manager Cloud Control (12c & 13c) or even SQLDeveloper besides the new, free tool, Enterprise Manager Express.
Core Components of a Multi-tenant Database
Though the new architecture is designed to make DBAs feel that they are working in a similar environment to pre-12c non-container databases, there is still a learning curve. There are few new components which we will look at in this section.
Before we describe each component, here is a (simplified) pictoral representation of a container database:
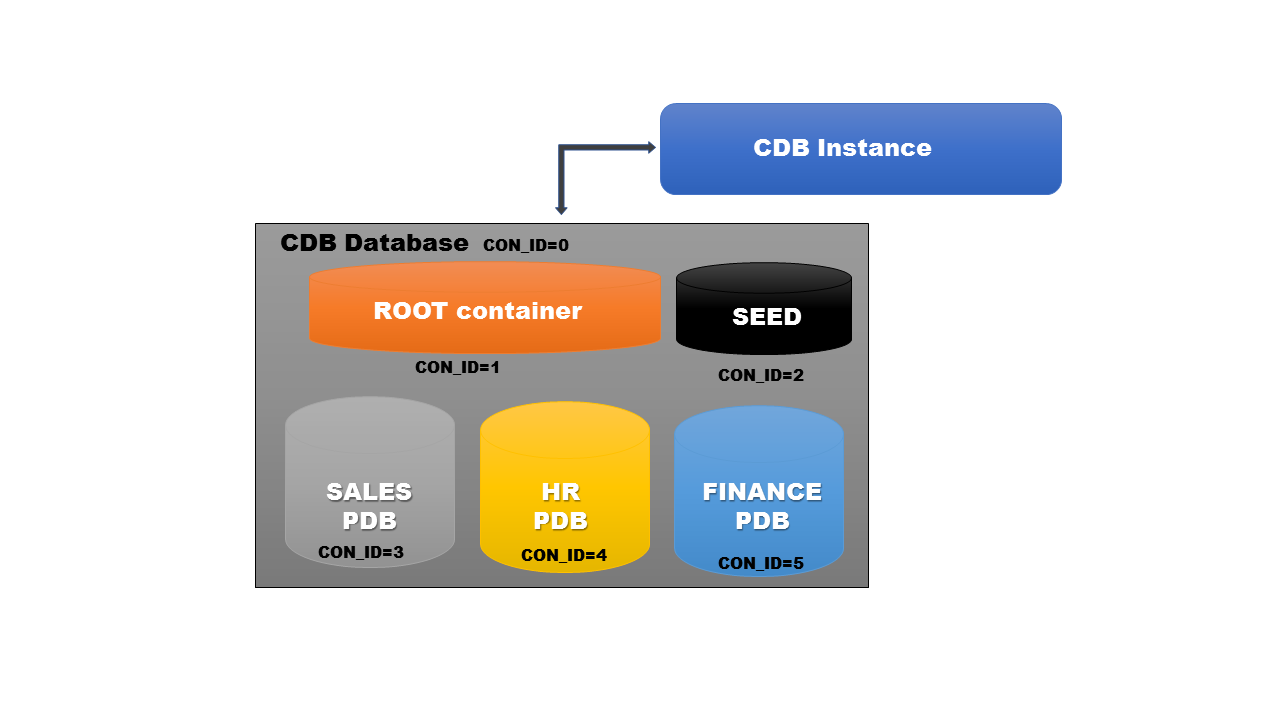
Now we’ll take a look at these components one-by-one.
CDB Instance
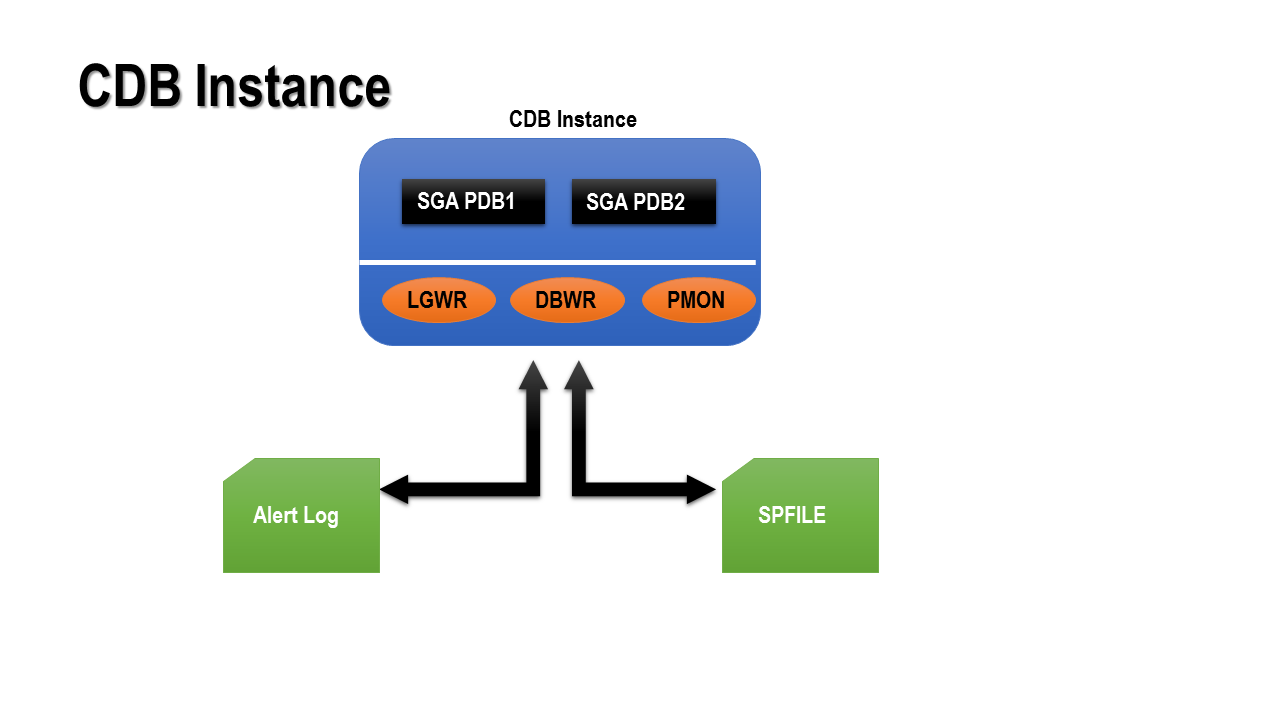
Multitentant Container Database (CDB) instances are similar to instances in a non-CDB (pre-12c) database. It’s owned by SYS user as in instances in previous versions of Oracle, but ownership is only allocated for the Container database as a whole. There is no separate instance for the underlying pluggable databases within that container database. It’s also maintained through the SPFile. The parameters can be modified from within the pluggable databases also but those parameters are recorded in an internal table – PDB_SPFILE$.
It’s important to note that any parameter(s) changed from a pluggable database won’t escalate to the container database nor will that modification impact any other pluggable databases.
Root Container
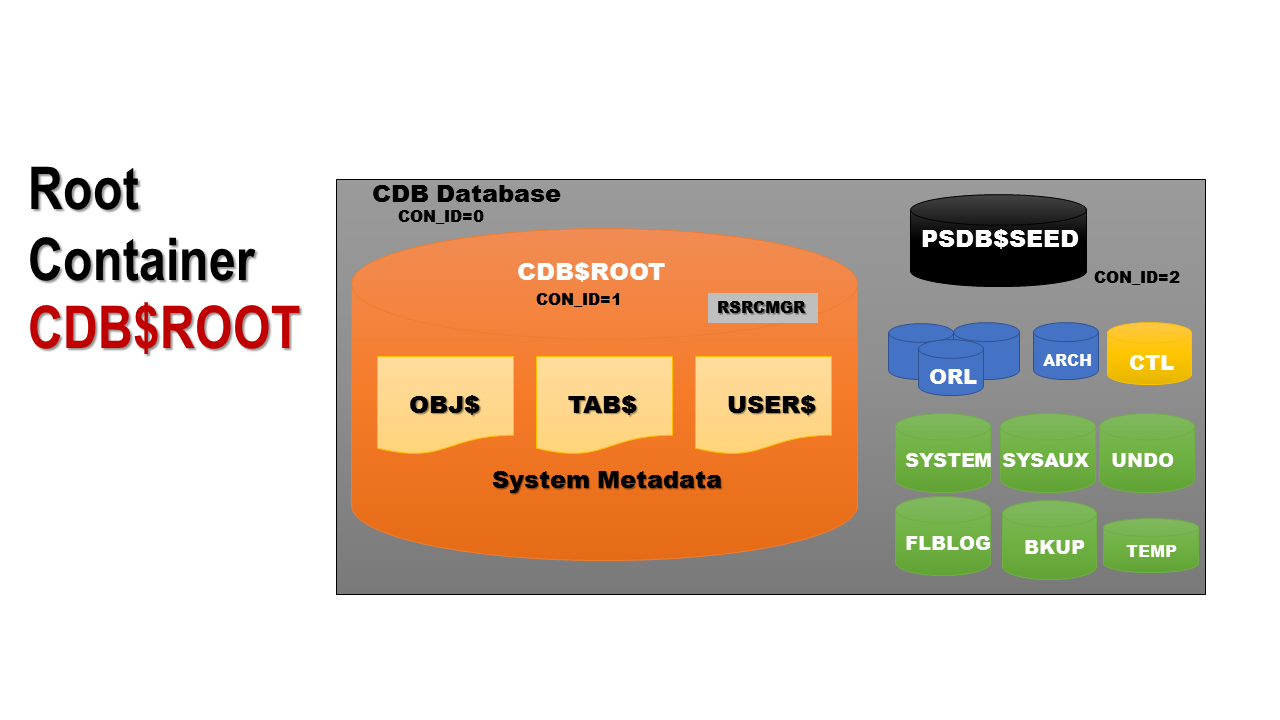
ROOT container is the very first container that’s created with a container database. It gets a default name – CDB$ROOT. As you can see from the illustration, it’s almost the same as databases in previous Oracle versions, and has the same basic contents – data files, control files, redo logs etc. If you look carefully, you’ll see it doesn’t contain any tablespace to store user-created data. And that’s the main difference between a Root container and the databases from previous versions. A ROOT container is only meant to store the system metadata, objects used by the databases internally and owners created by the database at the time of its creation i.e. SYS and SYSTEM. It also contains the information about all pluggable databases associated with it.
A Root container has a new type of user, Common users, within it. Common users are those which are avail-ble not just inside a Root container but also at all of the pluggable databases as well. Internally-created users are all common users and if you need to, you can explicitly create new common users as well.
Since the Root container is still a database, it can be backed up via standard tools like RMAN and Data Pump.
It’s worth mentioning that there is no technical restriction on creating any user-created objects inside the root container. And just like there is no restriction on creating an EMP table-alike table in the System or Sysaux tablespaces, just because it’s possible to do, you should never, ever, actually do it!
Seed Container

The Seed container is another default pluggable database that’s created at the same time as a container database. Like the Root container, the Seed container also gets a default name – PDB$SEED. It is used to create user-defined pluggable databases. For example, if you wanted to make a database for HR work, you would use this seed container and create a new pluggable database. Since the seed container is just meant to be used as a template for creating pluggable databases, it’s always in read-only mode, making any changes to its underlying objects impossible. Not only this, but a seed database also can’t be dropped. As with the Root container, the seed container can be backed up using oracle-supplied solutions like RMAN.
Pluggable Database (PDB)
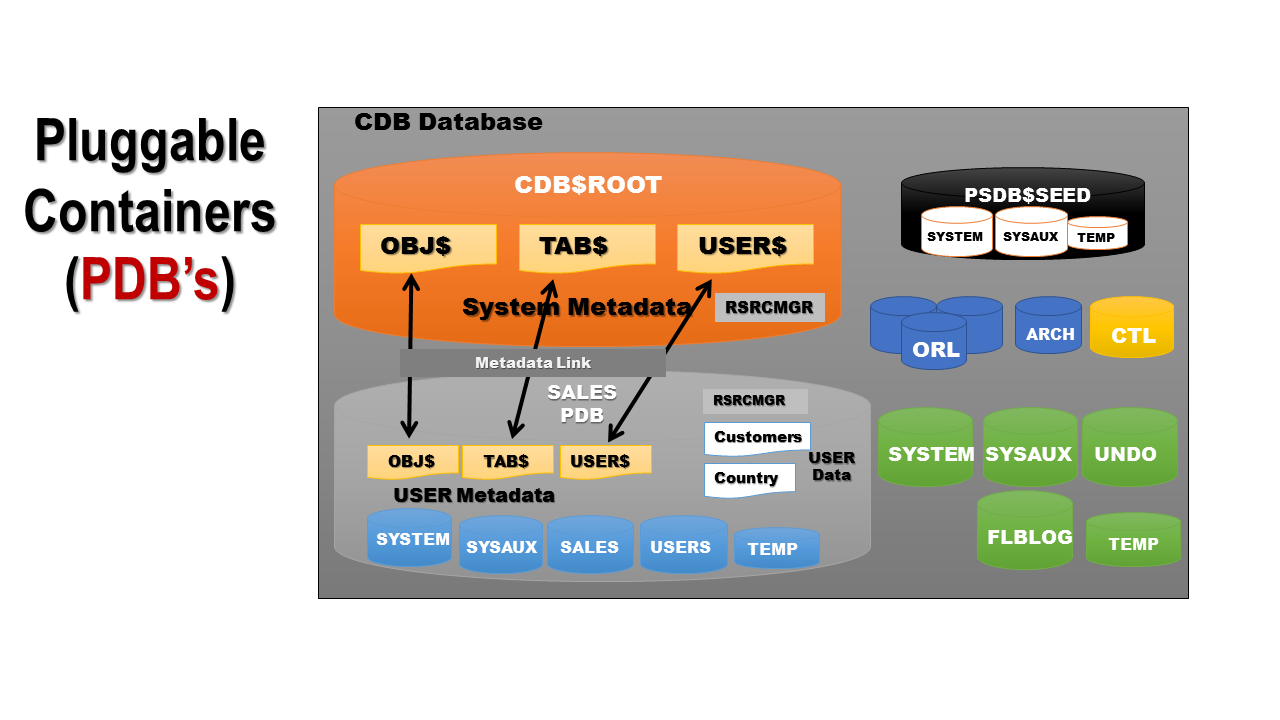
Pluggable containers are the databases which most DBAs are going to be interested in. The reason is that PDBs are user-created and will be used to hold the business related data as shown in the example above, where a Sales PDB is used to hold related objects. Unlike default containers like Root and Seed, PDBs are explicitly named by the DBA, which should be obvious since they are created on the basis of requirement by the business.
Each PDB holds user data, thus the data dictionary within it is used to hold the information for these objects. To keep the parent container database synched and updated with the object information of the underlying PDBs, the PDB-level data dictionary updates are synched using internal links. Each PDB is created via a service named after it within the database. As of version 12.1.0.2, the number of PDBs that can be held in a CDB is 253, including the one system-defined container, SEED$ROOT.
PDBs contain data that’s specific to them and are maintained by an administrator that’s set at the time of the creation of the PDB. As previously mentioned, a CDB contains Common users, whereas a PDB contains Local users, i.e. users that are confined only within that PDB itself. These PDBs act as data silos so if there is, for example, an HR PDB and a Sales PDB, just because both are in the same container that doesn’t mean the data in one can be accessed by the other without explicitly giving permission by the administrators of the PDBs or the object owners. To access data in another PDB, a database link must exist between the two.
Let’s complete the picture by putting it all together.
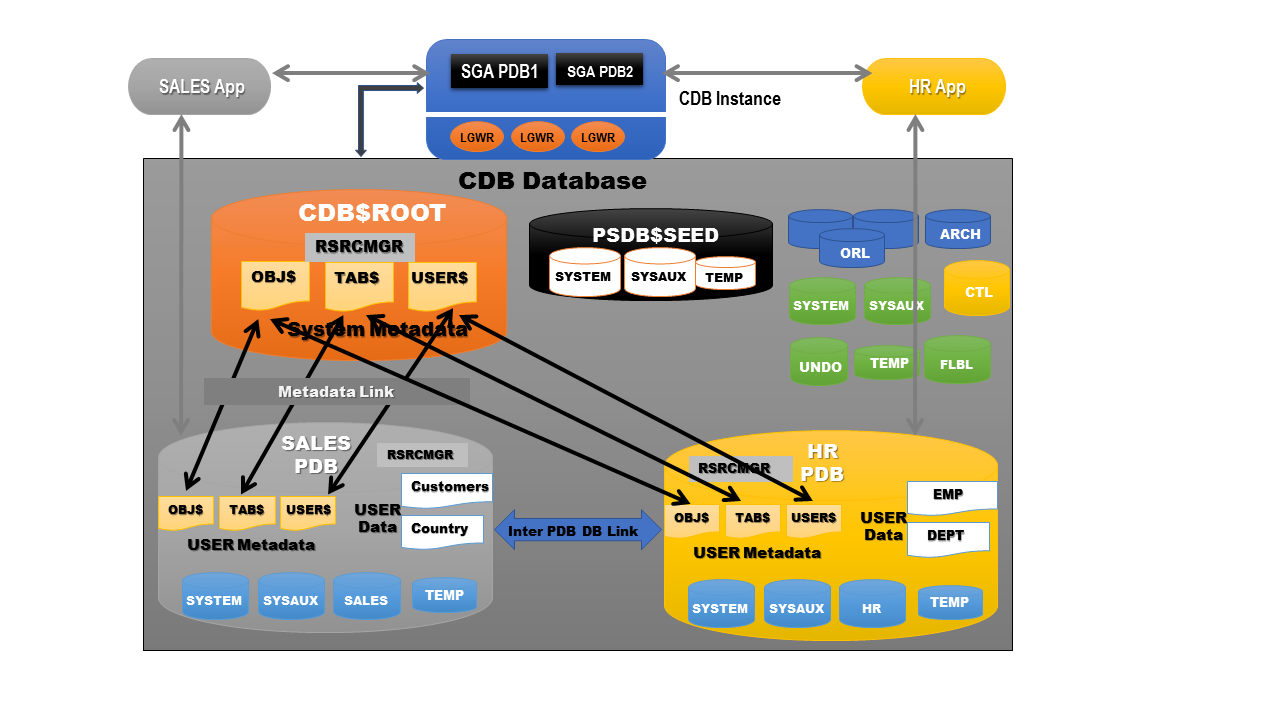
Know your pluggables – CON_ID & CON_NAME
Since there are many different types of containers now, it’s important to distinguish between them by some sort of identification and while working with them, it’s important to have a clear idea of which database you are connected to and working with. This requirement wasn’t there in previous versions because each database was an independent one. In a multitenant system this is solved by the introduction of two new functions – CON_ID and CON_NAME. The first function returns an ID number assigned to every database and the second one, as should be obvious, returns the name of the database.
The default containers which are created within a CDB and even the default parent container databases are assigned fixed numbers starting from 0 for the entire database, 1 for the Root container and 2 for the Seed pluggable database. Any pluggable databases created explicitly will always be assigned ID numbers higher than 2.
Let’s see it in action. We’ll make a connection to the database and confirm its ID and name.
|
1 2 3 4 5 6 7 8 |
SQL> conn / as sysdba Connected. SQL> select con_id, name 2 from v$database; CON_ID NAME ---------- --------- 0 ACDB |
We are connected to a 12.1.0.2 database and as we can see, from the view V$DATABASE, that ID=0 is assigned to the database and that the CON_ID column has been added to this view. CON_ID is added not just to this view, but to all database internal views.
Let’s execute the CON_ID and CON_NAME functions and see what they reveal.
|
1 2 3 4 5 6 7 8 9 10 |
SQL> show con_id CON_ID ------------------------------ 1 SQL> show con_name CON_NAME ------------------------------ CDB$ROOT |
As we already saw, Root is the owner of the database-level structures like log files, control files and data files, along with other internal objects which are required for the database to function. So when we have made a connection to the database using the traditional “/ as sysdba” option, in a multitenant structure this connects us to the Root container. We can see its name from the second function in our script.
Now, let’s connect to a pluggable database that we have manually created and compare the outcome of the same functions.
It’s worth mentioning that, before you can connect to any user defined pluggable, you must have an entry for it available in the TNSNAMES.ora file or the connection request will produce an error.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SQL> conn sys/oracle@apdb as sysdba Connected. SQL> show con_name CON_NAME ------------------------------ APDB SQL> show con_id CON_ID ------------------------------ 3 |
As we can see, the ID for this explicitly-created PDB (APDB) is greater than 2 (3 in this case). This will be the same for all subsequently-created PDBs.
There are several new views that are available in 12c, but two really important ones for the identification of pluggable and container databases – V$PDBS and V$Containers.
Just as we had DBA/ALL/USER views, we now have their CDB variations as well. The output of the CDB_* views depend on the container in which they are accessed. Let’s see an example – we’ll query two views, both showing information about the database users. We will execute the query first in Root and then in our own APDB pluggable database. Let’s see if there is any difference in the output.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
SQL> show con_name CON_NAME ------------------------------ CDB$ROOT SQL> select count(*) from dba_users; COUNT(*) ---------- 35 SQL> select count(*) from cdb_users; COUNT(*) ---------- 78 SQL> conn sys/oracle@apdb as sysdba Connected. SQL> select count(*) from dba_users; COUNT(*) ---------- 43 SQL> select count(*) from cdb_users; COUNT(*) ---------- 43 |
And we can see that there is indeed a difference. When we executed the query while connected to the Root, when we queried the CDB_USERS view, not only we could see the users from this container but also those from all underlying PDBs as well. And that explains the difference in the count from DBA_USERS. But when we executed the same query on the PDB the output was same as in our previous tests, since a PDB can’t see anything else except its own contents. This is a good demonstration of why it’s important to pay attention to the container you are connected to and to the category of view you are using.
Conclusion
Multitenant architecture is the biggest recent change to Oracle Database. There are many things to learn in this architecture, even for seasoned database administrators. This post should help in taking that first step into the new lands of containers and pluggables.
Load comments