
This article covers the parent/child structure, the library cache internals, the soft parse workflow in detail, and diagnostic queries against V$SQL and V$SQL_SHARED_CURSOR to identify cursor-sharing pathologies. This is Part 2 of the series; Part 1 (linked below) covers the broader query parsing workflow including hard parse vs soft parse.
In the first article of this series, we learned what query parsing is and what impact it has on query performance. In this part of the series, we shall continue the discussion and look at Soft Parsing of the query.
Click here for the full series.
Query Processing Workflow Revisited
As we saw in the previous installment, a query has to undergo Hard Parsing at least once. It’s important because only after hard parsing first occurs can we expect to find the cursor in memory. Once it’s in memory, the cursor can be reused for the execution of the query as shown below. This process of finding the cursor in the memory (Shared Pool) is called Soft Parsing.
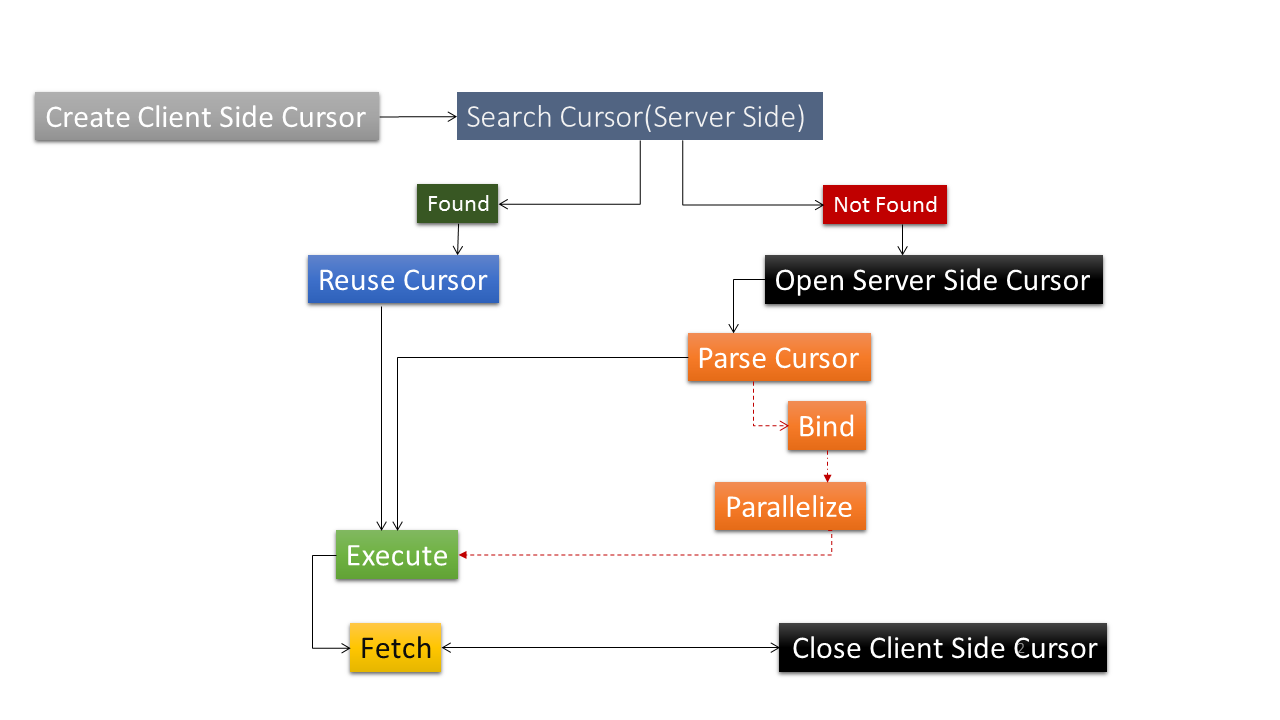
Soft Parsing
Soft parsing happens when the two subsequently-executed statements are deemed identical by the query optimizer. It’s important to note that the statements must not just be identical but shareable as well. Here is a simple example to demonstrate this. What we will do is to execute a very simple query, first in lower case and then in upper case. This is exactly same query, the only difference being the sentence case. Let’s see how Oracle treats it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DEPTNO DNAME LOC ---------- -------------- ------------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON SQL> SELECT * FROM SCOTT.DEPT; DEPTNO DNAME LOC ---------- -------------- ------------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON |
So as expected, the result is exactly the same (no surprise there). Oracle treats the queries as identical. But are they also shareable? Let’s find out by looking into two views: V$SQLAREA, V$SQL. This first result is from V$SQLAREA.
|
1 2 3 4 5 6 7 8 9 10 |
SQL> l 1 select sql_text, loaded_versions, plan_hash_value 2 from V$sqlarea 3* where sql_text like 'select * from scott%' or sql_text like 'SELECT * FROM SCOTT%' SQL> / SQL_TEXT LOADED_VERSIONS PLAN_HASH_VALUE -------------------------------------------------- --------------- --------------- SELECT * FROM SCOTT.DEPT 1 3383998547 select * from scott.dept 1 3383998547 |
Before we explain the output, let’s look at the V$SQL view as well.
|
1 2 3 4 5 6 7 8 9 |
SQL> select sql_id, sql_text, plan_hash_value, child_number 2 from v$sql 3 where sql_text like 'select * from scott%' or sql_text like 'SELECT * FROM SCOTT%' 4 / SQL_ID SQL_TEXT PLAN_HASH_VALUE CHILD_NUMBER ------------- -------------------------------------------------- --------------- ------------ 4db4txmchwqqh SELECT * FROM SCOTT.DEPT 3383998547 0 f6hhpzwv5jrna select * from scott.dept 3383998547 0 |
So what do we see here? It’s quite clear that both queries choose to use the same execution plan (they have the same PLAN_HASH_VALUE). This is understandable as both of them are supposed to only use full table scan, which we can see if we view the execution plan. But despite this similarity (both queries being identical), there are certain differences which mean that these two queries are not sharable. For example, you can see that both queries create two different SQL IDs. Also, both queries are loaded independently (LOADED_VERSIONS is 1 for both) and both have an individual “child cursor created” for them. So, despite the fact that the two statements were identical, Oracle didn’t consider them as sharable. Where this is the case, both of the statements are executed as standalone statements. As we discussed in the previous part of this series, this means both the queries would be Hard Parsed.
Enjoying this article? Subscribe to the Simple Talk newsletter
What is Hard Parsing?
When it’s not possible for a server process to find a matching cursor from the Shared Pool (Library Cache (LC) in particular), or if the cursor that’s present in the LC is not sharable, Oracle will decide that the cursor has to be created (or re-created). In other words, the statement needs to be compiled, and this mechanism is called Hard Parsing.
The decision between hard or soft parsing is based on whether, for a given statement, a matching parent and an executable and sharable Child cursor is found or not.
At this point, you must be wondering what the terms “parent/child cursor” mean. Good that you asked – it’s what we will be looking at next. But before we proceed, it’s important to know a little about the memory structure where these Parent and Child cursors reside – the Library Cache. So let’s look at Library Cache, from a distance.
A closer look at Library Cache
Before we can get to the discussion of the parent and child cursors, we must understand where they reside in the System Global Area (SGA). SGA is a cumulative term and contains numerous shared memory structures inside it, i.e. Data Buffer Cache, Shared Pool, Large Pool etc. Of these, probably the most important memory structure is the Shared Pool. Though SGA contains many sub-structures inside, one of the most important and most-used is the Library Cache.LC is the overarching structure which contains different types of objects inside it. The category of such objects is Namespace, and it’s exposed in the public view of V$LIBRARYCACHE’s NAMESPACE column. The following output is taken from an unpatched 12102 database running over EL 6.5.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SQL> select namespace from V$librarycache; NAMESPACE ---------------------------------------------------------------- SQL AREA TABLE/PROCEDURE BODY TRIGGER INDEX CLUSTER DIRECTORY QUEUE RULESET EDITION DBLINK OBJECT ID SCHEMA DBINSTANCE SQL AREA STATS SQL AREA BUILD PDB 17 rows selected. |
Of the above categories, the most highly-used is SQLAREA. Each category represents the objects which are loaded in the LC known as Library Objects (LO). LOs for the SQLAREA namespace are SQL statements which we upload when we execute a query.
Now Parent and Child cursors come into the picture.
Understanding Parent and Child Cursors
A query is represented in the library cache in the form of a shared cursor. This shared cursor is further categorized into two distinct types – Parent & Child cursors. Though both cursor types are important, it’s the child cursor in the library cache which governs the decision over whether a query will undergo a hard parse or a soft parse. If a query will undergo soft-parsing, then a matching child cursor for that query must be found – and not just found, the cursor must be identical and sharable. Of course, as we have seen in the example given above, the statement that we are currently executing is identical to the one we have executed before. But it might not be a sharable statement and if that’s the case, we have to reoptimize it. If in this case you are confused by the word “cursor”, it is the memory area that represents the statement.
A Parent cursor is essentially created for every query that’s uploaded in the LC You can say that this form of the cursor (or query) is like a wrapper or a template given to the statement. But just like a wrapper, it might not contain the same ingredients inside. The parent cursors are located in the LC using the Library Cache latch and the parent cursors are represented in the view V$SQLAREA. If we look at the example statement that we saw before, we have two separate or distinct Parent cursors in the LC. But a parent cursor has to execute as well. And that’s where the concept of Child Cursor comes into play.
A child cursor represents a particular form or type of parent cursor. In other words, a child cursor represents what will finally be executed. Since every child cursor must belong to a parent, thus every parent would execute with at least one child cursor created for it. Several forms of the parent cursor may exist in the Library Cache.
A simplified depiction of the LC and the parent and child cursors is given below:
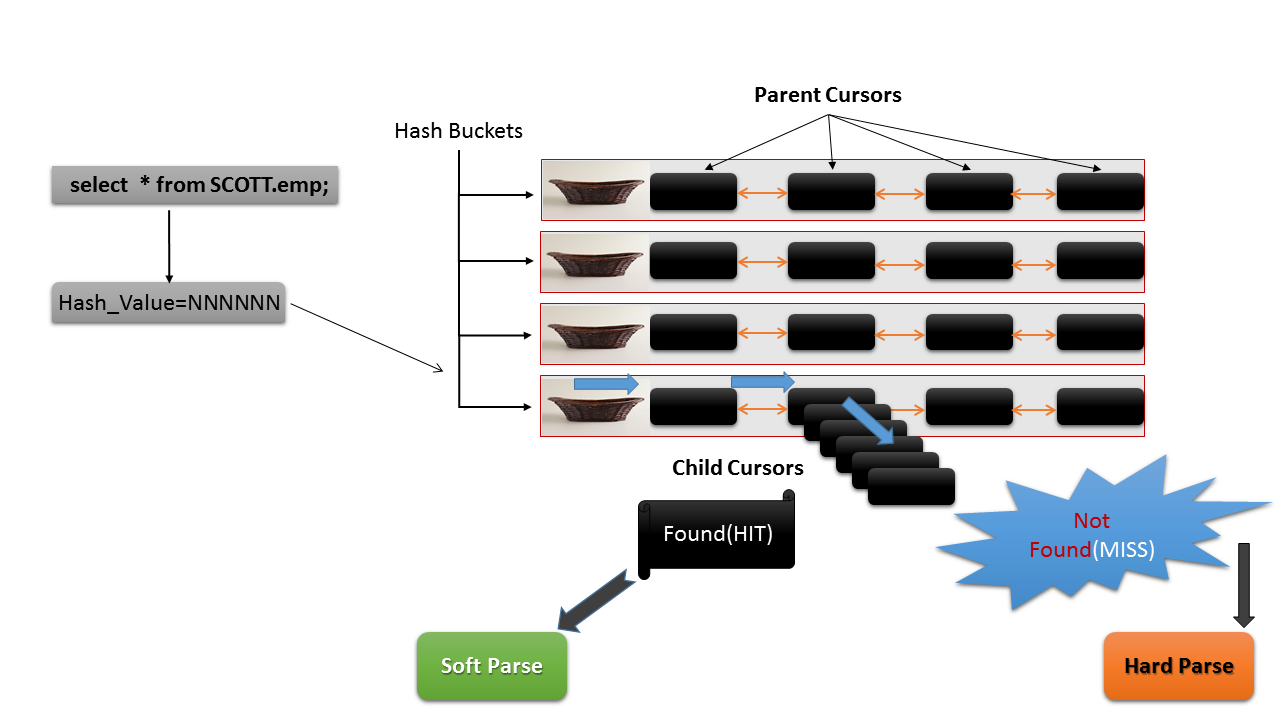
Let’s see an example of the situation where a query is will have a single parent cursor but the child cursors are not shared. For this example, we will alter the settings of the optimizer mode used in the execution of the query.
We start by flushing the Shared Pool and then move on to alter the OPTIMIZER_MODE parameter to FIRST_ROWS (the default value is ALL_ROWS).
|
1 2 3 4 5 6 7 8 9 10 11 |
SQL> alter system flush shared_pool; System altered. SQL> alter session set optimizer_mode=first_rows; Session altered. SQL> select * from t; DEPTNO DNAME LOC ---------- -------------- ------------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON |
Now, let’s alter the parameter again to a different mode.
|
1 2 3 4 5 6 7 8 9 |
SQL> alter session set optimizer_mode=choose; Session altered. SQL> select * from t; DEPTNO DNAME LOC ---------- -------------- ------------- 10 ACCOUNTING NEW YORK 20 RESEARCH DALLAS 30 SALES CHICAGO 40 OPERATIONS BOSTON |
So we have executed the same query twice now. Let’s check the parent cursor created for this query in the Library Cache:
|
1 2 3 4 5 6 |
SQL> select sql_id, sql_text, version_count, hash_value 2 from V$sqlarea where sql_text like 'select * from t' 3 / SQL_ID SQL_TEXT VERSION_COUNT HASH_VALUE ------------- ---------------- ------------- ---------- <strong>89km4qj1thh13 select * from t 2 1134051363</strong> |
So we can see that for this query there are two versions that are loaded in the memory. This shows that there are two distinct versions of the query available – these are the child cursors. Let’s see them now:
|
1 2 3 4 5 6 7 8 |
SQL> select sql_id, sql_text, hash_value, plan_hash_value, child_number CSR# 2 from V$sql 3 where sql_text like 'select * from t‘; SQL_ID SQL_TEXT HASH_VALUE PLAN_HASH_VALUE CSR# ------------- ------------ ---------- ----------------- --------------------------- ------- <strong>89km4qj1thh13 select * from t 1134051363 1601196873 0</strong> <strong>89km4qj1thh13 select * from t 1134051363 1601196873 1</strong> |
As expected, we see that two child cursors have been created. Both statements are completely identical as we have already seen. So why are these statements not be shared? Instead of the statement being considered for Soft Parsing, why did the database engine decide to treat the second statement as a newly-created one? The answer lies in the V$SQL_SHARED_CURSOR view. This view is very useful as it literally contains the reasons why the optimizer decided to mark the newly-created cursor as an unshared one. For the given example, we know it’s the optimizer mode’s mismatch. But in the real world, it won’t be this straightforward to find out the reason why the cursors couldn’t be shared. To find out, you need to query the V$SQL_SHARED_CURSOR view. Here is an output of this view for the above statement:
|
1 2 3 4 5 6 7 8 |
SQL> select s.sql_text, s.child_number, s.child_address, c.OPTIMIZER_MODE_MISMATCH from v $sql s, v$sql_shared_cursor c where s.sql_text like 'select * from t' and s.child_address = c.child_address; SQL_TEXT CHILD_NUMBER CHILD_ADDRESS O ------------------------- ----------------------- ---------------- ------ select * from t 0 00000000815A8728 N select * from t 1 00000000815600A0 Y |
It’s clearly visible here that the optimizer mismatch was the reason for the new child cursor being created.
Brief Summary
Oracle’s library cache uses a two-level structure to share SQL execution plans: parent cursors (one per textually-unique SQL statement) and child cursors (one or more per parent, representing plan variants appropriate to different execution contexts).
When a SQL statement is submitted, Oracle hashes the text and looks up the parent cursor; if found, it checks the parent’s child cursors for one whose execution context (bind variable types, NLS settings, optimizer environment, etc.) matches the current session.
If a matching child exists, soft parse reuses that child’s plan. If no matching child exists (the statement text is the same but the context differs enough to require a different plan), Oracle hard parses and creates a new child under the same parent.
The parent/child model optimizes for the common case (same SQL, same context, reuse plan) while handling the exception cases (same SQL, different context, use a different compatible plan). Excessive child cursors per parent (high ‘version count’) indicate a problem: something about each execution forces a new plan variant, defeating the sharing model.
Common causes of this are: per-session NLS_LANG differences, different bind variable types for the same parameter position, adaptive cursor sharing variants, OPTIMIZER_MODE hints varying per session.
Simple Talk is brought to you by Redgate Software
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments