
![]()
Nonclustered
Index Spool
Indexes, Indexes, Indexes… To misquote a certain prominent Microsoft employee. Indexing is a key issue when we are talking about databases and general performance problems, and so it’s time to feature the NonClustered Index Spool in my SQL Server ShowPlan operator series. If you missed the last article about the Lazy Spool, it’s actually very important that you read that before you get too deeply into this next article. If you’re just getting started with my Showplan series, you can find a list of all my articles here.
The Index Spool is used to improve the read performance of a table which is not indexed and, as with other types of Spool operators, it can be used in a “Lazy” or an “Eager” manner. So, when SQL Server needs to read a table that is not indexed, it can choose to create a “temporary index” using the Spool, which can result in a huge performance improvement in your queries. To get started with understanding Index Spool, we’ll use the usual table, called Pedidos (which means “Orders” in Portuguese). The following script will create a table and populate it with some garbage data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
USE tempdb GO IF OBJECT_ID('Pedido') IS NOT NULL DROP TABLE Pedido GO CREATE TABLE Pedido (ID INT IDENTITY(1,1), Cliente INT NOT NULL, Vendedor VARCHAR(30) NOT NULL, Quantidade SmallInt NOT NULL, Valor Numeric(18,2) NOT NULL, Data DATETIME NOT NULL) GO CREATE CLUSTERED INDEX ix ON Pedido(ID) GO DECLARE @I SmallInt SET @I = 0 WHILE @I < 50 BEGIN INSERT INTO Pedido(Cliente, Vendedor, Quantidade, Valor, Data) SELECT ABS(CheckSUM(NEWID()) / 100000000), 'Fabiano', ABS(CheckSUM(NEWID()) / 10000000), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))), GETDATE() - (CheckSUM(NEWID()) / 1000000) INSERT INTO Pedido(Cliente, Vendedor, Quantidade, Valor, Data) SELECT ABS(CheckSUM(NEWID()) / 100000000), 'Amorim', ABS(CheckSUM(NEWID()) / 10000000), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))), GETDATE() - (CheckSUM(NEWID()) / 1000000) INSERT INTO Pedido(Cliente, Vendedor, Quantidade, Valor, Data) SELECT ABS(CheckSUM(NEWID()) / 100000000), 'Coragem', ABS(CheckSUM(NEWID()) / 10000000), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))), GETDATE() - (CheckSUM(NEWID()) / 1000000) SET @I = @I + 1 END SET @I = 0 WHILE @I < 2 BEGIN INSERT INTO Pedido(Cliente, Vendedor, Quantidade, Valor, Data) SELECT Cliente, Vendedor, Quantidade, Valor, Data FROM Pedido SET @I = @I + 1 END GO SELECT * FROM Pedido Ped1 WHERE Ped1.Valor > ( SELECT AVG(Ped2.Valor) FROM Pedido AS Ped2 WHERE Ped2.Data < Ped1.Data) |
This is what the data looks like in SSMS:
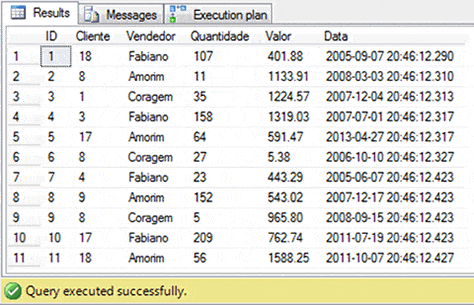
Figure 1. The Pedidos demonstration table and data.
To help us understand the Index Spool, I’ve written a query that returns all orders with a sale value higher than the average, as compared to all sales before the date of the order in question:
|
1 2 3 4 5 6 |
SELECT * FROM Pedido Ped1 WHERE Ped1.Valor > ( SELECT AVG(Ped2.Valor) FROM Pedido AS Ped2 WHERE Ped2.Data < Ped1.Data) |
Before we see the execution plan, let’s make sure we understand the query a little better. The SubQuery returns the average value of all sales (AVG(Ped2.Valor)) dated before the order we’re comparing them to. After that, the average is compared with the principal query, which determines whether the sale value in question is actually bigger than the average. If you’ve read last week’s article, you’ll see that this query has a very similar form to my previous demonstration. So, now we’ve got the following execution plan:
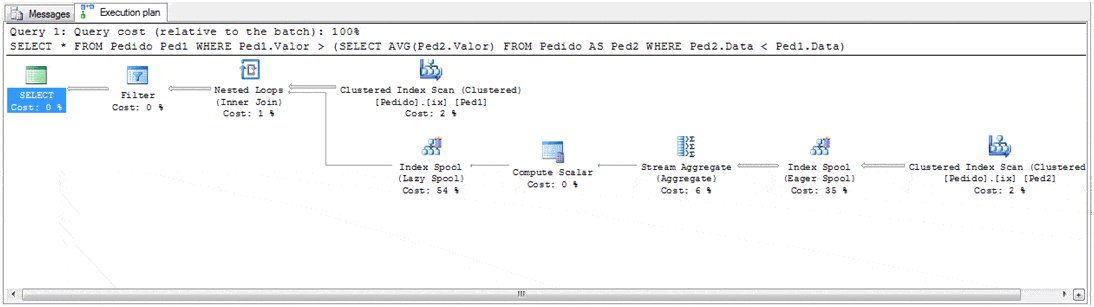
Figure 2. The graphical execution plan of the Index Spool demonstration query (click on the image for an enlarged view).
|
1 2 3 4 5 6 7 8 |
|--Filter(WHERE:([Pedido].[Valor] as [Ped1].[Valor]>[Expr1004])) |--Nested Loops(Inner Join, OUTER REFERENCES:([Ped1].[Data])) |--Clustered Index Scan(OBJECT:([Pedido].[PK_Pedido] AS [Ped1])) |--Index Spool(SEEK:([Ped1].[Data]=[Pedido].[Data] as [Ped1].[Data])) |--Compute Scalar(DEFINE:([Expr1004]=CASE WHEN [Expr1011]=(0) THEN NULL ELSE [Expr1012]/CONVERT_IMPLICIT(numeric(19,0),[Expr1011],0) END)) |--Stream Aggregate(DEFINE:([Expr1011]=Count(*), [Expr1012]=SUM([Pedido].[Valor] as [Ped2].[Valor]))) |--Index Spool(SEEK:([Ped2].[Data] < [Pedido].[Data] as [Ped1].[Data])) |--Clustered Index Scan(OBJECT:([Pedido].[PK_Pedido] AS [Ped2])) |
This is a very interesting plan, and, as we can see, the Optimizer chose to use two Index Spool operators; one working as an Eager and the other as a Lazy spool. We can also see that, after the Nested Loops, SQL Server uses the Filter operator to select just the rows that satisfy the WHERE condition (WHERE PEd1.Valor > …).
This execution plan is actually simpler than it looks; first, the Clustered Index Scan reads the rows in the Pedidos table, returning the Data and Valor (Date and Value) columns to the Eager Index Spool. With these rows, the Optimizer uses the Index Spool to create a temporary non-clustered index on Data and Valor, and as it is an Eager spool, it will read all the rows from the clustered scan to create the index.
Quick Tip:
If you create an index on the Pedidos table covering Data and Valor, you will optimizer the query because the operator Index Spool (Eager) will not be necessary.
After that, the optimizer will calculate the average value of the sales, using the following rule: For each row of Ped1, the optimizer computes the average of any orders where the Ped2.Data is lower than Ped1.Data (i.e. the average of any orders which have a date earlier than the order in the given row of Ped1). To do this, SQL Server uses the Stream Aggregate and the Compute Scalar operators, in a manner similar to what was discussed last week.
I’ll explain the Index Spool (lazy) in just a moment, but for now I’ll just say that it optimizes the Nested Loops join, which is joining the average calculated by the sub-query to the Ped1.Data column, and the result, as I mentioned, is then filtered to complete the query.
Now, let’s look at what makes the Index Spool (lazy) operator special. When SQL Server needs to read a value that it knows is repeated many times, then it can use a Spool to avoid having to do the same work each time it needs to find that value. For instance, suppose that the date column has a high density (i.e. it contains a lot of duplicated values); this will mean that SQL Server will have to do the same calculation more than once, since the Nested Loops operator will process the join row by row. However, If the value passed as a condition to the join is equal to a value that has already been calculated, you clearly shouldn’t need to recalculate the same result each time. So how can we reuse the value that has already been found?
This is exactly what the Nonclustered Index Spool operator (lazy), is designed to do: optimize the process of the Join. It is optimized to predict precisely the case that I’ve described above, so that a value that has already been calculated will not be recalculated, but instead read from the index, which is cached (TempDB). So, from the point of view of the Spool, it is very important to know if the required value still needs to be calculated(rebind), or has already been calculated (rewind). Now that this simple example has illustrated that point, it’s time to dive a little deeper.
Understanding Rebind and Rewind
First of all you need understand that all types of Spool operators use temporary storage to cache the values used in the execution plan, although this temporary storage is truncated for each new read of the operator. This means that, if I use a Lazy Spool to calculate an aggregation and keep this calculated value in cache, I can use this cached data in many parts of the plan, and potentially work with just single chunk of data in all the plan’s steps. However, to do this, we need reset the cache for each newly calculated value , otherwise by the end of the plan we’ll be working with the whole table! Thus, for a spool, it is very important to distinguish between executions need the same value (rewinds) and executions needing an different / new value (rebinds).
A rewind is defined as an execution using the same value as the immediately preceding execution, whereas a rebind is defined as an execution using a different value. I know this is a little confusing to understand for the first time, so I’ll try and explain it step by step, with some code and practical examples.
Rebind and Rewinds with Table Spool (Lazy Spool)
To understand a little more about Rebind and Rewind, let’s suppose our Pedido table has some rows in the Data (Date) column in the following order: “19831203”, “19831203”, “20102206” and “19831203”. A representation of Rewind and Rebind in a table spool operator would be something like this:
- Value = “19831203”. A rebind occurs, since is the first time the operator is called.
- Value = “19831203”. A rewind occurs since this value was already read, and is in the spool cache.
- Value = “20102206”. The value changes, so the cache is truncated and a rebind occurs, since is the value “20102206” is not in the cache.
- Value = “19831203”. A rebind occurs again, since the actual value in cache is “20100226”, and the value that was read in step 1 was truncated in the step 3.
So our final numbers are three rebinds (steps 1, 3 and 4) and just one rewind (step 2). To show this in a practice, I’ve written a script to repopulate the table Pedido with four rows, exactly as I’ve mentioned above.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
USE tempdb GO TRUNCATE TABLE Pedido GO SET IDENTITY_INSERT Pedido ON INSERT INTO Pedido(ID, Cliente, Vendedor, Quantidade, Valor, Data) SELECT 1, ABS(CheckSUM(NEWID()) / 100000000), 'Fabiano', ABS(CheckSUM(NEWID()) / 10000000), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))), '19831203' INSERT INTO Pedido(ID, Cliente, Vendedor, Quantidade, Valor, Data) SELECT 2, ABS(CheckSUM(NEWID()) / 100000000), 'Fabiano', ABS(CheckSUM(NEWID()) / 10000000), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))), '19831203' INSERT INTO Pedido(ID, Cliente, Vendedor, Quantidade, Valor, Data) SELECT 3, ABS(CheckSUM(NEWID()) / 100000000), 'Fabiano', ABS(CheckSUM(NEWID()) / 10000000), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))), '20100622' INSERT INTO Pedido(ID, Cliente, Vendedor, Quantidade, Valor, Data) SELECT 4, ABS(CheckSUM(NEWID()) / 100000000), 'Fabiano', ABS(CheckSUM(NEWID()) / 10000000), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))), '19831203' SET IDENTITY_INSERT Pedido OFF GO |
This is what the data looks like in SSMS:
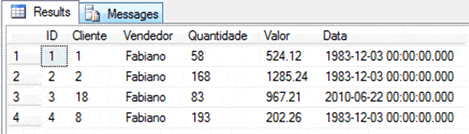
Figure 3. The second Pedidos demonstration table and data.
To illustrate the Rebind and Rewind using the Table Spool operator (which we already understand), I’ve written a query using the USE PLAN hint, to force a plan that uses the Table Spool operator. I’ll omit part of the code for brevity, but you can download the query here. Note that the following query only runs in the tempdb database, because the XML plan is using this database.
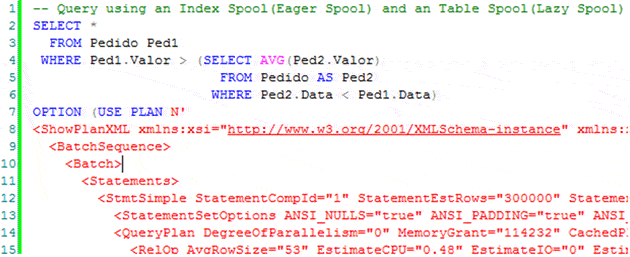
Figure 4. A query to demonstrate Rewinds and Rebinds.
For query above, we have the following execution plan:

Figure 5. The Graphical execution plan demonstrating rewinds and rebinds (click on the image for an enlarged view)
Note that the plan above is using a Table Spool (Lazy Spool) to perform the query; for each row read in the Pedido (Ped1) table, SQL Server will call the table Spool to run the SubQuery. Let’s look at the rebind and rewind properties to see how many times SQL Server executes each task.
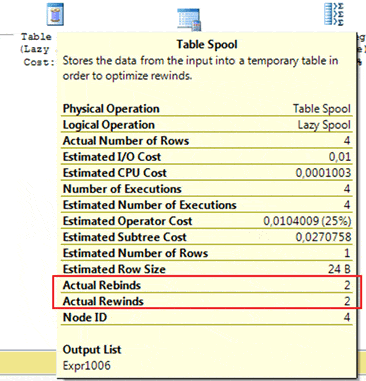
Figure 6. The rebinds and rewinds performed by the Table Spool operator.
“Hey, wait a minute Fabiano,” – I hear you exclaim – “Didn’t you said that we have three rebinds and one rewind? Why SQL is showing different values?“
Sharp-eyed as ever, dear reader. Pay attention, now; do you notice that I marked the Sort operator with a green square? We should be asking ourselves what this is doing.
As I said earlier, to SQL Server, it is very important to distinguish between executions using the same value and executions using different values. That means that if SQL Server reads the Pedido table and Sorts the values by Date, it will increase the chance of a rewind occurring, because the order of rows will go from:
- 19831203
- 19831203
- 20102206
- 19831203
to
- 19831203
- 19831203
- 19831203
- 20102206
That’s why SQL Server only makes two rebinds and two rewinds. Pretty smart, huh?
Rebind and Rewinds with Index Spool (Lazy Spool)
Now let’s see how the Index Spool works. Remember, index spool doesn’t truncate its cache, even if a Rebind occurs; instead it maintains a temporary index with all “rebound” rows. So a representation of Rewind and Rebind in an index spool operator would be something like this:
- Value = “19831203”. A rebind occurs, as this is the first time the operator is called.
- Value = “19831203”. A rewind occurs, as this value was already read, and is in the spool cache.
- Value = “20102206”. A rebind occurs, as the value “20102206” is not in the cache.
- Value = “19831203”. A rewind occurs, as this value was read in step 1, and is still in the temporary index.
So our final numbers are two rebinds (steps 1 and 3) and just two rewinds (step 2 and 4). The same numbers used in the plan above with the table spool operator.
To illustrate Rebind and Rewind using the Index Spool operator, I’ve written a second query using the USE PLAN hint to force a plan that uses the Index Spool operator. As before, I’ll omit part of the code for the sake of brevity, but you can download the query here.
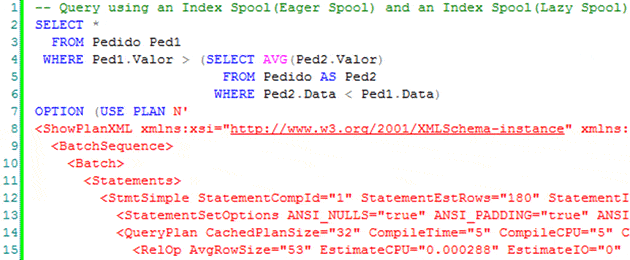
Figure 7. A SQL query to demonstrate rewinding and rebinding with the index spool operator.
To query above we have the following execution plan:
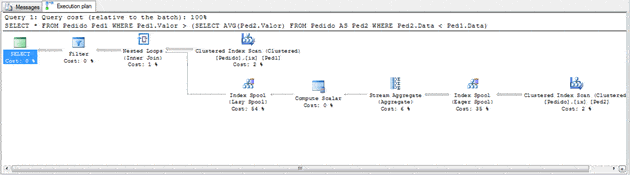
Figure 8. The execution plan generated in response to the query in Figure 7 (click on the image for an enlarged view).
Note that, as intended, the plan above is using an Index Spool (Lazy Spool) to perform the query. For each row read in the Pedido (Ped1) table, SQL Server will call the Index Spool to run the SubQuery. Let’s look at the Spool’s rebind and rewind properties to see how many times SQL Server executes each task.
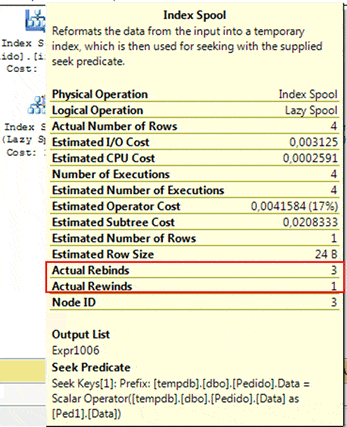
Figure 9. The number of rebinds and rewinds performed by the Index Spool.
Maybe you are wondering, “Once again, Fabiano – your prediction is different from the real values. Could you explain that please? Why is operator’s properties showing three rebinds and one rewind, when you expected two rebinds and two rewinds?“
Well, this time it’s because our Microsoft friends like to confuse us. That’s right, my count is correct, and the displayed properties are actually wrong. To quote from “Inside Microsoft SQL Server 2005 Query Tuning and Optimization“, this is what Craig Freedman wrote about this situation:
“Note that rewinds and rebinds are counted the same way for index and nonindex spools. As described previously, a reexecution is counted as a rewind only if the correlated parameter(s) remain the same as the immediately prior execution, and is counted as a rebind if the correlated parameter(s) change from the prior execution. This is true even for reexecutions, in which the same correlated parameter(s) were encountered in an earlier, though not the immediately prior, execution. However, since lazy index spools, like the one in this example, retain results for all prior executions and all previously encountered correlated parameter values, the spool may treat some reported rebinds as rewinds. In other words, by failing to account for correlated parameter(s) that were seen prior to the most recent execution, the query plan statistics may overreport the number of rebinds for an index spool.“
Summary
Generally, if you see a spool operator in your plan, you should take a closer look, because it can probably be optimized if you create the indexes properly. Doing this avoids the need for recalculations, prevents the query optimizer from having to create the indexes for you, and your query will perform better.
In my next article, we will talk about the last spool operator, the RowCount Spool. That’s all for now folks; I’ll see you next week with more “Showplan Operators”.
If you missed the last thrilling Showplan Operator, Lazy Spool, you can see it here.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments