
I. Introduction
Data Quality is imperative to the success of any Business Intelligence solution. In today’s era, where the data is being ingested from multiple sources, the quality of the data might differ between sources. The first step to a successful reporting application implementation is to ensure that only the highest quality data makes it to the reporting tables. In order to achieve this, a Data Quality Monitoring framework should be implemented.
Some of the characteristics of the Data Quality Framework are as follows:
- The Data Quality Monitoring framework should have a predefined set of rules specific to a Data Domain.
- The Data Quality Monitoring framework should be scalable, i.e., it should support the addition of new rules and should be able to support data quality monitoring across multiple data domains.
- The Data Quality Monitoring framework should have the ability to enable and disable rules to be executed against the data.
- All the results from Data Quality monitoring should be stored in a rules results repository.
II. Data Quality Monitoring Framework Process Flow
The process starts with the source data file(s) landing on the SQL Server or any ETL Server. Once files are detected, the Pre-Stage Data Quality rules are executed. Data Stewards receive a notification once Pre-Stage rules are executed, and results are available for data stewards for review. The processing stops if any of the Pre-Stage “Gating” Data Quality rules have failed. The process continues to load data into Stage table only if none of the Pre-Stage Gating rules has failed or if the Data Steward has chosen to override the failure. The process then loads data into Stage Table. After this, the post-stage Data Quality Rules are executed, and Data Stewards are notified when the results are available for review. If there is NO Gating rules failure, then the process automatically publishes a validated data file for the downstream systems to use. If any of the post-stage Gating rules have failed, then the Data Steward could decide to either abandon the cycle and request a new file from source or override the failure in order to publish data files for downstream systems.
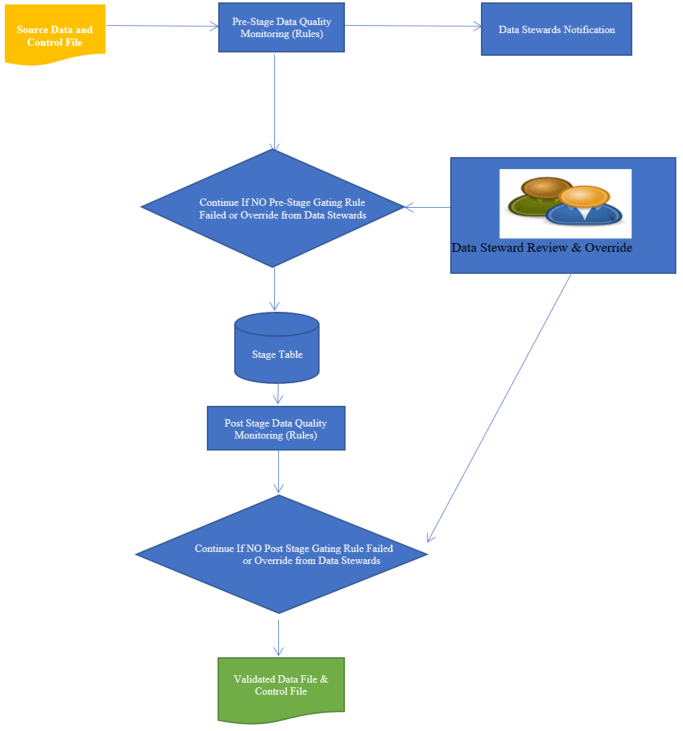
Figure 1: Process Flow Diagram for Data Quality Monitoring Framework. Data
The following section of the article will concentrate on the Implementation of Data Quality Rules (Pre-Stage & Post Stage) using Database tables.
III. Data Quality Monitoring Data Mart:
To implement Data Quality Monitoring Framework, a Data Quality Data Mart is needed.
A Data Quality Data Mart would have tables to provide the following capabilities.
- A table to store all predefined Data Quality rules. (DATA_QUALITY_RULE table)
- A table to provide the ability to turn on and turn off rules and store threshold percentages for each rule for its corresponding data domain (DATA_QUALITY_RULE_EXECUTE table).
- A table to store the results of Data Quality Rules to serve as a Data Quality Rule Monitoring results repository (DATA_QUALITY_RULE_RESULTS).
A possible model would look like Figure 2
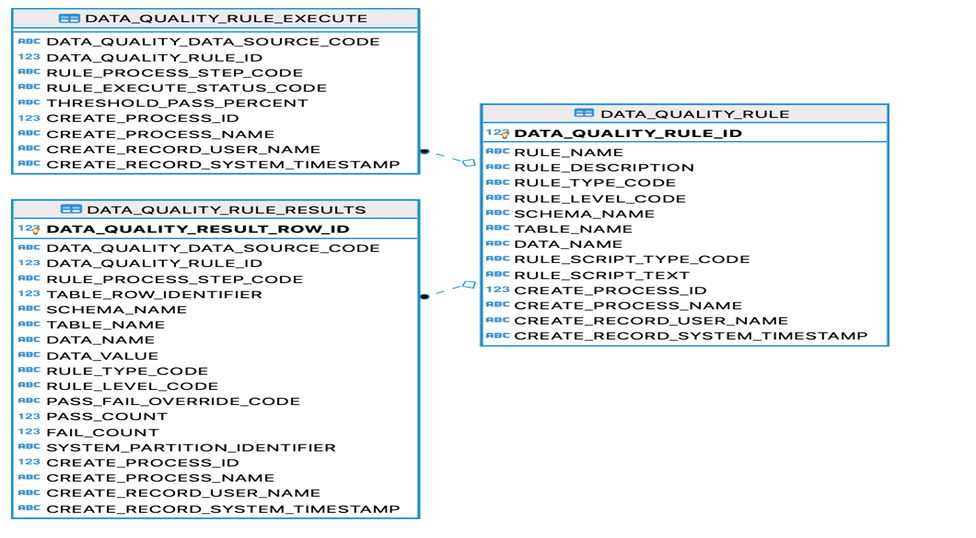
Figure 2: The data quality model
Here are the definitions for the three tables.
A. DATA_QUALITY_RULE Table
This table holds all the predefined Data Quality Rules. These rules could be for one data domain or multiple data domains.
DDL for creating the DATA_QUALITY_RULE table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE TABLE DATA_QUALITY_RULE ( DATA_QUALITY_RULE_ID INTEGER NOT NULL, RULE_NAME VARCHAR(60) NOT NULL, RULE_DESCRIPTION VARCHAR(256) NOT NULL, RULE_TYPE_CODE VARCHAR(20) NOT NULL, RULE_LEVEL_CODE VARCHAR(20) NOT NULL, SCHEMA_NAME VARCHAR(60), TABLE_NAME VARCHAR(60), DATA_NAME VARCHAR(60), RULE_SCRIPT_TYPE_CODE VARCHAR(20), RULE_SCRIPT_TEXT VARCHAR(256), CREATE_PROCESS_ID BIGINT NOT NULL, CREATE_PROCESS_NAME VARCHAR(35) NOT NULL, CREATE_RECORD_USER_NAME VARCHAR(35) NOT NULL, CREATE_RECORD_SYSTEM_TIMESTAMP DATETIME NOT NULL, CONSTRAINT [PK_DATA_QUALITY_RULE_ID] PRIMARY KEY ([DATA_QUALITY_RULE_ID]) ); |
|
Column Name |
Column Details |
|
DATA_QUALITY_RULE_ID |
Unique Rule Identifier |
|
RULE_NAME |
Name of the Rule |
|
RULE_DESCRIPTION |
Details about the Rule |
|
RULE_TYPE_CODE |
Describes if Rule is “GATING” or “PASSIVE” |
|
RULE_LEVEL_CODE |
Level at which rule is executed at file or table or column level. |
|
SCHEMA_NAME |
Schema of the Table or Schema of File. |
|
TABLE_NAME |
Table that holds the data on which Data Quality Rules need to execute. |
|
DATA_NAME |
Column Name on which rule is executed |
|
RULE_SCRIPT_TYPE_CODE |
Code for Detecting if Rule shall pass or Fail |
|
RULE_SCRIPT_TEXT |
Description regarding RULE_SCRIPT_TYPE_CODE |
|
CREATE_PROCESS_ID |
Process ID that loaded data in DATA_QUALITY_RULE Table |
|
CREATE_PROCESS_NAME |
Process Name that loaded data in DATA_QUALITY_RULE Table |
|
CREATE_RECORD_USER_NAME |
Service Account that loaded data in DATA_QUALITY_RULE Table |
|
CREATE_RECORD_SYSTEM_TIMESTAMP |
Timestamp when data that rule got inserted in DATA_QUALITY_RULE table |
B. DATA_QUALITY_RULE_EXECUTE Table
This table holds information related to whether the rule is active or not, and the threshold percentage values against which data quality is measured to pass or fail a rule.
DDL for creating DATA_QUALITY_RULE_EXECUTE table
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TABLE DATA_QUALITY_RULE_EXECUTE ( DATA_QUALITY_DATA_SOURCE_CODE VARCHAR(20) NOT NULL, DATA_QUALITY_RULE_ID INTEGER NOT NULL, RULE_PROCESS_STEP_CODE VARCHAR(256) NOT NULL, RULE_EXECUTE_STATUS_CODE VARCHAR(20) NOT NULL, THRESHOLD_PASS_PERCENT VARCHAR(20) NOT NULL, CREATE_PROCESS_ID BIGINT NOT NULL, CREATE_PROCESS_NAME VARCHAR(35) NOT NULL, CREATE_RECORD_USER_NAME VARCHAR(35) NOT NULL, CREATE_RECORD_SYSTEM_TIMESTAMP DATETIME NOT NULL, FOREIGN KEY ([DATA_QUALITY_RULE_ID]) REFERENCES [DATA_QUALITY_RULE] ([DATA_QUALITY_RULE_ID]) ON DELETE NO ACTION ON UPDATE NO ACTION ); |
|
Column Name |
Column Details |
|
DATA_QUALITY_DATA_SOURCE_CODE |
Data Domain or Source of the Data |
|
DATA_QUALITY_RULE_ID |
Unique Rule Identifier |
|
RULE_PROCESS_STEP_CODE |
Step at which data rule is being applied on Data (PRE_STAGE/POST_STAGE) |
|
RULE_EXECUTE_STATUS_CODE |
Indicates the Status of Rule. “P” Indicates “Pass”; “F” Indicates “Fail”, “O” Indicates “Override” |
|
THRESHOLD_PASS_PERCENT |
Threshold Percent that if met cause causes rule to “Pass” else will cause it to “Fail” |
|
CREATE_PROCESS_ID |
Process ID that loaded data in DATA_QUALITY_RULE Table |
|
CREATE_PROCESS_NAME |
Process Name that loaded data in DATA_QUALITY_RULE Table |
|
CREATE_RECORD_USER_NAME |
Service Account that loaded data in DATA_QUALITY_RULE Table |
|
CREATE_RECORD_SYSTEM_TIMESTAMP |
Timestamp when data that rule got inserted in DATA_QUALITY_RULE table |
C. DATA_QUALITY_RULE_RESULTS Table
This table is a repository to store the results of Data Quality Rule monitoring.
DDL for creating DATA_QUALITY_RULE_RESULTS table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
CREATE TABLE DATA_QUALITY_RULE_RESULTS ( DATA_QUALITY_RESULT_ROW_ID BIGINT NOT NULL, DATA_QUALITY_DATA_SOURCE_CODE VARCHAR(20) NOT NULL, DATA_QUALITY_RULE_ID INTEGER NOT NULL, RULE_PROCESS_STEP_CODE VARCHAR(20) NOT NULL, TABLE_ROW_IDENTIFIER BIGINT, SCHEMA_NAME VARCHAR(60), TABLE_NAME VARCHAR(60), DATA_NAME VARCHAR(60), DATA_VALUE VARCHAR(250), RULE_TYPE_CODE VARCHAR(20), RULE_LEVEL_CODE VARCHAR(20), PASS_FAIL_OVERRIDE_CODE CHAR(1), PASS_COUNT INTEGER, FAIL_COUNT INTEGER, SYSTEM_PARTITION_IDENTIFIER VARCHAR(60), CREATE_PROCESS_ID BIGINT NOT NULL, CREATE_PROCESS_NAME VARCHAR(35) NOT NULL, CREATE_RECORD_USER_NAME VARCHAR(35) NOT NULL, CREATE_RECORD_SYSTEM_TIMESTAMP DATETIME NOT NULL, CONSTRAINT [PK_DATA_QUALITY_RESULT_ROW_ID] PRIMARY KEY ([DATA_QUALITY_RESULT_ROW_ID]), FOREIGN KEY ([DATA_QUALITY_RULE_ID]) REFERENCES [DATA_QUALITY_RULE] ([DATA_QUALITY_RULE_ID]) ON DELETE NO ACTION ON UPDATE NO ACTION ); |
|
Column Name |
Column Details |
|
DATA_QUALITY_RESULT_ROW_ID |
Unique Identifier for each record in DATA_QUALITY_RULE |
|
DATA_QUALITY_DATA_SOURCE_CODE |
Data Domain or Source of the Data |
|
DATA_QUALITY_RULE_ID |
Unique Rule Identifier |
|
RULE_PROCESS_STEP_CODE |
Step at which data rule is being applied on Data (PRE_STAGE/POST_STAGE) |
|
TABLE_ROW_IDENTIFIER |
Unique Identifier from the Source table. |
|
SCHEMA_NAME |
Schema of the Table or Schema of File. |
|
TABLE_NAME |
Table that holds the data on which Data Quality Rules need to execute. |
|
DATA_NAME |
Column Name on which rule is executed |
|
DATA_VALUE |
Data Value |
|
RULE_TYPE_CODE |
Describes if Rule is “GATING” or “PASSIVE” |
|
RULE_LEVEL_CODE |
Level at which rule is executed at file or table or column level. |
|
PASS_FAIL_OVERRIDE_CODE |
Status of Data Quality Rule (Pass or Fail or Override) |
|
PASS_COUNT |
Count of Records that Passed the Rule |
|
FAIL_COUNT |
Count of Records that Failed the Rule |
|
SYSTEM_PARTITION_IDENTIFIER |
Partitioning key for DATA_QUALITY_RULE table |
|
CREATE_PROCESS_ID |
Process ID that loaded data in DATA_QUALITY_RULE Table |
|
CREATE_PROCESS_NAME |
Process Name that loaded data in DATA_QUALITY_RULE Table |
|
CREATE_RECORD_USER_NAME |
Service Account that loaded data in DATA_QUALITY_RULE Table |
|
CREATE_RECORD_SYSTEM_TIMESTAMP |
Timestamp when data that rule got inserted in DATA_QUALITY_RULE table |
IV. Understanding Data Quality Monitoring Implementation with an Example:
In order to understand the above Data Quality Framework, I will walk through an example as follows:
A. Source File
The Source File is a pipe-delimited file with Invoice data and its corresponding Control file.
|
1 2 3 4 5 6 |
InvoiceId|CustomerId|InvoiceDate|BillingAddress|BillingCity|BillingState|BillingCountry|BillingPostalCode|Total|StoreID 100|23|2007-01-11|69 Salem Street|Boston|MA|USA|2113|13.86|1 200|16|2007-02-19|1600 Amphitheatre Parkway|Mountain View|CA|USA|94043-1351|0.99|2 300|17|2007-03-04|1 Microsoft Way|Redmond|WA|USA|98052-8300|1.98|3 400|19|2007-03-05|1 Infinite Loop|Cupertino|CA|USA|95014|1.98|4 500|21|2007-03-06|801 W 4th Street|Reno|NV|USA|89503|3.96|5 |
B. Control File
The Control File has details related to the source file like record counts and other important details.
|
1 2 |
DataFileName|ControlFileName|DataFileCount|MinInvoiceDate|MaxInvoiceDate|TotalAmount Invoice_202001.dat|invoice.ctl|5|2007-01-11|2007-02-28|22.77 |
C. DATA_QUALITY_RULE Table
The Data Quality Rule table is a repository of all rules that need to be executed against the data to gauge the quality of data.
There are 2 types of data quality rules.
- Gating Rules
- Passive Rules
Gating Rules: Gating Rules are critical rules. These are rules that are critical to certify the quality of data. If any one of these rules fails, that means the data is not good enough to be loaded into application tables. The source data should be either corrected, or a new version of file needs to be requested from the source system. In that case, the data quality rules need to be rerun on new file and gating rules should pass for the data to be loaded into underlying reporting application tables. When “Gating” data quality rule fails, the ETL cycle would stop and would not proceed until either the new data is requested or that gating rule passes, or data stewards do a manual override.
Passive Rules: Passive Rules are the rules that are good to have but are not very critical. That means data is still useful for analytical reporting. If a passive data quality rule fails, then also data would be allowed to flow down to downstream applications.
In order to understand I’ll walk you through the following five rules.
Rule 1:
Data Quality Rule to Check the Source Schema/Layout matches the expected layout.
Rule 2:
Data Quality Rule to verify the same file has not been processed earlier (Duplicate File Check)
Rule 3:
Data Quality Rule to verify each record in the data file has an Invoice Date between the Minimum Invoice Date and Maximum Invoice Data and write failed records to the results table.
Rule 4:
Data Quality Rule to provide a count of passed/failed records for Invoice Date between the Minimum Invoice Date and Maximum Invoice Data.
Rule 5:
Data Quality Rule to provide a count of passed/failed records for StoreID being null.
Please refer to DataQuality_InsertStatements.txt for insert statements.
Note: I am inserting rules in the DATA_QUALITY_RULE table using Insert Statement (for demonstration/explanation purposes for each record). A preferable way would be to load all rules from a pipe separated file using an ETL tool or script.
RULE_SCRIPT_TYPE_CODE: The rule script type code field defines when a rule passes or fails and when records are supposed to be loaded to the DATA_QUALITY_RULE_RESULTS table.
To understand how this works, review this example:
RULE_SCRIPT_TYPE_CODE is set to “COMP_THRE_VAL_NE_F_F”
‘COMP_THRE_VAL’ stands for Compare Threshold values, i.e. compare the threshold value of the actual threshold vs the expected threshold.
NE – Stands for Not Equal, i.e. if the actual data threshold percent % and expected threshold percent (from DATA_QUALITY_RULE_EXECUTE) are not equal. Other possible values are
“EQ” stands for “Equal to”
“GE” stands for “Greater than or equal to”
“GT” stands for “Greater than”
“LE” stands for “Less than or equal to”
“LT” stands for “Less than”
F – Stands for action to be taken regarding the status of the rule. In this case, if the expected threshold percent is not equal to actual the data threshold percent, then fail the rule. The other possible value is “P”.
F – Stands for write the failed records to the DATA_QUALITY_RULE_RESULTS table. “P” Stands for write-only passed records and “E” stands for loading everything, i.e. both pass and fail records to be written to DATA_QUALITY_RULE_RESULTS table.
D. DATA_QUALITY_RULE_EXECUTE
This table is used to control the activation and inactivation of a data quality rule. If a rule is marked as active in the DATA_QUALITY_RULE_EXECUTE table, then that rule will be executed against the data, and corresponding data metrics would be captured and loaded in DATA_QUALITY_RULE_RESULTS table. If a rule is marked inactive in the DATA_QUALITY_RULE_EXECUTE table, then that rule will NOT be executed against the source data, and its metrics are not captured in the table.
Data Quality rules would be executed mostly at two places in the process as follows:
- Pre-Stage DQ Rules – Before loading into the Stage Table
- Post Stage DQ Rules – After loading into the Stage Table
Pre-Stage DQ Rules:
The Pre-Stage DQ rules are executed before the data gets loaded into the Stage Table.
The intent of having Pre-Stage DQ rules is to avoid loading bad data in stage tables and to avoid abortion of the ETL load process because of an unexpected file layout.
Some of the examples for Pre-Stage Data Quality rules are:
- Schema/layout validation of input file.
- Duplicate File Check
- Control File and Data File Count Match.
Post-Stage DQ Rules: Post-Stage DQ rules are executed after the data is loaded into the staging table. Post-Stage DQ rules would typically validate data against business-critical fields and produce metrics.
Please refer to DataQuality_InsertStatements.txt for insert statements.
Below is an explanation for each Insert statement into DATA_QUALITY_RULE_EXECUTE table
Rule 1 (Schema Layout Verification Rule):
The rule belongs to the “Invoice” Data Domain as apparent from DATA_QUALITY_DATA_SOURCE_CODE set to “Invoice”. It is a “PRE_STAGE” rule that means it should be executed before the Invoice data file is even loaded into an Invoice Stage table
Rule 2 (Duplicate File Validation Rule):
The rule belongs to the “Invoice” Data Domain as apparent from DATA_QUALITY_DATA_SOURCE_CODE set to “Invoice”. It is a “PRE_STAGE” rule that means it should be executed before the Invoice data file is even loaded into Invoice Stage table. The rule is “Active” as RULE_EXECUTE_STATUS_CODE is set to “A”. The Threshold Pass Percentage is set to 100, meaning that even if a single record does not meet the criteria, the rule will fail.
Rule 3 (Invoice Date Validation Rule):
The rule belongs to the “Invoice” Data Domain as apparent from DATA_QUALITY_DATA_SOURCE_CODE set to “Invoice”. It is a “POST_STAGE” rule meaning that it should be executed after the Invoice data file is loaded into Invoice Stage table. The rule is “Active” as RULE_EXECUTE_STATUS_CODE is set to “A”. The Threshold Pass Percentage is set to 100, meaning that even if a single record does not meet the criteria, the rule will fail.
Rule 4 (Invoice Date Summary Rule):
The rule belongs to the “Invoice” Data Domain as apparent from DATA_QUALITY_DATA_SOURCE_CODE set to “Invoice”. It is a “POST_STAGE” rule that means it should be executed after the Invoice data file is loaded into the Invoice Stage table. The rule is “Active” as RULE_EXECUTE_STATUS_CODE is set to “A”. The Threshold Pass Percentage is set to 100, meaning that even if a single record does not meet the criteria, the rule will fail.
Rule 5 (Store ID Summary Rule):
The rule belongs to the “Invoice” Data Domain as apparent from DATA_QUALITY_DATA_SOURCE_CODE set to “Invoice”. It is a “POST_STAGE” rule that means it should be executed after the Invoice data file is loaded into the Invoice Stage table. The rule is “Active” as RULE_EXECUTE_STATUS_CODE is set to “A”. The Threshold Pass Percentage is set to 90%, meaning that 90% or more of the records should have StoreID populated for the rule to pass.
E. DATA_QUALITY_RULE_RESULTS
The DATA_QUALITY_RULE_RESULTS table is a repository where all the data quality metrics for the rule executions are stored. The table is partitioned on SYSTEM_PARTITION_IDENTIFIER. A new partition is created for each month for each data source.
Data Quality Rule Results are generated by calculating the expected and actual results. Both expected and actual results are compared, and if the actual results match the expected results, the rule pass else would be marked as failed.
F. Expected Results:
Multiple steps are involved in generating expected results.
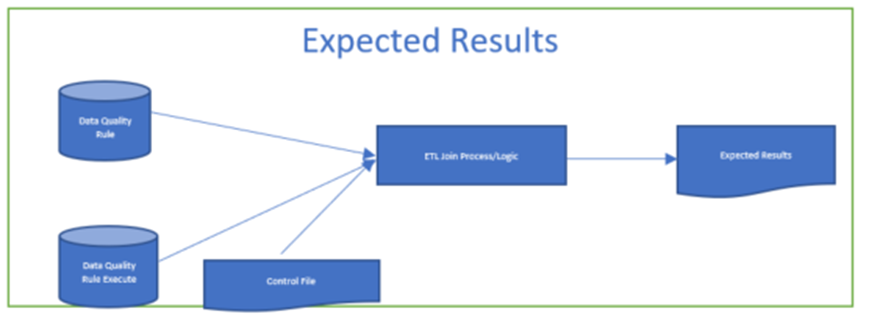
Figure 3: The expected results
In order to generate expected results, three steps are involved.
- Join the Data Quality Rule table with Data Quality Rule Execute table.
- Pivot the Control File Data
- Join the Data Quality Rule tables data with control file data
1. Join Data Quality Rule and Data Quality Rule Execute table as follows:
The SQL query below joins the Data_Quality_Rule table to the Data_Quality_Rule_Execute table on Rule ID to create a flattened record with all Data Quality Rules Information.
Please Note: You could add a where condition on DATA_QUALITY_DATA_SOURCE_CODE to filter the application for which you like to run the data quality rule.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
select dq.DATA_QUALITY_RULE_ID, dq.RULE_TYPE_CODE, dq.RULE_LEVEL_CODE, dq.SCHEMA_NAME, dq.TABLE_NAME, dq.DATA_NAME, dq.RULE_SCRIPT_TYPE_CODE, dq.RULE_SCRIPT_TEXT, dqr.RULE_PROCESS_STEP_CODE, dqr.RULE_EXECUTE_STATUS_CODE, dqr.THRESHOLD_PASS_PERCENT from data_quality_rule dq inner join DATA_QUALITY_RULE_EXECUTE dqr on dq.DATA_QUALITY_RULE_ID=dqr.DATA_QUALITY_RULE_ID |
The joined data would look something like this.
|
1 2 3 4 5 6 |
DATA_QUALITY_RULE_ID|RULE_TYPE_CODE|RULE_LEVEL_CODE|SCHEMA_NAME|TABLE_NAME|DATA_NAME|RULE_SCRIPT_TYPE_CODE|RULE_SCRIPT_TEXT|RULE_PROCESS_STEP_CODE|RULE_EXECUTE_STATUS_CODE|THRESHOLD_PASS_PERCENT 1|GATING|FILE|Invoice_schema.txt|Invoice_YYYYMM.dat|SCHEMA_VALIDATION|COMP_THRE_VAL_EQ_P_E|Val_SchemaFile_Chk|PRE_STAGE|A|100.00 2|GATING|FILE|Invoice_schema.txt|Invoice_YYYYMM.dat|DUPLICATE_VALIDATION|COMP_THRE_VAL_EQ_P_E|Val_DuplicateFile_Chk|PRE_STAGE|A|100.00 3|GATING|COLUMN|dbo|Invoice|InvoiceDate|COMP_THRE_VAL_NE_F_F|Val_InvoiceDate_Chk|POST_STAGE|A|100.00 4|PASSIVE|TABLE|dbo|Invoice|InvoiceDate|COMP_THRE_VAL_EQ_P_E|InvoiceDate_Chk_Summary|POST_STAGE|A|100.00 5|PASSIVE|TABLE|dbo|Invoice|StoreID|COMP_THRE_VAL_EQ_P_F|StoreID_CHK|POST_STAGE|A|90.00 |
2. Pivot the Control File Data.
This step pivots the data in the control file. Pivoting is nothing more than converting columns to rows.
Control File before pivoting (Also shown in above sections)
|
1 2 |
DataFileName|ControlFileName|DataFileCount|MinInvoiceDate|MaxInvoiceDate|TotalAmount Invoice_202001.dat|invoice.ctl|5|2007-01-11|2007-02-28|22.77 |
Control File After pivoting:
|
1 2 3 4 5 6 |
DATA_NAME|DATA_VALUE DataFileName|Invoice_202001.dat ControlFileName|Invoice.ctl DataFileCount|5MinInvoiceDate|2007-01-11 MaxInvoiceDate|2007-02-28 TotalAmount|22.87 |
Pivoting helps joining control file details with corresponding Data Quality Rule Information (from step 1).
3. Joining the Data Quality Rule Tables Data with Control File Data
This is the final step to create the expected results. In this, you join the pivoted control file data (Step2) with Data Quality Rule tables information (Step1) on “DATA_NAME.” This creates the expected results as follows. Expected results are nothing but control file data associated with corresponding data quality rule information.
|
1 2 3 4 5 6 |
DATA_QUALITY_RULE_ID|RULE_TYPE_CODE|RULE_LEVEL_CODE|DATA_NAME|DATA_VALUE|RULE_SCRIPT_TYPE_CODE|RULE_SCRIPT_TEXT|RULE_PROCESS_STEP_CODE|RULE_EXECUTE_STATUS_CODE|THRESHOLD_PASS_PERCENT 1|GATING|FILE|Schema_Validation|Y|COMP_THRE_VAL_EQ_P_E|Val_SchemaFile_Chk|PRE_STAGE|A|100.00 2|GATING|FILE|Duplicate_Validation|Y|COMP_THRE_VAL_EQ_P_E|Val_DuplicateFile_Chk|PRE_STAGE|A|100.00 3|GATING|COLUMN|InvoiceDate|2007-01-11:2007-03-06|COMP_THRE_VAL_NE_F_F|Val_InvoiceDate_Chk|POST_STAGE|A|100.00 4|PASSIVE|TABLE|InvoiceDate|2007-01-11:2007-03-06|COMP_THRE_VAL_EQ_P_E|InvoiceDate_Chk_Summary|POST_STAGE|A|0.00 5|PASSIVE|TABLE|StoreID|NOTNULL|COMP_THRE_VAL_EQ_P_F|StoreID_CHK|POST_STAGE|A|90.00 |
G. Actual Results:
There are two steps involved in creating the actual results as follows:
- Pivot the source data file.
- Join pivoted source data with Data Quality Rule table and ETL Process Metadata
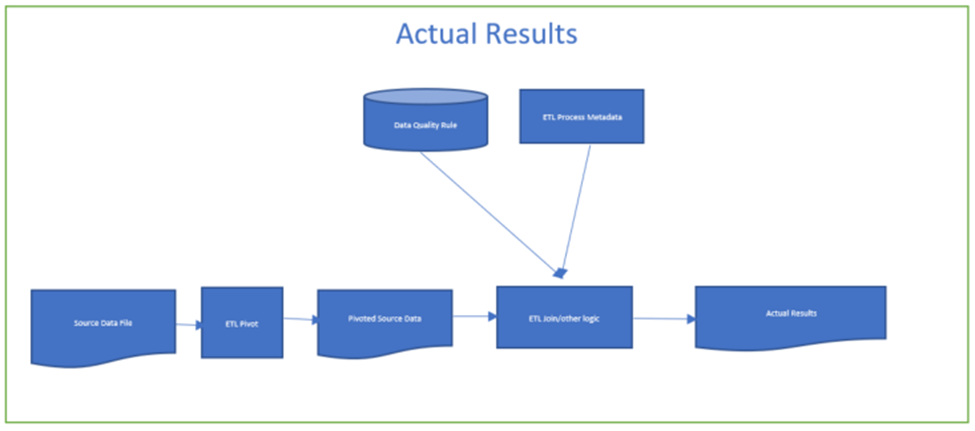
Figure 4: The actual results
1. Pivot the source data file:
Below is the source file that has been mentioned in an earlier section of this article.
Source File
|
1 2 3 4 5 6 |
InvoiceId|CustomerId|InvoiceDate|BillingAddress|BillingCity|BillingState|BillingCountry|BillingPostalCode|Total|StoreID 100|23|2007-01-11|69 Salem Street|Boston|MA|USA|2113|13.86|1 200|16|2007-02-19|1600 Amphitheatre Parkway|Mountain View|CA|USA|94043-1351|0.99|2 300|17|2007-03-04|1 Microsoft Way|Redmond|WA|USA|98052-8300|1.98|3 400|19|2007-03-05|1 Infinite Loop|Cupertino|CA|USA|95014|1.98|4 500|21|2007-03-06|801 W 4th Street|Reno|NV|USA|89503|3.96|5 |
Pivot the source file data with InvoiceID as the key for each record. Pivoting is a process for transforming row column-level data to the row level. The data would look like below.
Please Note: This is a sample set and not the entire data set.
|
1 2 3 4 5 6 7 8 9 10 11 |
InvoiceID|DataName|DataValue 100|InvoiceDate|2007-01-11 200|InvoiceDate|2007-02-19 300|InvoiceDate|2007-03-04 400|InvoiceDate|2007-03-05 500|InvoiceDate|2007-03-06 100|StoreID|1 200|StoreID |2 300|StoreID |3 400|StoreID |4 500|StoreID |5 |
2. Join Source File Pivot Data with Data Quality Rule table and ETL Process Metadata
In this step, take the pivoted source data (step 1) and join with the Data Quality Rule table to attach Rule ID to each pivoted source data record.
Please Note: The join to ETL process metadata is optional. If there are no Data Quality Rules related to ETL metadata, this join is not needed.
The ETL process metadata is standard metadata information captured by ETL processes like start and end time of ETL executions, if the source file met the expected schema, if the source file is a new file or a duplicate file based on the file name.
Once joining pivoted source data with Data Quality Rule table, you would then join it with ETL process metadata to get information related to Rule 1. This is related to file layout/schema verification of source file and also for Rule 2 that is related to duplicate source file names.
The following shows after validating for Rule 1, there is a Data Value of 5 and Pass Count as 5. This indicates that there were 5 rows in the file, and all 5 of them passed the validation. This information is coming from the ETL process metadata. Similarly, for Rule 2 related to Duplication Validation, the pass count is 1, and a fail count is 0. If this were a duplicate file, there would be a pass count of 0 and fail count of 1. For all the other rules, Pass count and Fail count are not populated yet because they are dependent on matching this actual data with expected data.
Data After Joining source pivoted data with Data Quality rule and ETL process metadata.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
RuleID|InvoiceID|DataName|DataValue|Pass_Count|Fail_Count 1|0|Schema_Validation|5|5|0 2|0|Duplicate_Validation|0|1|0 3|100|InvoiceDate|2007-01-11|NULL|NULL 3|200|InvoiceDate|2007-02-19|NULL|NULL 3|300|InvoiceDate|2007-03-04|NULL|NULL 3|400|InvoiceDate|2007-03-05|NULL|NULL 3|500|InvoiceDate|2007-03-06|NULL|NULL 4|100|InvoiceDate|2007-01-11|NULL|NULL 4|200|InvoiceDate|2007-02-19|NULL|NULL 4|300|InvoiceDate|2007-03-04|NULL|NULL 4|400|InvoiceDate|2007-03-05|NULL|NULL 4|500|InvoiceDate|2007-03-06|NULL|NULL 5|100|StoreID|1|NULL|NULL 5|200|StoreID |2|NULL|NULL 5|300|StoreID |3|NULL|NULL 5|400|StoreID |4|NULL|NULL 5|500|StoreID |5|NULL|NULL |
H. Generating Data Quality Rule Results.
Data Quality Rule Results are generated by comparing the Expected Results with Actual Results. The ETL logic compares expected results with actual results to derive Data Quality metrics and then loads it into the Data Quality Rule Results table.
Expected Results (These were derived in above section of article):
|
1 2 3 4 5 6 |
DATA_QUALITY_RULE_ID|RULE_TYPE_CODE|RULE_LEVEL_CODE|SCHEMA_NAME|TABLE_NAME|DATA_NAME|DATA_VALUE|RULE_SCRIPT_TYPE_CODE|RULE_SCRIPT_TEXT|RULE_PROCESS_STEP_CODE|RULE_EXECUTE_STATUS_CODE|THRESHOLD_PASS_PERCENT 1|GATING|FILE|Invoice_schema.txt|Invoice_YYYYMM.dat|SCHEMA_VALIDATION|NULL|COMP_THRE_VAL_EQ_P_E|Val_SchemaFile_Chk|PRE_STAGE|A|100.00 2|GATING|FILE|Invoice_schema.txt|Invoice_YYYYMM.dat|DUPLICATE_VALIDATION|NULL|COMP_THRE_VAL_EQ_P_E|Val_DuplicateFile_Chk|PRE_STAGE|A|100.00 3|GATING|COLUMN|dbo|Invoice|InvoiceDate|2007-01-11:2007-03-06|COMP_THRE_VAL_NE_F_F|Val_InvoiceDate_Chk|POST_STAGE|A|100.00 4|PASSIVE|TABLE|dbo|Invoice|InvoiceDate|2007-01-11:2007-03-06|COMP_THRE_VAL_EQ_P_E|InvoiceDate_Chk_Summary|POST_STAGE|A|100.00 5|PASSIVE|TABLE|dbo|Invoice|StoreID|NULL|COMP_THRE_VAL_EQ_P_F|StoreID_CHK|POST_STAGE|A|90.00 |
Actual Results (These were derived in above section of article):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
RuleID|InvoiceID|DataName|DataValue|Pass_Count|Fail_Count 1|0|Schema_Validation|5|5|0 2|0|Duplicate_Validation|0|1|0 3|100|InvoiceDate|2007-01-11|NULL|NULL 3|200|InvoiceDate|2007-02-19|NULL|NULL 3|300|InvoiceDate|2007-03-04|NULL|NULL 3|400|InvoiceDate|2007-03-05|NULL|NULL 3|500|InvoiceDate|2007-03-06|NULL|NULL 4|100|InvoiceDate|2007-01-11|NULL|NULL 4|200|InvoiceDate|2007-02-19|NULL|NULL 4|300|InvoiceDate|2007-03-04|NULL|NULL 4|400|InvoiceDate|2007-03-05|NULL|NULL 4|500|InvoiceDate|2007-03-06|NULL|NULL 5|100|StoreID|1|NULL|NULL 5|200|StoreID |2|NULL|NULL 5|300|StoreID |3|NULL|NULL 5|400|StoreID |4|NULL|NULL 5|500|StoreID |5|NULL|NULL |
Comparing Expected Results with Actual Results
The expected results are joined with actual results on column Data Quality Rule ID, and the other ETL process compares the actual vs expected and produces Data Quality Rule Metrics.
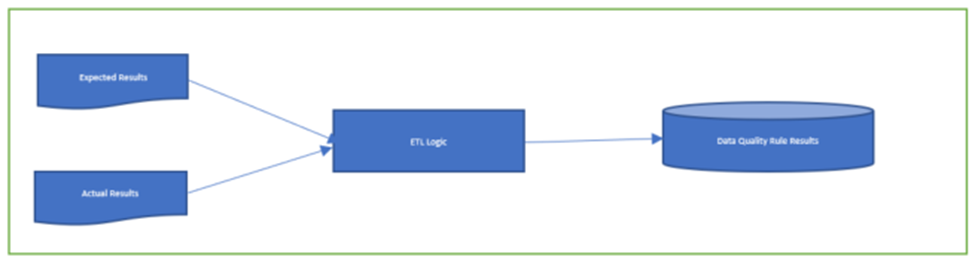
Rule 1: For Rule 1, the expected threshold is set to “100”. If the schema validation has passed for the data file, then the Actual Threshold would also be derived as “100” in the ETL logic. RULE_SCRIPT_TYPE_CODE is set to “COMP_THRE_VAL_EQ_P_E”. That means if both thresholds are equal, set the rule status to pass “P”, and “E” represents that rule results are to be loaded into the table irrespective of rule status.
![]()

Rule 2: For Rule 2, the expected threshold is set to “100”. If the data file is not a duplicate file, i.e. if the same file name has not been processed earlier, then the Actual Threshold would also be derived as “100” in the ETL logic. RULE_SCRIPT_TYPE_CODE is set to “COMP_THRE_VAL_EQ_P_E”, so if both thresholds are equal, set the rule status to pass “P”. “E” means that rule results are to be loaded into the table irrespective of rule status.


Rule 3: For Rule 3, the expected threshold is set to “100”, and the InvoiceDate of each record from the actual results dataset is compared with the expected InvoiceDate range of 2007-01-11 to 2007-02-28. As each row is checked, any record that has an InvoiceDate outside the range is marked as failed with the “F” status code. Since the RULE_SCRIPT_TYPE_CODE is set to “COMP_THRE_VAL_NE_F_F”, any record that fails would be loaded into the Data Quality Rule Results table.


Please Note: Pass count and Fail count loaded as “0” as this is column level rule and not a table-level rule. It is possible to increment the fail count with each row being loaded to into Data Quality Rule results table, but as this will require sorting and ranking rows. It is preferable that pass_count and fail_count be used for table level rules where the aggregation is done and total pass and fail count can be easily identified.
Rule 4: For Rule 4, the expected threshold is set to “100” and from the actual results records for which InvoiceDate does not fall within the expected range of 2007-01-11 to 2007-02-28 are counted, and Actual Threshold percentage is derived at 40. If no records have failed, then the actual Threshold percentage would be 100. As this is a table-level rule, only one record for the entire batch load will be loaded in the Data Quality Rule Results table. RULE_SCRIPT_TYPE_CODE is set to “COMP_THRE_VAL_EQ_P_E”, so that means if both thresholds are equal set the rule status to pass “P” and “E” (Everything) represents that rule results to be loaded into the table irrespective of rule status.


Rule 5: Rule 5 is to check if the StoreID column is not null. The expected threshold is set to “90” and RULE_SCRIPT_TYPE_CODE is set to “COMP_THRE_VAL_GE_P_F”. In the data file, there are no records that have StoreID as null. In this case, the ETL would calculate the actual threshold as “100” which is greater than 90% (expected threshold), and the rule will pass “P”. Since the final character is “F” in COMP_THRE_VAL_GE_P_F, it means only failed rules should be loaded in the data quality results table. In this case, no results would be loaded for Rule5. The final rule results table would look like this.
|
1 |
select * from DATA_QUALITY_RULE_RESULTS |



In the above example, I have walked through all the 5 data quality rules. Rules 1 and 2 are pre-stage rules, and they should be executed before data is loaded in-to stage table and the Rules 3, 4 and 5 are post-stage data quality rules and should be executed after the data is loaded to stage table.
A dashboard could be created on DATA_QUALITY_RULE_RESULTS table to provide data quality metrics to data stewards for review.
V. Conclusion
By implementing the above Data Quality Monitoring Data Framework, an organization can ensure that the highest quality data is loaded into underlying application tables. Detail metrics related to data quality could be made available to data stewards by building dashboard on top of DATA_QUALITY_RULE_RESULTS table.
Load comments