
We deal with databases in this trade, but so many of us do not entirely understand data analysis. I guess this why we recently invented the term “Data Science” and attached a large paycheck to it. No longer do we need to be so aware of the details of data before getting started in IT. The pioneers in Information Technology had to have a good grounding in math, elementary statistics, and the way that data was encoded. Nowadays, it is less central.
There is a Dilbert cartoon of the Pointy-Haired Boss called ‘The Wrong Data’…
‘Use the CRS database to size the market’That data is wrong.’Then use the DIBS database’That data is also wrong. ‘Can you average them?’Sure. I can also multiply them, too.
When I ask the kids what they know about floating point math and rounding error I get the strange impression of talking to a display case in a fish market; open mouths, dead glazed eyes staring back from cold dead meat. When we did statistical work with FORTRAN, you had to know this level of detail in the tools. Today, much of this is hidden in the tools, but the software cannot entirely protect you from needing to know the actual nature of data: You can still fail spectacularly.
Thinking about Data
Tee shirt slogan: “On a scale from 1 to 10, what color is your favorite letter of the alphabet?” I will bet you started to answer that question! That is the joke. But if you actually did answer the question, then you either need some help or you are an absurdist stand-up comedian. People do not understand scales and measurement and I have a whole book on this (Joe Celko’s Data, Measurements and Standards in SQL; 2009; Morgan Kaufmann; ISBN: 978-0-12-374722-8).
One of the barriers to understanding math is the way that the media increasingly use Pseudo-mathematics to reinforce belief and opinion: it sets a bad example. I’m 110% certain of this. If you like reading math books, get a copy of “Street-Fighting Mathematics” by Sanjoy Mahajan (2010; ISBN: 978-0262514293). The first chapter is on dimensions and it starts with false comparisons between the net worth of Exxon ($119 Billion after 125 years) and the GDP of Nigeria ($ 99 Billion per year). There is no way to legitimately compare these measurements, but people do! Perception is not math.
I have Mother Celko’s Law of Decimal Places: “A statistic or measurement impresses the reader to the square of the decimal places.” This a means that telling your non-techie manager that the average weight of a floobsnizzle is 23 kilograms is not as impressive as telling him the average weight of a floobsnizzle is 23.12 kilograms.
Then I have Mother Celko’s Law of Units. When I tell my non-techie manager that the average weight of a floobsnizzle is ~50 pounds, it does not look as scientific as ~23 kilograms. To an American, especially, Metric units are scientific while US customary units are for the grocery store. This is more than Americans not knowing the SI system; they do not even know that US customary units are not Imperial units! It is a mindset that says “European stuff is cool” that they got from fashion magazines as much as technical books.
Central Tendency Measures
Given a set of data and one attribute in it, what is the best way to summarize the attribute as a single value? This is usually called a measure of central tendency. Informally, you do this all the time when you declare “Those kids are fat!” in the everyday world. The set of kids can be vaguely defined (kids in <insert name of country here>), and the term “fat” is certainly fuzzy. A fat ballet dancer is probably different from a thin Sumo Wrestler.
When you put a number to this, however, it looks better. If I tell you most statistics are fake, it is not as convincing as telling you 79% of all statistics are invented on the spot. But what number to use and how do we get it?
- Average is the easiest one for SQL programmers because it is built into the language. The other two common ones are the median and the mode, but they are not built in. You can Google SQL for them; they are not hard.
- The mode is the most frequently occurring value in a set. If there are two such values in a set, statisticians call it a bimodal distribution; three such values make it trimodal, and so forth. Most SQL implementations do not have a mode function, since it is easy to calculate. But if the data is multi-modal, then there probably is no central tendency at all. Think about a third world country that is effectively without a middle class; you are either a starving peasant or a member of the rich royal family.
- The median is defined as the value for which there are just as many cases with a value below it as above it. If such a value exists in the data set, this value is called the statistical median by some authors. If no such value exists in the data set, the usual method is to divide the data set into two halves of equal size such that all values in one half are lower than any value in the other half. The median is then the average of the highest value in the lower half and the lowest value in the upper half, and is called the financial median by some authors. Then we have the weighted median based on subsets around the middle; it is easier to explain with a small example {1,2,2,3,3,3}. The financial median is (2+3)/2 = 2.5, but the weighted median is computed as (2+2+3+3+3)/5 = 2.6. The weighted median shows that half of the set is 3’s which shifts the central measure toward that side.
Darrell Huff wrote a classic book, “How to lie with Statistics” that has been in print since 1954. Yes, it is that good and you should read it. One of his example is list of salaries which look out of date in 2014.
|
occurrences |
salary |
|
1 |
$45,000.00 |
|
1 |
$15,000.00 |
|
2 |
$10,000.00 |
|
1 |
$5,700.00 |
|
3 |
$5,000.00 |
|
4 |
$3.700.00 |
|
1 |
$3,000.00 |
|
12 |
$2,000.00 |
The mode is $2,000.00. This makes the company look pretty cheap. The arithmetic mean is $5,700.00. That makes the pay look pretty good for 1954. The median is $2,500.00. This is a better measure of the central value of the set! People will, however, pick whichever number reinforces their political position.
This is about as far as most people get with central tendency. But there are other measures!
The Geometric Mean is sometimes a better measure of central tendency than the simple arithmetic mean when you are analyzing change-over-time. The geometric mean is more appropriate than the arithmetic mean for describing proportional growth, both exponential growth (constant proportional growth) and varying growth. The geometric mean of growth over periods yields the equivalent constant growth rate that would yield the same final amount.
At this point, I am talking too much math, so I will steal from Wikipedia. Suppose an orange tree yields 100 oranges one year and then 180, 210 and 300 the following years, so the growth is 80%, 16.6666% and 42.8571% for each year respectively. Using the arithmetic mean calculates a (linear) average growth of 46.5079% (80% + 16.6666% + 42.85261% divided by 3). However, if we start with 100 oranges and let it grow 46.5079% each year, the result is 314 oranges, not 300, so the linear average over-states the year-on-year growth. Instead, we can use the geometric mean. Growing with 80% corresponds to multiplying with 1.80, so we take the geometric mean of 1.80, 1.166666 and 1.428571, i.e. 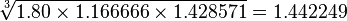 ;
;
thus the “average” growth per year is 44.2249%. If we start with 100 oranges and let the number grow with 44.2249% each year, the result is 300 oranges. This is a better measure of the trend.
You really need to read Wikipedia’s account of Pythagorean Means. These are the three Pythagorean means. They get this name because they are based on planar geometry model of distances
Simpson Paradox
Simpson’s paradox has nothing to do with Homer Simpson or O. J. Simpson; it is named after the British statistician Edward Hugh Simpson who wrote about it in the 1950’s. Simpson’s paradox happens when a trend that appears in separate groups of data disappears when these groups are combined, and the reverse trend appears for the aggregate data. It tends to happen when you partition your data into subsets where each of the subsets is a little skewed and of odd sizes, and illustrates well the dangers of the consequences of errors in population sampling.
The real problem is that people believe that correlation is causality, and that you can prove this with simple frequency analysis.
This result is often encountered in social-science and medical-science statistics, and is particularly confounding when frequency data are unduly given causal interpretations. Simpson’s Paradox disappears when causal relations are considered.
One of the best-known real-life examples is the University of California, Berkeley 1973 gender bias lawsuit. The charge was that university favored man over women in graduate school admission rates in the aggregate.
|
Applicant Count |
Admission Rate |
|
|
Men |
8442 |
44.00% |
|
Women |
4321 |
35.00% |
But when examining the individual departments, it appeared that no department was significantly biased against women. In fact, most departments had a small but statistically significant bias in favor of women. The data from the six largest departments are listed below.
|
Department Name |
Men |
Women |
||
|
Applicant Count |
Admission Rate |
Applicant Count |
Admission Rate |
|
|
A |
825 |
62.00% |
108 |
82.00% |
|
B |
560 |
63.00% |
25 |
68.00% |
|
C |
325 |
37.00% |
593 |
34.00% |
|
D |
417 |
33.00% |
375 |
35.00% |
|
E |
191 |
28.00% |
393 |
24.00% |
|
F |
373 |
6.00% |
341 |
7.00% |
The research showed that women tended to apply to competitive departments with low rates of admission even among qualified applicants (i.e. English Department), while men tended to apply to departments with high rates of admission and a smaller pool of qualified applicants (i.e. engineering and chemistry). 3
Bayesian Statistics
This school of statistics is named for Thomas Bayes (1702-1761), but a lot of other people have contributed. Bayes hung up in English Christian theology and Hume’s philosophy of his day. The central idea of Bayesian probability is that you can improve your estimates with new information.
On the other side of the table we have frequentist statistics. In a frequentist model, the unknown parameters are treated as having fixed but unknown values that are not capable of being treated as random variates in any sense, and hence there is no way that probabilities can be associated with them.
Despite the success of Bayesian models, most undergraduate courses are based on frequentist statistics. The frequentist assumption is that each sample is pulled from a universe of possible outcomes that are equally likely and independent of each other. We need to stop doing this.
I am going to assume that all good geeks have heard of the Monty Hall problem. It was used on an episode of the television show NUMB3RS (https://www.youtube.com/watch?v = OBpEFqjkPO8), made poplar by Marilyn vos Savant in her newspaper column “Ask Marilyn” (vos Savant, Marilyn (Sept 1990) Parade Magazine: 16) and many other places.
The problem was originally posed in a letter by Steve Selvin to the American Statistician in 1975. The problem gets its name from the American television game show “Let’s Make a Deal” which was hosted by Monty Hall. Suppose you’re on a game show, and you’re given the choice of three doors: Behind one door is a Lamborghini; behind the others, wet goats. You pick a door, and the host, who knows what’s behind all the doors, opens another door. This second door always has a wet goat. He then says to you, “Do you want to stay with your pick or to switch?”
We need to get a little notation:
probability of event A given event B is written Pr(A|B)
probability of event B is written Pr(B)
the Pr(A) is between zero (impossibility) and one (absolute certainty)
Pr(A|¬A) = 0 Pr(A|A) = 1
Bayes’ Theorem can be written:
Pr(A|B) = (Pr(B|A) × Pr(A)) / Pr(B)
Assume we pick Door #1 and then Monty shows us a wet goat behind Door #2. Now let event A mean the car is behind Door #1 and event B mean that Monty shows us a wet goat behind Door #2.
Then plug in the probabilities:
Pr(A|B) = (Pr(B|A) × Pr(A)) / Pr(B) = ( 1/2 × 1/3) / (1/3 × 1/2+1/3 × 0+1/3 × 1) = 1/3.
The tricky calculation is Pr(B). Remember, we are assuming we initially chose Door #1. We now know there is a wet goat behind Door #2, so we know the car is either behind Door #1 or Door #3. Since we started with the probability that the car is behind Door #1 is 1/3 and the sum of the two probabilities must equal 1, the probability the car is behind Door #3 is 1â1/3 = 2/3. You could also apply Bayes’ Theorem directly, but this is simpler.
The real power is avoiding panic. Mammograms are pretty accurate these days. They can identify about 80% of the breast cancers in 40 year old women and produce a false positive only about 10% of the time. We also have the prior knowledge that about 0.4% of women have breast cancer from medical stats. Call this 40 out of 10,000. About 32 of those 40 will get a true positive. But about 1000 of the original 10,000 population will get a false positive. Plug in the numbers and turn the crank, and you get ~3% that the positive result is true. But we also see that a mammogram miss about 1 in 5 breast cancers, which might be more of a problem.
REFERENCES:
- Mcblackne, Sharon Bertsch; The Theory That Would Not Die; 2011; Yale University Press; ISBN:978-0-300-16969-0
- Lies, Damned Lies, and Medical Science
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments