
As we have pieced together the components of a web application we have explored how best to structure the markup, and how to pull business logic out of the UI by following the Model View Presenter Pattern. Now let’s turn our attention to the Model as we pull all the pieces together and explore what a well behaved model might look like.
The Model will be the piece that handles storing and retrieving our data. Just as we did with the markup and view, we want to provide a separation of concerns and try to shield ourselves from the more volatile aspects of our design.
Model, Model, Everywhere
Software development is full of models. We have domain models, physical data models, logical models, process models, etc. Sometimes the terminology can be confusing and the differences subtle and often abused. Let’s try to clear some up some of the confusion.
A domain model is an informal way of thinking about data and how the data components relate to each other independent of any technology or formal structure. We think about relations but not constraints. We think about associations but not inheritance, and we think very loosely about data types, if at all. The domain model is the ultimate in fluid informal discussion.
A physical data model is the implementation of a domain model in a specific database. While the domain model is independent of any technology, the physical data model is very dependent on a particular database platform. It may even be dependent on a particular version of the selected database. In some cases, it may even be dependent on a particular disk configuration with a specific operating system.
The domain model is free from any technical constraints leaving many implementation details to be resolved in the physical data model. For example, entity names in the domain model can be anything, while entity names in the physical data model are limited to what the RDMS can handle. The domain does not have to worry about performance or maintenance. Most of the details in the physical model are consumed by these concerns.
Here we will focus most of our discussion on the development model. The relationship between the domain model and the development model is similar to the relationship between the domain and physical data models – similar but not exact.
The development model is the implementation of a domain model in code.
Ultimately, the development model will be expected to store and retrieve data from the physical data model. The development model also has restrictions and extensions that the physical data model never has to deal with. The development model can benefit from inheritance and polymorphism, and encapsulation, but also has to deal with the often self-contradictory business logic.
The development model is also the last line of defense protecting the data in the database. Validations in your code protect the data better than any constraint, firewall, or the best security measures that a security administrator can put in place.
Relationships of Models
There is a strong temptation to over- simplify modeling. I have often been tempted to start with the domain model and simply have a table for every entity and have a class for every table. This is simple, neat, and very easy to follow, but leads to a less than optimal solution.
The domain model may have the concept of Broker, Closing Agent, and Appraiser. These make nice domain entities. If the domain model even thinks about it, we may note that each of these entities have some common features like an address. In most cases, this will simply be defined very vaguely with no thought to implementation, and this is appropriate for the domain model. There will most likely not be an Address entity.
The physical data model may refine this further and have a separate table set up for the address, noting that each of these entities will have the same details for the address, and centralize these details to a common table and have a relationship to the tables for the Broker, Closing Agent, and Appraiser.
The development model may extend this further realizing that there are different types of addresses and specific types of validations and processing logic associated with each. While the domain model referred to a vague notion of an Address without flushing out a full entity, and the physical domain model was content with a single table housing the various details for all possible address, the development model may build an inheritance structure to accommodate business logic and simplify the implementation. We may define an object hierarchy similar to this:
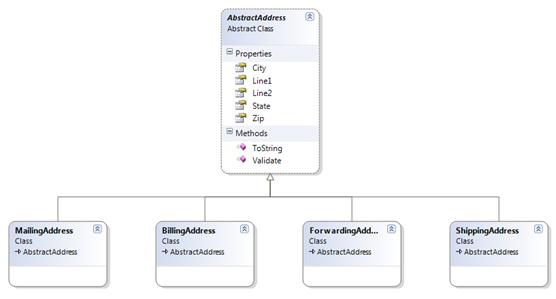
Such an inheritance hierarchy simplifies processing business logic without having to resort to a switch, or if statements, to use the proper implementation based on the type of address being used. We can simply instantiate the appropriate type based on the AddressType and call the method from the corresponding object.
So the domain model may only have a vague concept of an address with no additional details. The physical data model may have a centralized table with strongly typed columns, appropriate indexes, and foreign key constraints, and the development model may have a full inheritance hierarchy tracking the subtle nuances of the business logic. Each of these models is accurate and appropriate for their purposes. The domain model provided all the detail that it needed to, and the physical data model met the requirements and conformed to the limitations of a relational data model and leveraged the advantages of the relational data model. Each model has specific strengths and weaknesses. Each has specific goals and requirements. Each model will be unique.
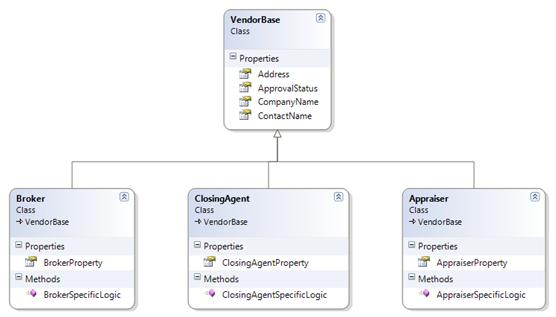
The data model may look at the domain entities and see the common fields shared between the Broker, Closing Agent, and Appraiser and decide that there should really be a common table to host the common fields, with separate tables for each entity to house the fields that are unique to each entity. The physical data model may also see the common fields and believe that all of the information can be stored in a single table, with a column for every attribute that any of these entities can have. It is also quite common for the data model to ignore these commonalities and provide a single table for each. For purposes of this article, let’s ignore the relative merits and weaknesses of these approaches and simply accept that each can happen.
The development model will most likely not ignore the commonalities, and has a single simple solution. We will define an inheritance hierarchy similar to the one shown. While the physical data model may not have a clear cut solution for how to represent this, we do have clear cut directions in our code. The common properties are easily at home in VendorBase. Common functionality can also easily find a home in VendorBase and not have to be duplicated in each derived class. If there are methods that we know each vendor will need but we have a different implementation for each type of vendor, we can still define the method in VendorBase but mark it as abstract (or mustoverride in VB). This will guarantee that each type of vendor provides an implementation for the method.
What Makes a Good Development Model
It is probably reasonable to conceptually start with a direct mapping from the data model. This is as good of a starting point as any. But we can follow a few guidelines to help play to the strengths of object oriented design.
Any time you see a Type field, such as AddressType, in the back of your mind, you should be thinking about differentiation through inheritance and look for an inheritance structure. This is what leads us to create a class for each address type.
Any time you see a table with fields that will not always be populated, think about inheritance with the optional fields being defined in a derived class.
Anytime you see a one to one relationship in the database, check to see if you have an opportunity for inheritance. Quite often the development model will benefit from including a derived class that includes properties from the other table.
These are guidelines and may not always hold up to close scrutiny, but they will usually warrant a closer look.
Development models will also generally have a split personality, or at least a split implementation. We will generally have two components and the less these two components know about each other the better. By this, I am referring to keeping the development model database agnostic.
Many people may argue the merits of keeping the development model completely ignorant of the database, and for good reason. Many of the arguments commonly used to support this stance talk about switching database vendors which will rarely happen for most people, but there are still compelling reasons for this approach. True, you may actually switch vendors; I have had to do this before. You may also need to switch from a database to making web service calls instead. I have also had to do this. There is also some merit for testing and demos if you can cut the actual database out of the loop all together.
Let’s consider what it takes for the development model to be database agnostic. First, do expose anything from the System.Data namespace. This means no DataSet, no DataTable, no DataReader, etc. In the past, I was less dogmatic about this and was OK exposing key interfaces from this namespace, but, allowing these interfaces still ties you to having a database somewhere. The approach we will outline here makes it relatively easy to switch to web services or static xml documents or mock objects, etc.
To get just a little bit more dogmatic, let’s further restrict to expose interfaces only and no classes. So if your development model has entities like Broker, ClosingAgent, and Appraiser, we will use interfaces like IBroker, IClosingAgent, and IAppraiser.
Why interfaces? They give us extra flexibility. Implementing business logic against interfaces means that any object implementing the interface can be used. This has some very nice implications for testing. It also allows us to develop and test the business logic without having a database connection. This can be useful to expedite development. You can start developing before you even have the database created. Once you have the interfaces defined, you are ready to implement business logic.
This also provides some exciting opportunities for giving software demos in isolation. Just as you can test the application using any object implementing the interfaces, you can also run the application with any object implementing these interfaces. It can be very useful to provide a series of objects implementing these interfaces pulling data from xml files. This way every time the application runs, you can be guaranteed to get the same results and you won’t have to worry about external influences on the database compromising the demonstration.
Pulling It All Together
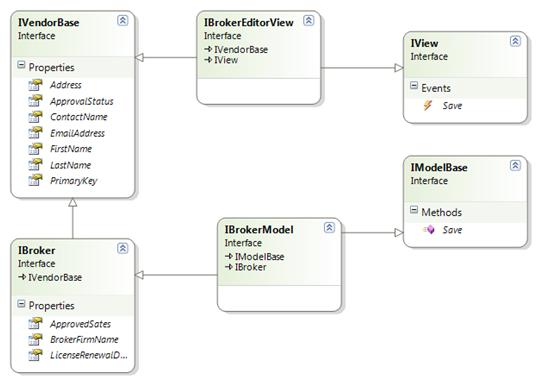
To follow data from Model through View, we can have both ends implement a common interface. For our Broker entity, these interfaces may look like this model. A couple of important thing to note are the use of base interfaces and the repeated use of IVendorBase. By using IBroker as the base interface for IBrokerModel and IBrokerEditorView we are guaranteed that every property will be available at both ends. By using the reflective data mapper outlined in an earlier article we are guaranteed to have every property mapped on both the save and data bind.
For the Presenter, which has both the View and the Model, saving and data binding is a simple straightforward operation.
MapData can handle mapping data from the model to the viewThe details lies in the View implementing simple properties that manipulate the UI.
|
1 2 3 4 5 6 7 8 9 |
/// <summary> /// Maps the data. /// </summary> /// <param id="model"">The model.</param> private void MapData(IModelBase model) { var mapper = new Mapper(); mapper.CopyTo(model, view ); } |
The save event raised by the view is equally straightforward:
|
1 2 3 4 5 6 7 8 9 10 |
private void View_Save(object sender, EventArgs e) { IBrokerModel model; if (view.PrimaryKey > 0) model = Model.Model.Load(view.PrimaryKey); else model = new Model.Model(); var mapper = new Mapper(); mapper.CopyTo(view, model); } |
Because the View exposes the Save event, the Presenter can wire up to it and handle the saving when the view raises the event.
|
1 2 3 4 5 6 7 8 9 10 |
public ProfilePresenter(IBrokerEditorView editorView) { view = editorView; view.Save += View_Save; if (view.PrimaryKey > 0) { IBrokerModel model = Model.Model.Load( view.PrimaryKey ); MapData(model); } } |
In the Page_Load event, the view can introduce itself to the presenter:
|
1 2 3 4 |
protected void Page_Load(object sender, EventArgs e) { ProfilePresenter presenter = new ProfilePresenter((IBrokerEditorView) this); } |
Alternately, if the View is implemented in a user control, then the introduction can take place in the containing page. Regardless, the view does not need to know anything about the presenter beyond this initial introduction. When it comes to raise the save event, the View is once again completely oblivious to the presenter:
|
1 2 3 4 5 6 7 |
protected void btnSave_Click(object sender, EventArgs e) { if (Save != null) { Save(this, e); } } |
All the View has to worry about is responding to UI events and interact with UI controls. The Business logic is implemented in the Presenter. The View does not have to worry about the business logic and the Presenter does not have to worry about the UI. Similarly, the Model handles interacting with the database or whatever persistence strategy is being followed. The Presenter does not have to worry about any of the mechanics of data persistence and retrieval, and the Model does not have to worry about the business logic stored in the Presenter.
Conclusion
Separating the layers and dividing the concerns results in multiple components that need to be implemented, but each component is relatively simple. Such separation also makes the application as a whole more resilient to change. Properly structured, the individual layers are separated through interfaces and shielded from changes in the other layers.
This is a great way to structure a web application. The resulting implementation can be spread over a larger team than would be practical without this separation. The final product will be more stable and easily maintained since each layer can be treated independently.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments