
It’s been said repeatedly more than a gazillion times: at some point data must be paged and served for display. In the beginning of web applications, paging was based on numeric indexes or based on relative positions (first, last, next and previous). Today, paging often comes in the form of just ‘show-me-more-data’, which boils down to unidirectional, forward-only navigation. In general, with the growing success of client-side intensive web applications you face two main paging alternatives:
- The client controls all of it, and asks the server for a given number of items in a given section of the data set. Each client (desktop, smartphone, tablet, smart TV) may be using different numbers, and requiring a different pace to paging;
- The client just delegates paging to the server, and the server provides a chunk of data, along with the total number of available items and maybe a link for asking more data;
Classic page-based navigation of Web Forms is still an option as long as you remain with Web Forms technology, and we leverage controls such as GridView or ListView. If you move to ASP.NET MVC while you can still manage to expose paging-enabled controller methods it is probably better to opt for one of the two paging models just introduced. Let’s see how to code them.
Paging Architecture
In the context of ASP.NET MVC, paging is a three-layer structure nowadays. Figure 1 attempts to illustrate this.
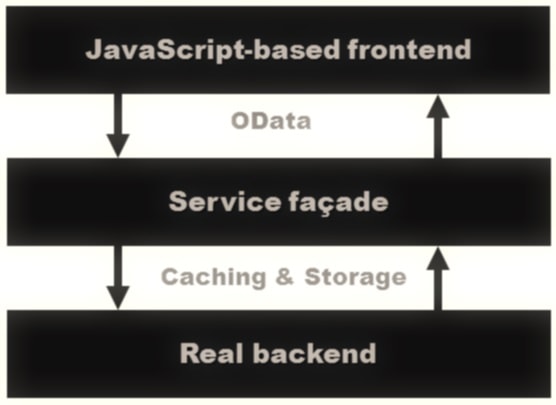
At the top, you’ll find a JavaScript-based frontend that is centered on plain jQuery code and/or some more sophisticated library such as BreezeJs or KnockoutJs. In the middle, you have a service façade mostly based on Web API. The communication between the frontend and the service façade is sometimes based on the OData protocol. Finally, there’s a third level which is where the data that we need to display really lives.
The block named “Real backend” in the figure is sometimes too hastily associated with a database behind an Entity Framework model. The backend where data is stored is likely to be a database, but it could be anything, including a memory database, a local or distributed cache or even a NoSQL store.
It is important to keep the ‘Domain model’ separate from the ‘View Model’. By ‘Domain model’, I mean the architecture of data that you use to implement the business logic and calculations. The ‘View Model’ is the architecture of the data that you expose to the outside world and let users occasionally page through.
So the purpose of this article is to discuss the most effective way of paging when providing the two commonest ways of browsing data. It turns out that you need to have some built-in logic to extract segments of data from the available data set; code that knows how to retrieve page N given a page size of M. You can still write this code yourself, but OData probably gives you better options, and more versatility.
The OData Protocol
Open Data Protocol (OData) is a data-access protocol designed to provide access to a data source via a web site in order to perform CRUD operations. Although the protocol was originally defined by Microsoft, it is now being standardized at OASIS. In the end, OData implements the same core idea as ODBC, except that it is not limited to SQL databases and lends itself to interesting uses over the web.
The protocol offers several URL-based options that users can choose in order to query for metadata, flat and hierarchical data, apply filters, sorting and, last but not least, paging. You might want to check http://www.odata.org for more information on both the protocol and the details about the syntax.
For example, consider the following URL:
/api/numbers?$top=20&$skip=10
OData defines the query string syntax in a standard way. This means that a server-side layer can be created to parse the query string out and plug into some server-side code that pages data. In ASP.NET MVC and Web API, this is just what the package System.Web.Http.OData attempts to do. It just contains a bunch of classes and facilities to create OData endpoints using ASP.NET Web API preferably, but not necessarily, on top of Entity Framework stores.
OData just seems to be the perfect fit to provide both of the paging options I mentioned earlier. You save yourself most of the coding effort when you use the Web API OData extension.
JavaScript Application Logic
Modern Web architectures tend to be fairly thick on the client side and they rely on a set of HTTP endpoints for interacting with the server. What is the kind of code that gets actually written in JavaScript and run from within the client browser? Sometimes I hear this code being qualified as business logic. However, to me this is just the code behind use-cases or, more likely, just the largest possible share of application logic required to implement application’s use-cases. The code therefore contains some orchestration logic, validation, simple calculations and refers to the backend for more complex things that pertain to the business domain such as algorithms, data models and persistence.
Generally speaking, a use-case is a screen displayed to the user that requires attention and may generate some interaction such as button clicking or item selection. To fully describe a use-case, you need at the very minimum a view model class that joins together all data that comes in and out of the screen. The JavaScript application logic is responsible for managing the view model class and for filling it up with data exposed from the service façade.
Here’s a sample view model class based on KnockoutJS.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
var NumbersViewModel = function () { var self = this; self.listOfNumbers = ko.observableArray([]); self.nextLink = ""; self.totalCount = ko.observable(0); self.addRows = function (items, nextLink, count) { for(var i=0; i<items.length; i++) self.listOfNumbers.push(items[i]); self.nextLink = nextLink; self.totalCount(count); }; self.next = function () { oDataApp.update(self.nextLink); }; self.perc = function () { return Math.round(100 * self.listOfNumbers().length / self.totalCount()); }); return self; }; |
The listOfNumbers property contains the data to page through and is marked as an observable array. In the KnockoutJS jargon it means that any time the property is updated the screen must be silently refreshed. The view model object features an addRows method through which new numbers are appended along with the current total number of pageable objects available on the server. The following code completes the JavaScript frontend for the sample page:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
var oDataApp = oDataApp || {}; oDataApp.viewModel = new NumbersViewModel(); oDataApp.initPage = function() { ko.applyBindings(oDataApp.viewModel); oDataApp.update("/api/numbers"); }; oDataApp.update = function (link) { $.getJSON(link, function (response) { oDataApp.viewModel.addRows( response.Items, response.NextPageLink, response.Count); }).error(function (jqXhr, textStatus, errorThrown) { // ... }); }; |
As you can see, a bit of jQuery downloads data from the service façade. The URL of the service endpoint is passed as an argument. That’s the trick to enable pagination via OData. The web page also contains the following script to fire things:
|
1 2 3 4 5 6 7 8 |
@section scripts { <script type="text/javascript" src="~/Content/Scripts/oDataApp.js"></script> <script type="text/javascript"> $(document).ready(function () { oDataApp.initPage(); }); </script> } |
From within method initPage, you call api/numbers which the Web API entry point in the service façade. Any time that you download OData from the endpoint, you get the URL to call for getting the next page and to keep on scrolling the page.
The Service Façade
At the end of the day, the paging facilities that the OData provides can be summarized by saying that the OData syntax for paging is properly handled by the infrastructure. All you need to do is making available a Get method that represents the whole data set.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
public class NumbersController : ApiController { private readonly NumberService _service = new NumberService(); private IEnumerable<Number> Data { get { return _service.GetData(); } } : } |
In our example, the exposed data are plain integer numbers just wrapped in a Number class.
|
1 2 3 4 |
public class Number { public int Value { get; set; } } |
The NumberService class is the worker class used to retrieve data from the backend and/or caching layer. The actual implementation of this class is not really important; let’s just say that this class represents the backend.
You can arrange your CRUD layer and put your own caching layer on top. In this case, you may save large chunks of the database in memory-whether a distributed cache or a plain in-memory database-and expose that content directly via IQueryable or just via IEnumerable.
All in all, I believe that a solution based on a caching layer is more general and also proves that you can really decouple the data store from client side pagination. In other words, regardless the actual format of saved data and domain model, you can always end up with a relational set of columns for the purposes of the user interface. And data to be consumed from the user interface may be aggregated from persisted data directly in memory or in a temporary table.
Put another way, there’s really no need for you to expose your entire data source over the web via OData. OData may be simply seen as a convenient way to consume data and easily page through it.
Exposing an OData Stream
When you create the Web API controller, all you need to do in order to effectively page through data is shown below:
|
1 2 3 4 5 |
[Queryable(PageSize = 10)] public IQueryable<Number> Get() { return Data.AsQueryable(); } |
The data you retrieved from the cache or the database has been turned into a queryable entity and the Web API infrastructure and the Queryable attribute filter it properly according to the parameters found on the requesting URL. Look again at the following URL:
/api/numbers?$top=20&$skip=10
The controller actually attempts to pick up the first twenty records after ten. The actual number of returned records, though, is also filtered by the PageSize parameter. In this particular case, the caller won’t get more than ten records regardless of how many were selected by the OData syntax. With the above syntax, the client only receives a plain JSON stream.
OData, though, allows you return a richer data stream with some additional paging information. To get this, though, you must change the implementation of the Get method as below:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
public PageResult<Number> Get(ODataQueryOptions<Number> options) { var settings = new ODataQuerySettings() { PageSize = 5 }; var results = options.ApplyTo(Data.AsQueryable(), settings); return new PageResult<Number>( results as IEnumerable<Number>, Request.GetNextPageLink(), Data.AsQueryable().Count()); } |
The parameter ODataQueryOptions is populated with any information discovered out of the URL care of the ASP.NET MVC model binding infrastructure. Results are processed and packaged in a PageResult<T> action result type. This result type adds a couple of extra information: the link to get the next page in the data source and the current total amount of data items available on the server. Here the sample JSON being returned.
|
1 2 3 4 5 |
{ "Items": [{"Value": 1}, {"Value": 2}, {"Value": 3}, {"Value": 4}, {"Value": 5}], "NextPageLink": "http://localhost:15223/api/numbers?$skip=5", "Count": 999 } |
Using this information, you can easily arrange client-side data binding via KnockoutJS. The figure below shows the page when the first five records have been downloaded.
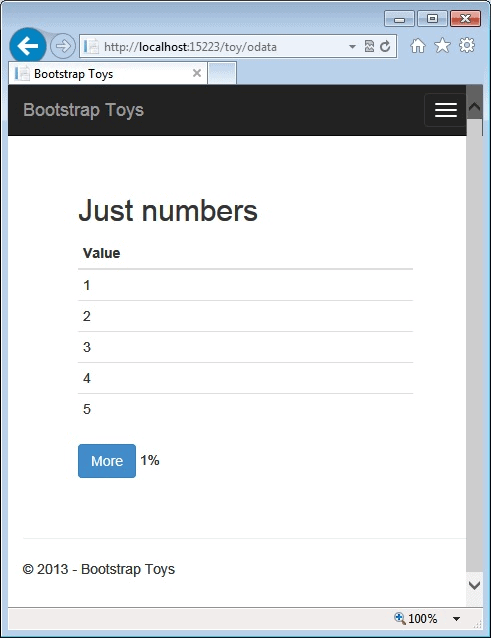
The More button displayed at the bottom of the table is bound to the URL carried by the NextPageLink field in the JSON stream. The Count field is used to arrange an observable data-binding field that shows the percentage of records currently displayed. Note that the percentage may vary during the pagination and even decrease. This may happen in case the server needs to retrieve more data directly from the database. KnockoutJS, however, ensures that the displayed percentage is constantly aligned with the total count of records returned from the service façade.
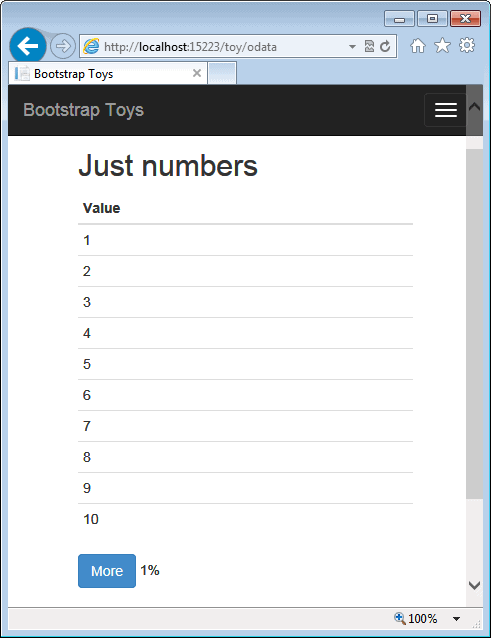
The power of the KnockoutJS library-whose code I presented earlier in the article-makes obtaining a forward-only pagination a walk in the park. You need no extra line except all those presented here to get a user interface like in the figure below.
Final Thoughts on Pagination
In the end, paging data relates to use-cases and use-cases relate to the user interface. It is key that you work out your backend to isolate and optimize the format of data to be queried from the client. In some cases, domain model is the same as view model. However, don’t expect that to be the norm; it has more of the novelty instead.
When it comes to paging, OData magically takes away a lot of coding by the trick of the Web API OData package. And it makes it transparent whether you build a client-intensive application or a plain server-based web site.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments