
Pre-Unicode
Younger programmers have grown up with ASCII and Unicode as the only ways of representing character data in a computer. But in the dark ages, before we invented dirt and entered into the stone age, there were other contenders.
The Control Data Corporation used a 6-bit binary scheme called Field Data. This was due to their hardware. Thanks to IBM’s dominance in the market at the time, punch cards were encoded with Hollerith and later their mainframes and mid-range computers used Extended Binary Coded Decimal Interchange Code (EBCDIC), an 8-bit scheme based off Hollerith. Unfortunately, there were three different versions of EBCDIC from IBM as well as some national code variations.
Back in the days of telegraphs, teletypes used Baudot (invented in the 1870’s) for their five channel paper tapes. (The inventor’s name is also where we get the term “baud” for transmission rates.) The coding scheme was improved a bit to become Murray code by 1901. One of the improvements was that the codes now included formatting codes, such as Carriage Return, Line Feed, Delete and so forth, which survived into the encoding schemes which came afterwards.
The debut of 7-bit ASCII in 1963 is where many programmers began learning programming. Mini-computers first used eight channel teletypes as their input device. Teletypes were relatively cheap and highly available back then.
Today, since computers have gotten smaller and less dominated by IBM, we use American Standard Code for Information Interchange (ASCII), which is a 7-bit character code. Each character is usually stored in one byte and the extra bit becomes a check digit or a way to shift to more ISO/IEC 8859 characters.
ISO/IEC 8859 was a joint ISO and IEC series of standards for 8-bit character encodings. The ISO working group for this standard has been disbanded. It’s job is now handled by Unicode. It was used for the accented letters in European languages that were based on the Latin alphabet. But coverage is not complete. For example, for compatibility, Dutch has been using “ij” as two letters in modern usage instead of one symbol. Likewise, in 2010, the Spanish Academy gave up “ch” and “ll” as separate letters for alphabetical order. (The term for these characters that tie two base characters together as one is a ligature. )
SQL added datatypes NATIONAL CHARACTER and NATIONAL VARYING CHARACTER. Nobody ever uses their full names, so we have NCHAR(n) and NVARCHAR(n) in our declarations. When we originally made this part of the language, there was no Unicode created yet, so they depended on whatever your implementation defined them as. It was assumed that this would depend on a national standards organization already having representations for the special characters they need for their language. We did not imagine it becoming as generalized as Unicode.
Unicode
The idea for Unicode began in 1988 and was formalized in 1991 in California. It was going to be a new character encoding under the name “Unicode”, sponsored by engineers at Xerox and Apple. The Unicode Consortium has more details on their website and today (2023 February) they are up to release 15.0.0 (and there is a 15.1.0 in draft mode).
Initially, academic, or political groups that had interest in obscure alphabets or writing systems made contributions to the character sets. Unicode 15.0.0 added 4489 characters, for a total of 149, 186 characters. These additions include 5 new scripts, for a total of 159 scripts, as well as 37 new emoji characters.
Today the big fights are about emoji symbols, and I have no idea why some of these characters are vital to data processing, but they are there!
Types of Characters
Characters can be broadly grouped into major categories: Letter, Mark, Number, Punctuation, Symbol, Separator and Other. The names pretty well explain themselves but do have more detailed definitions within each category. For example, letters are ordered by uppercase, lowercase, ligatures (such as æ and œ in English and French) containing uppercase, ligatures containing lowercase, and finally the lowest sort order, an ideograph (like a symbol in Chinese, for example) or a letter in a unicase alphabet. (Unicase alphabets only have one case instead of an upper and lowercase.)
This settles the question about how to handle upper and lowercase letters. It used to be that some correlations would put the lowercase version of a letter immediately after the uppercase version when setting up alphabetical order.
As a trivia question, can you name the alphabets which you do have a case system? We have Latin, Greek, Cyrillic and Arabic; the last one always surprises people, but letters have an initial form, a middle form (remember, it is a connected script), a terminal form and finally a standalone form.
Punctuation includes the underscore and dashes. The fun part comes with all the ways to make brackets. Brackets are considered part of punctuation, not math symbols.
Numbers include vulgar fractions (one number placed above another and a fraction bar, also known as a slash, like ½) and Roman numerals but do not include algebraic symbols. We also have problems with quote marks; do you do a separate open and close quote mark? Which pair do you use? Some Slavic languages prefer >> << and others use << >>.
This is just the beginning and it gets more complicated. For actual text, we still have a lot of legacy encoding systems in the typography business. Early adopters tended to use UCS-2 (the fixed-width two-byte precursor to UTF-16) and later moved to UTF-16 (the variable-width current standard), as this was the least disruptive way. The most widely used such system is Windows NT (and its descendants, 2000, XP, Vista, 7, 8, 10, and 11). Windows uses UTF-16 as the sole internal character encoding. The Java and .NET bytecode environments, macOS, and KDE also use it for internal representation. Partial support for Unicode can be installed on Windows 9x through the Microsoft Layer for Unicode.
For database people, the most important characteristic of Unicode is that all languages will support the simple Latin alphabet, digits, and a limited set of punctuation. The reason this is important is that ISO abbreviations for most units of measure and other standards use only these characters. This lets you insert them into the middle of the weirdest, most convoluted looking alphabets and symbol systems currently on earth, as well as mixing them in with emojis.
This also is a key concept if you ever must design an encoding system, don’t get fancy. Keep your encoding schemes in simple Latin letters and digits and use the “fancy stuff” for text.
Unicode Normalization
If you are old, you might remember a thing called a typewriter. It uses physical type to make images on paper by physically striking an inked ribbon. When we wanted a special character, we had to physically type the characters by either adding extra type elements to the machine (look at the IBM Selectric typewriter “golf balls” with special characters or before that, the Hammond multiplex) or use the backspace on these machines to create a single symbol.
Unicode came up with something like this. Despite the incredibly large range of symbols available to you, you can combine various diacritical marks and letters on top of each other. Without going into much detail, the Unicode standard gives four kinds of normalization. This means that I can put together string of Unicode characters, run them through an algorithm, and if they are equivalent, then I can reduce them to one single display character, or, at worst reduce them into a unique string of characters.
As an example, Å can be written in three ways in Unicode. The first to actually use the Å symbol as a letter of the Swedish alphabet (is your data Swedish?), use the symbol as the unit of measure (the angstrom is a unit of length that equals 0.1 nanometer), or build it from the pieces (uppercase A with a superior small circle accent, using zero spacing between two Unicode characters).
All three look the same when printed, but the first two have completely different meanings and the third is ambiguous, since it might be an attempt to go either of the first two ways.
Comparisons
The Unicode Standard defines two formal types of equivalence between characters when doing comparisons:
- Canonical means that equality characters or sequences of characters represent the same abstract character, and which when correctly displayed should always have the same visual appearance and behavior.
- Compatibility means that characters are not the same, but still mean the same thing.
For canonical equivalence, let’s consider Vietnamese on a menu at a restaurant (no, I do not read or speak Vietnamese). Their script was constructed for them by French missionaries, which is why it has a Latin alphabet as its basis. An individual letter can have several diacritical marks on it (marks above other characters that change the sound, such as the accent mark in fiancé), and the order that those marks are placed on the base letter don’t really matter; at the end of the construction, we get a single character regardless of the order in which it was constructed. You might have noticed, a pen has a much larger character set than your computer.
Korean, or Hangul as it is more properly called, is actually arranged from phonetic pieces in two dimensions to build syllables that are seen as single characters. The placement and the shape of the phonetic parts follow strict rules of organization. For example, in Hangul 가 is actually built from ᄀ +ᅡ. The leftmost unit changes shape. These two versions of 가 are considered canonically equivalent.
You can also pull a character apart. At one point, the use of ligatures was common in typesetting. For example, the “fi” ligature changes into its components “f” and “i”, and likewise for “ffl” , “ffi”, “st” and “ct” ligatures that were used mostly in the 1800s.
Compatibility equality is less strict and deals with characters that are close. For example, these two characters are not formally equal, but they are compatible with each other:
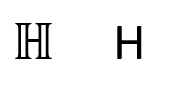
But wait! It gets even worse with mathematical notation. Just consider fractions; Is “1/4” the same thing as “¼”? The standard considers them compatible, but how many different ways are there to write logical operators? Comparison operators? Various mathematical societies have different typesetting standards, and it can get as bad as any written language.
For more details on this topic, check out this page on the Unicode.org website.
Normalization
Unicode Normalization Forms are formally defined normalizations of Unicode strings which make it possible to determine whether any two Unicode strings are semantically equivalent to each other. The goal of the Unicode Normalization Algorithm for database people Is to guarantee that Comparison operators and join operators, as well as SQL clauses like ORDER BY and GROUP BY will work without surprising users.
ANSI/ISO Standard SQL
Officially once you get into SQL, you can use statements to modify the collation character sets involved. I seriously doubt that many of you will ever use this in your career, as you are probably better off using whatever default you get with your SQL product. However, the more you understand what went into determining how collations are created the better. So, for the record, here are the statements from the CREATE COLLATION statement that some RDBMS’s provide (others, like SQL Server simply provide you thousands of choices.)
Where do accented letters fit in the collation? Some languages, put their accented letters at the end of the alphabet, and some put each letter after its unaccented form. When German was doing its spelling reforms, this was a big debate about whether the Umlaut-ed three letters made them separate letter the end of the alphabet or they were just different forms the base letter.
Esperanto puts its accented letters immediately after the unaccented form; ”a, b, c, ĉ, d…”; However, since the circumflex was not always available, Esperanto also has the convention of using the combination of a base letter followed by x; “a, b, c, cx, d..” Since the X is not used in the Esperanto alphabet.
Officially, in some SQL implementations you can change all of this at the database level and override the Unicode conventions. If you want to further mess up local language settings, you can also use a
|
1 2 3 |
CREATE CHARACTER SET < name of character set> AS < character set source> [<collation clause>] <character set source> ::= GET < character set specification>. |
Likewise, there is a CREATE COLLATION statement in the standard.
|
1 2 3 4 |
CREATE COLLATION <correlation name> FOR <Character set specification> < from existing correlation name> [< pad characteristic>] < pad characteristic> ::= NO PAD | PAD SPACE |
The pad characteristic that has to do with how strings are compared to each other. This is based on SQL versus the xBase language conventions. NO PAD follows the xBase convention of truncating the longer string before doing the comparison. The PAD SPACE option pads the shorter string with spaces and then begins comparing the strings character by character from left to right. This is the default in SQL.
Normalization
Unicode Normalization Forms are formally defined normalizations of Unicode strings which make it possible to determine whether any two Unicode strings are equivalent to each other. Depending on the particular Unicode Normalization Form, that equivalence The goal of the Unicode Normalization Algorithm For database people Is to guarantee that SQL clauses ORDER BY and GROUP BY will actually work without surprising us.
The two most common emoticon combinations were probably “:-)” and “:-(“. These conventions existed in the West and assumed that the reader would turn the line 90° to read it. Japanese users at the time, laid things out horizontally. Emojis evolved from these text based character expressions, but are actually cartoon figures.
There currently are over 800 different emojis and these are sent over 6 billion times a day through Facebook. According to Google, over 90 percent of the world’s population uses emojis and the most popular emoji employed on both Facebook and Twitter is the ‘laugh cry’ face. This makes me fear the literacy level among computer people.
General Advice on Handling Languages in Data Bases
There is a safety rule in life that says: “do not get tattoos in a languages in which you are not fluent.” This rule also applies to databases and text documents. Many years ago, a Canadian Sunday newspaper ran an article on Chinese tattoos that non-Chinese speakers got. What they actually said were things like “this cheap bastard does not tip tattoo artist” And worse. Perhaps you should find someone who does speak the language fluently and asked him to check what’s going into your database. Even if it isn’t obscene or absurd, it still may not be what you meant to put into the database.
Try to keep things as simple as possible and use a minimal character set. You will want to move your data from one platform to another. The days of a one vendor shop have been over for decades.
Remember that SQL is based on a tiered architecture. That means you don’t know when a new kind of presentation layer is going to be added to your database. In a serious application, the worst thing you can do is write SQL that is totally dependent on one release of one product from one vendor. Clean, simple, and portable are good.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments