
Dr. Codd first described the relational model in a paper in Communications of the ACM (CACM 13 No 6; June 1970). Some more work followed up after that by other people, giving us normal forms and other things we have taken for granted for 50+ years.
I was looking at some postings on a SQL newsgroup. The original poster wanted help with a problem he had storing International Classification of Diseases (ICD) values. Alternatively, to put it more accurately, he needed help fixing the problems he had created for himself. The non-table he was creating had a single text column that concatenated exactly four ICD codes.
Without going into much detail,
these are codes used by hospitals, insurance companies, and other places where we need a “Dewey decimal of death and despair” for reporting. They are a mixture of alpha and numeric characters, with minimum punctuation. It should come as no surprise because that is the standard format for many ISO standards. Thanks to Unicode, this limited set of symbols can be used with any alphabet or symbol system allowed in Unicode. The following regex pattern would match 2021 ICD-10-CM codes:
^(?i:[A-TV-Z][0-9][0-9AB](?:\.[0-9A-KXZ](?:[0-9A-EXYZ](?:[0-9A-HX][0-59A-HJKMNP-S]?)?)?)?|U07(?:\.[01])?)$
In English, ICD-10-CM codes consist of 3 to 7 alpha-numeric characters (case-insensitive), and codes longer than three characters have a decimal point between the third and the fourth character [1], e.g., “E11.9” represents Type 2 diabetes mellitus without complications. A list of ICD-10-CM codes can be found in the file icd10cm_order_YEAR.txt available at the CDC ICD-10-CM web page (https://www.cdc.gov/nchs/icd/Comprehensive-Listing-of-ICD-10-CM-Files.htm). This file’s 7th to 13th characters (the 2nd column) correspond to the 1st to 7th characters of ICD-10-CM codes.
You do not need a complete understanding of regular expressions or ICD codes to follow this article, so don’t worry too much about it. The reason for posting the simplified regular expression was to scare you. My point was that this regular expression would be a pretty impressive CHECK constraint on this column. Shall we be honest? Despite the fact that we know the best programming practice is to detect an error as soon as possible, do you believe that the original poster wrote such a constraint for the concatenated list of ICD codes?
I’m willing to bet that any such validation is being done in an input tier by some poor lonely program, in an application language. Even more likely, it’s not being done at all.
First Normal Form (1NF) says that this concatenated string is a repeated group, and we need to replace it with a proper relational construct. However, instead of getting some help on how to do it right, people posted various bits of code to slice up the original string! This is akin to the old engineering joke, “Don’t force it!; Get a bigger hammer!” This attitude is wrong in so many ways.
Problem 1: Validation
I’ve already hit on the first problem of Non-First Normal Form (NFNF) data; it is simply complicated. In the SQL standards, a “field” is defined as a part of a column that has some meaning by itself but is not a complete attribute. The classic example is that a date breaks down into (year, month, day) fields, and a timestamp breaks down into (year, month, day, hour, minute, seconds). You get the fields out of temporal datatypes with a statement like EXTRACT(<field name> FROM <temporal expression>), or in SQL Server DATEPART. Unfortunately, if you’re going to split up a NFNF column, you have to do all the work yourself.
Problem 2: Permutations & Combinations
SQL and the relational model are based on sets and not sequences. This means that (A, B, C) should be the same as (C, A, B) or any of the other six possible permutations. The original problem, the poster wanted to require four ICD codes crammed in the column. That means we have 4! = 24 permutations. Suddenly, a simple, equi-join is growing exponentially. One way around this would be to sort the fields within each string. This adds a little extra overhead and requires any change to a string to be recomputed. Think about an algorithm for finding all patients with a particular diagnosis. It might not be their primary diagnosis, so we must do a little scanning. This is sliding us back into the world of COBOL string-oriented data processing.
This poster made things even worse. He wanted the most severe diagnosis to appear first in the list. This means we are dealing with a combination and not a permutation. Hence, (A, B, C) <> (C, A, B), which makes comparisons and ordering a good bit harder. Now we need a process for raising the diagnosis. Unfortunately, it’s going to be rather individualized. We can probably all agree that being sucked through a jet engine is a severe medical problem. After that, is mild diabetes more of a problem than high blood pressure? It depends on the patient and the associated medical history. Since we were supposed to come up with four diagnoses, what if the only thing wrong with the patient was being sucked through a jet engine? Do we make up three more conditions? Create a dummy diagnosis. Repeat the jet engine diagnosis three times?
Problem 3: Nesting Table Structures
Programming languages have had a formal basis, such as FORTRAN being based on Algebra, LISP on list processing, etc. Data and databases did not get “academic legitimacy” until Dr. Codd invented his relational algebra. It had everything academics love—a set of math symbols, including new ones that would drive the typesetters crazy. However, it also had axioms, thanks to Dr. Armstrong. (https://en.wikipedia.org/wiki/Armstrong%27s_axioms)
The immediate result was a burst of papers using Dr. Codd’s relational algebra. However, the next step for a modern academic is to change or drop one of the axioms to see that you can still have a consistent formal system. In geometry, change the parallel axiom (parallel lines never meet) to something else. For example, the replacement axiom is that two parallel lines (great circles) meet at two points on the surface of a sphere. Spheres are real. Furthermore, we could test the new geometry with a real-world model.
Since 1NF is the basis for RDBMS, it was the one academics played with first. And we have real multi-valued databases to see if it works. Most of the academic work was done by Jaeschke and Schek at IBM and Roth, Korth, and Silberschatz at the University of Texas, Austin. They added new operators to the relational algebra and calculus to handle “nested relations” while keeping the relational model’s abstract set-oriented nature. 1NF is inconvenient for handling data with complex internal structures, such as computer-aided design and manufacturing (CAD/CAM). These applications have to handle structured entities, while the 1NF table only allows atomic values for attributes.
Non-first normal form (NFNF) databases allow a column in a table to hold nested relations and break the rule about a column only containing scalar values drawn from a known domain. In addition to NFNF, these databases are also called 2NF, NF2, and ¬NF in the literature. Since they are not part of the ANSI/ISO standards, you will find different proprietary implementations and academic notations for their operations.
Consider a simple example of employees and their children. On a normalized schema, the employees would be in one table, and their children would be in a second table that references the parent:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE Personnel (emp_name VARCHAR(20) NOT NULL PRIMARY KEY, ..); CREATE TABLE Dependents (dependent_name VARCHAR(20) NOT NULL PRIMARY KEY, emp_name VARCHAR(20) NOT NULL REFERENCES Personnel(emp_name)--- DRI actions ON UPDATE CASCADE ON DELETE CASCADE, ..); |
But in an NFNF schema, the dependents would be in a column with a table type, perhaps something like this:
|
1 2 3 4 5 6 7 8 |
CREATE NF TABLE Personnel (emp_name VARCHAR(20) NOT NULL PRIMARY KEY, dependents TABLE (dependent_name VARCHAR(20) NOT NULL PRIMARY KEY, emp_name VARCHAR(20) NOT NULL, ..), ..); |
Which would make for a set of data that you might diagram as:
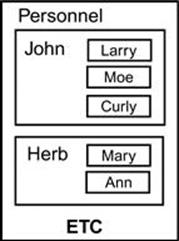
We can naturally extend the basic set operators UNION, INTERSECTION, and DIFFERENCE and subsets. Extending the relational operations is also relatively easy for PROJECTION and SELECTION. The JOIN operators are a bit harder, but limiting your algebra to the natural or equijoin makes life easier. The important characteristic is that when these extended relational operations are used on flat tables, they behave like the original relational operations.
To transform this NFNF table back into a 1NF schema, you would use an UNNEST operator. The unnesting, in this case, would make Dependents into its own table and remove it from Personnel. Although UNNEST is the mathematical inverse to NEST, the operator NEST is not always the mathematical inverse of UNNEST operations. Let’s start with a simple, abstract nested table:
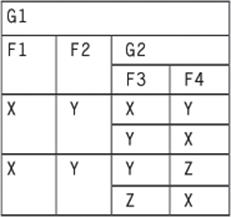
The UNNEST(<subtable>) operation will “flatten” a sub-table up one level in the nesting:
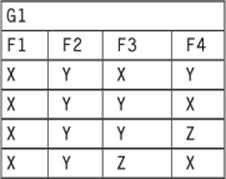
The NEST operation requires a new table name and its columns as a parameter. This is the extended SQL declaration:
|
1 |
NEST (G1, G2(F3, F4)) |
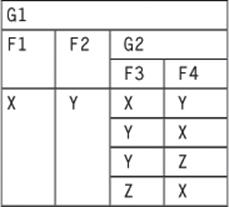
It fails when we try to “re-nest” this step back to the original table.
There is also the question of how to order the nesting. We put the dependents inside the Personnel table in the first example. Children are weak entities; they have to have a parent (a strong entity) to exist. However, we could have nested the parents inside the dependents. The problem is that NEST() does not commute. An operation is commutative when (A ☉ B) = (B ☉ A), if you forgot your high school algebra. Let’s start with a simple flat table:
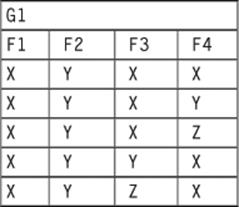
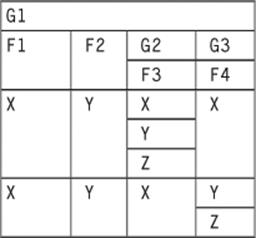
Now, we do two nestlings to create sub-tables G2, which is the F3 column and G3, which is the F4 column. First in this order:
|
1 |
NEST(NEST (G1, G2(F3)), G3(F4)) |
Now in the opposite order:
NEST(NEST (G1, G3(F3)), G2(F4))
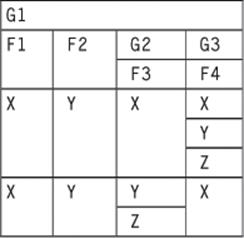
The next question is how to handle missing data. What if Herb’s daughter Mary is lactose-intolerant and has no favorite ice cream flavor in the Personnel table example? The usual NFNF model will require explicit markers instead of a generic missing value.
Another constraint required is for the operators to be objective, which is covered by the partitioned normal form (PNF). This normal form cannot have empty sub-tables and operations have to be reversible. A relation in PNF is such that its atomic attributes are a super-key of the relation and that any non-atomic component of a tuple of the relation is also in PNF.
Why This Occurs
OCCURS is literally the reason this occurs. COBOL has a clause in its DATA DIVISION with that keyword which indicates a sub-record. I will assume most of the readers do not know COBOL. The super-quick explanation is that the COBOL DATA DIVISION is like the DDL in SQL, but the data is kept in strings that have a picture (PIC) clause that shows their display format. In COBOL, display and storage formats are the same. The records and fields in COBOL are very physical, unlike the rows and columns of SQL, which are abstract and virtual.
Records are made of a hierarchy of fields, and the nesting level is shown as an integer at the start of each declaration (numbers increase with depth; the convention is to step by fives). Suppose you wanted to store your monthly sales figures for the year. You could define 12 fields, one for each month, like this:
|
1 2 3 4 5 |
05 MONTHLY-SALES-1 PIC S9(5)V99. 05 MONTHLY-SALES-2 PIC S9(5)V99. 05 MONTHLY-SALES-3 PIC S9(5)V99. ... 05 MONTHLY-SALES-12 PIC S9(5)V99. |
The dash is like an SQL underscore, a period is like a semicolon in SQL, and the picture tells us that each sales amount has a sign, up to five digits for dollars and two digits for cents. You can specify the field once and declare that it repeats 12 times with the simple OCCURS clause, like this:
|
1 |
05 MONTHLY-SALES OCCURS 12 TIMES PIC S9(5)V99. |
The individual fields are referenced in COBOL by using subscripts, such as MONTHLY–SALES(1). The OCCURS can also be at the group level, and this is its most useful application. For example, all 25-line items on an invoice (75 fields) could be held in this group:
|
1 2 3 4 |
05 LINE-ITEMS OCCURS 25 TIMES. 10 ITEM-QUANTITY PIC 9999. 10 ITEM-DESCRIPTION PIC X(30). 10 UNIT-PRICE PIC S9(5)V99. |
Notice the OCCURS is listed at the group level, so the entire group occurs 25 times.
There can be nested OCCURS. Suppose we stock ten products and we want to keep a record of the monthly sales of each product for the past 12 months:
|
1 2 3 |
01 INVENTORY-RECORD. 05 INVENTORY-ITEM OCCURS 10 TIMES. 10 MONTHLY-SALES OCCURS 12 TIMES PIC 999. |
In this case, INVENTORY-ITEM is a group composed only of MONTHLY-SALES, which occurs 12 times for each occurrence of an inventory item. This gives an array of 10 × 12 fields. The only information in this record is the 120 monthly sales figures—12 months for each of 10 items.
Notice that OCCURS defines an array of known size. However, because COBOL is a file system language, it reads fields in records from left to right. Since there is no NULL, inserting future values that are not yet known requires some coding tricks. The language has the OCCURS DEPENDING ON option. The computer reads an integer control field and then expects to find that many occurrences of a sub-record following at runtime. Yes, this can get messy and complicated, but look at this simple patient medical treatment history record to get an idea of the possibilities:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
01 PATIENT-TREATMENTS. 05 PATIENT-NAME PIC X(30). 05 PATIENT-NUMBER PIC 9(9). 05 TREATMENT-COUNT PIC 99 COMP-3. 05 TREATMENT-HISTORY OCCURS 0 TO 50 TIMES DEPENDING ON TREATMENT-COUNT INDEXED BY TREATMENT-POINTER. 10 TREATMENT-DATE. 15 TREATMENT-YEAR PIC 9999. 15 TREATMENT-MONTH PIC 99. 15 TREATMENT-DAY PIC 99. 10 TREATING-PHYSICIAN-NAME PIC X(30). 10 TREATMENT-CODE PIC 999. |
The TREATMENT-COUNT has to be handled in the applications to correctly describe the TREATMENT-HISTORY subrecords. I will not explain COMP-3 (a data type for computations) or the INDEXED BY clause (array index), since they are not important to my point.
My point is that we had been thinking of data in arrays of nested structures before the relational model. We just had not separated data from computations and presentation layers, nor were we looking for an abstract model of computing yet.
SIDEBAR:
When I described ICD codes as the Dewey decimal of death and despair, I probably should’ve also mentioned that they can be absurd. Here’s a list of the 20 strangest codes in the system. The phrase “subsequent encounter” means it has happened more than once to the patient. I am not sure how you can be sucked into jet engine more than once, but we have a code for it.
1. W220.2XD: Walked into lamppost, subsequent encounter
2. W61.33: Pecked by a chicken
3. W61.62XD: Struck by duck, subsequent encounter
4. W55.41XA: Bitten by pig, initial encounter
5. W59.22XA: Struck By turtle
6. R46.1: Bizarre personal appearance
7. Z63.1: Problems in relationship with in-laws
8. V97.33XD: Sucked into jet engine, subsequent encounter
9. R15.2: Fecal urgency
10.Y92.253: Opera house as the place of occurrence of the external cause
11.V9135XA: Hit or struck by falling object due to accident to canoe or kayak
12. X52: Prolonged stay in weightless environment
13.V94810: Civilian watercraft involved in water transport accident with military watercraft
14.Y92241: Hurt at the library
15. Y92.146: Swimming-pool of prison as the place of occurrence of the external cause
16. Y93.D1: Stabbed while crocheting
17. S10.87XA: Other superficial bite of other specified part of neck, initial encounter
18. Y93.D: V91.07XD: Burn due to water-skis on fire, subsequent encounter
19. V00.01XD: Pedestrian on foot injured in collision with roller-skater, subsequent encounter
20. W22.02XD: V95.43XS: Spacecraft collision injuring occupant
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments