
The Find/Replace feature of SQL Server Management Studio (SSMS) supports Regular Expressions. ‘Nice,’ you will think ‘This will be very handy for those refactoring jobs that would otherwise require programmers’ editor.’ Because you know that SSMS is a .NET application, you’ll imagine that it uses the lovely Regular Expression library that is within .NET. Actually, it doesn’t. It uses a quirky implementation of regular expressions, with unusual syntax, and few advanced features.
Here it is being used in SSMS.
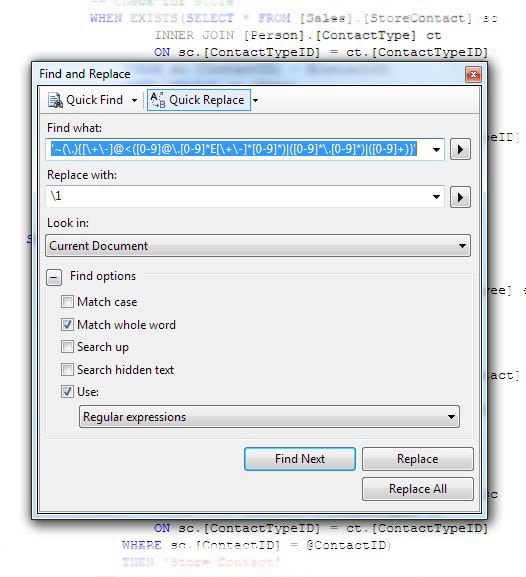
It is Microsoft’s standard RegEx implementation for Find/Replace in its applications. It comes from way back before Microsoft paid so much heed to industry standards. The same code is used in Visual Studio, even the completely re-written VS2010. It is very oddball syntax, and comes originally from Visual C++ 2.0. For some reason it was also used in Microsoft FrontPage and Expression Web too. The determination of Microsoft to maintain compatibility with Visual C++ Studio is one of the abiding mysteries of Windows. We were promised a change in VS2005, but it never happened. It has reappeared in VS2010, and so is likely to be there once again in the replacement for SSMS.
So is it any use?
Even though it is odd, and lacks some of the features one expects, it is still very handy, particularly if you have a few RegEx favourites squirreled away. Although it is definitely possible to type RegEx strings directly into the Find Box and have them work perfectly, a library of RegEx strings can save a lot of time for routine tidying up of SQL code, or formatting the results. Formatting results? Yes, the results in the result pane can quickly be turned into HTML or SQL Insertion code using a RegEx search and replace, though this is often easiest done in a more specialised programmers’ text editor.
The oddest quirk of the find/Replace Regex is the use of curly brackets to denote a capturing group. (e.g. {1}{2} ) Microsoft confusingly calls these ‘tagged groups’. You’ll notice that minimum and maximum ranges aren’t supported for quantifiers; there is no positive look-ahead or look-behind assertion. There seem to be no mode modifiers. There are a whole lot of character classes that are non-standard and some extra ones. For example ‘:q‘ matches both ‘single’ and “double” quotes, ‘:i‘ matches C/C++ identifiers. Hmm. Not much help to SQL coders. You can get around some of these problems. ‘Prevent match’ can be used as a poor-man’s negative look-ahead and negative look-behind. (you can do a sort of positive look-around too) You can specify ranges, but only if they are very narrow, via a tortuous work-around where you have to specify every valid count.
Another quirk of the RegEx ‘Find’ is that its method of traversing is different from a ‘Replace All’ in that it will Find strings that are part of strings that have previously been found: By contrast, it will never replace part of a string that has already been replaced. The Find Next button will search character-by-character from the current caret location rather than walk in the same way as a RegEx which will proceed from the end of the previous match, not counting the look around. This has caused a lot of confusion.
Why should these incompatibilities matter? Surely, it is just a matter of learning the new dialect? Well, when one is working in different dialects of RegEx, it makes life doubly awkward. I find that I have to constantly look up the equivalents in a chart to make progress in creating RegEx strings. Imagine having to do a lot of RegEx work using the .NET RegEx library, or JavaScript, and then have to use a different dialect of RegEx when searching for, or replacing stuff!
Find and Replace Regular Expression Examples
Before we start explaining RegEx in detail, let’s run through a few typical Search and Replace operations that can use regular expressions.
To take out blank lines (as when you import code from Firefox sometimes) find
\n @\n … and replace with \n
To find all instances of INT that aren’t commented out try
^~(:b*--).*:bINT> (this is an example of a good use for a negative look-behind to check that the line isn’t commented)
To select up to the first hundred characters in a line
^(.^100)|(.*) This will try to select 100 characters from the start of the line, and only if it fails, it will select all of them.
To insert a string at a particular column position
^{.^100} And replace with… \1'I've inserted this'(or whatever!) This simply matches a line with 100 characters and replaces the first hundred characters with the first hundred characters plus the string you want to insert.
To delete ten columns after column 100 use this
^{(.^100)}{.^10} Replace with \1What would happen if you used \2\1? Yeah. Useful once in a while!
To find either a quoted string or a delimited string, use
("[^"]*")|(\[[^\[]*\])
To replace all quoted strings with quoted delimiters, find
("{[^"]*}") … and replace with \[\1\]This shows how to create a capturing group using {}, and use it in the replace expression. It can also be used in the find expression.
To remove inline comments that take the whole line, find
^:b*--.*$ … and replace with nothingHere, we are using a greedy quantifier * to find the entire comment line (line starting with –).
To find any valid object name with delimiters
\[{[A-Za-z_#@][A-Za-z0-9#$@_]*}\] to take out the quoted delimiters [ and ] where they aren’t necessary, replace with \1This illustrates the use of character class definitions to determine whether the delimited strings contains only characters that are valid in a SQL identifier.
To find ‘tibbling’ (use of tbl, vw, fn, or usp prefixes) use this
<(tbl|vw|fn|usp)[A-Za-z0-9#$@_]*> Here we show one of the most useful of constructs, where alternative strings to search for are listed. It also shows how the special < and > characters are used to delimit the start and end of a word.
to de-tibblize code, us this
<(tbl|vw|fn|usp){[A-Za-z0-9#$@_]*}> … and replace with … \1 Here we add a capturing group (Microsoft calls them tags) to capture the word without the tibblizing prefix. (add your own to taste!)
to match any word at least 3 characters long, you can use
<:c^3:c*> This is one of the workarounds for the lack of proper range quantifying. It is the equivalent of {n,} in normal RegEx
To find multi-line comments using /* */ use this
/\*(:Wh|[^:Wh])*\*/ Normally, RegEx strings will stop searching at the end of the line if you use the standard wildcard. This RegEx uses a trick to get around that.
To find a Title-cased word (word starting with a capital letter followed by lowercase)
<:Lu:Ll[a-zA-Z0-9_$]*> Microsoft have some convenient shorthand characters to represent character classes. Here we illustrate their use with the :Lu:LI
To take out the headers that SMO puts in like /****** Object: StoredProcedure [dbo].[uspGetBillOfMaterials] Script Date: 01/07/2011 19:03:05 ******/ find this,
/[\*]^6.*[\*]^6/ replace with nothingThis shows the simplest quantifier. We use the [\*]^6 to represent six stars ******
To comment out lines, select the lines, Make sure you have ‘Look in selection’ and find
^ replace with --
To un-comment out lines, select the lines, Make sure you have ‘Look in selection’ and find
^:b*--{.*}$ replace with \1
To find two words separated by up to three words (in this case FROM and AS) use
<FROM(([^:a]+[:a]+)^1|([^:a]+[:a]+)^2|([^:a]+[:a]+)^3)[^:a]+AS> With normal syntax, you’d use \b FROM (?:\W+\w+){1,3}?\W+AS\b but we have no range quantifiers, so we are forced to use the ascending alternatives (descending if we want to be greedy rather than lazy). This becomes ridiculous if we want to specify the quantifiers for a complex expression. We’d have to duplicate the long expression.
To find the first object that is referenced by a FROM clause (doesn’t successfully avoid strings or multiline comments), use
^~(:b*--.*)<FROM>{(:Wh|[^:Wh])#}<(ON|CROSS|RIGHT|INNER|OUTER|LEFT|JOIN|WHERE|ORDER|GROUP|AS)> Here you have something that is looking for a whole lot of different alternative keywords merely by grouping them and using the | character to .
To find either an integer or a floating point number, one can use the following RegEx which is a bit long but simple in structure
~(\.)<([\+\-]@[0-9]@\.[0-9]*E[\+\-]*[0-9]*)|([\+\-]@[0-9]*\.[0-9]*)|([\+\-]@[0-9]+) This starts at a word boundary that is not preceded by a dot. It first looks for a floating point number in exponential notation. then it looks for a number in conventional notation before finally trying for an integer.
The negative lookahead and negative lookbehind
The idea of look-ahead and look-behind is slightly hard to understand. The object of the mechanism is to do be able to specify what shouldn’t or should be next to the string you are trying to match, without including the characters you look at in the match. If you are ‘replacing all’, you may want to include what you’ve looked at ahead in the next match. You could well want to look behind at things that have already been inspected in a RegEx for a match. Using the Find/Replace RegEx syntax, we can get somewhere close to a ‘negative’ check with a ‘prevent match’; in other words we can specify what should not precede, or follow, the match, but we can’t say what should do so, even with a double negative. If, for example, you are searching for words in the AdventureWorks database, you’ll have the word HumanResources appearing a great deal.
~(Human)Resources finds the word ‘Resources’, but not when immediately preceded by ‘human’ (negative lookbehind)
Human~(Resources) finds the word Human, but not when immediately followed by ‘resources’ (negative lookbehind)
~(:b)Resources finds the word Resources when not preceded by whitespace
but the expression cannot, it seems, be persuaded to find a positive lookaround. There are plenty of times that you’d want this. An example is using RegEx strings to tidy up a block of DECLARE statements into a single list, or if you want to select a range of characters based on column number
Constructing a RegEx for SSMS or VS search/Replace
I find the best approach to constructing a RegEx is to create some test data first that will thoroughly exercise the RegEx you want to create. I create a new query window, and rely on the history feature of the ‘Find What’ combo box and the ‘aide Memoir’ window reached by the arrow key to the right-hand side of it.
Start simple, and don’t be afraid of jettisoning what you try in favor of a different approach. Whatever you try is kept so you can return to it (I use AceText as well, so as to give me a long-term memory of what I’ve tried.) Build up the RegEx strings gradually, trying them out with every iteration. After a while, you will be able to ‘read’ RegEx strings as if you were using a RegEx IDE such as RegExBuddy (I’d use that if only it understood the quirky syntax of Microsoft’s search/replace RegEx.) Keep your old RegEx strings for re-use. RegEx strings are one of those snippets that are well-worth keeping.
Don’t be tempted to be clever with RegEx strings. I’m quite content to take a simple lumbering approach to the way RegEx strings work, though it may not impress many bearded developers in baggy jumpers, bottle glasses and sandals.
Taking things in stages.
For more complex tasks such as marking up code to colorize it, for creating tables from results, or for creating insert statements, it is often quicker and more maintainable to run several RegEx replacements in a particular order to achieve what you want. Let’s take a worked example.
Imagine we want to turn a result into a SELECT statement that returns a table. (it could use multi-row VALUES though there is a row limit) Our example will be short, but you’re likely to tackle much bigger results that are impossible to do by hand.
In AdventureWorks, open a query window. Set the Query -> Results to -> Text. Click on the Query -> ‘Query options…’, Click on Results Text in the tree on the left and set the dropdown box at the top right of the form to Tab Delimited. Click on the ‘include column headers in the result set’ optionbox so that it is UNTICKED.
Run this…
|
1 2 3 |
SELECT ErrorLogID, ErrorTime, UserName, ErrorNumber, ErrorSeverity, ErrorState, ErrorProcedure, ErrorLine FROM ErrorLog |
Click on the result pane to get focus
|
Find What |
Replace With |
Explanation |
|---|---|---|
^[^\t]*$ |
|
Take out all the rows that aren’t part of the result (rows without tabs) |
($)|(\t)|(^) |
',' |
replace all tabs, with the |
'~(\.){[\+\-]@<([0-9]@\.[0-9]*E[\+\-]*[0-9]*)|([0-9]*\.[0-9]*)|([0-9]+)}' |
\1 |
Strip off unnecessary quotes around numbers |
^', |
UNION SELECT |
Put the SQL statement you want at the start of the string |
,'$ |
|
Finish off the end of each line by deleting the last |
Then nick out the initial ‘UNION’, and you are left with…
|
1 2 3 4 5 |
SELECT 1,'2010-07-09 09:42:34.853','dbo',547,16,0,'uspUpdateEmployeeLogin',15 UNION SELECT 2,'2010-07-09 09:42:55.497','dbo',547,16,0,'uspUpdateEmployeeLogin',15 UNION SELECT 3,'2010-07-09 09:58:31.120','dbo',547,16,0,'uspUpdateEmployeeLogin',15 UNION SELECT 4,'2010-07-09 12:12:20.757','dbo',547,16,0,'uspUpdateEmployeeLogin',15 UNION SELECT 5,'2010-07-10 22:30:41.567','dbo',547,16,0,'uspUpdateEmployeeLogin',15 |
Of course, if you have strings with single-quote marks in, you’ll have to double them by replacing ‘ with ”, but otherwise, you’re done.
Feature Comparison with standard RegEx
Key |
| The same as standard RegEx |
| different symbol or syntax; |
| Missing from Search/Replace |
Here we list out the components of the Find/Replace Regex and compare each with the equivalent in standard Regex. If the two are the same, the background is in white. If the tw are different but the functionality is pretty well the same then the background is light gray, otherwise it is silver (see the key on the left)
|
Standard |
VS and SSMS |
Examples |
Meaning |
Metacharacters outside square brackets |
|||
|
|
|
|
general escape character (the next character as either a special character, a literal, a backreference, or an octal escape.) only [\^$.|?*+() have special meanings and have to be escaped |
|
|
|
|
assert start of string (or line, in multiline mode) |
|
|
|
GO$ finds GO at the end of a line |
assert (anchors) to end of string (or line, in multiline mode) |
|
|
|
|
match any character except newline (by default) |
|
|
|
|
start character class definition These definitions are by default case sensitive |
|
|
|
|
End character class definition |
|
|
|
|
start of alternative branch (the OR or PIPI operator) |
|
|
|
|
start sub-pattern |
|
|
|
|
end sub-pattern |
|
|
Extends the meaning of ( – is also used as a quantifier |
||
Quantifiers |
|||
|
|
0 or 1 . Can also mean ‘quantifier minimizer’ Also used after a bracket to extend its meaning |
||
|
|
|
0 or more -greedy |
|
|
|
+ |
1 or more -greedy (also “possessive quantifier”) |
|
|
|
lazy zero or one |
||
|
|
|
|
lazy zero or more (matches as few as possible) |
|
+? |
|
lazy one or more |
|
|
|
^n |
|
N is a positive integer. Matches exactly n times. |
|
|
N is positive integer. Matches at least n times. |
||
|
|
Range specifier. M and n are positive integers, where n <= m. Matches at least n and at most m times. |
||
|
|
When this character immediately follows any of the other quantifiers (*, +, ?, {n}, {n,}, {n,m}), this specifies that the matching pattern is lazy, in that it matches as little of the searched string as possible. Otherwise it matches as many as poassible. |
||
|
|
|
Wildcard: . Matches any single character except “\n”. |
|
Metacharacters inside square brackets (In a character class ) |
|||
|
|
\ |
|
general escape character |
|
|
Ë |
|
negate the class, but only if the first character |
|
|
- |
|
indicates character range |
|
|
] |
End character class definition |
|
|
|
[ |
POSIX character class |
|
Non-Printing characters in strings |
|||
|
|
|
Match a backspace |
|
|
|
|
Match a tab character |
|
|
|
Match a carriage return character Equivalent to \x0d and \cM. |
||
|
|
|
Match a line feed character Equivalent to \x0a and \cJ. |
|
|
|
|
Match a bell character |
|
|
|
|
Match a escape character |
|
|
|
Match a form feed character Equivalent to \x0c and \cL. |
||
|
|
Match a vertical tab character |
||
|
|
|
|
Match the ASCII or ANSI character with position in the character set (Hexadecimal escape values must be exactly two digits long). |
|
|
|
|
Match the Unicode character that occupies code point in the Unicode character table |
Generic Character types (character classes) |
|||
|
|
|
Match any single character that is not a line break character |
|
|
|
|
|
Match a single character that is a “word character” (letters, digits, and underscores) Equivalent to ‘[A-Za-z0-9_]’. |
|
|
|
|
Match a single character that is a “non-word character” c.f. [^A-Za-z0-9_] |
|
|
|
|
Match a single digit 0..9 |
|
|
|
Match a single character that is not a digit 0..9 |
|
|
|
|
Match a single character that is a “whitespace character” (spaces, tabs, and line breaks) Equivalent to [ \f\n\r\t\v]. |
|
|
|
|
Match a single character that is a “non-whitespace character” |
|
|
|
Match a single character in the range between “0” and “1” Character range: Matches any single character in the range from first to last. |
||
|
|
|
Match a single character present in either in the range between “a” and “z” or between “A” and “Z” |
|
|
|
|
Match a single character that is not present in either in the range between “a” and “z” or between “A” and “Z” |
|
|
|
|
Match a single character present in the list “Chars” |
|
|
|
Match a single unicode character eithee any kind of letter from any language (L) or Punctuation (P) |
||
|
Assertions (Anchors) |
|||
|
|
Assert position at the beginning of the string |
||
|
|
Assert position at the very end of the string |
||
|
|
Assert position at the end of the string (or before the line break at the end of the string, if any) |
||
|
^ |
^ |
Assert position at the beginning of a line (at beginning of the string or after a line break character) -this meaning outside a character class only |
|
|
|
|
Assert position at the end of a line (at the end of the string or before a line break character) |
|
|
|
|
Assert position at a word boundary |
|
|
|
|
|
Assert Start of word |
|
|
|
Assert end of word |
|
|
|
|
Assert position not at a word \b boundary |
|
|
|
Assert position at the end of the previous match (the start of the string for the first match) |
||
Grouping Constructs |
|||
|
|
|
A subexpression that matches pattern and captures the match. The captured match can be retrieved from the resulting Matches collection using the substitution . To match parentheses characters ( ), use ‘\(‘ or ‘\)’. |
|
|
|
Captures the matched subexpression into a named group. The captured match can be retrieved from the resulting Matches collection using the name. |
||
|
|
|
Defines a noncapturing group: A subexpression that matches pattern but doesn’t capture the match for later use. This is useful for combining parts of a pattern with the “or” character (|). For example, ‘entit(?:y|ies) is a more economical expression than ‘entity|entities’. |
|
|
|
Zero-width positive lookahead assertion: This is a ‘non-capturing match’. The search for the next match begins immediately after the current one, not including the characters that comprised the lookahead. |
||
|
|
|
The Find/Replace version prevents a match when pattern appears at this point in the expression. This is not quite the same to the zero-width negative lookahead assertion which is also a ‘non-capturing match’. The search for the next match begins immediately after the current one, not including the characters that comprised the lookahead. |
|
|
|
Zero-width positive lookbehind assertion. |
||
|
|
|
The Find/Replace version prevents a match when X appears at this point in the expression this is close to the zero-width negative lookbehind assertion. |
|
|
|
Nonbacktracking (or “greedy”) subexpression. |
||
BackReference constructs |
|||
|
|
|
|
Backreference. Matches the value of a numbered subexpression. |
|
|
Named back-reference. Matches the value of a named expression. |
||
Substitutions |
|||
|
|
|
|
Substitutes the substring matched by capturing group specified by the group number. |
|
|
Substitutes the substring matched by the named group. |
||
|
|
|
|
Substitutes a literal “$”. |
|
|
|
Substitutes a copy of the entire match. (not the lookarounds, of course) |
|
|
|
Substitutes the whole text of the input string before the match. |
||
|
|
Substitutes the entire text of the input string after the match. |
||
|
|
Substitutes the last group that was captured. |
||
|
|
Substitutes the entire input string. |
||
Comments |
|||
|
|
Inline ‘block’ comment. The comment ends at the first closing parenthesis. |
||
|
|
The comment starts at an unescaped # and continues to the end of the line. |
||
Not all the regular expressions are listed here. I’ve missed out the Unicode character properties and a lot of the non-standard character shortcuts. For a full list of these, you’ll need to refer to the help text provided by Microsoft in their How to: Search with Regular Expressions
Conclusions
So there you have it. Next time you find yourself doing some rather repetitive tasks in SSMS, Visual Studio or Expression Web, then I hope you remember this article and find it useful in helping with a boring job of work. The Find/Replace Regular Expressions are a bit eccentric, and short on advanced features, but they are still very useful on occasion. I know for sure that I’d hate to be without the use of regular expressions in SSMS.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments