
We have all been using the COUNT(DISTINCT) function to return row counts for a distinct list of column values in a table for ages. With the introduction of SQL Server 2019, there is a new way to get an estimate of distinct row values and counts for a table. It is by using the new APPROX_COUNT_DISTINCT() function. This new function doesn’t return the actual number of rows for each distinct value in a table, but instead returns an approximate count for each distinct value. This new function uses fewer resources than the tried and true COUNT(DISTINCT) function. Let’s take a little closer look at this new function.
What Problem is APPROX_COUNT_DISTINCT() Trying to Solve?
The new APPROX_COUNT DISTINCT() function is trying to solve the “Count Distinct Problem.” More information about this problem can be found here. Basically, the problem is that counting distinct values requires more and more memory as the number of distinct values increases. At some point, SQL Server can no longer manage to maintain the count of distinct values in memory and must spill to tempdb. Spilling to tempdb causes overhead and leads to increased execution time.
The implementation of APPROX_COUNT_DISTINCT() has a much smaller memory requirement than the COUNT(DISTINCT) function. The algorithm used for this new function is HyperLogLog. This algorithm can estimate the number of distinct values of greater than 1,000,000,000, where the accuracy of the calculated approximate distinct count value is within 2% of the actual distinct count value. It can do this while using less than 1.5 KB of memory.
More Information About the APPROX_COUNT_DISTINCT Function
The APPROX_COUNT_DISTINCT function has been available in other vendor software packages for a while now, but it is new in SQL Server. It first became available in Azure SQL Database, and now has been released for on premises use with SQL Server 2019 Community Technical Preview (CTP) 2.0. This new function is design to quickly return the approximate number of unique non-null values in a group, when your data set has millions, or billions of rows, and many distinct values.
This APPROX_COUNT_DISTINCT() function is designed to give you the approximate aggregated counts more quickly than using the COUNT (DISTINCT) method. It does this by using the HyperLogLog algorithm, which reduces the memory footprint required to maintain a list of distinct values. Because less memory is needed, APPROX_COUNT(DISTINCT) is, therefore, less likely to spill to tempdb when aggregating millions or billions of rows of data. This equates to shorter execution times compared to using the COUNT(DISTINCT) method.
The documentation states that this new function “guarantees up to a 2% error rate within a 97% accuracy.” Therefore, if speed is more important than absolute accuracy of the distinct count, then you might want to consider using this new function.
Invoking this function is similar to using the COUNT(DISTINCT) function. Here is the syntax:
|
1 |
APPROX_COUNT_DISTINCT ( expression ) |
The expression can be any type, except for image, sql_variant, ntext, or text value.
Testing APPROX_COUNT_DISTINCT() for Performance
In order to test out the performance of this new function, I’ll use a specific use case to determine out how fast APPROX_COUNT_DISTINCT() runs as compared to COUNT(DISTINCT. In addition to verifying the speed, I’ll also look to see if I can detect if this new function uses a smaller memory footprint than the old COUNT(DISTINCT) standby.
To gather and compare these metrics, I’m going to use this specific hypothetical use case and situation:
Use Case:
Develop a dashboard indicator that shows whether the number of unique IP addresses that have accessed our site for the current month is more, less or the same as the prior month.
Situation:
I work at an internet search engine, and I am responsible for building queries to run against some of the data we have collected. One of the things we track are the IP addresses for every visit to our site. We collect billions of rows of data every month. My boss has asked me to develop a query that can be used as a dashboard trend indicator that will show whether the number of unique IP Addresses coming to our site has gone up (+) or down (-) in the current month, as compared to the prior month. My boss requires this new query to run as fast as possible across our IP Address tracking table that contains billions, and billions of rows. My boss is willing to accept some level of lesser precision in the accuracy of the number, provide the indicator and percentage of change can be produced more quickly than a method that has absolute accuracy.
To create a testing environment, I created a database and populated a table named Visits2 that has a billion rows of randomly generated data. You can find the code I used to create my sample database in Listing 3, at the end of this article.
First, I want to test how fast the APPROX_COUNT_DISTINCT() function runs as compared to the COUNT(DISTINCT) function. For this test, I ran two SELECT queries that supported my use case. The first SELECT statement uses the COUNT(DISTINCT)function, and the second SELECT statement uses the APPROX_COUNT_DISTINCT() function. This code, found in Listing 1, generates a count of the number of unique IP Address that have accessed our site for July and August. You can also turn on “live query statistics” if you wish to monitor the progress of each SELECT statement while they are running.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SET STATISTICS TIME ON; GO SELECT COUNT(DISTINCT IP_Address) AS NumOfIP_Addresses, DATEPART (month,VisitDate) AS MonthNum FROM [dbo].[Visits2] WHERE DATEPART (month,VisitDate) IN (7, 8) GROUP BY DATEPART (month,VisitDate); GO SELECT APPROX_COUNT_DISTINCT(IP_Address) AS NumOfIP_Addresses, DATEPART (month,VisitDate) AS MonthNum FROM [dbo].[Visits2] WHERE DATEPART (month,VisitDate) IN (7, 8) GROUP BY DATEPART (month,VisitDate); |
Listing 1: Code to compare COUNT(DISTINCT) and APPROX_COUNT_DISTINCT() functions
This code turns on time statistics and runs each SELECT statement. I will use the time statistics produced by running this code to determine how much CPU and elapsed time it takes to get distinct IP address counts for July and August. In Results 1, you can see the CPU and elapsed times I got when I ran the code in Listing 1.
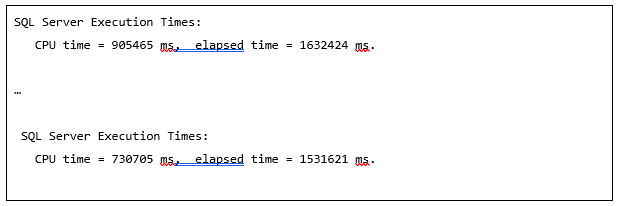
Results 1: The timing results when running the code in Listing 1
In Results 1, I show the timing results of the output produced by setting the STATISTICS TIME ON, for the two SELECT statements. The first set of times are from the COUNT(DISTINCT) query, whereas the second set of times are from the APPROX_COUNT_DISTINCT query. As you can see, APPROX_COUNT_DISTINCT used less CPU and elapsed time compared to the COUNT(DISTINCT)query. The APPROX_COUNT_DISTINCT() function ran a little over 6% faster than the COUNT(DISTINCT) function and uses almost 24% less CPU.
To determine the number of memory grants used by each SELECT statement, I used the output of the execution plan. In Results 2 you can see the execution plan from these two SELECT queries.
|
|
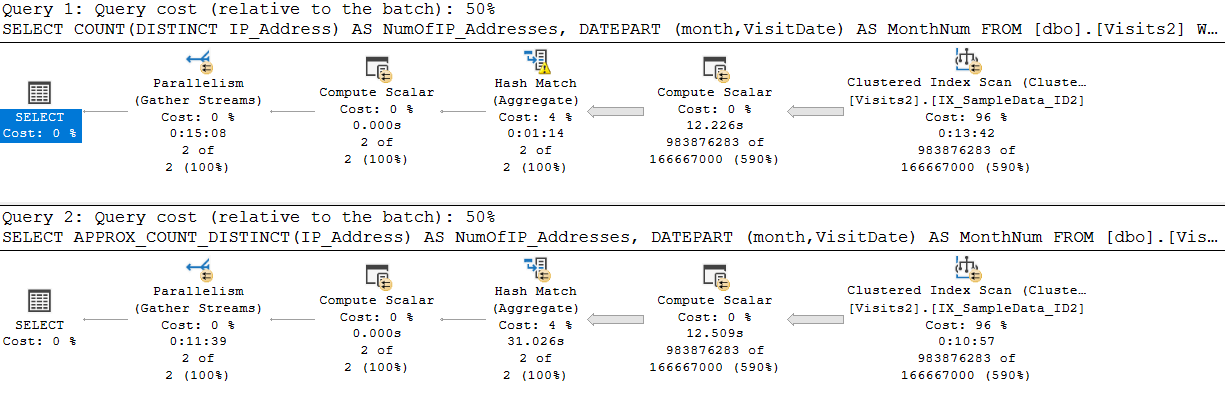
Results 2: Execution Plan code in Listing 1
The first thing you might notice when comparing these two executions is that the Cost of the Hash Match operation for the COUNT(DISTINCT) function takes more than twice as long to run as the Hash Match operation for the APPROX_COUNT_DISTINCT() function.
When I hover over the Hash Match operator for the COUNT(DISTINCT) function, I can see it spilled to disk (see Results 3), but when I hover over the Hash Match operator for the APPROX_COUNT_DISTINCT function, it did not spill to disk (see Results 4).
|
|
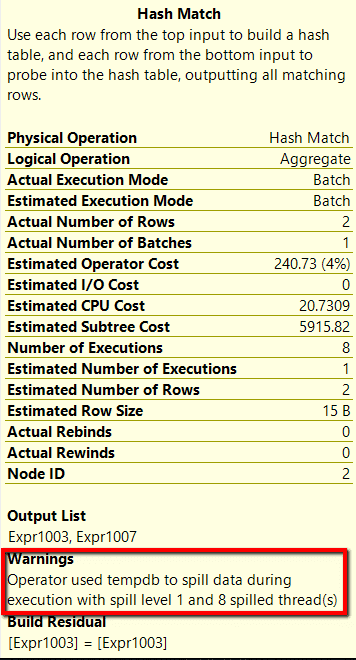
Results 3: Details of Hash Match operation for COUNT(DISTINCT) function
|
|
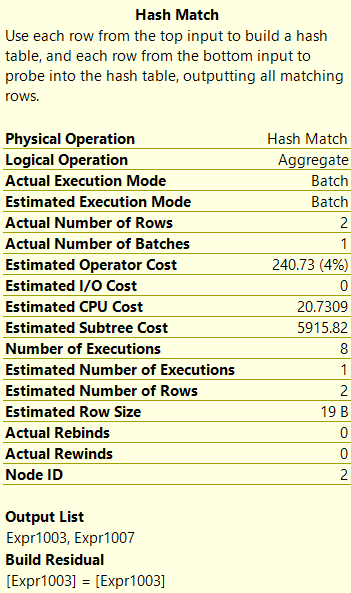
Results 4: Details of Hash Match operation for APPROX_COUNT_DISTINCT function
To display the number of memory grants between the two different functions, I hover over the SELECT icon in the execution plan. When I hover over the COUNT(DISTINCT) SELECT icon I get the results in Results 5, and when I hover over the APPROX_COUNT_DISTINCT SELECT icon I get the results in Result 6.
|
|
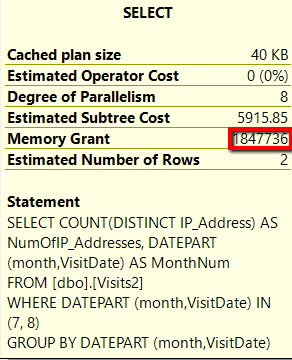
Results 5: Memory Grants for COUNT(DISTINCT)
|
|
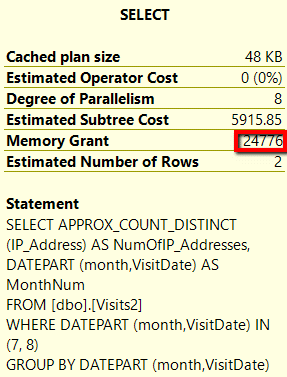
Results 6: Memory Grants for APPROX_COUNT_DISTINCT()
As you can see, the COUNT(DISTINCT) function required 1,847,736 memory grants, whereas the APPROX_COUNT_DISTINCT() function only required 24,776 memory grants. This means the COUNT(DISTINCT) took 74 times as many memory grants over the new APPROX_COUNT_DISTINCT() function. Based on this, you can see the APPROX_COUNT_DISTINCT() function had a significantly smaller number of additional memory grants required versus the COUNT(DISTINCT) function.
Testing APPROX_COUNT_DISTINCT() for Accuracy
In addition to performance testing, I also wanted to test the accuracy/precision of distinct values produced between the COUNT(DISTINCT) and the APPROX_COUNT_DISTINCT() functions. To determine the precision difference between the two functions, I compared the number of distinct values produced by the two different SELECT statements in Listing 1. The COUNT(DISTINCT) function returned a count of 16,581,375 distinct IP address for July, whereas the APPROX_COUNT_DISTINCT() function returns a count of 17,075,480 for July. By comparing these two numbers, I can see that the APPROX_COUNT_DISTINCT() function is off by a little over 2.97%. Since this number was not within 2% error rate as documented, I contact Microsoft about this.
An engineer at Microsoft told me that the SQL Server engine uses a “sophisticated analytic sampling method” to produce an estimated count, and because of this, it is possible to build a contrived table that throws off the sampling method and produces dramatically inaccurate results.
From this first test, I can see that the APPROX_COUNT_DISTINCT() function does, in fact, run faster and requires fewer resources over the COUNT(DISTINCT) function. The only problem I ran across with this first test, was that I had more than a 2% precision error when generating the approximate count, over the real distinct count value. In my case, I found the precision error was 2.97%, which according to documentation can occur.
Since my initial testing found the APPROX_COUNT_DISTINCT() function returned a distinct count that was more than 2% different than the actual distinct count, I decided to run some additional precision testing. The additional SELECT statements I will be testing can be found in Listing 2.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT COUNT(DISTINCT ID) AS COUNT_ID, COUNT(DISTINCT I100) AS COUNT_I100, COUNT(DISTINCT I1000) AS COUNT_I1000, COUNT(DISTINCT I10000) AS COUNT_I10000, COUNT(DISTINCT I1000000) AS COUNT_I1000000, COUNT(DISTINCT I10000000) AS COUNT_I10000000 FROM Visits2; GO SELECT APPROX_COUNT_DISTINCT(ID) AS COUNT_ID, APPROX_COUNT_DISTINCT(I100) AS COUNT_I100, APPROX_COUNT_DISTINCT(I1000) AS COUNT_I1000, APPROX_COUNT_DISTINCT(I10000) AS COUNT_I10000, APPROX_COUNT_DISTINCT(I1000000) AS COUNT_I1000000, APPROX_COUNT_DISTINCT(I10000000) AS COUNT_I10000000 FROM Visits2; |
Listing 2: Additional Testing Queries
The code in Listing 2 will identity the number of unique counts for columns that have a different number of unique values. I will use this code in Listing 2 to determine the number of different values it takes for the APPROX_COUNT_DISTINCT function to produce a count which is different than the actual number of unique values produced by the COUNT(DISTINCT) function. The code from Listing 2 produces the output found in Results 7.
|
|
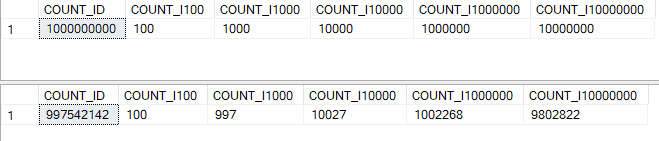
Results 7: Results from running code in Listing 2
As you can see by looking at Results 7, the APPROX_COUNT_DISTINCT() function produces the same number as compared to the COUNT(DISTINCT) function when the number of unique values is low. In my case less than 1,000 unique values. But for each column that had more than 100 values, the APPROX_COUNT_DISTINCT() function produced an approximate number was more or less than the actual number generated by the COUNT(DISTINCT) function. This test shows that when the actual number of distinct values in a table increases, the APPROX_COUNT_DISTINCT() functions don’t produce the same number of distinct values as the COUNT() function, however, it is close. Therefore, if your table contains a large number of distinct values, then expect this new function to produce a count value that is somewhat different than the actual number of distinct values.
Conclusions Based on My Initial Testing
From the few simple tests I ran here against my generated sample data, I have made the following observations:
- The
APPROX_COUNT_DISTINCT()function does return a distinct count number faster than theCOUNT(DISTINCT)function. - The
COUNT(DISTINCT)function requires more memory grants than theAPPROX_COUNT_DISTINCT()function. - In one situation, I able to returns a unique count value that had more than a 2% error rate.
- If the number of distinct values for a given column is low, then the
APPROX_COUNT_DISTINCT()function returns the same count value as theCOUNT(DISTINCT)function.
Should you start using the APPROX_COUNT_DISTINCT()function? That’s a good question. I suppose it depends on your situation. I was pleasantly surprised at how much I was able to improve the runtime and reduce the memory footprint using the APPROX_COUNT_DISTINCT() function over the COUNT(DISTINCT) function. But I was little concerned how easy it was for me to retrieve an aggregated count value that had a precision error of more than 2%. My Visits2 table was very contrived but did expose the improvement and drawbacks of using the APPROX_COUNT_DISTINCT() function. Therefore, before using this new function in a production environment, I would suggest developing a more exhaustive set of tests against real data to verify that any precision errors are within an acceptable range for each situation. As with any new feature, I suggest you identify what the new feature does and then test the heck out of it to verify it provides the improvements you desire in your environment.
Code Used to Create Sample Test Data
In Listing 3, you will find the code I used to create my contrived sample database (SampleData) and the table (Visits2) I used to support my testing. Keep in mind that the code in this listing is not very efficient at creating my sample data. It took over an hour on my laptop to create the billion-row table I used for testing.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
-- Create Sample DB with SIMPLE recovery CREATE DATABASE SampleData CONTAINMENT = NONE ON PRIMARY ( NAME = N'SampleData', FILENAME = N'D:\SQL Server 2019\SampleData.mdf', SIZE = 65GB, FILEGROWTH = 5GB) LOG ON ( NAME = N'SampleData_log', FILENAME = N'D:\SQL Server 2019\SampleData_log.ldf' , SIZE = 5GB, FILEGROWTH = 5GB); GO ALTER DATABASE SampleData SET RECOVERY SIMPLE; GO -- Set database context USE SampleData; GO -- Create table to hold sample data CREATE TABLE Visits2 ( ID INT, I100 INT, I1000 INT, I10000 INT, I100000 INT, I1000000 INT, I10000000 INT, IP_Address VARCHAR(15), VisitDate DATE ); GO -- Create Tally Table GO CREATE VIEW vw_Tally AS --Itzik style tally table WITH lv0 AS (SELECT 0 g UNION ALL SELECT 0) ,lv1 AS (SELECT 0 g FROM lv0 a CROSS JOIN lv0 b) -- 4 ,lv2 AS (SELECT 0 g FROM lv1 a CROSS JOIN lv1 b) -- 16 ,lv3 AS (SELECT 0 g FROM lv2 a CROSS JOIN lv2 b) -- 256 ,lv4 AS (SELECT 0 g FROM lv3 a CROSS JOIN lv3 b) -- 65,536 ,lv5 AS (SELECT 0 g FROM lv4 a CROSS JOIN lv4 b) -- 4,294,967,296 ,Tally (n) AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM lv5) SELECT TOP (1000000) n FROM Tally ORDER BY n; GO -- Populate Visits2 with sample data SET NOCOUNT ON; DECLARE @Max bigint = (select ISNULL(max(ID),0) From Visits2); WHILE @Max < 1000000000 BEGIN WITH TallyTable AS ( SELECT n + @Max as N, CAST(RAND(CHECKSUM(NEWID())) * 255 as INT) + 1 AS A4, CAST(RAND(CHECKSUM(NEWID())) * 255 as INT) + 1 AS A3, CAST(RAND(CHECKSUM(NEWID())) * 255 as INT) + 1 AS A2, 1.0 + floor(1 * RAND(convert(varbinary, newid()))) AS A1, DATEADD(DD, 1.0 + floor(62 * RAND(convert(varbinary, newid()))),'2018-07-01') AS VisitDate FROM vw_Tally) INSERT INTO Visits2 (ID, I100, I1000, I10000, I100000, I1000000, I10000000, IP_Address, VisitDate) SELECT n,n%100, n%1000, n%10000,n%100000, n%1000000, n%10000000, CAST(A1 AS VARCHAR) + '.' + CAST(A2 AS VARCHAR) + '.' + CAST(A3 AS VARCHAR) + '.' + CAST(A4 AS VARCHAR), VisitDate FROM TallyTable set @Max = (select ISNULL(max(ID),0) From Visits2); END -- CREATE UNIQUE CLUSTERED INDEX CREATE CLUSTERED INDEX IX_SampleData_Visits2_ID ON dbo.Visits2(ID); GO |
Listing 3: Script to create database and Visit2 table
Load comments