
SQL Server supports three types of T-SQL user-defined function: scalar functions (return a single value per call), inline table-valued functions (return a rowset derived from a single SELECT), and multi-statement table-valued functions (return a rowset built up across multiple statements).
Inline table-valued functions are the best-performing type because the optimiser inlines them into the calling query; scalar functions were historically slow but gained significant inlining in SQL Server 2019; multi-statement TVFs have the worst performance profile because the optimiser treats them as black boxes.
This article covers syntax and the railroad diagram, execution rules, restrictions, naming, parameters, properties (SCHEMABINDING, EXECUTE AS, RETURNS NULL ON NULL INPUT, ENCRYPTION), how to determine what a function references, and benchmarked performance comparisons between the three types.
What are User-Defined Functions in T-SQL (compared to functions in other languages)?
User-Defined Functions are an essential part of T-SQL. They aren’t, however, quite like functions in a procedural language, or even the built-in system functions such as GetDate(). It is tempting to use them to write SQL code that conforms to good procedural practice in maintaining a single responsibility. Certainly, inline table-valued functions can be used guilt-free where you’d want to use a parameterized view, but you can’t say the same of any type of multi-statement function, whether it produces a scalar value or a table.
These, which are characterised by their BEGIN….END block, need to be used with caution. When misused, multi-statement functions can cause a lot of performance problems. It is, however, a mistake to condemn them altogether, because they are, in some cases, essential. There are plenty of places in any database solution where multi-statement functions are by far the best solution to a problem, despite their restrictions, cautions and performance problems. They just take more care and consideration.
In this article, we won’t discuss CLR functions. They are a different topic.
How Functions are executed
Functions can be used in sql expressions within batches, stored procedures, replication-filter procedures, views, triggers, other scalar or table functions, and old-style rules wherever SQL Server’s built-in scalar expressions can be used. This includes computed columns and CHECK constraint definitions. Functions can be used in calculated fields and check constraints. Scalar functions can be recursive up to 32 levels. Table functions don’t support recursion at all, sadly.
Transact-SQL User-Defined Function Syntax – Railroad Diagram
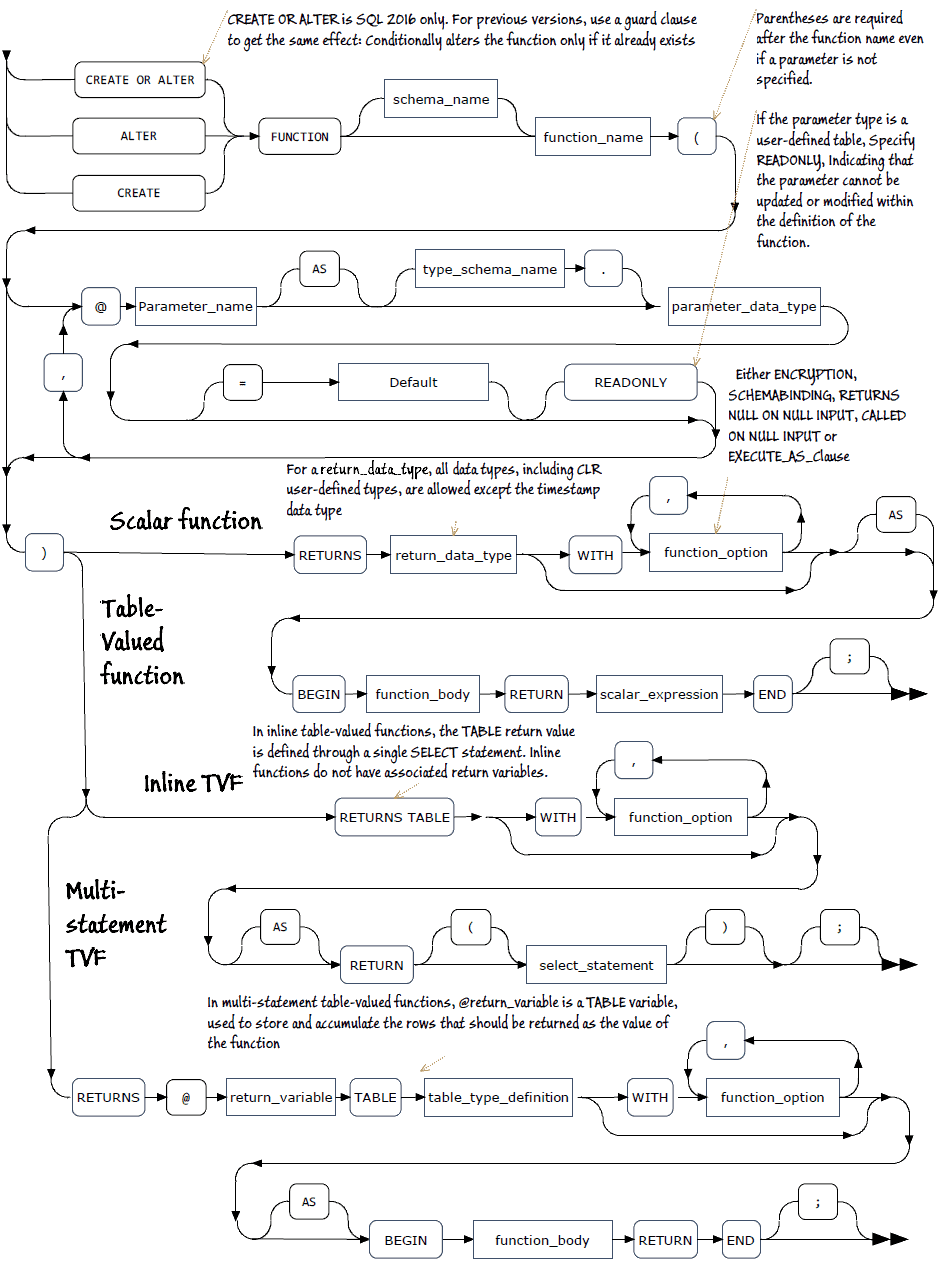
(a high-resolution PDF version of this diagram is available at the end of the article)
The different types of function
You’ll have noticed from the syntax diagram that there are three different types of Function.
- User-defined Scalar Functions (SFs) return a single scalar data value of the type defined in the RETURNS clause.
- User-defined table-valued functions (TVFs) return a table data type that can read from in the same way as you would use a table:.
- Inline Table-valued functions (ITVFs) have no function body; the scalar value that is returned is the result of a single statement without a BEGIN..END block.
As you can see from this, Table Functions can be Inline or Multi-statement. Inline functions do not have associated return variables, they just return a value functions. Multi-statement functions have a function body that is defined in a BEGIN…END block, consisting of a series of Transact-SQL statements that together do not produce a side effect such as modifying a table.
In the case of a multi-statement table-valued function, these T-SQL statements build and insert rows into the TABLE variable that is then returned. In inline table-valued functions, the TABLE return value is defined through a single SELECT statement. This makes it far easier to produce a sensible query plan.
Although Microsoft mentions in ‘types of function’ that ‘For an inline scalar function, there is no function body; the scalar value is the result of a single statement.’ – In fact, inline scalar functions aren’t yet implemented in SQL Server, only multi-statement inline functions, which are, sadly, slow when compared with system functions.
A skeletal, minimal version of these three types would look something like these three snippets/examples.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
/** A skeletal inline table function **/ CREATE FUNCTION dbo.MyInlineTableFunction ( @param1 INT, @param2 CHAR(5) ) RETURNS TABLE AS RETURN ( SELECT @param1 AS c1, @param2 AS c2 ) go /** A skeletal Multi-statement table function **/ CREATE FUNCTION dbo.MyMultistatenetTableFunction ( @param1 INT, @param2 CHAR(5) ) RETURNS @returntable TABLE ( c1 INT, c2 CHAR(5) ) AS BEGIN INSERT @returntable SELECT @param1, @param2; RETURN; END; GO /** A skeletal scalar function **/ CREATE FUNCTION [dbo].[MyScalarFunction] ( @param1 int, @param2 int ) RETURNS INT AS BEGIN RETURN @param1 + @param2 END |
Restrictions
- You cannot create a temporary function in the same way as you would a temporary table or procedure.(with the # or ## prefix)
- You cannot create a function in another database such as TempDB, though you can access one in another database.
- You cannot use SET statements in a user-defined function to change the current session handling, because of the danger of producing a side-effect.
- User-defined functions cannot be used to perform any actions that modify the database state, such as writing to a table or even using an OUTPUT INTO clause that has a table as its target.
- User-defined functions cannot return a result set, only a single table data type. Stored procedure, in contrast, can be used to return one or more result sets.
- A UDF has very restricted error handling. It supports neither RAISERROR nor TRY…CATCH. You can’t get at the @ERROR.
- You cannot call a stored procedure from within a UDF, but you can call an extended stored procedure.
- User-defined functions cannot make use of dynamic SQL or temporary tables.
- Several service broker statements cannot be used in functions.
- Side-affecting operators such as NEWID(), RAND(), TEXTPTR or NEWSEQUENTIALID() aren’t allowed in functions though, for some reason, GETDATE() or HOST_ID() is, though it makes the function non-deterministic. You can get a random number or any other banned system function by creating a view that calls the system function and then calling the view from within the user-defined function. The resulting function won’t be deterministic, though.
Only the following statements are allowed within multi-statement functions
- Assignment statements.
- Control-of-Flow statements except for TRY…CATCH statements.
- DECLARE statements that define local data variables and local cursors.
- SELECT statements that contain select lists with expressions that assign values to local variables.
- Cursor operations referencing local cursors that are declared, opened, closed, and deallocated in the function. Only FETCH statements that assign values to local variables using the INTO clause are allowed; FETCH statements that return data to the client are not allowed.
- INSERT, UPDATE, and DELETE statements only if they modify local table variables.
- EXECUTE statements calling extended stored procedures, but these cannot return result sets.
Things that can be done with functions but are to be avoided where possible.
- If computed columns have scalar functions in them they’ll make queries, index rebuilds and make some DBCC checks go serial. They will slow any updates that trigger a recalculation.
- Any multi-statement function can be a performance overhead
- Multi-statement table-value functions can cause excessive recompiles if used as a table source.
- Any multi-statement table-value function used directly, within a SQL expression, as a table source involved in a join will be slow due to getting a poor execution plan
- Using a scalar function in a WHERE clause or an ON clause for anything other than a small quantity of data should be avoided
Function names
Function names must, of course, comply with the general rules for identifiers and must be unique within its schema. If you use a function conventionally, you must use the dot convention to specify the schema name, and the database if necessary.
|
1 2 |
SELECT PhilFactor.dbo.NthDayOfWeekOfMonth ('2017', 'Jun', 'Fri',3) /* third Friday in the month of June 2017 */ |
Scalar-valued functions can be executed by using the EXECUTE statement. If you EXECUTE a function rather than use it in a SELECT statement or constraint, you can leave out the schema name in the function name, and it will look in the dbo schema followed by the users default schema. Here is an example of a scalar function being called via the EXECUTE syntax and the conventional way.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
CREATE FUNCTION dbo.NthDayOfWeekOfMonth ( @TheYear CHAR(4), --the year as four characters (e.g. '2014') @TheMonth CHAR(3), --in english (Sorry to our EU collegues) e.g. Jun, Jul, Aug @TheDayOfWeek CHAR(3)='Sun', -- one of Mon, Tue, Wed, Thu, Fri, Sat, Sun @Nth INT=1) --1 for the first date, 2 for the second occurence, 3 for the third RETURNS DATETIME WITH EXECUTE AS CALLER AS BEGIN RETURN DATEADD(MONTH, DATEDIFF(MONTH, 0, CONVERT(DATE,'1 '+@TheMonth+' '+@TheYear,113)), 0)+ (7*@Nth)-1 -(DATEPART (WEEKDAY, DATEADD(MONTH, DATEDIFF(MONTH, 0, CONVERT(DATE,'1 '+@TheMonth+' '+@TheYear,113)), 0)) +@@DateFirst+(CHARINDEX(@TheDayOfWeek,'FriThuWedTueMonSunSat')-1)/3)%7 END go -- in SQL Server 2012 onwards, you can either use either the EXECUTE command or the SELECT command to --execute a function. The main difference is in the way that parameters with defaults are handled but --also the schema name is not required in the execute syntax. DECLARE @ret DateTime EXEC @ret = NthDayOfWeekOfMonth '2017', 'Jun', 'Fri',3 /* third Friday in the month of June 2017 */ SELECT @ret AS Third_Friday_In_June_2017 EXEC @ret = NthDayOfWeekOfMonth '2017', 'Jun' /* first Sunday in the month of June 2017 */ SELECT @ret AS First_Sunday_In_June_2017 --or you can use the conventional syntax. --Note that you have to give all parameters SELECT dbo.NthDayOfWeekOfMonth('2017', 'May', DEFAULT, DEFAULT) AS 'Using default', dbo.NthDayOfWeekOfMonth('2017', 'May', 'Sun', 1) AS 'explicit' |
This other EXECUTE syntax is odd: more like a procedure. However, it has uses, as I’ll show later on.
Function parameters
The comma-separated list of parameters must be delimited by Parentheses, even if there are no parameters. Up to 2,100 parameters can be declared, if you feel so inclined. A default for the parameter can be defined. These parameters must have an ‘at’ sign (@) as the first character. The parameter name must comply with the rules for identifiers. Parameters are local to the function; the same parameter names can be used in other functions.
Parameters can take the place only of constants; they cannot be used instead of table names, column names, or the names of other database objects. The values supplied to parameters cannot be expressions, only literals (e.g. 1546) or local variables (e.g. @TheResult).When you pass parameter values to a user-defined function that are too large (e.g. a Char(8) value to a CHAR(4) parameter, the data is truncated to the defined size without any error or warning.
All scalar data types except the timestamp is allowed for a parameter. . The non-scalar types, cursor and table, aren’t allowed, though a Table-Valued Parameter is. If you don’t specify the schema for a user-defined data type, the Database Engine looks in the default schema of the user followed by the dbo schema.
When you have a default value assigned to a parameter, you can use it instead of a supplied value. In the first example above, I used a default value of NULL to tell the routine that if no value was specified, today’s date was to be used to calculate the week. Unfortunately, in the normal syntax, you have to specify that you are allowing the default to be used by providing the DEFAULT keyword. The EXECUTE syntax to call functions allow you more latitude. You need not provide values or the DEFAULT keyword. This can be useful, as in this little sample function that creates a list of up to ten strings. It works because, you can leave out parameters that have a default value assigned to them
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
Create FUNCTION AsAList /* a function for creating short lists of strings */ ( @first VARCHAR(80), @second VARCHAR(80) = NULL, @third VARCHAR(80) = NULL, @fourth VARCHAR(80) = NULL, @fifth VARCHAR(80) = NULL, @sixth VARCHAR(80) = NULL, @seventh VARCHAR(80) = NULL, @eighth VARCHAR(80) = NULL, @ninth VARCHAR(80) = NULL, @tenth VARCHAR(80) = NULL ) RETURNS VARCHAR(8000) WITH EXECUTE AS CALLER AS BEGIN RETURN @first + COALESCE(',' + @second, '') + COALESCE(',' + @third, '') + COALESCE(',' + @fourth, '') + COALESCE(',' + @fifth, '')+ COALESCE(',' + @sixth, '') + COALESCE(',' + @Seventh, '') + COALESCE(',' + @eighth, '')+ COALESCE(',' + @ninth, '') + COALESCE(',' + @tenth, '') END GO DECLARE @ret VARCHAR(8000) = NULL; EXEC @ret = AsAList 'unus','duo','tres'; SELECT @ret -- unus,duo,tres EXEC @ret = AsAList 'Aen','Taen','Tethera','Fethera','hubs','Aaylher','Layalher','Ouoather','Ouaather','Dugs' SELECT @ret -- Aen,Taen,Tethera,Fethera,hubs,Aaylher,Layalher,Ouoather,Ouaather,Dugs |
You can, of course, use this to create tables from lists but you can’t use the EXECUTE function. This means that your lists have to be marked with an explicit DEFAULT when you go beyond the end of the list.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
Create FUNCTION AsATable /* an iTVF function for creating short tables */ ( @first VARCHAR(80), @second VARCHAR(80) = NULL, @third VARCHAR(80) = NULL, @fourth VARCHAR(80) = NULL, @fifth VARCHAR(80) = NULL, @sixth VARCHAR(80) = NULL, @seventh VARCHAR(80) = NULL, @eighth VARCHAR(80) = NULL, @ninth VARCHAR(80) = NULL, @tenth VARCHAR(80) = NULL ) RETURNS table AS RETURN SELECT * FROM (VALUES (1, @first),(2,@second),(3,@third),(4,@fourth),(5,@fifth), (6,@sixth),(7,@seventh),(8,@eighth),(9,@ninth),(10,@tenth)) AS f(TheORDER, word) WHERE word IS NOT null GO SELECT * FROM dbo.AsATable('Aen','Taen','Tethera','Fethera','hubs','Aaylher','Layalher','Ouoather','Ouaather','Dugs') SELECT * FROM dbo.AsATable('Moanday','Tiresday','Woeday','Tearsday','Frightday','Sittingday','Sinday',default,default,default) |
User-Defined Table Types can be used as parameter in functions. If so, they should be marked as READONLY, indicating that the parameter cannot be updated or modified within the definition of the function. They can be used to define variables that are used within a function, but as they are not scalar variable, they cannot be returned by scalar functions! You can return XML types from inline functions, thereby allowing hierarchies to be represented in XML.
You can use a table-valued function as a ‘table source’ in a FROM clause of SELECT, INSERT, UPDATE, or DELETE statements, but if you use a multi-statement function, this can perform badly in joins due mainly to the poor execution plan.
Properties of functions
The code of a function is easily obtained via a system function
|
1 2 3 |
SELECT sql_modules.definition FROM sys.sql_modules WHERE sql_modules.object_id = OBJECT_ID('dbo.NthDayOfWeekOfMonth') |
If, for example, you are using a scalar function within a computed column, SQL Server needs to know certain properties of a function to judge whether a computed column can be persisted or indexed when it contains a function. To use a computed column as an index, SQL Server must be able to verify that any function that is used in the expression must be deterministic, precise, and makes no data access. You can check whether a function complies from the metadata, using, for example ObjectpropertyEx(), the system catalogs or the information schema. Here is an example using ObjectpropertyEx()
|
1 2 3 4 5 6 7 8 9 10 11 12 |
--A deterministic function has to be created with schema binding, and always returns --the same result for any particular set of input values and with the same state of the database. SELECT OBJECTPROPERTYEX(OBJECT_ID('dbo.NthDayOfWeekOfMonth'), N'IsDeterministic'); --Is a precise number returned? Whenever floating point operations are used in resolving --expressions, the results are not precise, by the very nature of the way that the datatype is stored. SELECT OBJECTPROPERTYEX(OBJECT_ID('dbo.NthDayOfWeekOfMonth'), N'IsPrecise'); --Can SQL Server verify that the function is precise and deterministic? SELECT OBJECTPROPERTYEX(OBJECT_ID('dbo.NthDayOfWeekOfMonth'), N'IsSystemVerified'); --The function accesses local system catalogs or virtual system tables SELECT OBJECTPROPERTYEX(OBJECT_ID('dbo.NthDayOfWeekOfMonth'), N'SystemDataAccess'); --The Function accesses user data in the local instance of SQL Server SELECT OBJECTPROPERTYEX(OBJECT_ID('dbo.NthDayOfWeekOfMonth'), N'UserDataAccess'); |
You can, of course find out quickly the name of your user-defined functions and their categories.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
--all scalar functions in the database SELECT name AS Scalar_function FROM sys.objects WHERE objectproperty(OBJECT_ID,'IsScalarFunction')= 1; --all table-valued functions in the database SELECT name AS Table_Valued_Function FROM sys.objects WHERE objectproperty(OBJECT_ID,'IsTableFunction')= 1; --all inline table-valued functions in the database SELECT name AS Inline_Function FROM sys.objects WHERE objectproperty(OBJECT_ID,'IsInlineFunction')= 1; --all multi-statement table-valued functions in the database SELECT name AS MultiStatement_Table_Valued_Function FROM sys.objects WHERE objectproperty(OBJECT_ID,'IsInlineFunction')= 0 AND objectproperty(OBJECT_ID,'IsTableFunction')=1 |
There are a number of objectproperties that are useful
- ExecIsAnsiNullsOn: Was ANSI_NULLS set when the function was created?
- ExecIsQuotedIdentOn: Was QUOTED_IDENTIFIER set when the function was created?
- IsAnsiNullsOn : Do all comparisons against a null value evaluate to UNKNOWN?
- IsDeterministic: Is the function deterministic?
- IsEncrypted: I the function encrypted?
- IsPrecise: Is the return value the result of precise calculations? (no floating point numbers)
- IsInlineFunction: Is it an inline function?
- IsQuotedIdentOn: Are quoted identifiers set to ‘on’?
- IsScalarFunction: Is it a scalar function?
- IsSchemaBound : Is it schema-bound? (does a change to a dependent object trigger a recompile?)
- IsSystemVerified: Can the system verify that the function is deterministic etc?
- IsTableFunction: Is it a table function?
- SystemDataAccess: Does the function access system data, system catalogs or virtual system tables, in the local instance of SQL Server?
- UserDataAccess: Does the function user data, user tables, in the local instance of SQL Server?
Some of these properties are function options, specified with the WITH clause. These are:
SCHEMABINDING
Unless you have a good reason otherwise, use the SchemaBinding function option, It specifies that the function is bound to the database objects that it references. When SCHEMABINDING is specified, the base objects cannot be modified in a way that would affect the function definition.
EXECUTE AS
Specifies the security context under which the user-defined function is executed. Therefore, you can control which user account SQL Server uses to validate permissions on any database objects that are referenced by the function.
RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT
This applies only to scalar-valued functions it specifies the OnNULLCall attribute. If not specified, CALLED ON NULL INPUT is implied by default, meaning that the function body executes even if NULL is passed as an argument.
ENCRYPTION
Indicates that the Database Engine will convert the original text of the CREATE FUNCTION statement to an obfuscated format. It isn’t used nowadays, and there just for backward compatibility
You can easily get the parameters of functions (this sample code is for just the scalar functions but the changes to list both or just table functions should be obvious)
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT OBJECT_SCHEMA_NAME(so.object_id)+'.'+so.name+REPLACE( ' ('+COALESCE((SELECT name+', ' FROM sys.parameters sp WHERE sp.object_ID=so.object_ID AND parameter_ID>0 ORDER BY parameter_ID FOR XML PATH('')), '')+')', ', )', ')') [Scalar functions] FROM sys.objects so WHERE OBJECTPROPERTY(object_id, 'IsScalarFunction')<>0 |
Determining what a function references and what references it.
It is often useful to find out what is using a function, especially if the function is lurking in a trigger or a particularly if it is a slow multi-statement function. Here is some SQL, as an example, that tells you where your multi-statement table value functions are used, and what they, in turn, reference. You would change the objectproperty references according to what you wanted to find out.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
USE AdventureWorks2012; SELECT COALESCE(OBJECT_SCHEMA_NAME(sed.referencing_id) + '.', '') + --likely schema name OBJECT_NAME(sed.referencing_id) + --definite entity name COALESCE('.' + COL_NAME(sed.referencing_id, sed.referencing_minor_id), '') AS referencing, COALESCE(sed.referenced_server_name + '.', '') + --possible server name if cross-server COALESCE(sed.referenced_database_name + '.', '') + --possible database name if cross-database COALESCE(sed.referenced_schema_name + '.', '') + --likely schema name COALESCE(sed.referenced_entity_name, '') + --very likely entity name COALESCE('.' + COL_NAME(sed.referenced_id, sed.referenced_minor_id), '') AS referenced FROM sys.sql_expression_dependencies sed WHERE objectproperty(sed.referencing_id,'IsInlineFunction')= 0 AND OBJECTPROPERTY(sed.referencing_id,'IsTableFunction')= 1 ORDER BY referenced; SELECT COALESCE(sed.referenced_server_name + '.', '') + --possible server name if cross-server COALESCE(sed.referenced_database_name + '.', '') + --possible database name if cross-database COALESCE(sed.referenced_schema_name + '.', '') + --likely schema name COALESCE(sed.referenced_entity_name, '') + --very likely entity name COALESCE('.' + COL_NAME(sed.referenced_id, sed.referenced_minor_id), '') AS referencing, COALESCE(OBJECT_SCHEMA_NAME(sed.referencing_id) + '.', '') + --likely schema name OBJECT_NAME(sed.referencing_id) + --definite entity name COALESCE('.' + COL_NAME(sed.referencing_id, sed.referencing_minor_id), '') AS referenced FROM sys.sql_expression_dependencies sed WHERE objectproperty(sed.referenced_id,'IsInlineFunction')= 0 AND OBJECTPROPERTY(sed.referenced_id,'IsTableFunction')= 1 ORDER BY referenced; |
Performance Comparisons
We take the example function I showed when discussing scalar functions above, giving the date of the nth instance of a particular weekday in the named month in a year, and we can build the other two function types from it. We can also run the expression within the function outside of a function. We can run timings and compare the execution plans. This will give use a fairly good indication of the relative performance of the various ways of doing it.
First we create the other versions of the function.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
/* we create all the candidates for the test */ /*First we create the scalar version of the date-calculator without schema binding */ IF Object_Id('dbo.NthDayOfWeekOfMonth') IS NOT NULL DROP function dbo.NthDayOfWeekOfMonth go CREATE FUNCTION dbo.NthDayOfWeekOfMonth ( @TheYear CHAR(4), --the year as four characters (e.g. '2014') @TheMonth CHAR(3), --in english (Sorry to our EU collegues) e.g. Jun, Jul, Aug @TheDayOfWeek CHAR(3)='Sun', -- one of Mon, Tue, Wed, Thu, Fri, Sat, Sun @Nth INT=1) --1 for the first date, 2 for the second occurence, 3 for the third RETURNS DATETIME WITH EXECUTE AS CALLER AS BEGIN RETURN DATEADD(MONTH, DATEDIFF(MONTH, 0, CONVERT(DATE,'1 '+@TheMonth+' '+@TheYear,113)), 0)+ (7*@Nth)-1 -(DATEPART (WEEKDAY, DATEADD(MONTH, DATEDIFF(MONTH, 0, CONVERT(DATE,'1 '+@TheMonth+' '+@TheYear,113)), 0)) +@@DateFirst+(CHARINDEX(@TheDayOfWeek,'FriThuWedTueMonSunSat')-1)/3)%7 END GO /*Then we create the scalar version of the date-calculator with schema binding */ IF Object_Id('dbo.NthDayOfWeekOfMonthBound') IS NOT NULL DROP function dbo.NthDayOfWeekOfMonthBound go CREATE FUNCTION dbo.NthDayOfWeekOfMonthBound ( @TheYear CHAR(4), --the year as four characters (e.g. '2014') @TheMonth CHAR(3), --in english (Sorry to our EU collegues) e.g. Jun, Jul, Aug @TheDayOfWeek CHAR(3)='Sun', -- one of Mon, Tue, Wed, Thu, Fri, Sat, Sun @Nth INT=1) --1 for the first date, 2 for the second occurence, 3 for the third RETURNS DATETIME WITH SCHEMABINDING,EXECUTE AS CALLER AS BEGIN RETURN DATEADD(MONTH, DATEDIFF(MONTH, 0, CONVERT(DATE,'1 '+@TheMonth+' '+@TheYear,113)), 0)+ (7*@Nth)-1 -(DATEPART (WEEKDAY, DATEADD(MONTH, DATEDIFF(MONTH, 0, CONVERT(DATE,'1 '+@TheMonth+' '+@TheYear,113)), 0)) +@@DateFirst+(CHARINDEX(@TheDayOfWeek,'FriThuWedTueMonSunSat')-1)/3)%7 END GO IF Object_Id('dbo.iTVF_NthDayOfWeekOfMonth') IS NOT NULL DROP function dbo.iTVF_NthDayOfWeekOfMonth go /*We create the inline version of the date-calculator */ CREATE FUNCTION dbo.iTVF_NthDayOfWeekOfMonth ( @TheYear CHAR(4), --the year as four characters (e.g. '2014') @TheMonth CHAR(3), --in english (Sorry to our EU collegues) e.g. Jun, Jul, Aug @TheDayOfWeek CHAR(3)='Sun', -- one of Mon, Tue, Wed, Thu, Fri, Sat, Sun @Nth INT=1) --1 for the first date, 2 for the second occurence, 3 for the third RETURNS table WITH schemabinding AS RETURN (SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, CONVERT(DATE,'1 '+@TheMonth+' '+@TheYear,113)), 0)+ (7*@Nth)-1 -(DATEPART (WEEKDAY, DATEADD(MONTH, DATEDIFF(MONTH, 0, CONVERT(DATE,'1 '+@TheMonth+' '+@TheYear,113)), 0)) +@@DateFirst+(CHARINDEX(@TheDayOfWeek,'FriThuWedTueMonSunSat')-1)/3)%7 AS TheDate) GO /*We create the multi-line version of the date-calculator */ IF Object_Id('dbo.TVF_NthDayOfWeekOfMonth ') IS NOT NULL DROP function dbo.TVF_NthDayOfWeekOfMonth go CREATE FUNCTION dbo.TVF_NthDayOfWeekOfMonth ( @TheYear CHAR(4), --the year as four characters (e.g. '2014') @TheMonth CHAR(3), --in english (Sorry to our EU collegues) e.g. Jun, Jul, Aug @TheDayOfWeek CHAR(3)='Sun', -- one of Mon, Tue, Wed, Thu, Fri, Sat, Sun @Nth INT=1) --1 for the first date, 2 for the second occurence, 3 for the third RETURNS @When TABLE (TheDate DATETIME) WITH schemabinding AS Begin INSERT INTO @When(TheDate) SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, CONVERT(DATE,'1 '+@TheMonth+' '+@TheYear,113)), 0)+ (7*@Nth)-1 -(DATEPART (WEEKDAY, DATEADD(MONTH, DATEDIFF(MONTH, 0, CONVERT(DATE,'1 '+@TheMonth+' '+@TheYear,113)), 0)) +@@DateFirst+(CHARINDEX(@TheDayOfWeek,'FriThuWedTueMonSunSat')-1)/3)%7 RETURN end GO |
We can now check and demonstrate ways of using the table versions to run the calculation on all rows of a table
|
1 2 3 4 5 6 7 8 |
/* demonstrate ways of using the table versions to run the calculation on all rows of a table*/ SELECT TheDate FROM dbo.iTVF_NthDayOfWeekOfMonth('2001','may','Sun',2) SELECT TheYear, CONVERT(NCHAR(11),(SELECT TheDate FROM dbo.iTVF_NthDayOfWeekOfMonth(TheYear,'may','Sun',2)),113) FROM (VALUES ('2010'),('2011'),('2012'),('2013'),('2014'),('2015'),('2016'),('2017'),('2018'))years(TheYear) SELECT TheYear, CONVERT(NCHAR(11),TheDate,113) FROM (VALUES ('2010'),('2011'),('2012'),('2013'),('2014'),('2015'),('2016'),('2017'),('2018'))years(TheYear) OUTER apply dbo.iTVF_NthDayOfWeekOfMonth(TheYear,'may','Sun',2) |
Now we create some test data for the function
|
1 2 3 4 5 6 7 8 |
SELECT * INTO #testData FROM (VALUES ('2010'),('2011'),('2012'),('2013'),('2014'),('2015'),('2016'),('2017'),('2018'))years(TheYear) CROSS join (VALUES ('jan'),('feb'),('mar'),('apr'),('may'),('jun'), ('jul'),('aug'),('sep'),('oct'),('nov'),('dec'))months(Themonth) CROSS join (VALUES ('Mon'),('Tue'),('Wed'),('Thu'),('Fri'),('Sat'), ('Sun'))day(TheDay) CROSS join (VALUES (1),(2),(3),(4))nth(nth) |
…and quickly run some tests. (I use a very slow test server specially for performance testing-the only user, physical server)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
IF EXISTS(SELECT * FROM tempdb.sys.tables WHERE name LIKE '#testData%') DROP TABLE #testData SELECT * INTO #testData FROM (VALUES ('2010'),('2011'),('2012'),('2013'),('2014'),('2015'),('2016'),('2017'),('2018'))years(TheYear) CROSS join (VALUES ('jan'),('feb'),('mar'),('apr'),('may'),('jun'), ('jul'),('aug'),('sep'),('oct'),('nov'),('dec'))months(Themonth) CROSS join (VALUES ('Mon'),('Tue'),('Wed'),('Thu'),('Fri'),('Sat'), ('Sun'))day(TheDay) CROSS join (VALUES (1),(2),(3),(4))nth(nth) --And quickly run some tests. (I use a very slow test server specially for performance testing-the only user, physical server) DECLARE @log TABLE (TheOrder INT IDENTITY(1,1), WhatHappened varchar(200), WHENItDid Datetime2 DEFAULT GETDATE()) ----start of timing INSERT INTO @log(WhatHappened) SELECT 'Starting My_Section_of_code'--place at the start -- first we use no type of function at all to get a baseline SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, CONVERT(DATE,'1 '+TheMonth+' '+TheYear,113)), 0)+ (7*Nth)-1 -(DATEPART (WEEKDAY, DATEADD(MONTH, DATEDIFF(MONTH, 0, CONVERT(DATE,'1 '+TheMonth+' '+TheYear,113)), 0)) +@@DateFirst+(CHARINDEX(TheDay,'FriThuWedTueMonSunSat')-1)/3)%7 AS TheDate INTO #stuff0 FROM #testData INSERT INTO @log(WhatHappened) SELECT 'Using the code entirely unwrapped'; ---we now use an inline Table-valued function cross-applied SELECT TheYear, CONVERT(NCHAR(11),TheDate,113) AS itsdate INTO #stuff1 FROM #testData CROSS APPLY dbo.iTVF_NthDayOfWeekOfMonth(TheYear,TheMonth,TheDay,nth) INSERT INTO @log(WhatHappened) SELECT 'Inline function cross apply' ---we now use an inline Table-valued function cross-applied SELECT TheYear, CONVERT(NCHAR(11),(SELECT TheDate FROM dbo.iTVF_NthDayOfWeekOfMonth(TheYear,TheMonth,TheDay,nth)),113) AS itsDate INTO #stuff2 FROM #testData INSERT INTO @log(WhatHappened) SELECT 'Inline function Derived table' ---To compare untrusted, we now use a scalar function with schemabinding SELECT TheYear, CONVERT(NCHAR(11), dbo.NthDayOfWeekOfMonthBound(TheYear,TheMonth,TheDay,nth))itsdate INTO #stuff3 FROM #testData INSERT INTO @log(WhatHappened) SELECT 'Trusted (Schemabound) scalar function' ---Next, we use a scalar function without schema binding SELECT TheYear, CONVERT(NCHAR(11), dbo.NthDayOfWeekOfMonth(TheYear,TheMonth,TheDay,nth))itsdate INTO #stuff6 FROM #testData INSERT INTO @log(WhatHappened) SELECT 'Untrusted scalar function' ---Next the multi-statement table function derived SELECT TheYear, CONVERT(NCHAR(11),(SELECT TheDate FROM dbo.TVF_NthDayOfWeekOfMonth(TheYear,TheMonth,TheDay,nth)),113) AS itsdate INTO #stuff4 FROM #testData INSERT INTO @log(WhatHappened) SELECT 'multi-statement table function derived' ---finally the multi-statement table cross-applied SELECT TheYear, CONVERT(NCHAR(11),TheDate,113) AS itsdate INTO #stuff5 FROM #testData CROSS APPLY dbo.TVF_NthDayOfWeekOfMonth(TheYear,TheMonth,TheDay,nth) INSERT INTO @log(WhatHappened) SELECT 'multi-statement cross APPLY'--where the routine you want to time ends SELECT ending.whathappened AS Test, DateDiff(ms, starting.whenItDid,ending.WhenItDid) [AS Time (ms)] FROM @log starting INNER JOIN @log ending ON ending.theorder=starting.TheOrder+1 --list out all the timings DROP table #stuff0 DROP table #stuff1 DROP table #stuff2 DROP table #stuff3 DROP table #stuff4 DROP table #stuff5 DROP table #stuff6 DROP TABLE #TestData |
With this result:
Which, over a run of six further tests gives …
And can be graphed to show the ghastly overhead of using Multi-statement Table functions
Which gives a pretty stark message, particularly about the performance of Multi-statement Table functions.
When should I use a user-defined function?
Functions, of all types, are easily tested since they should encapsulate a clear component of a process, and are deterministic (always give the same output for the same input). They allow functionality to be maintained in just one place. They integrate with the flow of a batch much more smoothly than a stored procedure does, especially when results have to be passed between routines.
Multi-statement Functions are a good choice when a complex action needs to be done only once: for example, when a Metaphone needs to be calculated for a person’s surname in a customer database. Changes in Surname/lastname happen very infrequently for any individual. To take another example, the date of Easter for a particular year needs to be done just once. It is sensible, therefore, make very sure that such calculations are not done repeatedly and entirely unnecessarily, as is possible when put in an update trigger.
Inline Table-valued functions are a good way of creating views that require parameters. These are particularly useful for interfaces, because they allow controlled and limited access to the data in base tables while preventing direct access (see Schema-Based Access Control for SQL Server Databases). Under the covers, these functions can be resolved into a good query plan for accessing the base table.
Scalar functions are useful for creating XML documents that represent hierarchical information. This is because Scalar functions can return results as XML variables, and can be called recursively.
Conclusion
User-Defined Functions come in two flavours. The inline Table-valued functions are an excellent device. They are easy to use and maintain, and can usually be resolved into fast-running queries by the Query Optimiser. Scalar functions are a good choice if you SchemaBind them, though even then there is always an overhead from the BEGIN …END block. Multi-statement table-valued functions are like a bandsaw in a woodworkers shop, wonderful when you’re an expert, especially when you retain a certain element of terror, but can cause some nasty problems when you use it carelessly, and without the necessary expertise. Yes, injudicious use of user-defined functions can bring any database to its knees, so use them, but with care and caution.
Further Reading
- SQL Server Functions: The Basics By Jeremiah Peschka
- TSQL User-Defined Functions: Ten Questions You Were Too Shy To Ask by Robert Sheldon
- Understand the Performance Behavior of SQL Server Scalar User Defined Functions by Simon Liew
- Forcing a Parallel Query Execution Plan by Paul White
- T-SQL User-Defined Functions: the good, the bad, and the ugly (part 1) by Hugo Kornelis
- T-SQL User-Defined Functions: the good, the bad, and the ugly (part 2) by Hugo Kornelis
- T-SQL User-Defined Functions or How to Kill Performance in One Easy Step (transcript) by Hugo Kornelis






Load comments