
SQL Server has several options for exporting data to file: native BCP (fastest, binary, SQL Server-specific), XML via BCP (fast, portable, handles nested structures), comma-delimited CSV (widely compatible but fragile when data contains commas or quotes), tab-delimited (simpler than CSV but fails when data contains tabs), and a few others.
This article benchmarks each format against AdventureWorks data deliberately chosen to exercise the edge cases (illegal column names, embedded delimiters, Unicode content) and measures both speed and correctness.
The headline results: native BCP and XML via BCP both perform very rapidly; tab-delimited and comma-delimited are slower and have data-integrity pitfalls on real data; if source and target are both SQL Server and the data is relational, native BCP is the clear winner. For cross-system transfer, XML via BCP handles structure better than CSV; JSON (covered in a companion article) is the modern alternative.
I enjoy pulling the data out of AdventureWorks. It is a great test harness. What is the quickest way of doing it? Well, everyone knows it is native BCP, but how much faster is that format than tab-delimited or comma-delimited BCP? Can we quickly output data in XML? Is there a way of outputting array-in-array JSON reasonably quickly? How long does it take to output in MongoDB’s Extended JSON? Of course, the answer is going to vary from system to system, and across versions, but any data about this is usually welcome.
In addition to these questions, I wanted to know more about how much space these files take up, either raw or zipped. We’re about to find out. We’ll test all that, using good ol’ BCP and SQLCMD.
My motivation for doing this was to explore ways of quickly transferring data to MongoDB. to test out a way of producing array-in-array JSON at a respectable turn of speed. It turned out to be tricky. The easy and obvious ways were slow.
How? Why?
The reason I like AdventureWorks is that it has a bit of an assault course there. There are illegal column names, reserved words used as columns, CLR types, and free text search. Not as much of this as I’d like, of course, but it makes things a bit more tricky, so it is good for testing, along with old Pubs with its awkward obsolete data types.
Because the SQL Server implementation of XML and JSON are rather delicate creatures that quail at the smell of a CLR Datatype, or a column name with an embedded space, we generally need some supporting logic, rather than belt out the tables to file just by SELECT *.
As most people know, you can use BCP very simply, just specifying each table. Here we output in Tab-delimited format in utf-8, which is a format that Excel likes. It is safe as long as you don’t include tab characters in your spreadsheet cells! Note that xp_cmdshell must be enabled to try this example.
|
1 2 3 4 5 6 7 |
--over-ride this path if you need to. DECLARE @ourPath sysname = 'OurPath\TabDelimited\'; DECLARE @Database sysname = Db_Name(); DECLARE @command NVARCHAR(4000)= ' EXECUTE xp_cmdshell ''bcp ? out '+@ourPath +'?.Tab -c -C 65001 -d' +@Database+' -T -S '+@@servername +''', NO_OUTPUT;' EXECUTE sp_msforeachtable @command |
Native and “comedy-limited” formats aren’t much harder. Proper CSV format output from the tables of a database is only possible via ODBC.
Creating the Test Harness
For this task, I set up several directories on the server for the different types of output
Then ran the script from The Code section in this article which wrote out the data from AdventureWorks into each directory in the different formats. I included within the batch all the necessary temporary procedures along with a routine that switched in the configuration that allowed me to use xp_cmdshell and then switched it off again.
Into each directory was written all the files, one for each table, like this.
One can, and should of course, open these files up and check on them. Here is the Tab-delimited format.
OK, it would be good not to have the quoted identifiers in the filename [Human Resources]. [Employee].Tab, perhaps, but they are legal. If they irritate you, it is very quick and easy to remove them.
|
1 2 |
Get-ChildItem -path 'MyDirectory’ -Filter "*[*]*.json" -Recurse | Rename-Item -NewName {$_.name -replace '(\[|\])',''} |
Mixed Usefulness of the Different Formats
Not all these formats are particularly useful. Tab-delimited is fine just so long as you don’t have tabs in any strings. The comma-separated format isn’t CSV. If you run …
|
1 |
SQLCMD -d AdventureWorks2016 -E -u -s, -W -Q "set nocount on; SELECT * from (values ('This text has commas, like this, and so should be delimited.','comedy-limited, nice but unreliable'),(',,,,,','This text has no commas'))f(one,two)" |
… you will see instantly that it hasn’t coped. It isn’t CSV.
|
1 2 3 4 |
one,two ---,--- This text has commas, like this, and so should be delimited.,comedy-limited, nice but unreliable ,,,,,,This text has no commas |
The Results
The XML via BCP and the native BCP both worked very rapidly. Tab delimited and comma-delimited took a little bit longer. SQLCMD and the object-in-array JSON were slightly laggard but respectable. Extended JSON had a third-more to write than ordinary JSON. Bringing up the rear was the array-in-array-format. I originally tried exporting array-in-array JSON via XML. However, it turned out to be too slow. Although XML is quick to export, the overhead of converting it to JSON is slow. The method of using OpenJSON was again prohibitively slow, taking two or three minutes.

A word of caution with these results. They can vary considerably, even on the same server and general setup.
The performance of array-in-array JSON was as good as I can manage to get. CLR, or even PowerShell could easily do better. I’d prefer to wait for SQL Server to support the format. However, this is only five times as long as the fastest, BCP. It is usable for most purposes.
What about the space they take up?
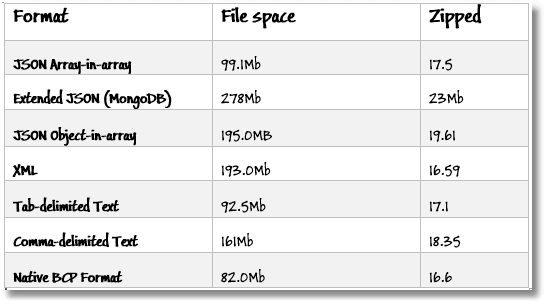
The advantage of the array-in-array format of JSON is that the text takes half the space of the object -in-array format. This advantage almost vanishes when the files are zipped, though.
XML and Json Object-in-Array format both take around twice as much space as the simpler tabular formats, which is unsurprising as they are more versatile in the structure of the information they can hold. The large space used by comma-delimited files is due to the fact that I had difficulty storing the file in UTF-8 format. I opted for Unicode instead. This disappeared when the files were zipped. Comma-delimited format was only there for the sake of completion.
All the formats, when zipped, take roughly the same space. This shouldn’t be a surprise because they all held exactly the same information. It is just that some formats repeated it a lot!
The Code
So, here is the SQL to run the comparative tests. They take some time to run. Something like three and a half minutes for AdventureWorks. You’ll see that we start by hurriedly ensuring that we are allowed to use XP_CmdShell and changing the configuration if necessary. Then we run the tests and finally, if necessary, close off the configuration to prevent it being used.
To run this, change the path values to a directory on your server if required. Remember that you are writing these files to your server, not the workstation.
I describe the methodology for the test harness, and how to set it up as a SQL Prompt snippet, in an article ‘How to record T-SQL execution times using a SQL Prompt snippet’.
These routines need to access temporary stored procedures. These are all stored on GitHub, and I’ll keep those updated. They are here, at JSONSQLServerRoutines along with several others that I use for processing JSON. For this example, create the #SaveJsonDataFromTable, #SaveExtendedJsonDataFromTable, and #ArrayInArrayJsonDataFromTable temporary stored procedures in the same query window before running the following code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 |
/* lets just check the config and make sure that xp_cmdshell is enabled. */ DECLARE @Settings TABLE ( name sysname, minimum INT, Maximum INT, config_value INT, run_value INT); INSERT INTO @Settings (name, minimum, Maximum, config_value, run_value) EXECUTE sp_configure @configname = 'show advanced options'; IF NOT EXISTS ( SELECT * FROM @Settings WHERE name = 'show advanced options' AND run_value = 1) BEGIN EXECUTE sp_configure 'show advanced options', 1; RECONFIGURE; END; INSERT INTO @Settings (name, minimum, Maximum, config_value, run_value) EXECUTE sp_configure @configname = 'xp_cmdshell'; IF NOT EXISTS ( SELECT * FROM @Settings WHERE name = 'xp_cmdshell' AND run_value = 1) BEGIN EXECUTE sp_configure 'xp_cmdshell', 1; RECONFIGURE; END; go /* start of timed run */ DECLARE @log TABLE (TheOrder INT IDENTITY(1,1), WhatHappened varchar(200), WHENItDid Datetime2 DEFAULT GETDATE()) USE adventureworks2016 ----start of timing INSERT INTO @log(WhatHappened) SELECT 'Starting Writing out every table' --place at the start DECLARE @ourPath9 sysname = 'C:\Data\RawData\AdventureWorks\XML\'; Declare @command9 NVARCHAR(4000)= 'EXEC xp_cmdshell ''bcp "SELECT * FROM ? FOR XML AUTO" queryout "' +@ourPath9+'?.xml" -S '+@@Servername+' -T -c -C 65001 -t'', NO_OUTPUT;' EXECUTE sp_msforeachtable @command9 INSERT INTO @log(WhatHappened) SELECT 'Writing out every table as XML took ' --log the time taken to get to this point /* first lets try using JSON array--in-array format */ DECLARE @ourPath1 sysname = 'C:\Data\RawData\AdventureWorks\JSONArrayInArray\'; Declare @command1 NVARCHAR(4000)= ' DECLARE @Json NVARCHAR(MAX) EXECUTE #ArrayInArrayJsonDataFromTable @TableSpec=''?'',@JSONData=@json OUTPUT CREATE TABLE ##myTemp (Bulkcol nvarchar(MAX)) INSERT INTO ##myTemp (Bulkcol) SELECT @JSON EXECUTE xp_cmdshell ''bcp ##myTemp out "'+@ourPath1 +'?.JSON" -c -C 65001 -S '+@@Servername+' -T '', NO_OUTPUT; DROP TABLE ##myTemp' EXECUTE sp_msforeachtable @command1 INSERT INTO @log(WhatHappened) SELECT 'Writing out every table as Array-in-Array JSON took ' --log the time taken to get to this point DECLARE @ourPath2 sysname = 'C:\Data\RawData\AdventureWorks\JSONObjectInArray\'; DECLARE @command2 NVARCHAR(4000)= ' DECLARE @Json NVARCHAR(MAX) EXECUTE #SaveJsonDataFromTable @TableSpec=''?'',@JSONData=@json OUTPUT CREATE TABLE ##myTemp (Bulkcol nvarchar(MAX)) INSERT INTO ##myTemp (Bulkcol) SELECT @JSON EXECUTE xp_cmdshell ''bcp ##myTemp out '+@ourPath2 +'?.JSON -c -C 65001 -S '+@@Servername+' -T '', NO_OUTPUT; DROP TABLE ##myTemp' EXECUTE sp_msforeachtable @command2 INSERT INTO @log(WhatHappened) SELECT 'Writing out every table as Object-in-Array JSON took ' --log the time taken to get to this point DECLARE @ourPath3 sysname = 'C:\Data\RawData\AdventureWorks\TabDelimited\'; DECLARE @Database3 sysname = Db_Name(); --over-ride this if you need to. DECLARE @command3 NVARCHAR(4000)= ' EXECUTE xp_cmdshell ''bcp ? out '+@ourPath3+'?.Tab -c -C 65001 -d' +@Database3+' -S '+@@Servername+' -T '', NO_OUTPUT;' EXECUTE sp_msforeachtable @command3 INSERT INTO @log(WhatHappened) SELECT 'Writing out every table as tab-delimited BCP took ' --log the time taken to get to this point DECLARE @ourPath4 sysname = 'C:\Data\RawData\AdventureWorks\NativeBCP\'; DECLARE @Database4 sysname = Db_Name(); --over-ride this if you need to. DECLARE @command4 NVARCHAR(4000)= ' EXECUTE xp_cmdshell ''bcp ? out '+@ourPath4+'?.data -N -d' +@Database4+' -S '+@@Servername+' -T '', NO_OUTPUT;' EXECUTE sp_msforeachtable @command4 INSERT INTO @log(WhatHappened) SELECT 'Writing out every table as native BCP took ' --log the time taken to get to this point DECLARE @ourPath6 sysname = 'C:\Data\RawData\AdventureWorks\CSV\'; DECLARE @Database6 sysname = Db_Name(); --over-ride this if you need to. DECLARE @command6 NVARCHAR(4000)= ' EXECUTE xp_cmdshell ''sqlcmd -d ' +@Database6+' -u -E -h -1 -s, -W -Q "set nocount on; SELECT * FROM ?" -S ' +@@Servername+' -o '+@ourPath6++'?.CSV'', NO_OUTPUT;' EXECUTE sp_msforeachtable @command6 INSERT INTO @log(WhatHappened) SELECT 'Writing out every table as SQLCMD comedy-limited took ' --log the time taken to get to this point --log the time taken to get to this point DECLARE @ourPath7 sysname = 'C:\Data\RawData\AdventureWorks\ExtendedJSON\'; Declare @command7 NVARCHAR(4000)= ' DECLARE @Json NVARCHAR(MAX) EXECUTE #SaveExtendedJsonDataFromTable @TableSpec=''?'',@JSONData=@json OUTPUT CREATE TABLE ##myTemp (Bulkcol nvarchar(MAX)) INSERT INTO ##myTemp (Bulkcol) SELECT @JSON EXECUTE xp_cmdshell ''bcp ##myTemp out "'+@ourPath7 +'?.JSON" -c -C 65001 -S '+@@Servername+' -T '', NO_OUTPUT; DROP TABLE ##myTemp' EXECUTE sp_msforeachtable @command7 INSERT INTO @log(WhatHappened) SELECT 'Writing out every table as Extended JSON took ' --log the time taken to get to this point SELECT ending.whathappened, DateDiff(ms, starting.whenItDid,ending.WhenItDid) AS ms FROM @log starting INNER JOIN @log ending ON ending.theorder=starting.TheOrder+1 UNION all SELECT 'Total', DateDiff(ms,Min(WhenItDid),Max(WhenItDid)) FROM @log ORDER BY ms asc --list out all the timings go DECLARE @Settings TABLE (name sysname, minimum INT, Maximum INT, config_value INT, run_value INT); INSERT INTO @Settings (name, minimum, Maximum, config_value, run_value) EXECUTE sp_configure @configname = 'show advanced options'; IF NOT EXISTS ( SELECT * FROM @Settings WHERE name = 'show advanced options' AND run_value = 1) BEGIN EXECUTE sp_configure 'show advanced options', 1; RECONFIGURE; END; INSERT INTO @Settings (name, minimum, Maximum, config_value, run_value) EXECUTE sp_configure @configname = 'xp_cmdshell'; IF NOT EXISTS ( SELECT * FROM @Settings WHERE name = 'xp_cmdshell' AND run_value = 0) BEGIN EXECUTE sp_configure 'xp_cmdshell', 0; RECONFIGURE; END; |
Conclusions
It is very useful to run tests like these, and I caught several bugs while doing so. However, I much prefer testing things rather than waving my hands and arguing.
What I’d conclude from all this is that JSON is a good way of storing data and isn’t really any bulkier as a format than any other way of doing it. When data is zipped, it seems to boil down to the same size whatever the format you use. Obviously, Native BCP is the quickest and neatest way of ‘dumping’ data but it isn’t easy to read, and you cannot prepare data from another source and import it as native BCP because it isn’t a data transport medium. If you want an unzipped tabular format with the robustness of JSON and the size of CSV, then JSON Array-in-array is the one to go for.
None of the delimited formats are safe in that it is always possible that column value could contain an unescaped character that is used as a delimiter. CSV, in contrast, would be fine if there were a reliable way of doing it in BCP. If you want a safe way of transporting data, then XML or JSON is an obvious choice but who would use XML when there was an alternative?
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments