
Sparse columns and column sets can be used in conjunction, and are ideal for fields that contain mostly NULL values. Sparse columns handle NULL values extremely efficiently; column sets combine all sparse columns into an XML representation as a new column.
Sparse columns are designed to allow a relational database to store and process relatively unstructured data, where any individual entity may have a modest selection from a very wide set of attributes. This sort of data can be found frequently in scientific, pharmaceutical, and medical applications. EAV (Entity/Attribute/Value) storage techniques were engineered for such data; however, EAV data storage has proved to be somewhat inefficient in such areas as query speed and storage cost.
Sparse columns work well where a high proportion of the data in a column is NULL, because negligible storage space is used for the NULL representation. A table that is wide in theory can be made narrow in practice by implementing sparse columns, and the addition of filtered indexes provides effective searches on the sparse data. Sparse columns support the use of check constraints, as long as the constraints allow NULL values (a sparse column requirement). Constraints introduce basic data type checking, and thus allow for a good range of validation and integrity-checking techniques.
Column sets provide a solution to the difficulties of efficient imports and exports of sparse data. The untyped XML representation that is generated for each row interacts directly with each sparse field. The XML field accepts inserts, and its data can be extracted and modified easily. This feature effectively supports certain types of serialized object data from various applications.
Sparse Columns
The SPARSE column property is a special, NULL-friendly column option – introduced with SQL Server 2008. Sparse column data storage is extremely efficient for NULL values. In fact, a NULL value requires no space at all in a sparse column – MSDN states that “…when the column value is NULL for any row in the table, the values require no storage.” However, the storage requirement for a non-NULL value is increased by up to 4 bytes when the SPARSE column property is used. Given that trade-off, Microsoft recommends not using sparse columns unless the percentage of NULL values in a column is high enough that a 20 percent to 40 percent storage savings gain would result. The ratio of NULLs to real values that would warrant implementing a sparse column differs for each data type. For example, when using the datetime type, 52% of the values must be NULL in order to save 40% in storage, but for the bit data type, 98% must be NULL. Fortunately, Microsoft has compiled a chart to easily find the percentage information for each data type.
Sparse columns are ordinary columns, with the addition of the SPARSE property. To create a table with sparse columns, simply use the SPARSE keyword:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE Royalty ( Chronology INT PRIMARY KEY, FirstName VARCHAR(50) NULL, LastName VARCHAR(50) SPARSE, CrownYear INT SPARSE, Region VARCHAR(100) SPARSE, Motto VARCHAR(100) SPARSE, ) GO |
In order to make a column sparse after-the-fact, use an ALTER TABLE statement:
|
1 2 3 |
ALTER TABLE Royalty ALTER COLUMN FirstName VARCHAR(50) SPARSE GO |
This can also be accomplished by changing the ‘Is Sparse‘ column property to ‘Yes‘ in table design view in the SQL Server Management Studio GUI:
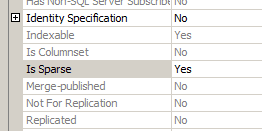
A sparse column must be NULLABLE, so the NULL keyword is optional. A sparse column is populated in the same manner as a normal column:
|
1 2 3 4 5 6 7 8 9 10 |
INSERT Royalty(Chronology, FirstName, CrownYear, Region, Motto) VALUES (1, 'Catherine', 1509, 'Aragon', 'Humble and Loyal') GO INSERT Royalty(Chronology, FirstName, LastName, CrownYear, Motto) VALUES (2, 'Anne', 'Boleyn', 1533, 'La Plus Heureuse'); GO SELECT * FROM Royalty GO |

Comparing NULL Storage
To demonstrate the space savings gained when using sparse columns, we will create two new tables that contain many NULL values, and then examine the amount of space used for storage in each table. First, we’ll create an Employees_sparse table with three sparse columns:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE Employees_sparse ( EMP_ID INT IDENTITY(5001,1) PRIMARY KEY, SSN CHAR(9) NOT NULL, TITLE CHAR(10) SPARSE NULL, FIRSTNAME VARCHAR(50) NOT NULL, MIDDLEINIT CHAR(1) SPARSE NULL, LASTNAME VARCHAR(50) NOT NULL, EMAIL CHAR(50) SPARSE NULL) GO |
Next, an identical table without the SPARSE property enabled:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE Employees ( EMP_ID INT IDENTITY(5001,1) PRIMARY KEY, SSN CHAR(9) NOT NULL, TITLE CHAR(10) NULL, FIRSTNAME VARCHAR(50) NOT NULL, MIDDLEINIT CHAR(1) NULL, LASTNAME VARCHAR(50) NOT NULL, EMAIL CHAR(50) NULL) GO |
Before we populate these tables, let’s add a CHECK constraint to the EMAIL field. Sparse columns DO support CHECK constraints. We want to ensure that each email address in the table will contain the ‘@’ symbol, and that the ‘@’ symbol appears only once in each email address:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
ALTER TABLE Employees_sparse ADD CONSTRAINT chkEmailEmpSparse CHECK ( LEN(REPLACE(EMAIL,'@',''))+1=LEN(EMAIL) ) GO ALTER TABLE Employees ADD CONSTRAINT chkEmailEmp CHECK ( LEN(REPLACE(EMAIL,'@',''))+1=LEN(EMAIL) ) GO |
To save time, we’ll use RedGate’s SQL Data Generator to insert 50000 Employee records into the Employees_sparse table.
Now that we have test data in the table, let’s take a look at portion of it to verify that the distribution of data in the sparse columns is realistic:
|
1 2 3 |
SELECT TOP 10 * FROM Employees_sparse GO |
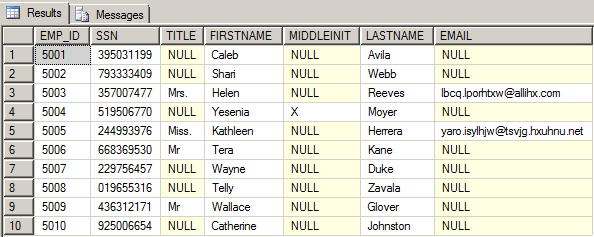
We see a good sampling of the data, where there are very few values in the columns that have the SPARSE property enabled. The Data Generator recognized that TITLE, MIDDLEINIT, and EMAIL are sparse columns, and should contain very few values.
Because we want to compare data storage size between the two tables, we need to insert identical data into the non-sparse table (Employees). We’ll copy over all 50000 records from the sparse table:
|
1 2 3 4 |
INSERT INTO Employees (SSN, TITLE, FIRSTNAME, MIDDLEINIT, LASTNAME, EMAIL) SELECT SSN, TITLE, FIRSTNAME, MIDDLEINIT, LASTNAME, EMAIL FROM Employees_sparse GO |
To view the sparse table’s storage savings, we’ll run the sp_spaceused system stored procedure on both tables:
|
1 2 3 4 5 |
sp_spaceused 'Employees' GO sp_spaceused 'Employees_sparse' GO |
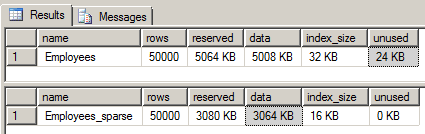
We see that the storage difference between the two tables is quite notable, including index sizes, when the data is very sparse. However, the space savings that were gained can be lost quickly in the event that many NULL values are replaced with real values.
Sparse Column Limitations
A few things to keep in mind when considering using sparse columns:
- Sparse columns cannot have default values, and must accept NULL values
- A computed column cannot be SPARSE
- Sparse columns do not support data compression
- A sparse column cannot be a primary key
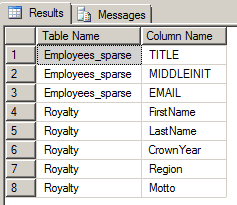
Locating Sparse Columns
A list of all columns that use the SPARSE property can be obtained via the is_sparse field in sys.columns:
|
1 2 3 4 5 6 |
SELECT so.name [Table Name], sc.name [Column Name] FROM sys.columns sc JOIN sys.objects so ON so.OBJECT_ID = sc.OBJECT_ID WHERE is_sparse = 1 GO |
Column Sets
An interesting enhancement to a table that uses sparse columns is a column set. A sparse column set gathers all sparse columns into a new column that is similar to a derived or computed column, but with additional functionality – its data can be updated and selected from directly. A column set is calculated based on the sparse columns in a table, and it generates an untyped XML representation of all sparse columns and values (NULL or otherwise). Keep in mind that a column set is optional. Sparse columns may be used without the implementation of a sparse column set.
A column set may be included in a table definition at the time of creation, or added later, if no sparse columns exist yet. A column set may not be added to a table that contains existing sparse columns:
|
1 2 3 4 5 |
ALTER TABLE Royalty ADD DetailSet XML COLUMN_SET FOR ALL_SPARSE_COLUMNS Msg 1734, Level 16, State 1, Line 1 Cannot create the sparse column set 'DetailSet' in the table 'Royalty' because the table already contains one or more sparse columns. A sparse column set cannot be added to a table if the table contains a sparse column. |
To include the sparse column set in the Royalty table, we must first drop and then recreate the table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DROP TABLE Royalty GO CREATE TABLE Royalty ( Chronology INT PRIMARY KEY, FirstName VARCHAR(50) SPARSE, LastName VARCHAR(50) SPARSE, CrownYear INT SPARSE, Region VARCHAR(100) SPARSE, Motto VARCHAR(100) SPARSE, DetailSet XML COLUMN_SET FOR ALL_SPARSE_COLUMNS ) GO |
We are now able to populate the table in order to demonstrate the behavior of the column set:
|
1 2 3 4 5 6 7 8 9 10 |
INSERT Royalty(Chronology, FirstName, CrownYear, Region, Motto) VALUES (1, 'Catherine', 1509, 'Aragon', 'Humble and Loyal'); GO INSERT Royalty(Chronology, FirstName, LastName, CrownYear, Motto) VALUES (2, 'Anne', 'Boleyn', 1533, 'La Plus Heureuse'); GO SELECT * FROM Royalty GO |

We can see that the results of a SELECT * FROM Royalty are completely different after the introduction of the column set. Every one of the sparse columns is now gathered into an XML string. Only the non-sparse Chronology field is not included in the column set. However, each and every sparse column is still accessible individually when invoked by name:
|
1 2 3 |
SELECT Chronology, FirstName, LastName, CrownYear, Region, Motto, DetailSet FROM Royalty GO |

Almost every column in the Royalty table makes use of the SPARSE property. Keep in mind that for a column to make good use of the SPARSE property, it is expected that most of the values will be NULL.
Column Set Advantages
What are the benefits of using a sparse column set? For one, the column set itself is directly updatable. Because of this, operations performed directly on the column set may be more efficient than when they are performed on individual columns. After an update or an insert, the values that were added to the column set are immediately accessible via the singular sparse column(s):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
INSERT Royalty(Chronology, DetailSet) VALUES (3, '<FirstName>Jane</FirstName><LastName>Seymour</LastName><CrownYear>1536</CrownYear>'); GO INSERT Royalty(Chronology, DetailSet) VALUES (4, '<FirstName>Anne</FirstName><Region>Cleves</Region>'); GO SELECT Chronology, FirstName, LastName, CrownYear, Region, Motto, DetailSet FROM Royalty WHERE Chronology IN (3,4) GO |

To demonstrate the efficiency of a column set operation, consider the following situation: the Royalty table is empty, and we have an XML string that contains all of the records that we want in the table. We can insert the data directly to the DetailSet (xml column set) column all at once, with the help of a bit of XQuery. Let’s remove the existing records in the Royalty table to prepare for the XML import:
|
1 2 |
DELETE FROM Royalty GO |
We have an XML string that contains all the data that we want to put in the empty table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
DECLARE @Royalty XML = ' <Royalty> <Person Chronology="1"> <FirstName>Catherine</FirstName> <CrownYear>1509</CrownYear> <Region>Aragon</Region> <Motto>Humble and Loyal</Motto> </Person> <Person Chronology="2"> <FirstName>Anne</FirstName> <LastName>Boleyn</LastName> <CrownYear>1533</CrownYear> <Motto>La Plus Heureuse</Motto> </Person> <Person Chronology="3"> <FirstName>Jane</FirstName> <LastName>Seymour</LastName> <CrownYear>1536</CrownYear> </Person> <Person Chronology="4"> <FirstName>Anne</FirstName> <Region>Cleves</Region> </Person> <Person Chronology="5"> <FirstName>Catherine</FirstName> <LastName>Howard</LastName> <CrownYear>1540</CrownYear> </Person> <Person Chronology = "6"> <FirstName>Catherine</FirstName> <LastName>Parr</LastName> </Person> </Royalty> ' |
Because we have a built-in identifier for each Person node (the Chronology attribute), we can use a SQL variable in a small XQuery script that will serve as a counter for a loop, and will also delineate each Person record for the insert operation:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
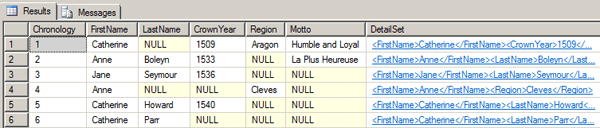
DECLARE @i INT = 1 WHILE @i <= 6 BEGIN INSERT Royalty(Chronology, DetailSet) SELECT @i, @Royalty.query('/Royalty/Person[@Chronology=sql:variable("@i")]/child::node()') SET @i = @i + 1 END GO SELECT Chronology, FirstName, LastName, CrownYear, Region, Motto, DetailSet FROM Royalty GO |
This can streamline otherwise time-consuming data imports. Even if the XML schema changes frequently, or is structured poorly, directly importing it to a customized column set can be relatively easy – only one representative record of the XML data would have to be examined. A table structure that included appropriate sparse columns could then be constructed, based on the XML schema.
Additionally, the maximum sparse column count per table far outdistances the maximum column count limit for traditional columns – but only when used in conjunction with a column set. The column count limit without the use of a column set is the same for sparse columns as it is for non-sparse columns – 1024. If a script were generated to create an all-sparse column table of 2000 columns, but without a column set defined, the following error would result:
|
1 2 |
Msg 1702, Level 16, State 1, Line 1 CREATE TABLE failed because column 'Col_2000' in table 'SPARSE_TBL' exceeds the maximum of 1024 columns. |
Although only one column set per table is permitted, a sparse column set can contain up to 30,000 sparse columns – a wide table solution for a table that has reached the normal column limit of 1024 columns, and still needs to grow in width. Even though no more than 1024 columns may be returned in a result set at once, the entire XML column set may be returned together. In addition, all columns, sparse or non-sparse, may be reverted to an XML representation (without a root element) by using the FOR XML AUTO clause:
|
1 2 3 4 |
SELECT * FROM Royalty FOR XML AUTO GO |
The first two elements of the XML results of the above query are as follows:
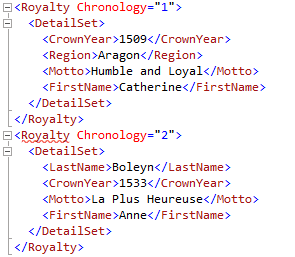
Notice that the column set is represented as a node containing child nodes for all sparse columns, while any non-sparse columns (the Chronology column) are depicted as node attributes.
Column Set Disadvantages
There are a number of disadvantages to using a column set. As mentioned earlier, only one column set may be used per table, and a column set cannot be added to a table that already contains sparse columns. Replication, distributed queries, and change data capture (CDC) do not support using column sets. Also, a column set cannot be indexed in any way.
What’s next? Introducing Filtered Indexes
Another option to consider for sparse columns is a filtered index. A filtered index, when designed properly, can be much smaller and faster than a normal index, because it only stores data that meet certain criteria. This is accomplished by using a WHERE clause in the index definition. The WHERE clause feature makes filtered indexes ideal for sparse columns, as an index can be designed to store only the non-NULL values from a column. A filtered index must be created as a nonclustered index:
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX FI_Region ON Royalty(FirstName, Region) WHERE Region IS NOT NULL GO |
The above index will be small in size, and should return faster, more efficient results for queries similar to the following:
|
1 2 3 4 |
SELECT FI_Region , Region FROM Royalty WHERE Region IS NOT NULL GO |
Filtered indexes will not store the NULL values on the heap when the WHERE criteria is configured correctly, unlike unfiltered nonclustered indexes.
Summary
Sparse columns store NULL values very efficiently for tables that contain a high percentage of NULLs. Sparse columns accommodate drastically improved query speeds when used in conjunction with filtered indexes. When used with column sets, sparse columns extend the traditional column count limit for tables, providing a much better solution for storing unstructured data than older, inefficient EAV methods. Column sets also represent sparse data in an automatically generated XML format that allows easy data imports, exports, and manipulation.
Sparse columns do not support primary keys, data compression, NOT NULL constraints, or default values. Non-sparse columns may not be altered to have the SPARSE property, but instead must be created with it. Sparse columns implicitly allow NULLs upon table creation. Column sets are not compatible with data replication, distributed queries, or indexes. Sparse columns are compatible with CHECK constraints and nonclustered indexes.
We’ve looked at some detailed examples that use sparse columns and column sets. Sparse column solutions offer many benefits when applied correctly, but may be unnecessary if the ratio of NULL values to non-NULL values is not high enough, or if the table is not wide enough to warrant the use of a column set.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments