
Time is an interesting thing. It moves in only one direction; it’s units of measurement are irregular and constantly in motion. When we go to model it in SQL, it’s usually easier to do lookup tables (calendars) rather than trying to compute it. SQL is not a computational language, but it also must deal with the nature of this dimension. Digital computers are based on discrete states, but time by its very nature is a continuum. In a continuum, there is always an infinite number of points between any two points in the continuum. This means we’re already in a state of heresy when we try to put time into a digital computer.
Quantum Models
The quantum model is the simplest model, and a timestamp is the most common example. We simply ignore the inconvenience of the continuum and assume that time comes in discrete units or quanta. These quanta are sometimes called “chronons” in the literature. If you want to have a physical instrument for this model, think of a wall clock whose hands jump from one number to another, without sweeping in between them on the face of the clock. Or think about a calendar, whose unit of granularity is a day.
If you are a fan of kids’ television shows, you might have seen an iCarly episode that featured a new integer between 5 and 6, called “derf.” The same gimmick was recently used in an episode of DUST, a science fiction series on YouTube, if you do not to want to admit you watch kids’ television shows. Whether you treat the idea as joke or a scary fantasy, the point is that a temporal model has to be based on discrete values without gaps and a strong ordering for computations.
But what happens when you have to record a temporal value from the real world which is between quanta with such a scale? You have to assign or ignore a temporal value that is in the set of allowed values. In the Orient, a person’s age in years is a count of the full and partial years that they have lived. A new-born baby is one year old in this system. In the Western world, we only count the full years and use “months” if the child has lived less than a year. Or, to put it another way, you can round a temporal value toward the past or toward the future to map it to a quanta value in this model.
The old DATETIME data type in Transact-SQL defines a date that is combined with a time of day with fractional seconds that is based on a 24-hour clock. The date range is from 1753 January 1 to 9999 December 31. The start date is the beginning of the Gregorian calendar when it was first adopted in Great Britain. The end date is the largest four-digit year that can be represented on it. Other countries adopted it latter times, often years later (for a very detailed history, read THE CALENDAR by David Ewi ng Duncan, ISBN 9781857029796). Today we’re not really on the Gregorian calendar anymore. We use what’s called the Common Era calendar and we’ve replaced A.D. and B.C. with CE and BCE. It’s almost like the Gregorian calendar, except it starts at 0001-01-01 and goes through 9999-12-31.
The time range is 00:00:00 through 23:59:59.997, but the fractional seconds are weird. They are rounded to quanta of 0.000, 0.003, or 0.007 seconds. The reason for this has to do with the original implementation of SQL Server under Sybase. DATETIME data was stored in the floating-point format available on the original 16-bit hardware. The mantissa held the date portion, and the exponent held the clock portion. This is why if you look at old SQL Server code you may find a DATETIME value CAST or CONVERTed to floating-point, manipulated and then cast back to DATETIME. If this sounds like a kludge, that’s because it is. But it was a very fast kludge, especially if your machine had floating-point hardware. Since we had no separate DATE and TIME data types, the convention was to fake having a DATE by setting the time portion to 00:00:00.000. You will find a lot of old code for this in legacy systems.
SQL Server has had ANSI/ISO compliant date and time datatypes for several years now. You should not ever use the old DATETIME data type, and instead you should be moving on to DATETIME2(n) and DATE datatypes today. I also think it’s probably a good idea to go through and replace those old kludges with the modern datatypes. The new datatypes are not only ANSI/ISO 8601 conformant but use less storage and have more precision if you really need it. Let’s be honest, most of the time, commercial work is quite happy with precisions to a date or to a fraction of an hour within the date. While it’s nice to be able to go down to nanoseconds, we really don’t use that degree of precision in any common application you will ever run into.
Another advantage is using the ISO 8601 format which is an international standard with unambiguous specification. Also, this format isn’t affected by the SET DATEFORMAT or SET LANGUAGE setting. This format has several display options; SQL picked one.
Today, the ANSI/ISO SQL Standards only allow the ISO 8601 format which looks like “yyyy-mm-dd HH:mm:ss.ssssss”, in the language. Please notice the use of dashes and a space between the date and the time fields. The ISO 8601 standard also specifies a version that drops out the dashes and replaces the space with a “T” as a separator, which SQL Server also allows. Frankly I like the second version better because of the continuous string with no worries about white spaces (Blank? Tab? Newline? Carriage return?) and I’m very glad to see that Microsoft supports it. However, we picked the first version when we were setting up the standards because it looks nicer for people. It is the default in the SQL world.
Other Date Displays
Probably the most esoteric way of representing a date is the Julian system. It’s used by astronomers and it has nothing to do with the Julian calendar. Nobody ever uses that outside of the sciences. The count starts with 4713, January 01 BCE, and the Julian Date for 00:30:00.0 UT January 1, 2013, is 2 456 293.520 833. For details see this article and this one.
Another common way of displaying a date is simply the ordinal date format. It consist of “yyyy-ddd” where the “yyyy” is the usual year and “ddd” is the day within the year, taking on the values 001 thru 365 or 366.
Closed Interval Models
Another model is based on a closed interval defined by (start_timestamp, end_timestamp) pairs that mark the end points of a temporal interval. We assume (start_timestamp ≤ end_timestamp). All of the temporal points in the interval are assumed to be in the set of values, even if you cannot actually represent them with your software. The FIPS (Federal Information Processing Standards) require at least four decimal places of seconds in a timestamp in all clocks used by the US government. However, the current hardware and SQL Standards can give seven decimal places, nanoseconds.
A calculus for temporal reasoning was introduced in 1983 by James F. Allen (“Maintaining knowledge about temporal intervals”, Communications of the ACM. 26(11): 832–843.). It was not designed for SQL, but for general use when describing events. The following 13 base relations capture the possible relations between two intervals in Allen’s Interval Algebra:
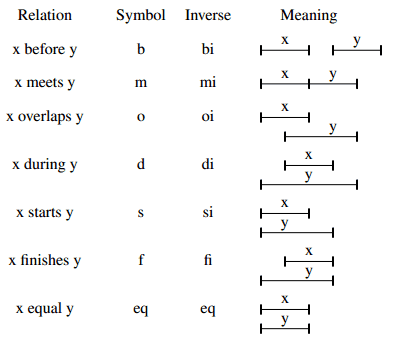
The inverse of a relation simply flips the right and left sides of the infixed operators and rewords the definition. Obviously, equality is its own inverse.
In general, the number of different relations between n intervals is 1, 1, 13, 409, 23917, 2244361… OEIS A055203. The special case shown above is for n=2.You have to decide if endpoints are co-located, or merely tangent. It gets messy, but it is a consistent, known model.
ISO Half Open Interval Model
The ISO model of time is based on half open intervals. That means we have a starting point, but we have no ending point for an interval. The duration in the interval approaches but never actually reaches the ending point. To make this a little more explicit, consider a day. It begins at 00:00:00 Hrs (midnight), progresses through 24 hours, but never gets to 24:00:00 Hrs. That final endpoint actually belongs to the start of the next day. DB2, other SQL products, and international conventions will convert 24:00:00 Hrs to midnight of the next day automatically.
Depending exactly in what precision your times are kept, you can get as close as 23:59:59.9999999 Hrs, assuming that you’re following the precision required by Federal Information Processing Standards. In actual practice, for commercial purposes, you probably are not paying your employees by the nanosecond. Let’s be honest, to be within one minute is probably good enough in most cases.
The advantage of the half open interval model is that two time periods can be abutted to each other. Each point in time belongs to one and only one interval. If you used closed intervals, then they would abut on at least one point, or could overlap. This makes for a lot of problems when you are trying to determine during which shift a particular billable event occurs.
In mathematics, this is called the partitioning of a set, and it’s where we get the name of the PARTITION BY clause in SQL. But unlike mathematics, SQL (or any other digital representation in a computer) can’t actually be a continuum. To give you an idea where I’m going, let’s assume that a day is broken into three shifts in a factory for purposes of timecards.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE TABLE Shifts ( shift_code CHAR(12) NOT NULL PRIMARY KEY CHECK (shift_code IN ( 'first_shift', 'second_shift', 'third_shift' )), start_time TIME(0) NOT NULL, end_time TIME(2) NOT NULL, CHECK (start_time < end_time) ); INSERT INTO Shifts VALUES ('first_shift', '09:00:00', '16:59:999'), ---nine to five ('second_shift', '17:00:00', '19:59:999'), ---five to eight ('third_shift', '20:00:00', '23:59:59.999'); -- graveyard shift CREATE TABLE Timecards ( emp_name VARCHAR(25) NOT NULL PRIMARY KEY, clock_in_time TIME(0) NOT NULL, clock_out_time TIME(0) NOT NULL, CHECK (clock_in_time <= clock_out_time) ... ); |
This is a pretty skeletal timecard system created for illustrating the basic principles of this article. A real schema would have a lot more details.
For example, employee A enters a time in/out block 08:30:00– 17:30:00. That block would have to be parsed as something like
SHIFT CODE third_shift = 0.5 hours
SHIFT CODE first_shift = 8 hours
SHIFT CODE second_shift = 0.5 hours
We can use decimal representation for hours… common in payroll and time tracking. Many decades ago, I had a similar problem. We rounded the durations to 15 minute blocks (xx:00:00 thru xx:14:59, xx:15:00 thru xx:29:59, xx:30:00 thru xx:44:59, xx:45:00 thru xx:59:59) as per union rules. 24 hrs per day * 4 blocks per hour = 96 blocks per day, 5 days per work week = 480, 50 work weeks per year = 24,000; a decade of lookups = 240,000 rows. Put a running total of blocks in each row, then subtract the starting block count from the ending block count.
We found that a simple lookup table was easier than trying to do temporal math. After all, SQL is a data language, not a computational language. Use a spreadsheet and load the table, so you are done for a decade.
The OVERLAPS() Predicate
ANSI/ISO Standard SQL defines the OVERLAPS() predicate as the result of the following expression:
(S1 > S2 AND NOT (S1 >= T2 AND T1 >= T2))
OR (S2 > S1 AND NOT (S2 >= T1 AND T2 >= T1))
OR (S1 = S2 AND (T1 <> T2 OR T1 = T2))
where S1 and S2 are the starting times of the two time periods and T1 and T2 are their termination times. The rules for the OVERLAPS() predicate sound like they should be intuitive, but they are not. The principles that we wanted in ANSI/ISO Standard SQL were:
1. A time period includes its starting point but does not include its end point. We have already discussed this temporal model.
2. If the time periods are not “instantaneous”, they overlap when they share a common time period.
3. If the first term of the predicate is an INTERVAL and the second term is an instantaneous event (a <datetime> data type), they overlap when the second term is in the time period (but is not the end point of the time period). That follows the half-open model.
4. If the first and second terms are both instantaneous events, they overlap only when they are equal.
5. If the starting time is NULL and the finishing time is a <datetime> value, the finishing time becomes the starting time and we have an event. If the starting time is NULL and the finishing time is an INTERVAL value, then both the finishing and starting times are NULL.
Please consider how your intuition reacts to these results, when the granularity is at the YEAR-MONTH-DAY level. Remember that a day begins at 00:00:00 Hrs.
(today, today) OVERLAPS (today, today) = TRUE
(today, tomorrow) OVERLAPS (today, today) = TRUE
(today, tomorrow) OVERLAPS (tomorrow, tomorrow) = FALSE
(yesterday, today) OVERLAPS (today, tomorrow) = FALSE
Keeping Contiguous Events
Alexander Kuznetsov wrote this programming idiom for History Tables in T-SQL, but it generalizes to any SQL. It builds a temporal chain from the current row to the previous row with a self-reference. This idiom easy to use, once the DDL is in place.
This is easier to show with code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
CREATE TABLE Tasks ( task_id INTEGER NOT NULL, task_score CHAR(1) NOT NULL, previous_end_date DATE, -- null means first task current_start_date DATE DEFAULT CURRENT_TIMESTAMP NOT NULL, CONSTRAINT previous_end_date_and_current_start_in_sequence CHECK (previous_end_date <= current_start_date), --DEFERRABLE INITIALLY IMMEDIATE, current_end_date DATE, -- null means unfinished current task CONSTRAINT current_start_and_end_dates_in_sequence CHECK (current_start_date <= current_end_date), CONSTRAINT end_dates_in_sequence CHECK (previous_end_date <> current_end_date), PRIMARY KEY ( task_id, current_start_date ), UNIQUE ( task_id, previous_end_date ), -- null first task UNIQUE ( task_id, current_end_date ), -- one null current task FOREIGN KEY ( task_id, previous_end_date ) -- self-reference REFERENCES Tasks ( task_id, current_end_date ) ); |
Well, that looks complicated! Let’s look at the code column by column. Task_id explains itself. The previous_end_date will not have a value for the first task in the chain, so it is NULL-able. The current_start_date and current_end_date are the same data elements, temporal sequence and PRIMARY KEY constraints we had in the simple history table schema.
The two UNIQUE constraints will allow one NULL in their pairs of columns and prevent duplicates. Remember that UNIQUE is NULL-able, not like PRIMARY KEY, which implies UNIQUE NOT NULL.
Finally, the FOREIGN KEY is the real trick. Obviously, the previous task must end when the current task started for them to abut, so there is another constraint. This constraint is a self-reference that makes sure this is true. Modifying data in this type of table is easy but requires some thought. The foreign key reference is to be disabled when this table is first constructed and then restarted afterwards. In ANSI/ISO Standard SQL, this is done with deferrable constraints, but in T-SQL you have to explicitly turn the constraint on and off during the session.
DATETIMEOFFSET
DATETIMEOFFSET is a data type giving you the ability to work with time zones. Here’s the format:
YYYY-MM-DD hh:mm:ss[.nnnnnnn] [{+|-}hh:mm]
The final option on this date format is the number of hours and minutes that the time zone difference differs from UTC. Time zones can be a little crazy, usually for political reasons rather than computational considerations. For example, for many years Japan and Korea had different zones. Columbia did not want to be in the same time zone as United States when Caesar Chavez was their dictator. You can find the currently recognized time zones here. SQL Server doesn’t care if the time zone offset exists in the real world or not, it just needs to be computationally valid.
To generate the current local non-offset date and time value in the target SQL Server instance, you use functions such as SYSDATETIME (returns DATETIME2) or GETDATE (returns DATETIME). To generate the current local date and time value with the offset, use SYSDATETIMEOFFSET. This example returns the date and time, including the offset, for US Central Standard Time when running on my computer:
|
1 |
PRINT SYSDATETIMEOFFSET(); |
This command returns:
![]()
To return the current time zone offset, you use functions like DATENAME (returns a string with hours and minutes offset) or DATEPART (returns an integer with minutes offset) with the TZoffset part (tz in short). The displacement will make allowances for daylight saving time, according to Microsoft conventions. Here’s an example which returns -300 since the offset is -5 hours:
|
1 2 |
DECLARE @Date DATETIMEOFFSET = SYSDATETIMEOFFSET(); PRINT DATEPART(tz,@Date); |
AT TIME ZONE
The AT TIME ZONE function was introduced in SQL Server 2016. It replaces both TODATETIMEOFFSET and SWITCHOFFSET. It has the following syntax:
|
1 |
<value> AT TIME ZONE '<standard time zone name>' |
Here’s an example:
|
1 2 3 4 |
DECLARE @Date DATETIMEOFFSET = GETDATE(); PRINT @Date; SET @Date = @Date AT TIME ZONE 'Pacific Standard Time'; PRINT @Date; |
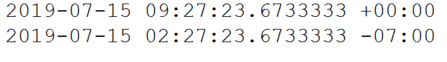
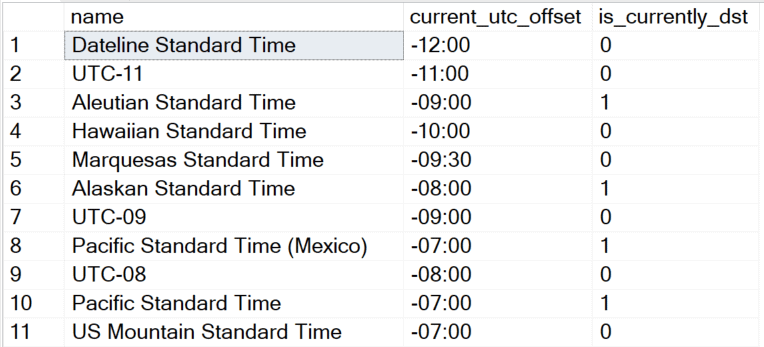
When the input value is a nonoffset date and time value, the function behaves similar to TODATETIMEOFFSET; when the input value is a date and time value with an offset, the function behaves similar to SWITCHOFFSET. Moreover, you don’t need to worry about clock switching; rather, just specify the target standard time zone name (for instance, for Pacific Time always specify ‘Pacific Standard Time’), and SQL Server will figure out dynamically the target time zone offset based on the Windows time zone conversion rules. To get the full list of supported standard time zone names, plus their current offset from UTC and whether it’s currently on daylight saving time, query the sys.time_zone_info function:
|
1 |
SELECT * FROM sys.time_zone_info; |
The query returns 139 rows, but here is a sample:
I also strongly recommend that you read this article, so have some idea just how complicated things can get.
The Most Important Thing to take Home from this article
Use the TIME, DATE, DATETIME2 and DATETIMEOFFSET data types for new work. These types align with the SQL Standard. They are more portable. DATE, TIME DATETIME2 and DATETIMEOFFSET provide more decimal seconds precision. DATETIMEOFFSET provides time zone support for globally deployed applications, but think in UTC.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments