
While trying to solve the data challenges an organization throws our way, it is often easy to get buried in large, complex queries. Despite efforts to write concise, easy to read, maintainable T-SQL, sometimes the need to just get a data set quickly results in scary code that is better off avoided rather than committed.
This article dives into a handful of query patterns that can be useful when attempting to simplify messy code and can both improve query performance while improving maintainability at the same time!
The problems
There is no singular problem to solve here. Instead, a handful of cringeworthy T-SQL snippets will be presented, along with some alternatives that are less scary. Hopefully, this discussion not only provides some helpful solutions to common database challenges but provides some general guidance toward cleaner and more efficient code that can extend to other applications.
Note that all demos use the WideWorldImporters demo database from Microsoft.
Multiple WHERE clauses
A common need, especially in reporting, is to have to retrieve a variety of metrics from a single table. This may manifest itself in a daily status report, a dashboard, or some other scenario where intelligence about some entity is necessary. The following is an example of code that collects a variety of metrics related to orders:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT COUNT(*) AS TotalOrderCount FROM Sales.Orders WHERE OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016'; SELECT COUNT(*) AS PickingNotCompleteCount FROM Sales.Orders WHERE PickingCompletedWhen IS NULL AND OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016'; SELECT COUNT(*) PickedPersonUndefined FROM Sales.Orders WHERE PickedByPersonID IS NULL AND OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016'; SELECT COUNT(DISTINCT CustomerID) AS CustomerCount FROM Sales.Orders WHERE PickedByPersonID IS NULL AND OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016'; SELECT COUNT(*) AS ArrivingInThreeDaysOrMore FROM Sales.Orders WHERE DATEDIFF(DAY, OrderDate, ExpectedDeliveryDate) >= 3 AND OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016'; |
Each of these queries performs a single calculation based on order data for a specific time frame. From a reporting perspective, this is a common need. The results are as follows:
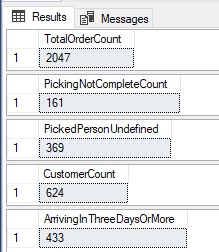
It’s a long chunk of code with many lines repeated within each query. If a change is needed in the logic behind this query, it would need to be changed in each of the five queries presented here. In terms of performance, each query takes advantage of different indexes to return its calculation. Some use index seeks and others index scans. In total, the IO for these queries is as follows:
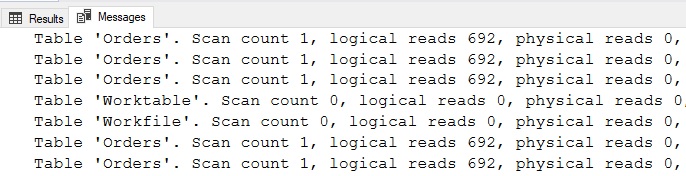
A total of 3,460 reads are required to retrieve results using two clustered index scans and three seeks. Despite the WHERE clauses varying from query to query, it is still possible to combine these individual queries into a single query that accesses the underlying table once rather than five times. This can be accomplished using aggregate functions like this:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT COUNT(*) AS TotalOrderCount, SUM(CASE WHEN PickingCompletedWhen IS NULL THEN 1 ELSE 0 END) AS PickingNotCompleteCount, SUM(CASE WHEN PickedByPersonID IS NULL THEN 1 ELSE 0 END) AS PickedPersonUndefined, COUNT(DISTINCT CustomerID) AS CustomerCount, SUM(CASE WHEN DATEDIFF(DAY, OrderDate, ExpectedDeliveryDate) >= 3 THEN 1 ELSE 0 END) AS ArrivingInThreeDaysOrMore FROM Sales.Orders WHERE OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016'; |
The resulting code returns the same results in a single statement, rather than five, trading more lines of code for more complex code within the SELECT portion:

In this particular scenario, the query also performs better, requiring one scan rather than two scans and three seeks. The updated IO is as follows:

The performance of a set of queries that are combined using this method will typically mirror the performance of the worst-performing query in the batch. This will not always be an optimization, but by combining many different calculations into a single statement, efficiency can be found (sometimes). Always performance test code changes to ensure that new versions are acceptably efficient for both query duration and resource consumption.
The primary benefit of this refactoring is that the results require far less T-SQL. A secondary benefit is that adding and removing calculations can be done by simply adding or removing another line in the SELECT portion of the query. Maintaining a single query can be simpler than maintaining one per calculation. Whether or not performance will improve depends on the underlying queries and table structures. Test thoroughly to ensure that changes do indeed help (and not harm) performance.
One additional note on the use of DISTINCT: It is possible to COUNT DISTINCT for a subset of rows using syntax like this:
|
1 2 3 4 5 |
SELECT COUNT(DISTINCT CASE WHEN PickingCompletedWhen IS NOT NULL THEN CustomerID ELSE NULL END) AS CustomerCountForPickedItems FROM Sales.Orders WHERE OrderDate >= '5/1/2016' AND OrderDate < '6/1/2016'; |
This looks a bit clunky, but it allows a distinct count of customers to be calculated, but only when a specific condition is met. In this case, when PickingCompletedWhen IS NOT NULL.
Duplicate management
Finding (and dealing with) unwanted duplicates is quite common in the world of data. Not all tables have constraints, keys, or triggers to ensure that the underlying data is always pristine, and in lieu of that is the question of how to most easily find duplicates.
The following example shows a small data set of customers and order counts for a given date:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
CREATE TABLE #CustomerData ( OrderDate DATE NOT NULL, CustomerID INT NOT NULL, OrderCount INT NOT NULL); INSERT INTO #CustomerData (OrderDate, CustomerID, OrderCount) VALUES ('4/14/2022', 1, 100), ('4/15/2022', 1, 50), ('4/16/2022', 1, 85), ('4/17/2022', 1, 15), ('4/18/2022', 1, 125), ('4/14/2022', 2, 2), ('4/15/2022', 2, 8), ('4/16/2022', 2, 7), ('4/17/2022', 2, 0), ('4/18/2022', 2, 12), ('4/14/2022', 3, 25), ('4/15/2022', 3, 18), ('4/16/2022', 3, 38), ('4/17/2022', 3, 44), ('4/18/2022', 3, 10), ('4/14/2022', 4, 0), ('4/15/2022', 4, 0), ('4/16/2022', 4, 1), ('4/17/2022', 4, 3), ('4/18/2022', 4, 0), ('4/14/2022', 5, 48), ('4/15/2022', 5, 33), ('4/16/2022', 5, 59), ('4/17/2022', 5, 24), ('4/18/2022', 4, 90); |
This data was retrieved from a handful of order systems and needs to be validated for duplicates based on order date and customer. A unique constraint is not ideal on this table as it would prevent further analysis. Instead, the validation occurs after-the-fact so that there is control over how duplicates are reported and managed.
For this example, assume that when duplicates are identified, the one with the highest order count is retained and others are discarded. There are many ways to identify which rows are duplicates. For example, the data can be aggregated by OrderDate and CustomerID:
|
1 2 3 4 5 6 7 |
SELECT OrderDate, CustomerID, COUNT(*) AS Row_Count FROM #CustomerData GROUP BY OrderDate, CustomerID HAVING COUNT(*) > 1; |
This identifies a single OrderDate/CustomerID pair with duplicates:
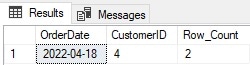
Once identified, any extra rows need to be deleted, which requires a separate query to remove them. Most common methods of duplicate removal require two distinct steps:
- Identify duplicates
- Remove duplicates
Here is an alternative that requires only a single step to do its work:
|
1 2 3 4 5 6 7 8 9 10 |
WITH CTE_DUPES AS ( SELECT OrderDate, CustomerID, ROW_NUMBER() OVER (PARTITION BY OrderDate, CustomerID ORDER BY OrderCount DESC) AS RowNum FROM #CustomerData) DELETE FROM CTE_DUPES WHERE RowNum > 1; |
Using a common-table expression combined with the ROW_NUMBER window function allows for duplicates to be identified within the CTE and immediately deleted in the same statement. The key to this syntax is that the PARTITION BY needs to contain the columns that are to be used to identify the duplicates. The ORDER BY determines which row should be kept (row number = 1) and which rows should be deleted (row numbers > 1). Replacing the DELETE with a SELECT * is an easy way to validate the results and ensure that the correct rows are getting jettisoned.
In addition to simplifying what could otherwise be some complex T-SQL, this syntax scales well as the complexity of the duplication logic increases. If more columns are required to determine duplicates or if determining which to remove requires multiple columns, each of those scenarios can be resolved by adding columns to each part of the ROW_NUMBER window function.
Code and list generation with dynamic SQL
A tool often maligned as hard to document, read, or maintain, dynamic SQL can allow for code to be greatly simplified when used effectively. A good example of this is in generating T-SQL. Consider code that performs a maintenance task on each user database on a SQL Server, such as running a full backup before a major software deployment. The most common solutions to this request would be one of these chunks of code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
-- Solution 1: BACKUP DATABASE [AdventureWorks2017] TO DISK = 'D:\ReleaseBackups\AdventureWorks2017.bak'; BACKUP DATABASE [AdventureWorksDW2017] TO DISK = 'D:\ReleaseBackups\AdventureWorksDW2017.bak'; BACKUP DATABASE [WideWorldImporters] TO DISK = 'D:\ReleaseBackups\WideWorldImporters.bak'; BACKUP DATABASE [WideWorldImportersDW] TO DISK = 'D:\ReleaseBackups\WideWorldImportersDW.bak'; BACKUP DATABASE [BaseballStats] TO DISK = 'D:\ReleaseBackups\BaseballStats.bak'; BACKUP DATABASE [ReportServer] TO DISK = 'D:\ReleaseBackups\ReportServer.bak'; -- Solution 2 DECLARE DatabaseCursor CURSOR FOR SELECT databases.name FROM sys.databases WHERE name NOT IN ('master', 'model', 'MSDB', 'TempDB'); OPEN DatabaseCursor; DECLARE @DatabaseName NVARCHAR(MAX); DECLARE @SqlCommand NVARCHAR(MAX); FETCH NEXT FROM DatabaseCursor INTO @DatabaseName; WHILE @@FETCH_STATUS = 0 BEGIN SELECT @SqlCommand = N' BACKUP DATABASE [' + @DatabaseName + '] TO DISK = ''D:\ReleaseBackups\' + @DatabaseName + '.bak'';'; EXEC sp_executesql @SqlCommand; FETCH NEXT FROM DatabaseCursor INTO @DatabaseName; END CLOSE DatabaseCursor; DEALLOCATE DatabaseCursor; |
The first solution has database names hard-coded into backup statements. While simple enough, it requires manual maintenance as each time a database is added or removed; this code needs to be updated to be sure that databases are all getting backup up properly. For a server with a large number of databases, this could become a very large chunk of code to maintain.
The second solution uses a cursor to iterate through databases, backing each up one-at-a-time. This is dynamic, ensuring that the list of databases to backup is complete, but it uses a cursor and iterates to complete the set of backups. While a more scalable solution, it is still a bit cumbersome and relies on a cursor or WHILE loop to ensure each database is accounted for.
Consider this alternative:
|
1 2 3 4 5 6 7 |
DECLARE @SqlCommand NVARCHAR(MAX) = ''; SELECT @SqlCommand = @SqlCommand + N' BACKUP DATABASE [' + name + '] TO DISK = ''D:\ReleaseBackups\' + name + '.bak'';' FROM sys.databases WHERE name NOT IN ('master', 'model', 'MSDB', 'TempDB'); EXEC sp_executesql @SqlCommand; |
In this example, dynamic SQL is built directly from sys.databases, allowing a single T-SQL statement to generate the full list of backup commands, which are then immediately executed in a single batch. This is fast, efficient, and the smaller T-SQL is less complex than the earlier dynamic SQL example and easier to maintain than the hard-coded list of backups. This code does not speed up the backup processes themselves, but simplifies the overhead needed to manage them.
Lists can be similarly generated. For example, if a comma-separated list of names was required by a UI, it could be generated using a method like this:
|
1 2 3 4 5 6 7 8 9 |
DECLARE @MyList VARCHAR(MAX) = ''; SELECT @MyList = @MyList + FullName + ',' FROM Application.People WHERE IsSystemUser = 1 AND IsSalesperson = 1; IF LEN(@MyList) > 0 SELECT @MyList = LEFT(@MyList, LEN(@MyList) - 1); SELECT @MyList; |
The results stored in @MyList are as follows:

Nothing fancy, but the ability to generate that list without an iterative loop and without extensive T-SQL is convenient. Note that the final two lines of this code serve to remove the trailing comma if the list was non-empty.
Alternatively, STRING_AGG can take the place of list-building, like this:
|
1 2 3 4 5 |
SELECT STRING_AGG(FullName,',') FROM Application.People WHERE IsSystemUser = 1 AND IsSalesperson = 1; |
Even less code! The dynamic SQL syntax will benefit from flexibility if there is a need to do quite a bit of string manipulation, but STRING_AGG provides the most minimalist solution possible.
Generating a list using dynamic SQL will often be an efficient and simple way to either display data in a compact format or to execute T-SQL statements en masse via metadata stored in a user table or system view. This is a scenario where dynamic SQL can simplify maintenance and also decrease the amount of code that needs to be maintained in stored procedures, PowerShell, or script files.
Reading and writing data simultaneously using OUTPUT
A common need in applications that write transactional data is to immediately retrieve and use recently modified data. The classic tactic for accomplishing this would be to:
- Modify data
- Determine what data was modified using temp tables,
SCOPE_IDENTITY(), SELECTstatements with targeted filters, or some other process. - Use the information from step #2 to retrieve any changed data that is required by the application.
While functionally valid, this process requires accessing transactional data multiple times to write it and then retrieving the recently written rows. OUTPUT allows recently modified data to be captured as part of the same T-SQL statement that modifies it. The following is an example of an update statement that uses OUTPUT to retrieve some metadata about which rows were updated in an inventory table:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE #StockItemIDList (StockItemID INT NOT NULL PRIMARY KEY CLUSTERED); UPDATE StockItemHoldings SET BinLocation = 'Q-1' OUTPUT INSERTED.StockItemID INTO #StockItemIDList FROM warehouse.StockItemHoldings WHERE BinLocation = 'L-3'; SELECT * FROM #StockItemIDList; DROP TABLE #StockItemIDList; |
The update is straightforward, updating an item’s location to someplace new. The added OUTPUT clause takes the IDs for all updated rows and inserts them into the temporary table. This allows further actions to be taken using information about the updated rows without the need to go back and figure out which were updated after the fact.
INSERTED and DELETED behave similarly to those tables as they are used in triggers and can both be freely accessed when using OUTPUT. This example illustrates how a column from each can be returned together as part of an UPDATE:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TABLE #StockItemIDList (StockItemID INT NOT NULL PRIMARY KEY CLUSTERED, LastEditedWhen DATETIME2(7) NOT NULL); UPDATE StockItemHoldings SET BinLocation = 'L-3' OUTPUT INSERTED.StockItemID, DELETED.LastEditedWhen INTO #StockItemIDList FROM warehouse.StockItemHoldings WHERE BinLocation = 'Q-1'; SELECT * FROM #StockItemIDList; DROP TABLE #StockItemIDList; |
The results returned in the temp table are as follows:
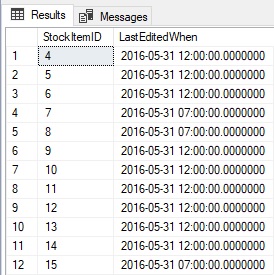
Shown above are the IDs for each updated row as well as the time it was last updated BEFORE this statement was executed. The ability to access both the INSERTED and DELETED tables simultaneously when updating data can save time and T-SQL. As with triggers, a DELETE statement can only meaningfully access the DELETED table, whereas an INSERT should only use the INSERTED table.
Consider the alternative for a moment:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TABLE #StockItemIDList (StockItemID INT NOT NULL PRIMARY KEY CLUSTERED); DECLARE @LastEditedWhen DATETIME2(7) = GETUTCDATE(); UPDATE StockItemHoldings SET BinLocation = 'Q-1', LastEditedWhen = @LastEditedWhen FROM warehouse.StockItemHoldings WHERE BinLocation = 'L-3'; INSERT INTO #StockItemIDList (StockItemID) SELECT StockItemID FROM warehouse.StockItemHoldings WHERE BinLocation = 'Q-1'; -- Or alternatively WHERE LastEditedWhen = @LastEditedWhen |
It’s a bit longer and requires double-dipping into the StockItemHoldings table to both update data and then retrieve information about it after-the-fact.
OUTPUT provides convenience and allows data to be modified while simultaneously collecting details about those modifications. This can save time, resources, and allow for simpler code that is easier to read and maintain. It may not always be the best solution but can provide added utility and simplified code when no other alternative exists that is as clean as this one.
Some useful dynamic management views
Books could easily be written on how to use dynamic management views for fun and profit, so I’ll stick to a handful that are simple, easy to use, and contain information that would otherwise be a hassle to get within SQL Server:
|
1 2 3 |
SELECT * FROM sys.dm_os_windows_info SELECT * FROM sys.dm_os_host_info SELECT * FROM sys.dm_os_sys_info |
These provide some basic details about Windows and the host that this SQL Server runs on:
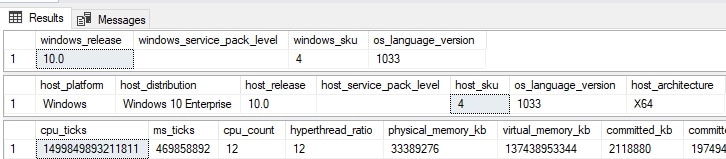
If you need to answer some quick questions about the Windows host or its usage, these are great views to interrogate for answers. This one provides details about SQL Server Services:
|
1 |
SELECT * FROM sys.dm_server_services |
Included are SQL Server, SQL Server Agent, as well as any others that are controlled directly by SQL Server (such as full-text indexing):

More useful info that is more convenient to gather via a query than by manually visiting using a UI. This is particularly valuable data as any one of these columns could otherwise be a hassle to get across many servers. The service account can be used to answer audit questions or validate that those services are configured correctly. Likewise, the last startup time is helpful to understanding uptime, maintenance, or unexpected restarts.
This DMV lists the registry settings for this SQL Server instance:
|
1 |
SELECT * FROM sys.dm_server_registry |
The results can be lengthy, but being able to quickly collect and analyze this data can be a huge time-saver when researching server configuration settings:
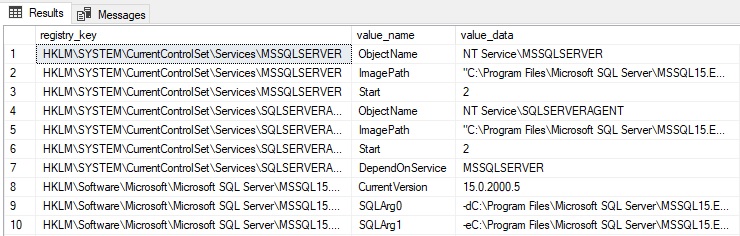
The alternatives of using the UI or some additional scripting to read these values are a hassle, and this dynamic management view provides a big convenience bonus! Note that only registry entries associated with the SQL Server instance are documented here. This includes port numbers, execution parameters, and network configuration details.
One final view that also provides some OS-level details that are otherwise a nuisance to get:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT master_files.name, master_files.type_desc, master_files.physical_name, master_files.size, master_files.max_size, master_files.growth, dm_os_volume_stats.volume_mount_point, dm_os_volume_stats.total_bytes, dm_os_volume_stats.available_bytes FROM sys.master_files CROSS APPLY sys.dm_os_volume_stats(master_files.database_id, master_files.file_id); |
Dm_os_volume_stats returns information about volume mount points, their total/available space, and lots more:

The results are a great way to check the size and growth settings for each file for databases on this SQL Server, as well as overall volume mount point details. There are many more columns available in these views that may prove useful, depending on what details are needed. Feel free to SELECT * from these views to get a better idea of their contents.
Getting results using less T-SQL
The best summary for this discussion is that there are often many ways to solve a problem in SQL Server. Ultimately, some of those methods will be faster, more reliable, and/or require less computing resources. When knee-deep in code, don’t hesitate to stop and look around for better ways to accomplish a complex task. It is quite possible that a new version, service pack, or even CU of SQL Server contains a function that will make your life dramatically easier (DATEFROMPARTS anyone? How about STRING_SPLIT?). Hopefully, the tips in this article make your life a bit easier – and feel free to share your personal favorites as well!
If you like this article, you might also like Efficient Solutions to Gaps and Islands Challenges
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments